数据结构作业——哈夫曼树
/*【基本要求】
(1) 从文件中读出一篇英文文章,包含字母和空格等字符。
(2) 统计各个字符出现的频度。
(3) 根据出现的频度,为每个出现的字符建立一个哈夫曼编码,并输出。
(4) 输入一个字符串,为其编码并输出。
(5) 输入一串编码,为其译码并输出*/
/*【演示结果】
(1)显示英文文章及各字符出现的频率。
(2)显示每个字符的哈夫曼编码。
(3)文件读入一文本,显示对其编码结果,并存盘
(4)文件读入一组编码,显示对其译码结果,并存盘*/
#include
using namespace std;
#define N 128//最多128个字符种类
//数据存储结构
typedef struct{
char data;//数据
int weight;//数据权重
int lchild,rchild,parent;//左右结点及双亲
}HumfNode;
//词频统计存储结构
typedef struct{
char data;
int freq;
}Datafreq;
//编码存储结构
typedef struct{
int bits[128];存放编码0、1的数组
int start;
}HCode;
代码:
#include
#include
#include
#include
#include
#include
using namespace std;
#define N 128 //最大叶子结点数
typedef struct
{
char data; //编码对应的字符
int weight; //结点的权值
int lchild, rchild, parent;
}HumfNode;
typedef struct
{
char data;
int freq;
}Datafreq;
typedef struct
{
int bits[128]; //存放哈夫曼编码的字符数组
int start; //编码的起始位置
}HCode;
void FreqNode(char* st, Datafreq str[]) //统计单词和空格与其频率
{
int i, j, k, num[128];
char* p = st;
for (i = 0; i < 128; i++)
{
str[i].freq = 0;
}//初始化频度结点的频度
for (i = 0; i < 128; i++)
num[i] = 0;
//printf("英文文章如下:");
while (*p != NULL)
{
num[int(*p)]++;
p++;
}
j = 0;
for (i = 0; i < 128; i++)
{
str[i].data = char(i);
str[i].freq = num[i];
//统计每个结点的权重和内容
}
printf("\n");
printf("频度如下(ascll码由小到大排列):");
for (i = 0; i < 128; i++)
{
if (str[i].freq != '\0')
{
cout << str[i].data << str[i].freq << " ";
}
}
printf("\n");
}//功能实现的是统计文档中的各个字符的出现频率
//将整个ascll码表全部存储,并将其频度(权重)和内容放入哈夫曼结点中
void CreatHufmTree(HumfNode tree[], Datafreq str[], int n) //建立哈夫曼树
{
int m1, m2, i, l, r, k;
Datafreq* p = str;
for (i = 0; i < 2 * n - 1; i++)
{
tree[i].lchild = tree[i].rchild = tree[i].parent = -1;
tree[i].weight = 0;
}
for (i = 0; i < n; i++)
{
tree[i].data = p[i].data;
tree[i].weight = p[i].freq;
}
for (i = n; i < 2 * n - 1; i++)
{
m1 = m2 = 32767;
l = r = -1;
for (k = 0; k < i; k++)
{
if (tree[k].parent == -1 && tree[k].weight <= m1)
{
m2 = m1;
r = l;
m1 = tree[k].weight;
l = k;
}
else if (tree[k].parent == -1 && tree[k].weight <= m2)
{
m2 = tree[k].weight;
r = k;
}
else
{
}
}
tree[i].weight = tree[l].weight + tree[r].weight;
tree[i].lchild = l;
tree[i].rchild = r;
tree[l].parent = i;
tree[r].parent = i;
if (tree[i].weight == tree[l].weight)
{
tree[i].data = tree[l].data;
tree[i].weight = tree[l].weight;
tree[i].lchild = tree[i].rchild = -1;
}
else if (tree[i].weight == tree[r].weight)
{
tree[i].data = tree[r].data;
tree[i].weight = tree[r].weight;
tree[i].lchild = tree[i].rchild = -1;
}
//下标为i的新结点成为权值最小的两个结点双亲
//新结点的权值为两个结点权值之和
//权值最小的结点是新结点的左孩子
//权值次最小的结点为右孩子
}
}//建立哈夫曼树
void HufmCode(HumfNode tree[], HCode hcd[], int n) //哈夫曼编码的生成
{
int i, f, c, k;
HCode cd; //用于临时存放编码串
for (i = 0; i < 128; i++)
{
for (int r = 0; r < N; r++)
{
cd.bits[r] = 2;
}
cd.start = n - 1;
c = i; //从叶子结点开始往上回溯
f = tree[i].parent;
//找到它的双亲结点
while (f != -1) //回溯到根结点
{
//&& tree[f].weight != tree[c].weight
if (tree[f].lchild == c && tree[tree[f].rchild].weight != tree[f].weight && tree[tree[f].lchild].weight != tree[f].weight)
{
cd.bits[cd.start] = 0;
cd.start--;
c = f;
f = tree[c].parent;
}
else if (tree[f].rchild == c && tree[tree[f].rchild].weight != tree[f].weight && tree[tree[f].lchild].weight != tree[f].weight)
{
cd.bits[cd.start] = 1;
cd.start--;
c = f;
f = tree[c].parent;
}
else
{
tree[f].data = tree[tree[f].rchild].data;
tree[f].weight = tree[tree[f].rchild].weight;
tree[f].lchild = tree[f].rchild = -1;
c = f;
f = tree[c].parent;
}
}
//cd.start++;
hcd[i] = cd;
}
printf("输出哈夫曼编码:\n");
for (i = 0; i < n; i++)
{
if (tree[i].weight != 0)
{
printf("%c\n", tree[i].data);
for (k = hcd[i].start + 1; k < n; k++)
{
printf("%d", hcd[i].bits[k]);
}
printf("\n");
}
}
}
string TsCode( char a[], HumfNode tree[], int n) //哈夫曼树的译码
{
char* p = a;
int i = 0;
int k = 0;
i = 2 * n - 2;
string tsresult;
//将树根结点的下标赋i,从根结点出发向下搜索
a = p;
//unsigned long len = strlen(a);
printf("译码结果如下:");
while (*a != '2'&&*a!='\0')
{
if (*a == '0')
{
//printf("%d\n", tree[i].weight);
i = tree[i].lchild;
if ((tree[i].lchild == -1) && (tree[i].rchild == -1))
{
//printf("%d\n", tree[i].weight);
printf("%c", tree[i].data);
tsresult+=tree[i].data;
i = 2 * n - 2;
k++;
}
a++;
}
else if (*a == '1')
{
//printf("%d\n", tree[i].weight);
i = tree[i].rchild;
if ((tree[i].lchild == -1) && (tree[i].rchild == -1))
{
//printf("%d\n", tree[i].weight);
printf("%c", tree[i].data);
tsresult += tree[i].data;
i = 2 * n - 2;
k++;
}
a++;
}
}
return tsresult;
}
void outputfiles(string file,string a)
{
ofstream fout(file);
fout << a;
fout.close();
}
void outputfile(string file, HCode hcd[], HumfNode tree[], int n)
{
int i, k;
ofstream fout(file);
if (!fout)
{
cout << "文件不能打开" << endl;
}
else
{
// 输出到磁盘文件
for (i = 0; i < n; i++)
{
if (tree[i].data != '\0' && tree[i].weight != 0)
{
fout << tree[i].data << ":";
for (k = hcd[i].start + 1; k < n; k++)
if (hcd[i].bits[k] != 2)
{
fout << hcd[i].bits[k];
}
fout << endl;
printf("\n");
}
}
//关闭文件输出流
fout.close();
}
}
char* openfile(string file, char* st) //打开并显示文件
{
char ch;
int i = 0;
ifstream infile;
infile.open(file.data()); //将文件流对象与文件连接起来
while (!infile.eof())
{
infile.get(ch); //get( )函数从相应的流文件中读出一个字符,并将其返回给变量ch
if (infile.fail())
{
break;
}
st[i] = ch;
//cout << ch;
i++;
}
infile.close(); //关闭文件
return st;
}
void Getcode(char* bit, HumfNode tree[], HCode hcd[], int n)
{
char* p = bit;
int i = 0, k;
while (*(bit + i) != '\0')
{
for (k = 0; k < n; k++)
{
if (tree[k].data == *(bit + i))
{
for (int r = hcd[k].start; r < n; r++)
printf("%d", hcd[k].bits[r]);
}
}
i++;
}
//while (*p != '\0')
//{
// int i = 1, k;
// while (i <= n)
// {
// if (tree[i].data == *p)
// {
// // printf("输出哈夫曼编码:\n");
// // printf("%c",tree[i].data);
// for (k = hcd[i].start; k <= n; k++)
// printf("%c", hcd[i].bits[k]);
// // printf("\n");
// }
// i++;
// // else
// // i++;
// }
// p++;
//}
}
void main()
{
int i, j, k, t = 0, m, b;
char x;
int n = 128;
Datafreq str[128], stt[128], sft[128], num[128];
char st[1000], bm[200], sd[50], sf[50], sm[50];
HumfNode tree[2 * N - 1], st_tree[2 * N - 1], sf_tree[2 * N - 1]; //用于存放树中所有结点
HCode hcd[N], st_hcd[N], hst[N]; //用于存放字符的哈夫曼编码
char* ss, * yima;
string tscode;
while (1)
{
printf("******************************************************************************\n");
printf("******************************************************************************\n");
printf("** 1.从文件中读出一篇英文文章,包含字母和空格等字符。 **\n");
printf("** 2.统计各个字符出现的频度,为每个出现的字符建立一个哈夫曼编码,并输出。 **\n");
printf("** 3.输入一个字符串,为其编码并输出。 **\n");
printf("** 4.输入一串编码,为其译码并输出。 **\n");
printf("** 5.退出 **\n");
printf("******************************************************************************\n");
printf("******************************************************************************\n");
scanf_s("%d", &x);
switch (int(x))
{
case 1:
for (int y = 0; y < 1000; y++)
{
st[y] = '\0';
}
ss = openfile("D:\\mathess\\eee.txt", st);
printf("英文文章如下:");
while (*ss != '\0')
{
printf("%c", *ss);
ss++;
}
printf("\n");
break;
case 2: FreqNode(st, str);
CreatHufmTree(tree, str, n);
//cout << tree[65].data;
HufmCode(tree, hcd, n);
outputfile("D:\\mathess\\eeecode.txt", hcd, tree, n);
break;
case 3: printf("请输入一个字符串:");
scanf_s("%s", &sd, 50);
FreqNode(sd, stt);
CreatHufmTree(st_tree, stt, n);
HufmCode(st_tree, st_hcd, n);
//Getcode(sd, tree, hcd, n);
break;
case 4: printf("请输入一个字符串(为后面的译码内容提供编码参考):");
scanf_s("%s", &sf, 50);
FreqNode(sf, sft);
CreatHufmTree(sf_tree, sft, n);
HufmCode(sf_tree, hst, n);
for (int i = 0; i < 200; i++)
{
bm[i] = '2';
}
yima = openfile("D:\\mathess\\xuyaoyima.txt", bm);
i = 0;
printf("文档的一串编码为:");
while (*yima != '\0')
{
if (*yima == '0' || *yima == '1')
{
printf("%c", *yima);
yima++;
}
else
{
break;
}
}
printf("\n");
//scanf_s("%s", bm, 200);
//printf("译码后的结果:");
tscode=TsCode( bm, sf_tree, n);
//printf("%s", tscode);
//printf("%c", * Tscode);
outputfiles("D:\\mathess\\tscode.txt", tscode);
printf("\n");
break;
case 5: exit(0);
// default: printf("输入有误,请重新输入");
}
}
}
运行结果:


从文件读取英文文章,并显示读取后的文章内容
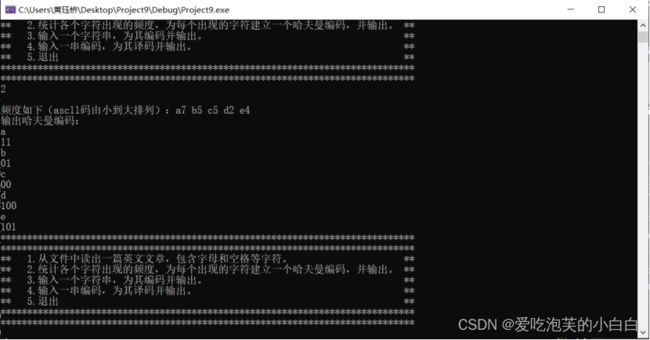

将其统计频率进行输出,并将编码结果存盘
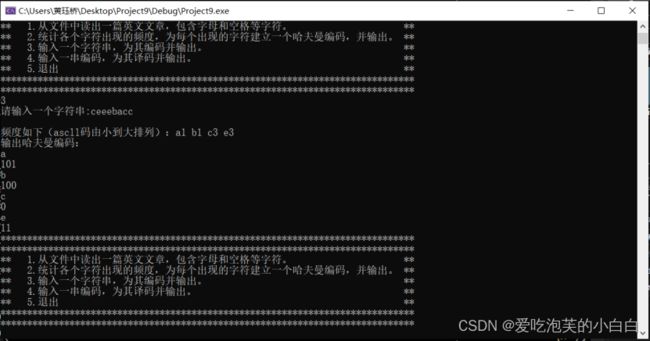
输入需要编码的字符串,并将译码结果输出

输入需要译码的编码,进行译码,并将译码结果输出,存盘,经过判断结果正确。