Apache Hudi初探(二)(与flink的结合)--flink写hudi的操作(JobManager端的提交操作)
背景
在Apache Hudi初探(一)(与flink的结合)中,我们提到了Pipelines.hoodieStreamWrite 写hudi文件,这个操作真正写hudi是在Pipelines.hoodieStreamWrite方法下的transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFactory),具体分析一下写入的过程。
分析
对于transform(opName("stream_write", conf), TypeInformation.of(Object.class), operatorFactory)这个代码片段,我们主要看operatorFactory 这个对象(transform这个操作是Flink框架的操作):
public class StreamWriteOperator extends AbstractWriteOperator {
public StreamWriteOperator(Configuration conf) {
super(new StreamWriteFunction<>(conf));
}
public static WriteOperatorFactory getFactory(Configuration conf) {
return WriteOperatorFactory.instance(conf, new StreamWriteOperator<>(conf));
}
}
最主要的hudi算子为StreamWriteOperator,其中最主要的操作是由StreamWriteFunction来完成的:
// StreamWriteFunction
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
this.taskID = getRuntimeContext().getIndexOfThisSubtask();
this.metaClient = StreamerUtil.createMetaClient(this.config);
this.writeClient = FlinkWriteClients.createWriteClient(this.config, getRuntimeContext());
this.writeStatuses = new ArrayList<>();
this.writeMetadataState = context.getOperatorStateStore().getListState(
new ListStateDescriptor<>(
"write-metadata-state",
TypeInformation.of(WriteMetadataEvent.class)
));
this.ckpMetadata = CkpMetadata.getInstance(this.metaClient.getFs(), this.metaClient.getBasePath());
this.currentInstant = lastPendingInstant();
if (context.isRestored()) {
restoreWriteMetadata();
} else {
sendBootstrapEvent();
}
// blocks flushing until the coordinator starts a new instant
this.confirming = true;
}
@Override
public void open(Configuration parameters) throws IOException {
this.tracer = new TotalSizeTracer(this.config);
initBuffer();
initWriteFunction();
}
@Override
public void snapshotState(FunctionSnapshotContext functionSnapshotContext) throws Exception {
if (inputEnded) {
return;
}
snapshotState();
// Reload the snapshot state as the current state.
reloadWriteMetaState();
}
@Override
public void snapshotState() {
// Based on the fact that the coordinator starts the checkpoint first,
// it would check the validity.
// wait for the buffer data flush out and request a new instant
flushRemaining(false);
}
@Override
public void processElement(I value, ProcessFunction.Context ctx, Collector -
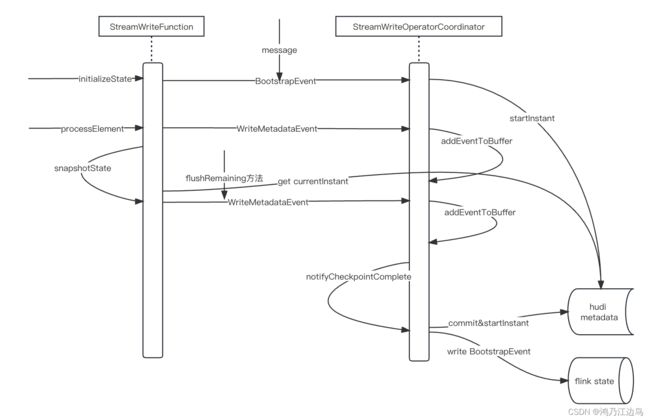
initializeState操作,主要是做一些初始化的操作-
this.taskID = getRuntimeContext().getIndexOfThisSubtask();
获取当前的task的索引下标,用来向operator coordinator发送event给operator coordinator,之后 StreamWriteOperatorCoordinator(operator coordinator) 进行处理,后续会说到StreamWriteOperatorCoordinator -
metaClient = StreamerUtil.createMetaClient(this.config)
writeClient = FlinkWriteClients.createWriteClient
初始化hudi的元数据客户端(这里是HoodieTableMetaClient)和写入客户端(这里是HoodieFlinkWriteClient) -
writeStatuses = new ArrayList<>()
记录后续的写入hudi文件的信息 -
writeMetadataState = context.getOperatorStateStore().getListState
记录写入hudi的元数据事件,会在后续的操作中,会包装成event发送给operator coordinator(StreamWriteOperatorCoordinator) -
ckpMetadata = CkpMetadata.getInstance
Flink的checkpoint的元数据信息路径,默认的路径是/${hoodie.basePath}/.hoodie/.aux/ckp_meta -
currentInstant = lastPendingInstant()
获取上次还没有完成的commit -
restoreWriteMetadata或者sendBootstrapEvent,根据是否是从checkpoint恢复过来的进行不同消息的发送,
这里的operator coordinator(StreamWriteOperatorCoordinator)会进行统一的处理,并初始化一个commit
-
-
open操作
写入hudi前的前置操作,比如说初始化TotalSizeTracer记录maxBufferSize便于flush操作
根据write.operation的值(默认是upsert)选择后续的操作是insert或upsert或overwrite,这里是upsert -
processElement操作
这里对传入的HoodieRecord进行缓存,主要是bufferRecord做的事情,- 首先会获取bucketID,之后再往对应的bucket中插入数据
- 如果超出
write.batch.size(默认是128MB),则会进行flushBucket操作,该操作主要是写入hudi操作 //TODO: 具体的写入hudi操作- 首先会获取新的需要提交的commit
- 再进行写入的实际操作
- 写入的文件元数据信息回传到
operator coordinator进行统一处理
-
snapshotState操作- 调用
flushRemaining写入剩下的数据到hudi存储中 - 重新加载当前写入的hudi文件元数据信息到当前flink的state中
- 调用
hudi StreamWriteOperatorCoordinator作用
总的来说,StreamWriteOperatorCoordinator扮演的角色和在Spark中driver的角色一样,都是来最后来提交 元数据信息到huid中。
具体的作用还是得从具体的方法来看:
@Override
public void handleEventFromOperator(int i, OperatorEvent operatorEvent) {
ValidationUtils.checkState(operatorEvent instanceof WriteMetadataEvent,
"The coordinator can only handle WriteMetaEvent");
WriteMetadataEvent event = (WriteMetadataEvent) operatorEvent;
if (event.isEndInput()) {
// handle end input event synchronously
// wrap handleEndInputEvent in executeSync to preserve the order of events
executor.executeSync(() -> handleEndInputEvent(event), "handle end input event for instant %s", this.instant);
} else {
executor.execute(
() -> {
if (event.isBootstrap()) {
handleBootstrapEvent(event);
} else {
handleWriteMetaEvent(event);
}
}, "handle write metadata event for instant %s", this.instant
);
}
}
...
@Override
public void notifyCheckpointComplete(long checkpointId) {
executor.execute(
() -> {
// The executor thread inherits the classloader of the #notifyCheckpointComplete
// caller, which is a AppClassLoader.
Thread.currentThread().setContextClassLoader(getClass().getClassLoader());
// for streaming mode, commits the ever received events anyway,
// the stream write task snapshot and flush the data buffer synchronously in sequence,
// so a successful checkpoint subsumes the old one(follows the checkpoint subsuming contract)
final boolean committed = commitInstant(this.instant, checkpointId);
if (tableState.scheduleCompaction) {
// if async compaction is on, schedule the compaction
CompactionUtil.scheduleCompaction(metaClient, writeClient, tableState.isDeltaTimeCompaction, committed);
}
if (tableState.scheduleClustering) {
// if async clustering is on, schedule the clustering
ClusteringUtil.scheduleClustering(conf, writeClient, committed);
}
if (committed) {
// start new instant.
startInstant();
// sync Hive if is enabled
syncHiveAsync();
}
}, "commits the instant %s", this.instant
);
}
-
handleEventFromOperator方法用来接受task发送的消息
-
对于
BootStrap类型的WriteMetadataEvent(在StreamWriteFunction方法initializeState中),相当于函数初始化也就会触发
该类型的消息由handleBootstrapEvent来处理(我们这里假设每个任务operator都完成了初始化的操作),对应的数据流如下:initInstant || \/ reset => startInstantstartInstant 这里就会初始化一个hudi写操作的commit信息
-
对于一般的write的信息的event,(比如说在processElement的flushBucket函数中),由
handleWriteMetaEvent来处理:if (this.eventBuffer[event.getTaskID()] != null) { this.eventBuffer[event.getTaskID()].mergeWith(event); } else { this.eventBuffer[event.getTaskID()] = event; }这里只是加到变量名为eventBuffer 的WriteMetadataEvent类型的数组中,后续中会进行处理
-
对于
isEndInput为true的event,这种一般source是基于文件的这种,这里先不讨论
-
-
notifyCheckpointComplete 当对应的checkpointId完成以后,该方法会被调用
- commitInstant 提交hudi元数据,如果如果有发生异常,则回滚当前hudi对应的commit
- scheduleCompaction && scheduleClustering 进行hui的
Compcation和Clustering - 如果成功的提交了,则会开启一个新的commit,如果开了hive同步(
hive_sync.enabled默认为false),则会同步元数据信息到hive
总结
用一张图总结一下交互方式,如下: