HadoopHA部署(1+x)
目录
打开已创建好的centOS虚拟机
配置网络
测试网络(内网、外网都要测试)
关机并克隆
启动三台机器,并为克隆的两台机器修改相应名称和IP,以及检测内外网,修改完后重启(init 6),使主机名生效
重启后连接xshell(三台虚拟机都要连接)
回到master1-1,下载lrzsz,传输文件(两种)
配置环境变量
ssh免密登录
配置zookeeper
配置Hadoop
初始化(顺序不能乱)
修改主机(Windows)的hosts文件(不修改无法用主机名登录)
打开网页
打开已创建好的centOS虚拟机
-
配置网络
1.vi 打开网络配置文件

2.修改配置文件
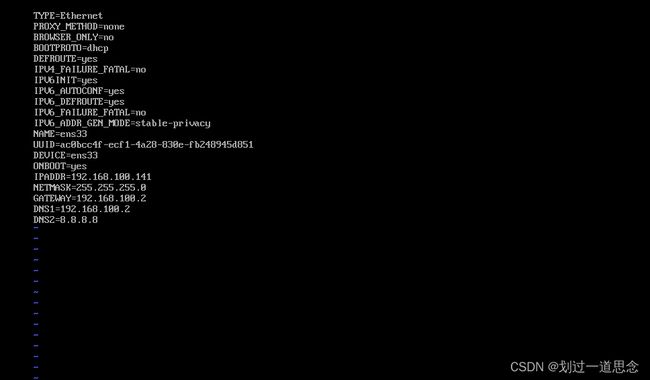
3.重启网络

-
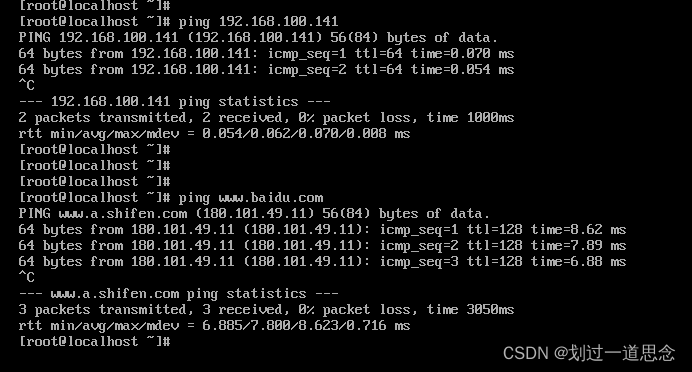
测试网络(内网、外网都要测试)
- 修改主机名和映射
1.修改主机名(两种方法)
第一种


第二种
使用命令hostnamectl set-hostname master1-1(主机名),并用bash生效
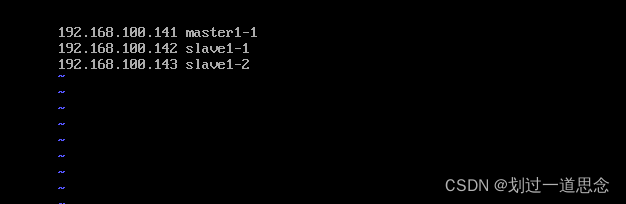
2.映射(因为考试时要求是三台虚拟机,映射都要写,另外两台虚拟机的IP在克隆完master1-1时要修改)

-
关机并克隆

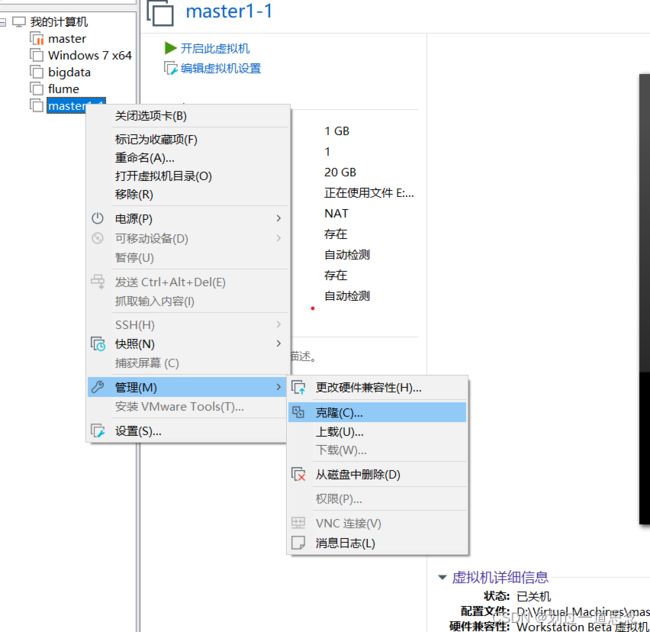

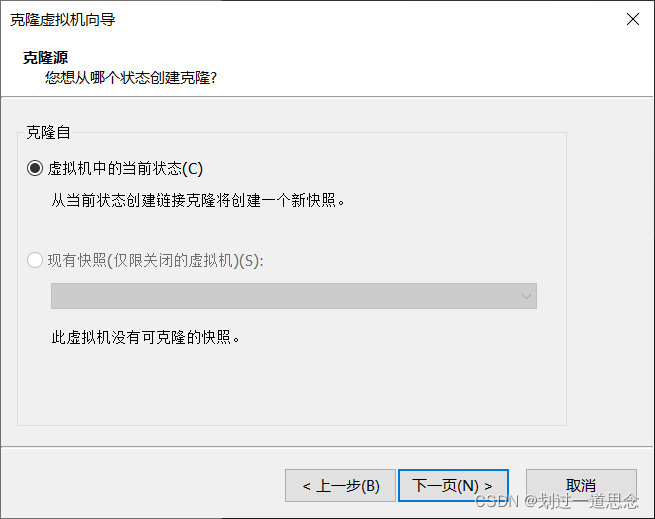
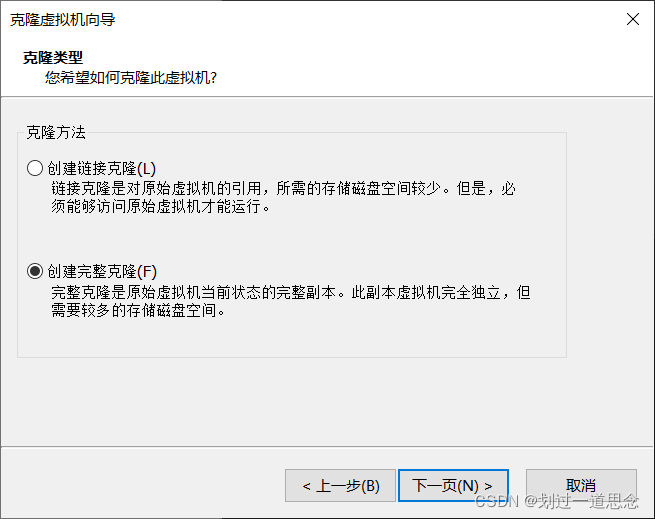
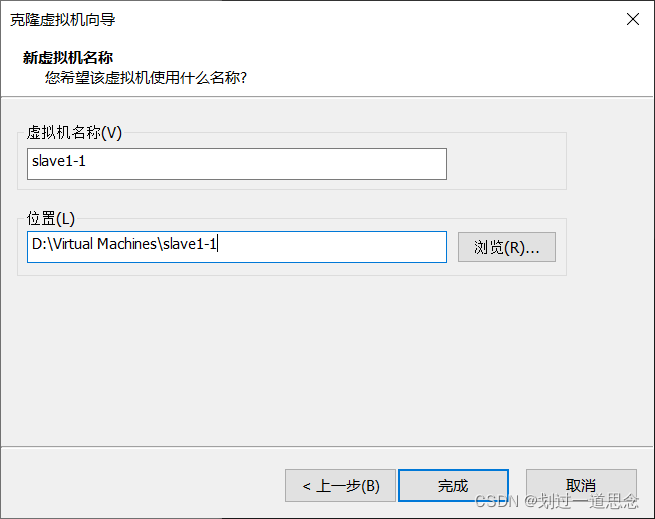
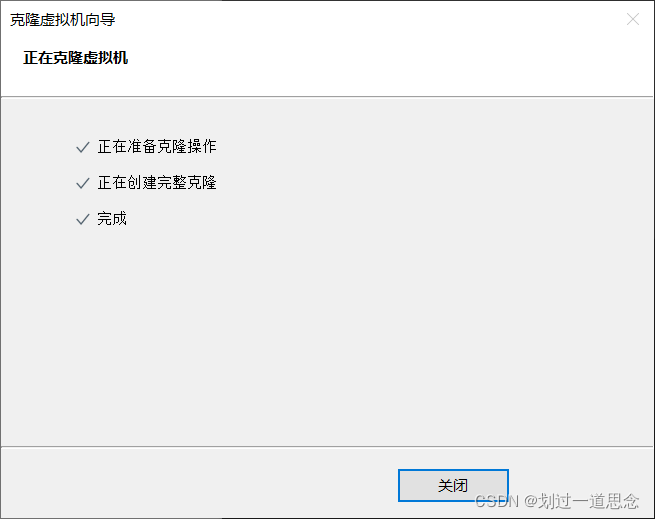
如上图操作在克隆一台虚拟机slave1-2
-
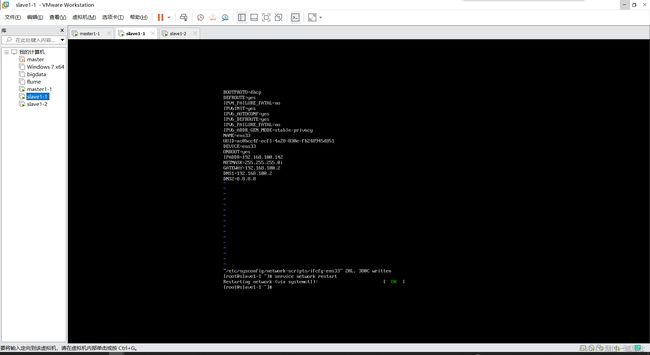
启动三台机器,并为克隆的两台机器修改相应名称和IP,以及检测内外网,修改完后重启(init 6),使主机名生效
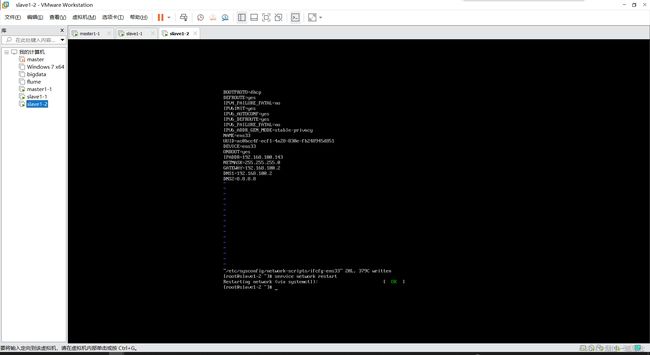
-
重启后连接xshell(三台虚拟机都要连接)
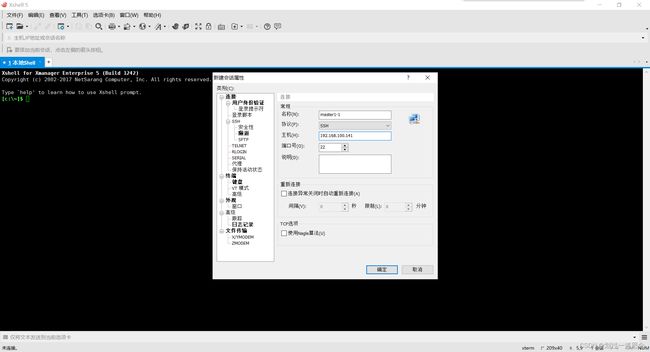
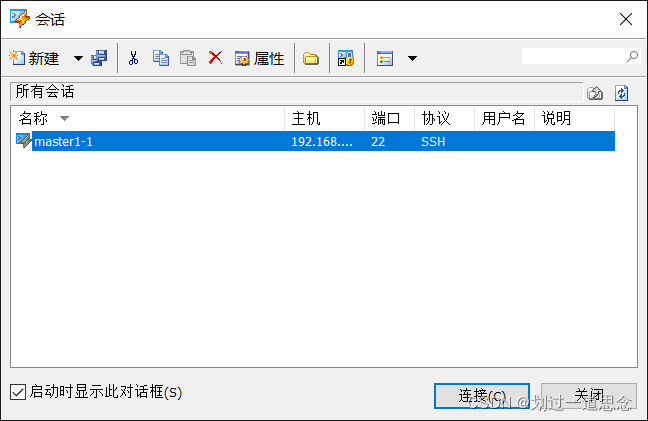
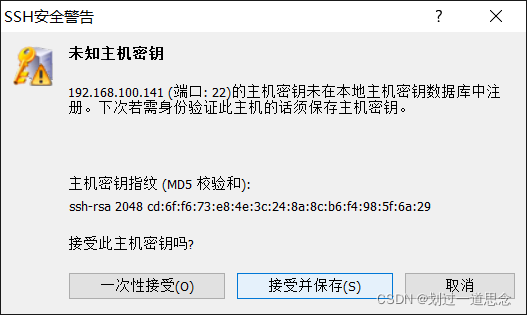
-
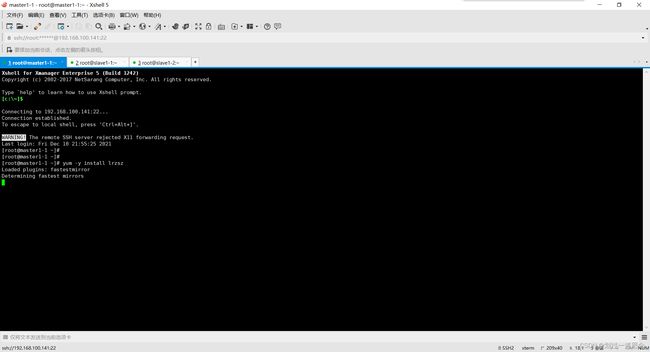
回到master1-1,下载lrzsz,传输文件(两种)
- 第一种
按照要求:在/usr/local/src/下新建文件夹h3cu,此文件夹用于存放传输的文件

使用rz命令在h3cu下传输文件


按住ctrl选择以下包,点击打开
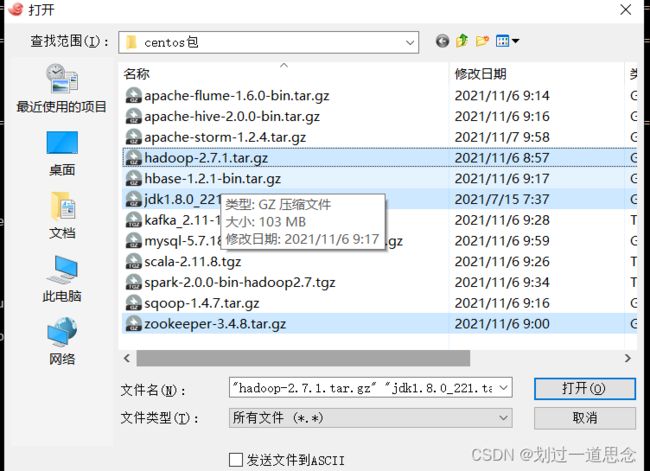
传输时乱码或毫无动静,则取消后再传一次
文件传输成功

第二种
打开xftp并连接

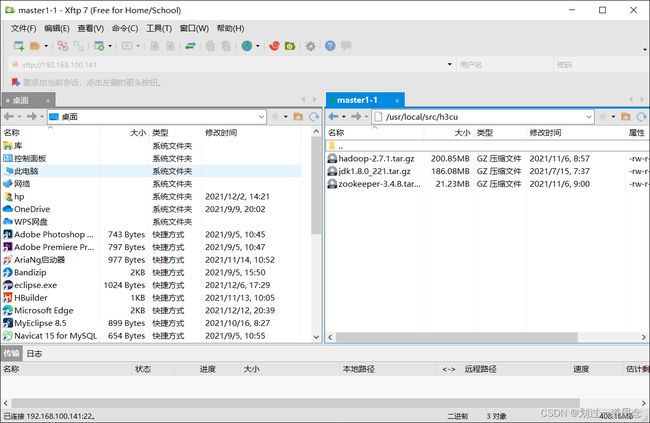

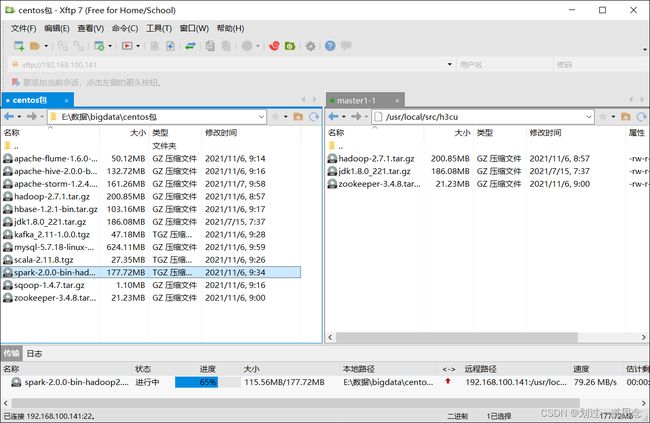
- 将传输的包分别解压到相应位置,并修改名称





-
配置环境变量
-
(环境变量配置错误后生效,许多命令无法使用,则输入export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin ,使其环境变量可修改)
-

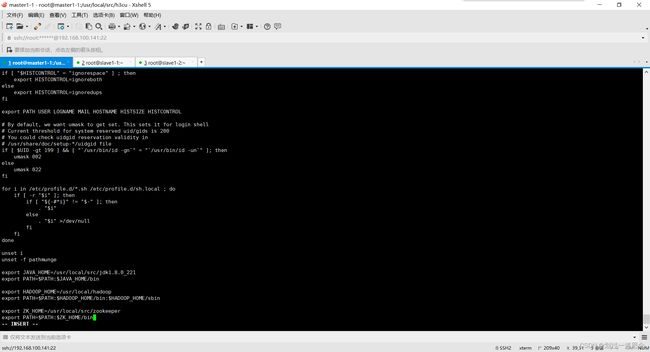
Source一下使环境变量生效

检查Java版本,检测环境变量是否生效

ssh免密登录
查看是否已安装ssh服务
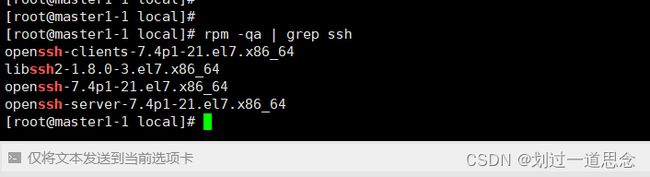
使用yum进行安装ssh服务

查看ssh进程

生成密钥
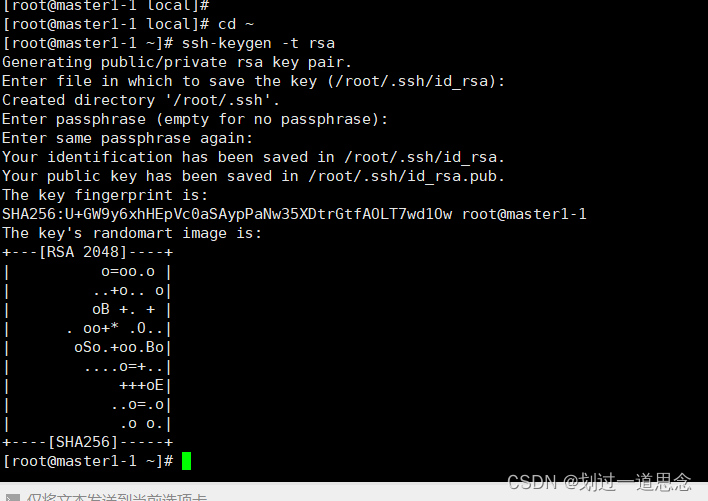
分发密钥
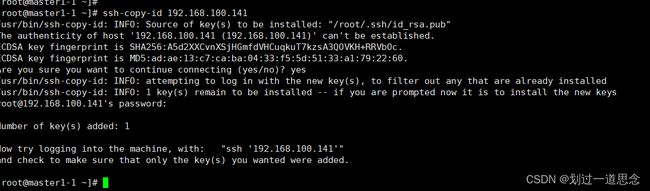
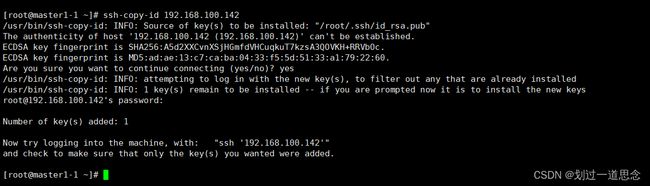
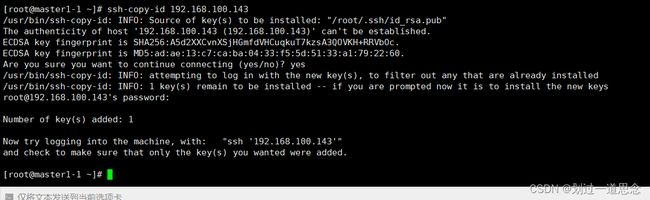
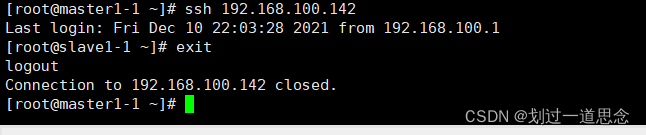
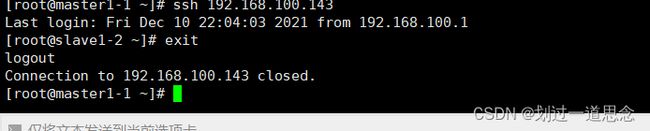
检验登录

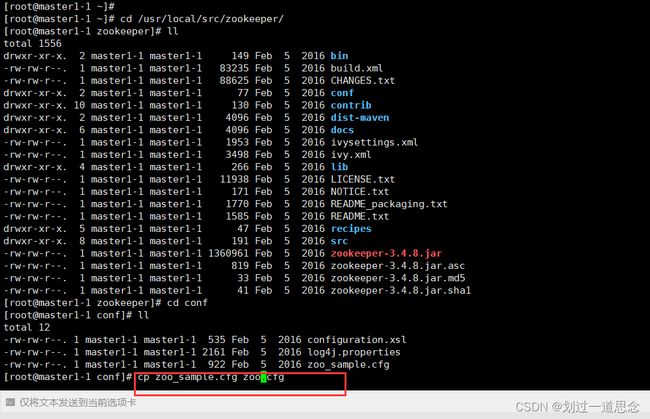
配置zookeeper
复制并改名
编辑文件

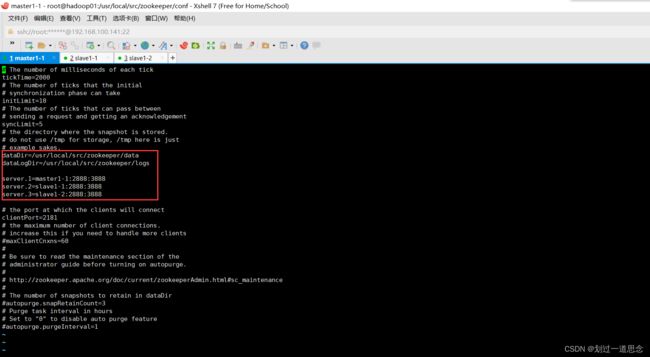
建相关文件夹
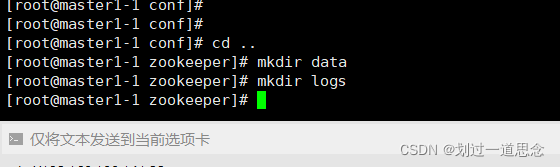
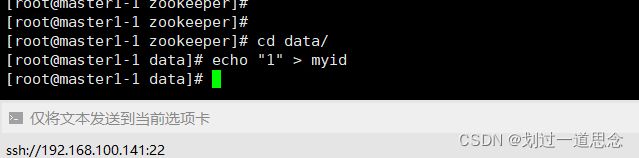
在/usr/local/src/zookeeper/data下编辑myid
分发jdk
![]()

分发zookeeper


分发环境变量


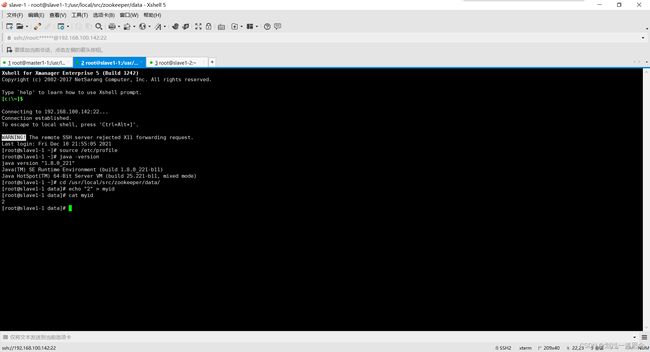
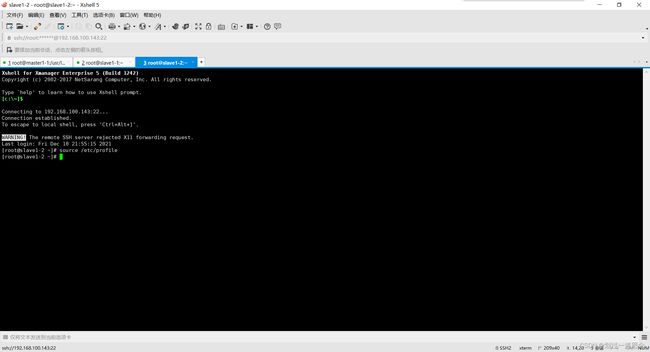
在克隆的机器里source一下,并检查Java
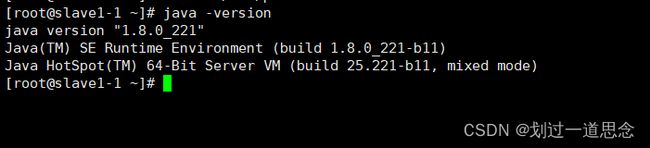
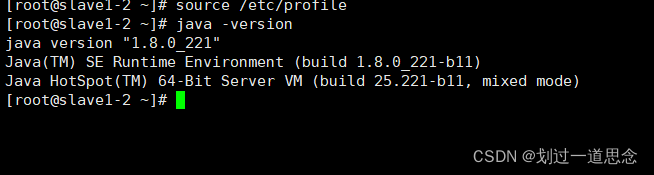
分别到克隆的机器更改myid

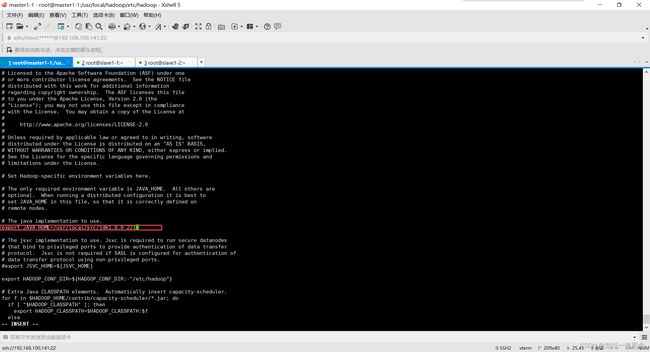
配置Hadoop

hadoop-env.sh
core-site.xml
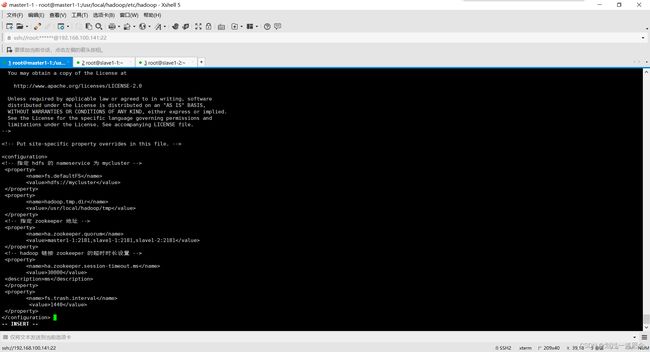
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/usr/local/hadoop/tmp
ha.zookeeper.quorum
master1-1:2181,slave1-1:2181,slave1-2:2181
ha.zookeeper.session-timeout.ms
30000
ms
fs.trash.interval
1440
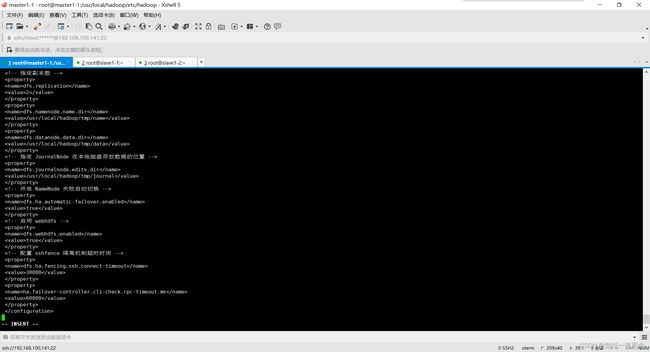
hdfs-site.xml
dfs.qjournal.start-segment.timeout.ms
60000
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
master1-1,slave1-1
dfs.namenode.rpc-address.mycluster.master1-1
master1-1:9000
dfs.namenode.rpc-address.mycluster.slave1-1
slave1-1:9000
dfs.namenode.http-address.mycluster.master1-1
master1-1:50070
dfs.namenode.http-address.mycluster.slave1-1
slave1-1:50070
dfs.namenode.shared.edits.dir
qjournal://master1-1:8485;slave1-1:8485;slave1-2:8485/mycluster
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
shell(/bin/true)
dfs.permissions.enabled
false
dfs.support.append
true
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.replication
2
dfs.namenode.name.dir
/usr/local/hadoop/tmp/name
dfs.datanode.data.dir
/usr/local/hadoop/tmp/data
dfs.journalnode.edits.dir
/usr/local/hadoop/tmp/journal
dfs.ha.automatic-failover.enabled
true
dfs.webhdfs.enabled
true
dfs.ha.fencing.ssh.connect-timeout
30000
ha.failover-controller.cli-check.rpc-timeout.ms
60000
mapred-site.xml
![]()
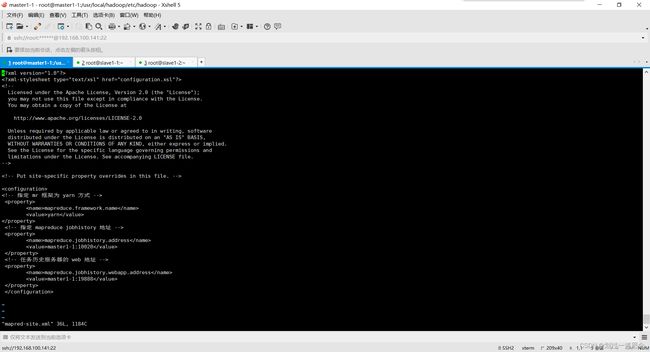
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master1-1:10020
mapreduce.jobhistory.webapp.address
master1-1:19888
yarn-site.xml
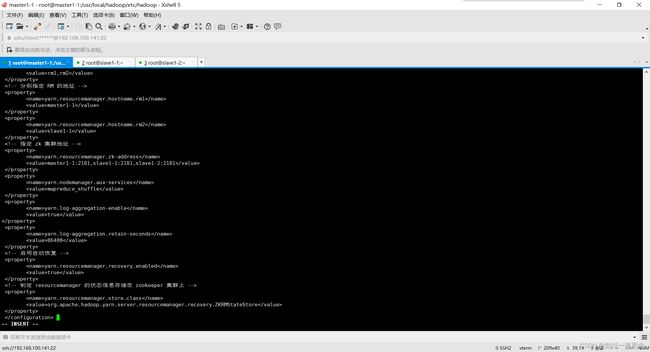
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
master1-1
yarn.resourcemanager.hostname.rm2
slave1-1
yarn.resourcemanager.zk-address
master1-1:2181,slave1-1:2181,slave1-2:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
86400
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
Slaves
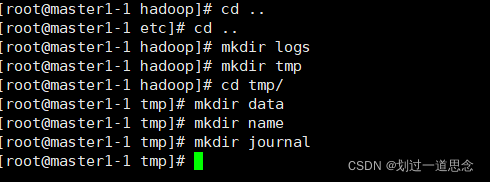
建立相关文件
分发Hadoop
![]()

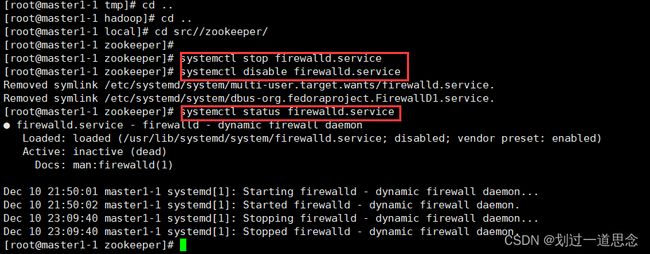
启动zookeeper(三台都要关闭)
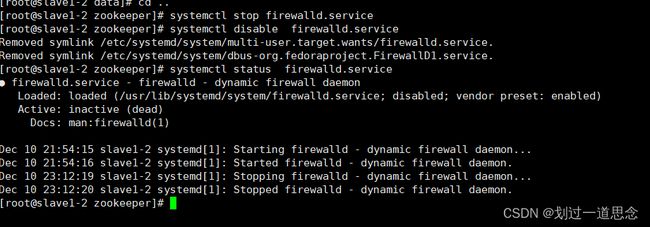
关闭防火墙(顺序:1.关闭防火墙 2.禁用防火墙 3.查看防火墙状态)
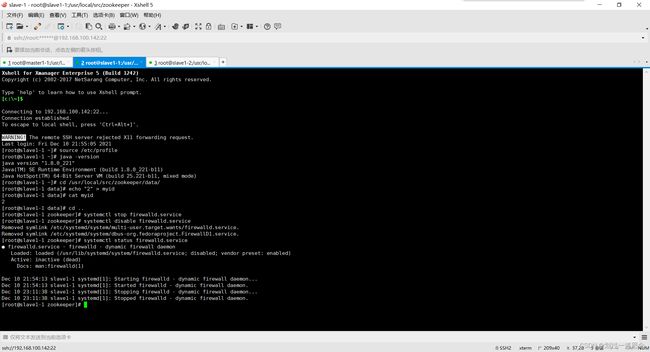
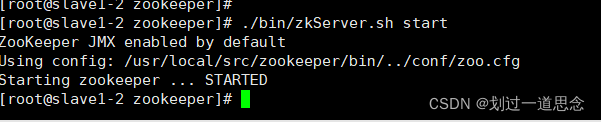
三台机器先启动再检查状态(顺序不能乱)
启动


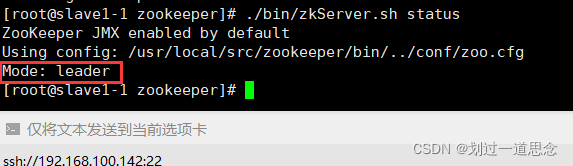
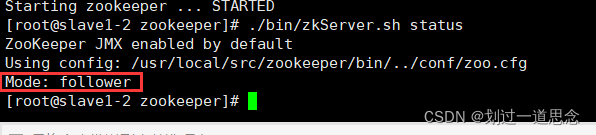
检查状态(两个follwer,一个leader)

初始化(顺序不能乱)
初始化HA在zookeeper中的状态(master1-1)

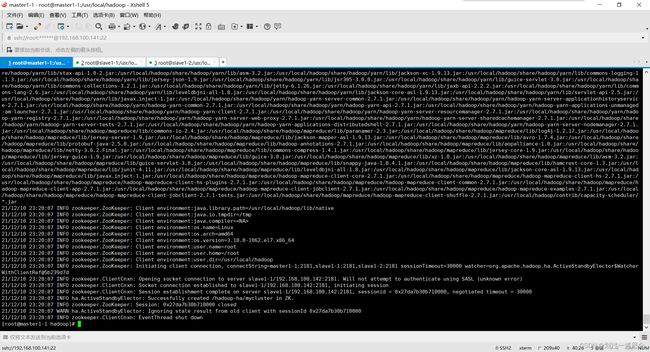
启动journalnode进程(三台机器)



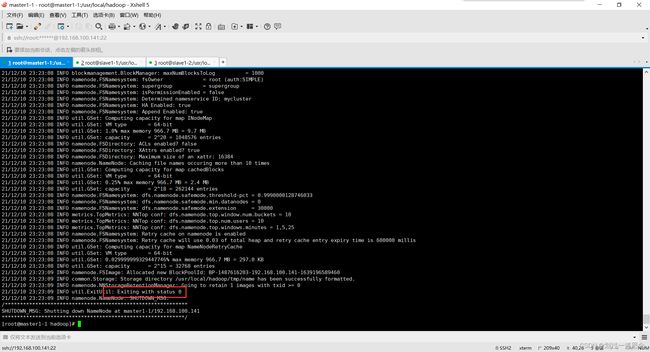
初始化namenode(master1-1)
![]()
状态为0表示成功
启动Hadoop

查看进程(三台)
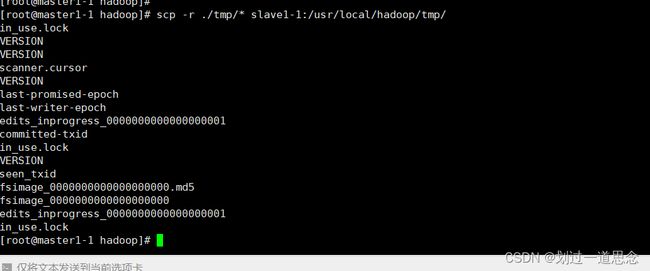
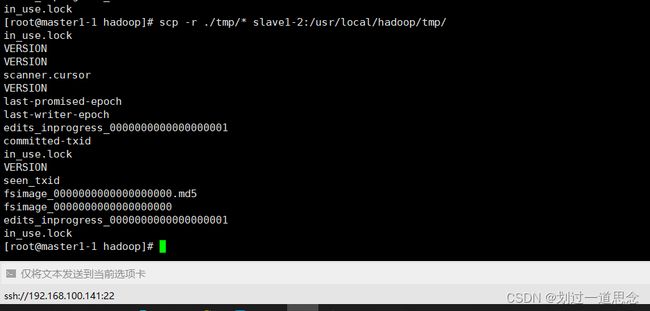
分发tmp文件
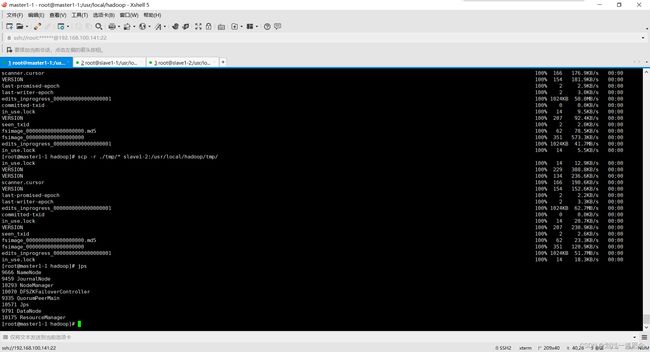
在slave1-1下启动resourcemanager和namenode进程


查看jps(master1-1和slave1-1)
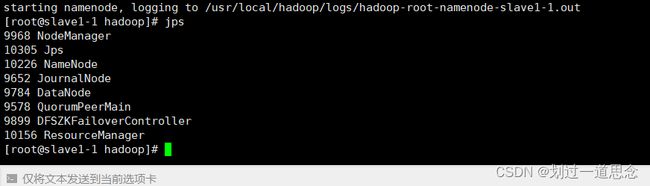
修改主机(Windows)的hosts文件(不修改无法用主机名登录)
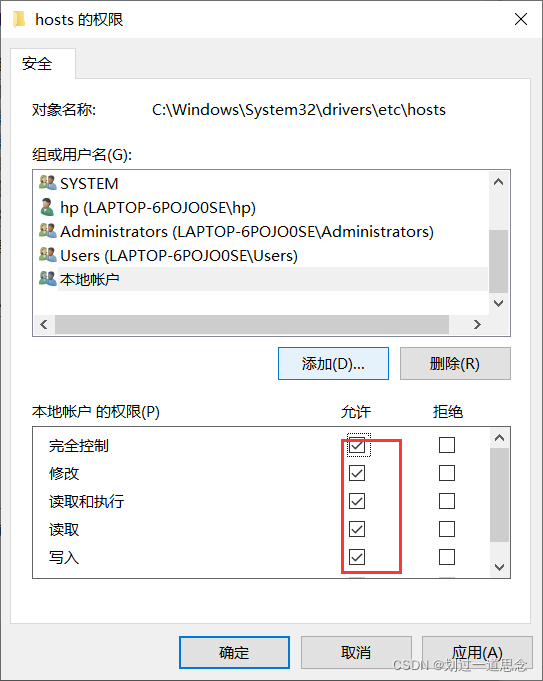
两种方法:1.DOS命令修改 2.图像界面下修改权限(若无权限无法保存)
- win+r打开cmd
按ctrl+shift+回车进入管理员界面
进入目录,并用记事本打开hosts
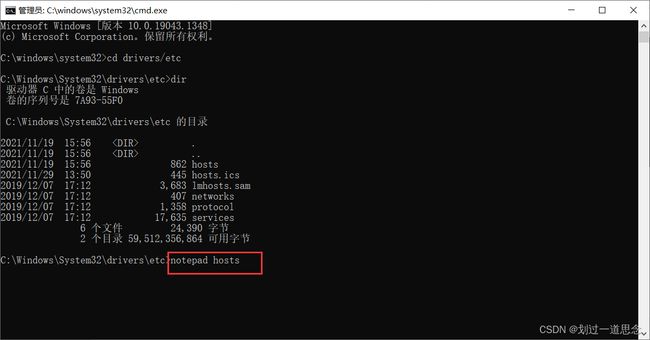
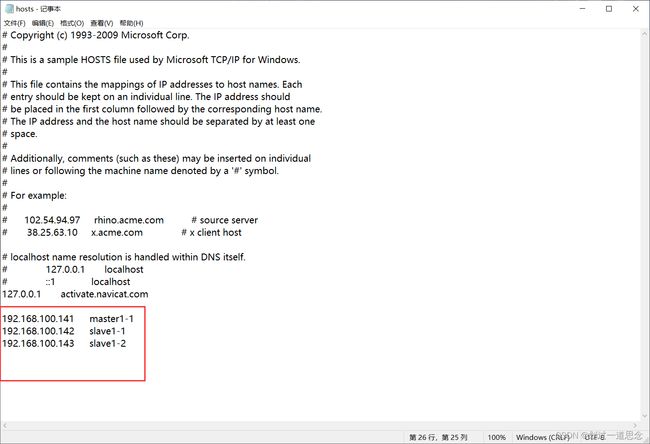
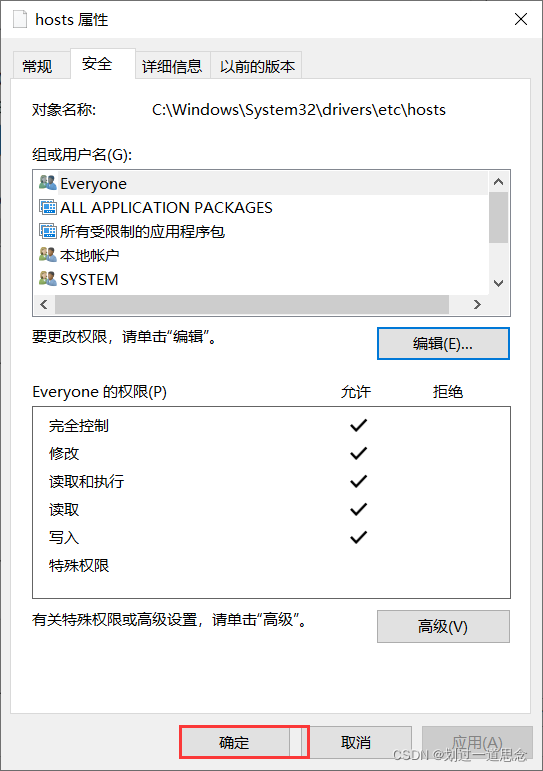
修改并保存
- 进入C:\Windows\System32\drivers\etc目录下找到hosts文件
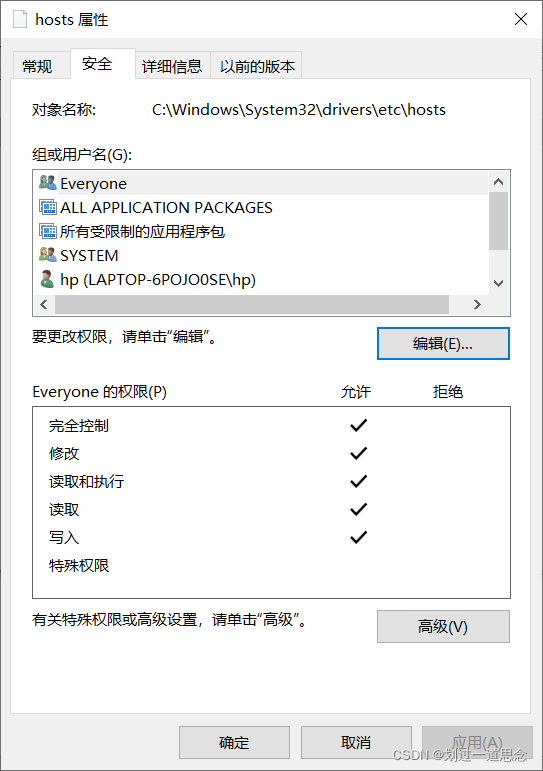
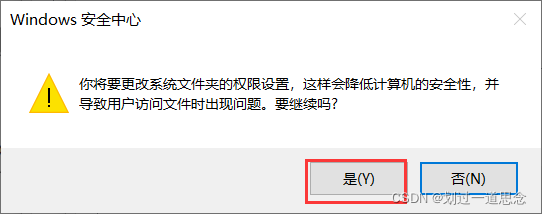
更改hosts文件的属性,使其可以修改内容
右击——属性

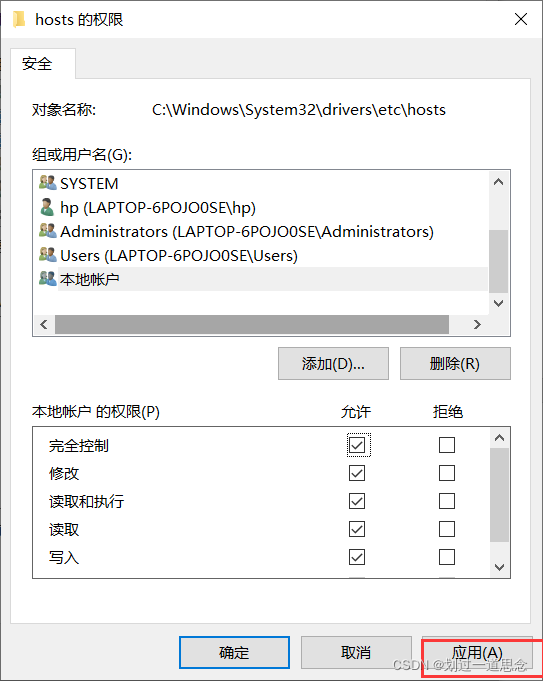
安全——编辑
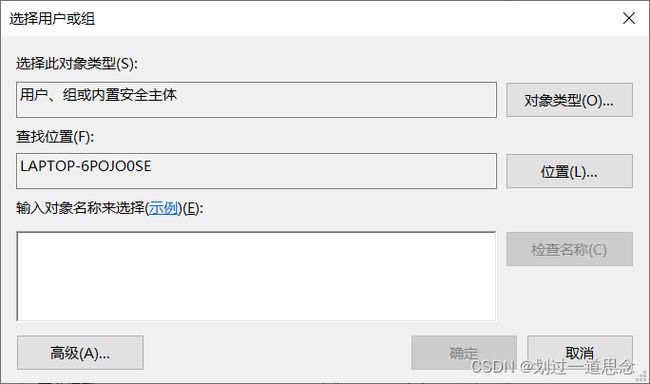
添加
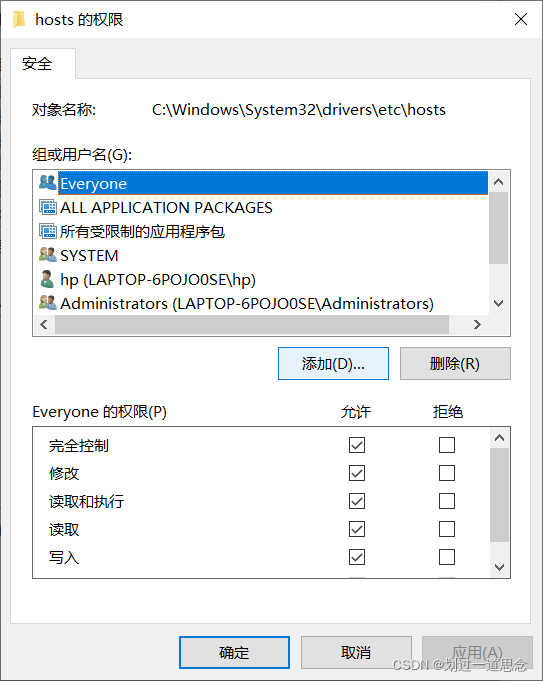
高级
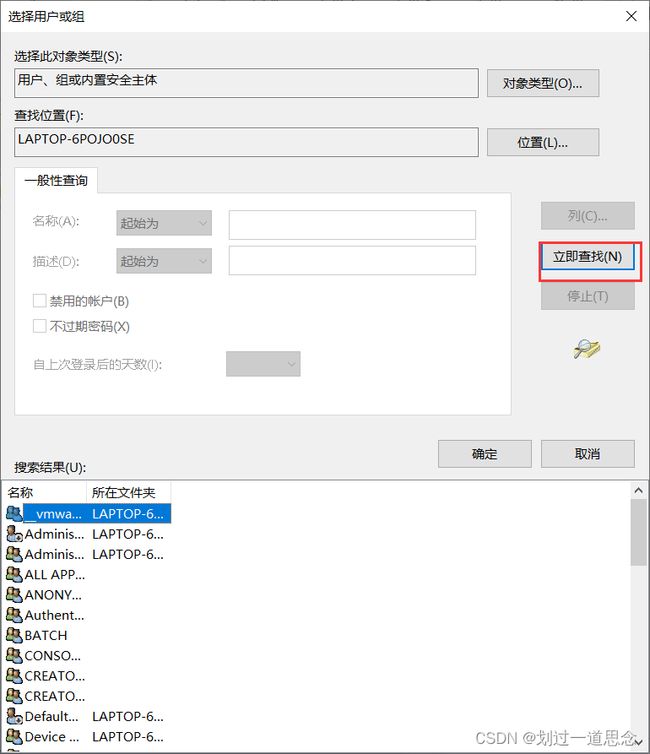
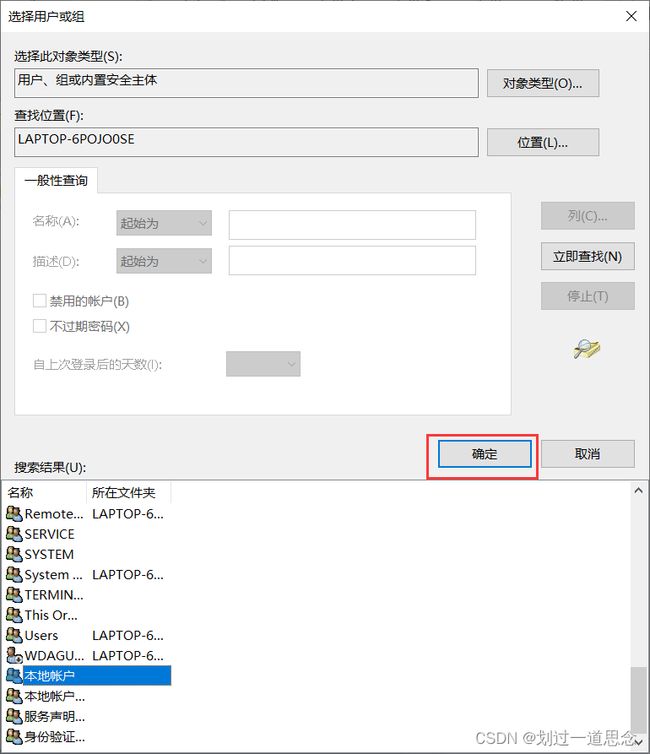


编辑文件
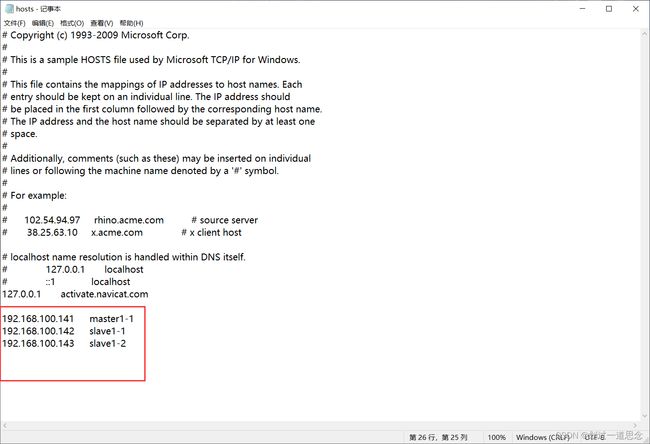
打开网页
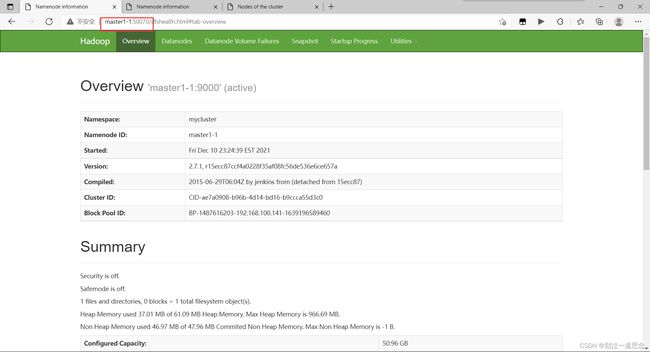
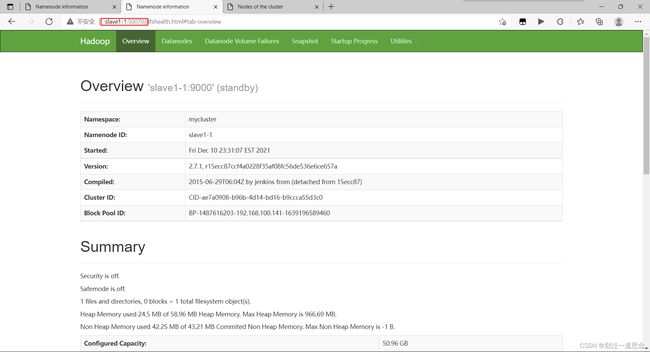
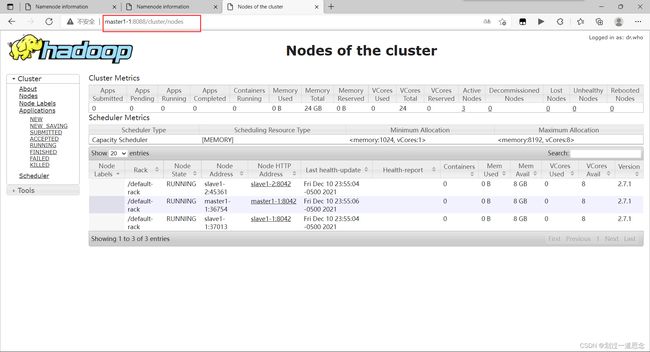
十八、杀死active的namenode
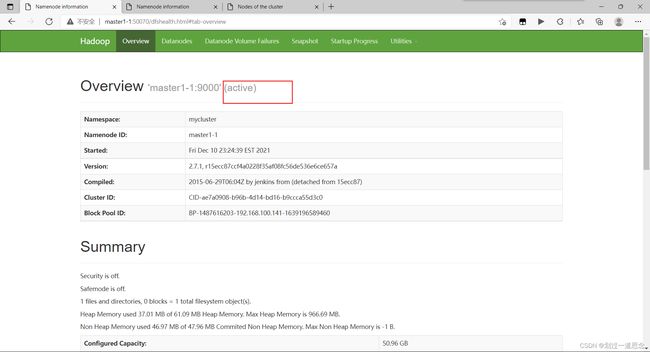
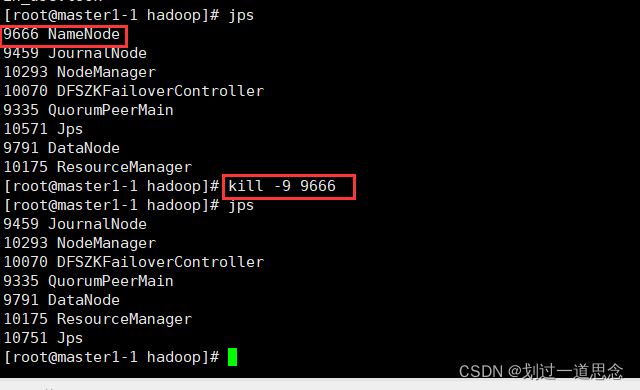
刷新页面
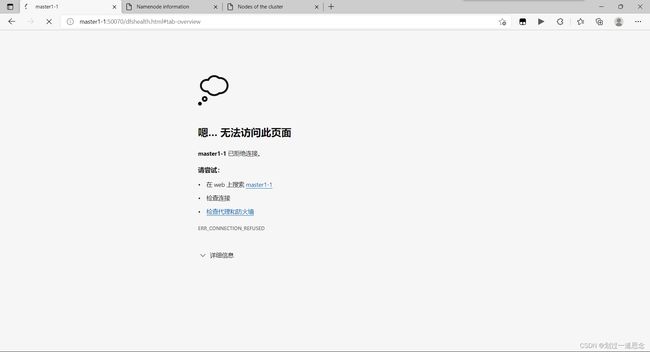
重启namenode
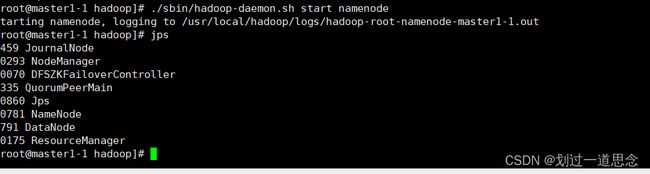
刷新页面(active变为standby)
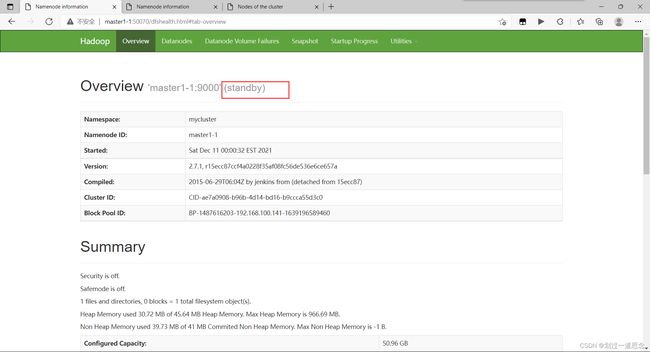
至此HadoopHA部署完成