响应式编程
响应式编程
响应式编程打破了传统的同步阻塞式编程模型,基于响应式数据流和背压机制实现了异步非阻塞式的网络通信、数据访问和事件驱动架构,能够减轻服务器资源之间的竞争关系,从而提高服务的响应能力。
一、Reactive Stream
要了解什么是响应式编程,首先要了解JDK 9 的Reactive Stream。Reactive Stream其实就是一个支持背压的发布订阅模式。其核心主要包括4个接口 ,即 Publisher、Subscriber、Subscription 和 Processor
1.1 概念
-
背压
背压是指订阅者能和发布者交互,可以调节发布者发布数据的速率,解决把订阅者压垮的问题。
-
Pubisher
/** * 发布者 */ public interface Publisher<T> { // 注册订阅者 public void subscribe(Subscriber<? super T> s); } -
Subscriber
/** * 订阅者 */ public interface Subscriber<T> { // 订阅者被注册时的回调 public void onSubscribe(Subscription s); // 发布者发布事件(数据)时的回调 public void onNext(T t); // 处理事件(数据)过程中出现异常时的回调 public void onError(Throwable t); // 事件全部处理完成,发布者结束发布的回调 public void onComplete(); } -
Subscription
/** * 发布订阅上下文,可以理解为发布者和订阅者沟通的桥梁,是实现背压的关键 */ public interface Subscription { // 请求n个事件(数据) public void request(long n); // 取消订阅 public void cancel(); } -
Processor
Processor, 需要继承SubmissionPublisher并实现Processor接口,它是Publisher和Subscriber之间的一道屏障,可以理解为过滤器;
1.2 代码示例
/**
* 带 process 的 flow demo
*/
import java.util.concurrent.Flow;
import java.util.concurrent.SubmissionPublisher;
/**
* Processor, 需要继承SubmissionPublisher并实现Processor接口
*
* 输入源数据 integer, 过滤掉小于0的, 然后转换成字符串发布出去
*/
class MyProcessor extends SubmissionPublisher<String> implements Flow.Processor<Integer, String> {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
// 保存订阅关系, 需要用它来给发布者响应
this.subscription = subscription;
// 请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(Integer item) {
// 接受到一个数据, 处理
System.out.println("处理器接受到数据: " + item);
// 过滤掉小于0的, 然后发布出去
if (item > 0) {
this.submit("转换后的数据:" + item);
}
// 处理完调用request再请求一个数据
this.subscription.request(1);
// 或者 已经达到了目标, 调用cancel告诉发布者不再接受数据了
// this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
// 出现了异常(例如处理数据的时候产生了异常)
throwable.printStackTrace();
// 我们可以告诉发布者, 后面不接受数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
// 全部数据处理完了(发布者关闭了)
System.out.println("处理器处理完了!");
// 关闭发布者
this.close();
}
}
public class FlowDemo2 {
public static void main(String[] args) throws Exception {
// 1. 定义发布者, 发布的数据类型是 Integer
// 直接使用jdk自带的SubmissionPublisher
SubmissionPublisher<Integer> publisher = new SubmissionPublisher<>();
// 2. 定义处理器, 对数据进行过滤, 并转换为String类型
MyProcessor processor = new MyProcessor();
// 3. 发布者 和 处理器 建立订阅关系
publisher.subscribe(processor);
// 4. 定义最终订阅者, 消费 String 类型数据
Flow.Subscriber<String> subscriber = new Flow.Subscriber<>() {
private Flow.Subscription subscription;
@Override
public void onSubscribe(Flow.Subscription subscription) {
// 保存订阅关系, 需要用它来给发布者响应
this.subscription = subscription;
// 请求一个数据
this.subscription.request(1);
}
@Override
public void onNext(String item) {
// 接受到一个数据, 处理
System.out.println("接受到数据: " + item);
// 处理完调用request再请求一个数据
this.subscription.request(1);
// 或者 已经达到了目标, 调用cancel告诉发布者不再接受数据了
// this.subscription.cancel();
}
@Override
public void onError(Throwable throwable) {
// 出现了异常(例如处理数据的时候产生了异常)
throwable.printStackTrace();
// 我们可以告诉发布者, 后面不接受数据了
this.subscription.cancel();
}
@Override
public void onComplete() {
// 全部数据处理完了(发布者关闭了)
System.out.println("处理完了!");
}
};
// 5. 处理器 和 最终订阅者 建立订阅关系
processor.subscribe(subscriber);
// 6. 生产数据, 并发布
// 这里忽略数据生产过程
publisher.submit(-111);
publisher.submit(111);
// 7. 结束后 关闭发布者
// 正式环境 应该放 finally 或者使用 try-resouce 确保关闭
publisher.close();
// 主线程延迟停止, 否则数据没有消费就退出
Thread.currentThread().join(1000);
}
}
二、Project Reactor
在 Java 领域,目前响应式流的开发库包括 RxJava、Akka、Vert.x 和 Project Reactor 等。
Spring 5 的响应式编程模型以 Project Reactor 库为基础,并且Spring Boot 从 2.x 版本开始也是全面依赖 Spring 5。
Reactor 框架可以单独使用。和集成其他第三方库一样,如果想要在代码中引入 Reactor,要做的事情就是在 Maven 的 pom 文件中添加如下依赖包。:
<dependency>
<groupId>io.projectreactorgroupId>
<artifactId>reactor-coreartifactId>
dependency>
Reactor 框架提供了两个核心组件来发布数据,分别是 Flux 和 Mono 组件。这两个组件可以说是应用程序开发过程中最基本的编程对象。
2.1 创建流
2.1.1 Flux
Flux 代表的是一个包含 0 到 n 个元素的异步序列,Reactor 官网给出了它的示意图,如下所示:
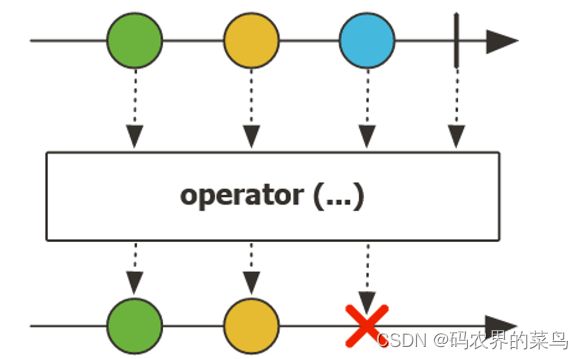
创建Flux的方式总体上来说分为两类,一类是静态创建方法,一类是动态创建方法。我们来看下:
-
静态方法创建Flux
-
just()方法
一般情况下,在已知元素数量和内容时,使用 just() 方法是创建 Flux 的最简单直接的做法。
Flux.just("Hello", "World").subscribe(System.out::println); -
fromXXX()方法组
如果我们已经有了一个数组、一个 Iterable 对象或 Stream 对象,那么就可以通过 Flux 提供的 fromXXX() 方法组来从这些对象中自动创建 Flux,包括 fromArray()、fromIterable() 和 fromStream() 方法。
List<String> strList = new ArrayList<>(); strList.add("1"); strList.add("2"); strList.add("3"); Flux.fromIterable(strList).subscribe(System.out::println); Flux.fromArray(new String[]{"1","2","3"}).subscribe(System.out::println); Flux.fromStream(Arrays.stream(new String[]{"1","2","3"}).map(Integer::parseInt)).subscribe(System.out::println); -
range()方法
如果你快速生成一个整数数据流,那么可以采用 range() 方法,该方法允许我们指定目标整数数据流的起始元素以及所包含的个数,序列中的所有对象类型都是 Integer,这在创建连续的年份信息或序号信息等场景下非常有用。
Flux.range(2020, 5).subscribe(System.out::println); -
interval()方法
interval() 方法可以用来生成从 0 开始递增的 Long 对象的数据序列。通过 interval() 所具备的一组重载方法,我们可以分别指定这个数据序列中第一个元素发布之前的延迟时间,以及每个元素之间的时间间隔。
Flux.interval(Duration.ofMillis(500), Duration.ofMillis(1000)).subscribe(System.out::println);-
empty()、error() 和 never()
可以分别使用 empty()、error() 和 never() 这三个方法类创建一些特殊的数据序列: 可以使用 empty() 方法创建一个只包含结束消息的空序列; 通过 error() 方法可以创建一个只包含错误消息的序列 ; 使用 never() 方法创建的序列不发出任何类似的消息通知 。
// empty() Flux.empty().subscribe(System.out::println); // error() Flux.error(new Exception("测试出错")).subscribe(System.out::println); // never() Flux.never().subscribe(System.out::println);
-
-
动态方法创建Flux
-
generate()方法
generate() 方法生成 Flux 序列依赖于 Reactor 所提供的 SynchronousSink 组件,SynchronousSink 组件包括 next()、complete() 和 error() 这三个核心方法。从 SynchronousSink 组件的命名上就能知道它是一个同步的 Sink 组件,也就是说元素的生成过程是同步执行的。这里要注意的是 next() 方法只能最多被调用一次。
// 直接发布具体数据 Flux.generate(synchronousSink -> { synchronousSink.next("1"); synchronousSink.complete(); }).subscribe(System.out::println); // 先定义数据,再处理数据 Flux.generate(() -> 1, (i, synchronousSink) -> { synchronousSink.next(i); if (i == 5) { synchronousSink.complete(); } return ++i; }).subscribe(System.out::println); // 先定义数据,再处理数据,最后再监控数据 Flux.generate(() -> 1, (i, synchronousSink) -> { synchronousSink.next(i); if (i == 5) { synchronousSink.complete(); } return ++i; }, i -> System.out.println("这里是状态监控器,i最后的状态为:" + i)).subscribe(System.out::println);运行该段代码,会在系统控制台上得到“1”。我们在这里调用了一次 next() 方法,并通过 complete() 方法结束了这个数据流。如果不调用 complete() 方法,那么就会生成一个所有元素均为“1”的无界数据流。
-
create()方法
create() 方法与 generate() 方法比较类似,但它使用的是一个 FluxSink 组件, FluxSink 除了 next()、complete() 和 error() 这三个核心方法外,还定义了背压策略,并且可以在一次调用中产生多个元素。
// 直接发布具体的数据 Flux.create(fluxSink -> { for (int i = 0; i < 5; i++) { fluxSink.next(i); } fluxSink.complete(); }).subscribe(System.out::println); // 发布具体的数据,并指定背压策略 Flux.create(fluxSink -> { for (int i = 0; i < 5; i++) { fluxSink.next(i); } fluxSink.complete(); }, FluxSink.OverflowStrategy.DROP).subscribe(System.out::println);在 Reactor 框架中,针对背压有以下四种处理策略。
-
BUFFER:代表一种缓存策略,缓存消费者暂时还无法处理的数据并放到队列中,这时候使用的队列相当于是一种无界队列。
-
DROP:代表一种丢弃策略,当消费者无法接收新的数据时丢弃这个元素,这时候相当于使用了有界丢弃队列。
-
LATEST:类似于 DROP 策略,但让消费者只得到来自上游组件的最新数据。
-
ERROR:代表一种错误处理策略,当消费者无法及时处理数据时发出一个错误信号。
-
-
2.1.2 MONO
Mono 数据序列中只包含 0 个或 1 个元素,如下图所示 :
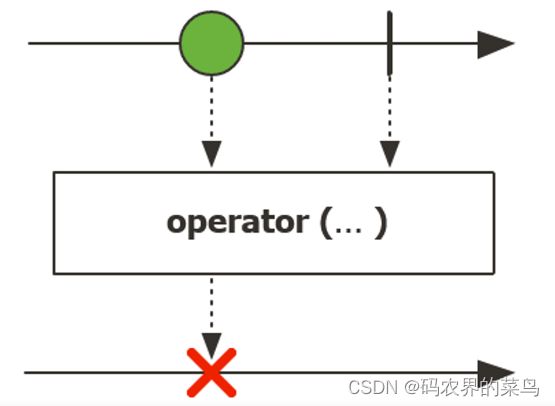
创建Mono的方式总体上来说和Flux差不多,也是一类是静态创建方法,一类是动态创建方法。我们来看下:
-
静态方法创建Mono
针对静态创建 Mono 的场景,前面给出的 just()、empty()、error() 和 never() 等方法同样适用, 除了这些方法之外,比较常用的还有 justOrEmpty() 等方法。
-
just()\justOrEmpty()
// 报错 NPE Mono.just(null).subscribe(System.out::println); // 不报错 Mono.justOrEmpty(null).subscribe(System.out::println); -
fromCallable()
该方法返回一个新的Mono,该Mono执行提供的Runnable任务并返回其结果(如果有的话)。
Mono.fromCallable(() -> account).subscribe(System.out::println); -
fromRunnable()
这个方法类似于
Mono.from(),但是它不返回任何结果,只执行提供的Runnable任务。Mono.fromRunnable(() -> System.out.println("这里只执行逻辑不会返回任何信息")).subscribe(System.out::println);
-
-
动态方法创建Mono
-
create()
Mono.create(monoSink -> monoSink.success("ceshi")).subscribe(System.out::println);
-
2.2 订阅流
想要订阅响应式流,就需要用到 subscribe() 方法。在前面的示例中我们已经演示了 subscribe 操作符的用法,知道可以通过 subscribe() 方法来添加相应的订阅逻辑。同时,在调用 subscribe() 方法时可以指定需要处理的消息通知类型。正如前面内容所看到的,Flux 和 Mono 提供了一批非常有用的 subscribe() 方法重载方法,大大简化了订阅的开发例程。这些重载方法包括如下几种:
//订阅流的最简单方法,忽略所有消息通知
subscribe();
//对每个来自 onNext 通知的值调用 dataConsumer,但不处理 onError 和 onComplete 通知
subscribe(Consumer<T> dataConsumer);
//在前一个重载方法的基础上添加对 onError 通知的处理
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer);
//在前一个重载方法的基础上添加对 onComplete 通知的处理
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer,
Runnable completeConsumer);
//这种重载方法允许通过请求足够数量的数据来控制订阅过程
subscribe(Consumer<T> dataConsumer, Consumer<Throwable> errorConsumer,
Runnable completeConsumer, Consumer<Subscription> subscriptionConsumer);
//订阅序列的最通用方式,可以为我们的 Subscriber 实现提供所需的任意行为
subscribe(Subscriber<T> subscriber);
2.3 操作流
数据流通常都会涉及转换、过滤、裁剪等核心操作,以及一些辅助性的操作,总的来说可以分成如下六大类型:
-
转换(Transforming)操作符,负责将序列中的元素转变成另一种元素;
-
过滤(Filtering)操作符,负责将不需要的数据从序列中剔除出去;
-
组合(Combining)操作符,负责将序列中的元素进行合并、连接和集成;
-
条件(Conditional)操作符,负责根据特定条件对序列中的元素进行处理;
-
裁剪(Reducing)操作符,负责对序列中的元素执行各种自定义的裁剪操作;
-
工具(Utility)操作符,负责一些针对流式处理的辅助性操作。
我们接下来的讲解,主要看一些常用的方法。
2.3.1 转换操作符
转换可以说是对数据流最常见的一种操作了,Reactor 中常用的转换操作符包括 buffer、window、map 和 flatMap 等。
-
buffer 操作符
buffer 操作符的作用相当于把当前流中的元素统一收集到一个集合中,并把这个集合对象作为新的数据流。使用 buffer 操作符在进行元素收集时,可以指定集合对象所包含的元素的最大数量。buffer 操作符的一种用法如下所示:
Flux.just("1","2","3","4", "5").buffer(2).subscribe(System.out::println);上面的操作结果为:
[1, 2]
[3, 4]
[5] -
map 操作符
map 操作符相当于一种映射操作,它对流中的每个元素应用一个映射函数从而达到转换效果
Flux.just("1","2","3","4", "5").map(i -> "number:" + i).subscribe(System.out::println); -
flatMap 操作符
flatMap 操作符执行的也是一种映射操作,但与 map 不同,该操作符会把流中的每个元素映射成一个流而不是一个元素,然后再把得到的所有流中的元素进行合并。
Flux<User> users = userRepository.getUsers(); users.flatMap(u -> getOrdersByUser(u));
2.3.2 过滤操作符
过滤类操作符的作用非常明确,就是从数据流中只获取自己想要的元素。Reactor 中的过滤操作符也有很多,常用的包括 filter、first/last、skip/skipLast、take/takeLast 等,这些操作符应用起来都相对比较简单。
-
filter 操作符
filter 操作符的含义与普通的过滤器类似,就是对流中包含的元素进行过滤,只留下满足指定过滤条件的元素,而过滤条件的指定一般是通过断言。
Flux.range(1, 10).filter(i -> i % 2 == 0).subscribe(System.out::println); -
skip/skipLast
如果使用 skip 操作符,将会忽略数据流的前 n 个元素。类似的,如果使用 skipLast 操作符,将会忽略流的最后 n 个元素。
List<String> strList = new ArrayList<>(); strList.add("1"); strList.add("2"); strList.add("3"); Flux.fromIterable(strList).skip(2).subscribe(System.out::println); Flux.fromIterable(strList).skipLast(2).subscribe(System.out::println); -
take/takeLast
take 系列操作符用来从当前流中提取元素。我们可以按照指定的数量来提取元素,也可以按照指定的时间间隔来提取元素。类似的,takeLast 系列操作符用来从当前流的尾部提取元素。
List<String> strList = new ArrayList<>(); strList.add("1"); strList.add("2"); strList.add("3"); Flux.fromIterable(strList).take(2).subscribe(System.out::println); Flux.fromIterable(strList).takeLast(2).subscribe(System.out::println);
2.3.3 组合操作符
Reactor 中常用的组合操作符有 then/when、merge、startWith 和 zip 等。相比过滤操作符,组合操作符要复杂一点 。
-
then\thenMany操作符
then 操作符的含义是等到上一个操作完成再进行下一个
Flux.just(1, 2, 3) .then() .subscribe(System.out::println); Flux.just(1, 2, 3) .thenMany(Flux.just(4, 5)) .subscribe(System.out::println); -
when操作符、
when 操作符的含义则是等到多个操作一起完成.
public Mono<Void> updateOrders(Flux<Order> orders) { return orders.flatMap(file -> { Mono<Void> saveOrderToDatabase = ...; Mono<Void> sendMessage = ...; return Mono.when(saveOrderToDatabase, sendMessage); }); -
merge/mergeSequential 操作符
作为一种典型的组合类操作符,merge 操作符用来把多个 Flux 流合并成一个 Flux 序列,而合并的规则就是按照流中元素的实际生成的顺序进行 。
Flux.merge(Flux.intervalMillis(0, 100).take(2), Flux.intervalMillis(50,100).take(2)).toStream().forEach(System.out::println);请注意,这里的第一个 intervalMillis 方法没有延迟,每隔 100 毫秒生成一个元素,而第二个 intervalMillis 方法则是延迟 50 毫秒之后才发送第一个元素,时间间隔同样是 100 毫秒。相当于两个数据序列会交错地生成数据,并合并在一起。所以以上代码的执行效果如下所示:
0
0
1
1
和 merge 类似的还有一个 mergeSequential 方法。不同于 merge 操作符,mergeSequential 操作符则按照所有流被订阅的顺序,以流为单位进行合并。现在我们来看一下这段代码,这里仅仅将 merge 操作换成了 mergeSequential 操作:
Flux.mergeSequential (Flux.intervalMillis(0, 100).take(2), Flux.intervalMillis(50,100).take(2)).toStream().forEach(System.out::println);执行以上代码,我们将得到不同的结果,如下所示 :
0
1
0
1
2.3.4 条件操作符
所谓条件操作符,本质上就是提供了一个判断的依据来确定是否处理流中的元素。Reactor 中常用的条件操作符有 defaultIfEmpty、takeUntil、takeWhile、skipUntil 和 skipWhile 等。
-
defaultIfEmpty
defaultIfEmpty 操作符针对空数据流提供了一个简单而有用的处理方法。该操作符用来返回来自原始数据流的元素,如果原始数据流中没有元素,则返回一个默认元素。
defaultIfEmpty 操作符在实际开发过程中应用广泛,通常用在对方法返回值的处理上。如下所示的就是在 Controller 层中对 Service 层返回结果的一种常见处理方法 。
@GetMapping("/orders/{id}") public Mono<ResponseEntity<Order>> findOrderById(@PathVariable String id) { return orderService.findOrderById(id) .map(ResponseEntity::ok) .defaultIfEmpty(ResponseEntity .status(404).body(null)); } -
takeUntil
takeUntil 操作符的基本用法是 takeUntil (Predicate predicate),其中 Predicate 代表一种断言条件,该操作符将从数据流中提取元素直到断言条件返回 true。takeUntil 的示例代码如下所示,我们希望从一个包含 100 个连续元素的序列中获取 1~10 个元素。
Flux.range(1, 100).takeUntil(i -> i == 10).subscribe(System.out::println); -
takeWhile
takeWhile 操作符的基本用法是 takeWhile (Predicate continuePredicate),其中 continuePredicate 代表的也是一种断言条件。与 takeUntil 不同的是,takeWhile 会在 continuePredicate 条件返回 true 时才进行元素的提取。takeWhile 的示例代码如下所示,这段代码的执行效果与 takeUntil 的示例代码一致。
Flux.range(1, 100).takeWhile(i -> i <= 10).subscribe(System.out::println); -
skipUntil/skipWhile
与 takeUntil 相对应,skipUntil 操作符的基本用法是 skipUntil (Predicate predicate)。skipUntil 将丢弃原始数据流中的元素直到 Predicate 返回 true。
同样,与 takeWhile 相对应,skipWhile 操作符的基本用法是 skipWhile (Predicate continuePredicate),当 continuePredicate 返回 true 时才进行元素的丢弃。这两个操作符都很简单,就不具体展开讨论了。
2.3.5 裁剪操作符
裁剪操作符通常用于统计流中的元素数量,或者检查元素是否具有一定的属性。在 Reactor 中,常用的裁剪操作符有 any、all、concat、reduce等
-
any操作符
any 操作符用于检查是否至少有一个元素具有所指定的属性,示例代码如下 :
Flux.just(3, 5, 7, 9, 11, 15, 16, 17) .any(e -> e % 2 == 0) .subscribe(isExisted -> System.out.println(isExisted)); -
all操作符
all 操作符,用来检查流中元素是否都满足同一属性,示例代码如下所示 :
lux.just("abc", "ela", "ade", "pqa", "kang") .all(a -> a.contains("a")) .subscribe(isAllContained -> System.out.println(isAllContained)); -
concat操作符
concat 操作符用来合并来自不同 Flux 的数据。与上一讲中所介绍的 merge 操作符不同,这种合并采用的是顺序的方式,所以严格意义上并不是一种合并操作,所以我们把它归到裁剪操作符类别中。 例如,如果执行下面这段代码,我们将在控制台中依次看到 1 到 10 这 10 个数字。
Flux.concat( Flux.range(1, 3), Flux.range(4, 2), Flux.range(6, 5) ).subscribe(System.out::println); }; -
reduce操作符
裁剪操作符中最经典的就是这个 reduce 操作符。reduce 操作符对来自 Flux 序列中的所有元素进行累积操作并得到一个 Mono 序列,该 Mono 序列中包含了最终的计算结果。reduce 操作符示意图如下所示:
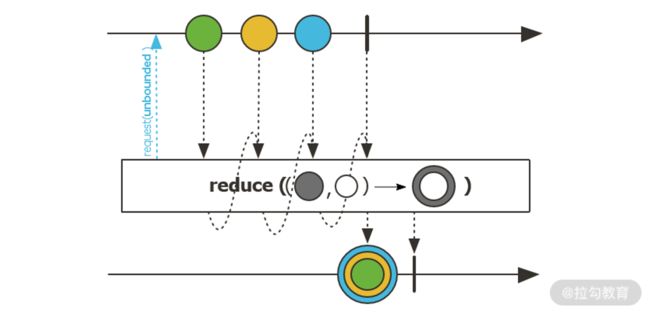
在上图中,具体的累积计算很简单,我们也可以通过一个 BiFunction 来实现任何自定义的复杂计算逻辑。reduce 操作符的示例代码如下所示,这里的 BiFunction 就是一个求和函数,用来对 1 到 10 的数字进行求和,运行结果为 55:
Flux.range(1, 10).reduce((x, y) -> x + y).subscribe(System.out::println);
2.3.6 工具操作符
Reactor 中常用的工具操作符有 subscribe、timeout、block、log 等
-
subscribe操作符
subscribe操作符我们在订阅流中已经介绍了,这里就不赘述了。
-
timeout操作符
timeout 操作符非常简单,保持原始的流发布者,当特定时间段内没有产生任何事件时,将生成一个异常
-
block操作符
block 操作符在接收到下一个元素之前会一直阻塞。block 操作符常用来把响应式数据流转换为传统数据流。 例如,使用如下方法将分别把 Flux 数据流和 Mono 数据流转变成普通的 List`` 对象和单个的 Order 对象,我们同样可以设置 block 操作的等待时间。
public List<Order> getAllOrders() {
return orderservice.getAllOrders()
.block(Duration.ofSecond(5));
}
public Order getOrderById(Long orderId) {
return orderservice.getOrderById(orderId)
.block(Duration.ofSecond(2));
}
-
log操作符
Reactor 中专门提供了针对日志的工具操作符 log,它会观察所有的数据并使用日志工具进行跟踪。我们可以通过如下代码演示 log 操作符的使用方法,在 Flux.just() 方法后直接添加 log() 函数。
Flux.just(1, 2).log().subscribe(System.out::println);以上代码的执行结果如下所示(为了显示简洁,部分内容和格式做了调整)。通常,我们也可以在 log() 方法中添加参数来指定日志分类的名称。
Info: | onSubscribe([Synchronous Fuseable] FluxArray.ArraySubscription)
Info: | request(unbounded)
Info: | onNext(1)
1
Info: | onNext(2)
2
Info: | onComplete()
三、Spring的响应式编程
2017 年,Spring 发布了新版本 Spring 5,这是从 Spring 4 发布以来将近 4 年的时间中所发布的一个全新版本。Spring 5 引入了很多核心功能,这其中重要的就是全面拥抱了响应式编程的设计思想和实践。
Spring 5 针对响应式编程构建了全栈式的开发组件。对于常见的应用程序而言,Web 服务层和数据访问层构成了最基本的请求链路。而 Spring 5 也提供了针对 Web 服务层开发的响应式 Web 框架 WebFlux,以及支持响应式数据访问的 Spring Data Reactive 框架。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y0o8A7F3-1692664892746)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1691541645767.png)]
3.1 SpringBoot WebFlux
Spring WebFlux 是 Spring Framework 5.0中引入的新的响应式web框架。与Spring MVC不同,它不需要Servlet API,是完全异步且非阻塞的,并且通过Reactor项目实现了Reactive Streams规范。
Spring WebFlux 用于创建基于事件循环执行模型的完全异步且非阻塞的应用程序。 (PS:所谓异步非阻塞是针对服务端而言的,是说服务端可以充分利用CPU资源去做更多事情,这与客户端无关,客户端该怎么请求还是怎么请求。)
webflux的关键是自己编写的代码里面返回流(Flux/Mono),spring框架来负责处理订阅。
3.1.1 核心依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webfluxartifactId>
dependency>
3.1.2 实战应用
想要使用 WebFlux 构建响应式服务的编程模型,开发人员有两种选择。第一种是使用基于 Java 注解的方式,这种编程模型与传统的 Spring MVC 一致;而第二种则是使用函数式编程模型。
-
注解方式
Spring WebFlux 与 Spring MVC 的不同之处,前者使用的类型都是 Reactor 中提供的 Flux 和 Mono 对象,而不是普通的 POJO。
@RestController public class HelloController { @GetMapping("/") public Mono<String> hello() { return Mono.just("Hello World!"); } } -
路由函数
Router Functions 则提供一套函数式风格的 API,其中最重要的就是 Router 和 Handler 接口。我们可以简单把 Router 对应成 RequestMapping,把 Controller 对应为 Handler。
@Configuration public class OrderRouter { @Bean public RouterFunction<ServerResponse> routeOrder(OrderHandler orderHandler) { return RouterFunctions.route( RequestPredicates.GET("/orders/{orderNumber}") .and(RequestPredicates.accept(MediaType.APPLICATION_JSON)), orderHandler::getOrderByOrderNumber); } } @Configuration public class OrderHandler { @Autowired private OrderService orderService; public Mono<ServerResponse> getOrderByOrderNumber(ServerRequest request) { String orderNumber = request.pathVariable("orderNumber"); return ServerResponse.ok().body(this.orderService.getOrderByOrderNumber(orderNumber), Order.class); } }
3.2 Spring Data Reactice Repositories
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MIISXM9j-1692664892746)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1691994507191.png)]
如图所示,如果某一个环节或步骤不是响应式的,就会出现同步阻塞,从而导致背压机制无法生效。如果某一层组件(例如数据访问层)无法采用响应式编程模型,那么响应式编程的概念对于整个请求链路的其他层而言就没有意义。在常见的 Web 服务架构中,最典型的非响应式场景就是数据访问层中使用了关系型数据库,因为传统的关系型数据库都基于非响应式的数据访问机制。为此,Spring家族中专门处理存储层的组件Spring Data Repositories也针对响应式编程除了一款Spring Data Repositories Reactive。
我们以 Spring Data Redis Reactive 组件为例。
3.2.1 核心依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-redis-reactiveartifactId>
dependency>
3.2.2 实战应用
Redis 不提供响应式存储库,ReactiveRedisTemplate 类是响应式 Redis 数据访问的核心工具类。 那么在Spring容器启动时,就需要将ReactiveRedisTemplate初始化到容器中。
@Configuration
public class RedisConfiguration {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private Integer port;
@Value("${spring.redis.password}")
private String password;
@Bean
public ReactiveRedisConnectionFactory reactiveRedisConnectionFactory() {
// 配置redis
RedisStandaloneConfiguration redisStandaloneConfiguration = new RedisStandaloneConfiguration();
redisStandaloneConfiguration.setHostName(host);
redisStandaloneConfiguration.setPort(port);
redisStandaloneConfiguration.setPassword(RedisPassword.of(password));
// 构建连接工厂
return new LettuceConnectionFactory(redisStandaloneConfiguration, LettuceClientConfiguration.builder().build());
}
@Bean
public RedisSerializationContext<String, Object> redisSerializationContext() {
RedisSerializationContext.RedisSerializationContextBuilder<String, Object> builder = RedisSerializationContext.newSerializationContext();
builder.key(StringRedisSerializer.UTF_8);
builder.value(RedisSerializer.json());
builder.hashKey(StringRedisSerializer.UTF_8);
builder.hashValue(StringRedisSerializer.UTF_8);
return builder.build();
}
@Bean
public ReactiveRedisTemplate<String, Object> reactiveRedisTemplate(ReactiveRedisConnectionFactory reactiveRedisConnectionFactory, RedisSerializationContext<String, Object> redisSerializationContext) {
return new ReactiveRedisTemplate<>(reactiveRedisConnectionFactory, redisSerializationContext);
}
}
那么我们只要在Repositories中调用这个ReactiveRedisTemplate即可。
@Repository
public class AccountRepositories implements IAccountRepositories {
/**
* redis存储的hashkey
*/
private static final String REDIS_HASH_KEY = "TABLE:ACCOUNT";
@Autowired
private ReactiveRedisTemplate<String, Object> reactiveRedisTemplate;
@Override
public Mono<Account> findById(String id) {
return reactiveRedisTemplate.opsForHash()
.get(REDIS_HASH_KEY, id)
.flatMap(accStr -> Mono.just(JSONUtil.toBean((String) accStr, Account.class)));
}
@Override
public Flux<Account> findByIds(Flux<String> ids) {
return null;
}
@Override
public Mono<Boolean> saveAccount(Mono<Account> accountMono) {
return accountMono.flatMap(account -> reactiveRedisTemplate.opsForHash().put(REDIS_HASH_KEY, account.getId(), JSONUtil.toJsonStr(account)));
}
@Override
public Mono<Boolean> deleteById(String id) {
return reactiveRedisTemplate.opsForHash().remove(REDIS_HASH_KEY, id).flatMap(count -> Mono.just(count == 1));
}
}
四、服务间调用
我们知道,在传统微服务生态中,服务之间的调用可以通过 Feign或者Retrofit等框架来实现,但是Feign或者Retrofit等框架并不支持响应式的编码,即它们都是同步阻塞的调用,我们上面说过,在整个调用链中,任何一个环节阻塞了都会导致响应式编码失效。
所以,Spring家族提供了WebClient来支持异步非阻塞的服务调用,WebClient是从Spring WebFlux 5.0版本开始提供的一个非阻塞的基于响应式编程的进行Http请求的客户端工具。它的响应式编程的基于Reactor的。WebClient中提供了标准Http请求方式对应的get、post、put、delete等方法,可以用来发起相应的请求。
4.1 创建 WebClient
创建 WebClient 有两种方法,一种是通过它所提供的 create() 工厂方法,另一种则是使用 WebClient Builder 构造器工具类。
- create() 工厂方法
WebClient webClient = WebClient.create();
- 构造器类 Builder
WebClient webClient = WebClient.builder().build();
4.2 使用WebClient
4.2.1 构造 URL
Web 请求中通过请求路径可以携带参数,在使用 WebClient 时也可以在它提供的 uri() 方法中添加路径变量和参数值。如果我们定义一个包含路径变量名为 id 的 URL,然后将 id 值设置为 100,那么就可以使用如下示例代码。
webClient.get().uri("http://localhost:8081/accounts/{id}", 100);
4.2.2 获取响应主体
-
retrieve方法
retrieve() 方法是获取响应主体并对其进行解码的最简单方法,我们再看一个示例,如下所示。
WebClient webClient = WebClient.create("http://localhost:8081"); Mono<Account> result = webClient.get() .uri("/accounts/{id}", id) .accept(MediaType.APPLICATION_JSON) .retrieve() .bodyToMono(Account.class); -
exchange方法
如果希望对响应拥有更多的控制权,retrieve() 方法就显得无能为力,这时候我们可以使用 exchange() 方法来访问整个响应结果,该响应结果是一个 ClientResponse 对象,包含了响应的状态码、Cookie 等信息,示例代码如下所示。
Mono<Account> result = webClient.get() .uri("/accounts/{id}", id) .accept(MediaType.APPLICATION_JSON) .exchange() .flatMap(response -> response.bodyToMono(Account.class));
L
Web 请求中通过请求路径可以携带参数,在使用 WebClient 时也可以在它提供的 uri() 方法中添加路径变量和参数值。如果我们定义一个包含路径变量名为 id 的 URL,然后将 id 值设置为 100,那么就可以使用如下示例代码。
webClient.get().uri("http://localhost:8081/accounts/{id}", 100);
4.2.2 获取响应主体
-
retrieve方法
retrieve() 方法是获取响应主体并对其进行解码的最简单方法,我们再看一个示例,如下所示。
WebClient webClient = WebClient.create("http://localhost:8081"); Mono<Account> result = webClient.get() .uri("/accounts/{id}", id) .accept(MediaType.APPLICATION_JSON) .retrieve() .bodyToMono(Account.class); -
exchange方法
如果希望对响应拥有更多的控制权,retrieve() 方法就显得无能为力,这时候我们可以使用 exchange() 方法来访问整个响应结果,该响应结果是一个 ClientResponse 对象,包含了响应的状态码、Cookie 等信息,示例代码如下所示。
Mono<Account> result = webClient.get() .uri("/accounts/{id}", id) .accept(MediaType.APPLICATION_JSON) .exchange() .flatMap(response -> response.bodyToMono(Account.class));