Linux内核文件操作
Linux内核文件操作
- 前言
- 一、文件操作结构体
- 二、VFS之file_operations对象
-
- 1.文件打开filp_open
- 2.文件关闭filp_close
- 3.文件读取vfs_read
- 4.文件写入vfs_write
- 5.注意点
- 三、驱动模块实例
前言
Linux系统中的文件系统由两层结构进行构建:第一层为虚拟文件系统(VFS),第二层则是各种不同的具体的文件系统。VFS则是将各种具体的文件系统的公共部分抽取出来,从而形成一个抽象层,是Linux系统内核的一部分,它位于用户程序和具体的文件系统之间,对用户提供了标准的文件系统调用接口,对于具体的文件系统,通过一系列的对不同文件系统公用的函数指针来实际调用具体文件系统的函数,完成实际的各种差异操作。对于用户,对文件的读写操作时,可以使用函数open()、read()、write()和close()等,当在Linux内核中,肯定是没有这些函数可以使用,这个时候,可以使用内核的一些函数filp_open()、vfs_read()、vfs_write()、和filp_close()等去完成文件的读写。
一、文件操作结构体
struct file_operations {
struct module *owner;
/* 更新偏移量指针,由系统调用lleek调用它 */
loff_t (*llseek) (struct file *, loff_t, int);
/* 略 */
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
/* 略 */
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
/* 异步读,4.4版本前为aio_read() */
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
/* 异步写,4.4版本前为aio_write() */
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iterate) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
/* 在无大内核锁(BKL)的情况下调用,如果用户调用ioctl()系统调用,VFS便可以调用unlocked_ioctl() */
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
/* compat 全称 compatible(兼容的),主要目的是为 64 位系统提供 32 位 ioctl 的兼容方法,也是在无大内核锁的情况下调用 */
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
};
二、VFS之file_operations对象
接下来,简单介绍相关的内核API接口是如何使用的,对于filp_open()、filp_close()、vfs_read()、vfs_write()函数的声名在文件linux/fs.h中。
1.文件打开filp_open
函数原型如下:
struct file *filp_open(const char *filename, int flags, umode_t mode);
参数说明:
1)filename:要打开或创建文件的字符串名称,包括路径部分;
2)flags:文件的打开方式,该取值与open()函数类似,可以取O_CREATE、O_RDWR、O_RDONLY;
3)mode:创建文件时使用该参数,设置文件的读写权限,其它情况可以设置为0。
返回值:
文件打开成功返回正确的struct file *指针,失败返回错误的指针。
注意:函数filp_open()将返回struct file *结构指针,将会提供给后继的函数进行使用,需要使用IS_ERR()来校验指针的有效性。
2.文件关闭filp_close
函数的原型如下:
int filp_close(struct file *filp, fl_owner_t id);
参数说明:
1)filp:使用filp_opne()函数返回的struct file *结构指针;
2)id:一般设置为NULL。
返回值:
文件成功关闭时返回0,失败时返回负的错误号。
3.文件读取vfs_read
函数的原型如下:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos);
参数说明:
1)file:函数filp_open()调用后返回的struct file *结构指针;
2)buf:buf缓冲区,用来存储读取到的数据,该参数具有__user进行修饰,表明buf指向用户空间地址,如果传入内核空间地址时,就会出错,并返回-EFAULT;
3)count:要读取的数据字节个数;
4)pos:返回数据读取后的文件指针。
返回值:
文件读取成功时,返回读取到字节数,如果失败,返回负的错误号。
Linux内核实现源码:
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_READ))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count);
if (ret >= 0) {
count = ret;
ret = __vfs_read(file, buf, count, pos);
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}
EXPORT_SYMBOL(vfs_read);
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
/* 调用文件读操作方法 */
if (file->f_op->read)//同步
return file->f_op->read(file, buf, count, pos);
/* 通用文件模型读方法 */
else if (file->f_op->read_iter)//异步
return new_sync_read(file, buf, count, pos);/* Call file->f_op->read_iter */
else
return -EINVAL;
}
EXPORT_SYMBOL(__vfs_read);
注意:
1、上述代码"__vfs_read()"实现很简单,在做了一些条件判断后,如果改文件索引节点inode定义了文件的读实现方法的话就调用此方法,Linux下特殊文件读往往是用此方法(f_op->read),一些伪文件系统如:proc,sysfs等读写文件也是用此方法。
2、如果上述方法没有定义(即f_op->read/write==NULL)就会调用通用文件模型的读写方法(f_op->read_iter),它最终就是读内存,或者需要从存储介质中去读数据。(一般对普通文件操作时往往是此方法)。
4.文件写入vfs_write
函数的原型如下:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
参数说明:
1)file:函数filp_open()调用后返回的struct file *结构指针;
2)buf:buf缓冲区,用来存储要写入文件中的数据,该参数具有__user进行修饰,表明buf指向用户空间地址,如果传入内核空间地址时,就会出错,并返回-EFAULT;
3)count:要写入的数据字节个数;
4)pos:返回数据写入后的文件指针。
返回值:
文件写入成功时,返回写入到的字节个数,如果失败,返回负的错误号。
Linux内核实现源码:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_READ, buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (ret >= 0) {
count = ret;
file_start_write(file);
ret = __vfs_write(file, buf, count, pos);
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
}
return ret;
}
EXPORT_SYMBOL(vfs_write);
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
/* 调用文件写操作方法 */
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
/* 通用文件模型写方法 */
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
EXPORT_SYMBOL(__vfs_write);
5.注意点
对于vfs_read()和vfs_write()函数,参数buf是使用__user进行修饰的,表明buf指向用户空间地址,由于函数是在内核态中使用,因此,需要使用函数改变kernel对内存地址检查的处理方式,可以使用下面的函数:
static inline void set_fs(mm_segment_t fs)
对于set_fs()函数中的参数fs,具有两个取值,分别是USER_DS和KERNEL_DS,分别代表了用户空间和内核空间,在默认情况下,内核取值为USER_FS,也就是对用户空间地址检查并变换,因此,需要使用
set_fs(KERNEL_DS)
进行转换,改变kernel对内核空间地址检查,防止函数调用时出错,该函数的一般用法如下:
filp_open();
mm_segment_t old_fs;
old_fs = get_fs();
set_fs(KERNEL_DS);
...
... /* 内存相关的操作 */
...
set_fs(old_fs);
以上就是,在内核态进行文件操作的相关操作API接口,对于函数的具体实现,可以查看内核源码。
三、驱动模块实例
接下来,将进行一个简单的实例进行说明上面介绍的函数API接口使用,编写一个简单的内核模块filp_open,在模块加载的时候,在内核态中完成一个test,cfg文件的创建和读写操作,新建filp_open.c文件,代码如下:
#include 模块比较简单,不介绍了,接下来,为该模块编写Makefile文件,如下:
# Makefile for driver
obj-m += filp_open.o
all:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) modules
clean:
make -C /lib/modules/$(shell uname -r)/build M=$(PWD) clean
使用命令进行编译,并将模块加载到内核中运行:
$ make
$ sudo insmod filp_open.ko
模块加载后,会创建/home/hly/test.cfg文件,并在文件中写入字符串"hello world,kernel file.",将该字符串读取出来并打印效果如下:
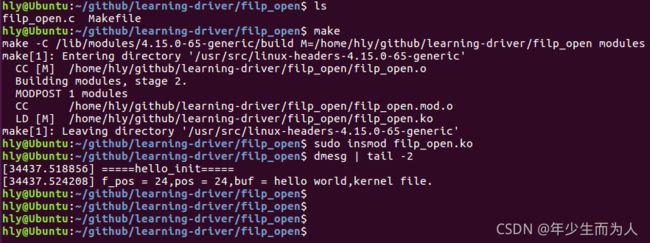
到此,关于该测试模块的相关介绍完毕。
参考链接