Chrome代码分析(二)——EscapeAnalysisPhase
Chromium Code
EscapeAnalysis
当v8在处理js代码时通常会将其转化为字节码进行执行,在遇到热点函数时会用Turbofan将其优化转换为JIT代码来执行以此来提高代码执行效率,Turbofan使用了“Sea of Nodes”的概念它将对象及其一些操作与控制流视作节点(node)然后由这些节点组成图,当Turbofan生成机器码时会先进行优化,优化有多个阶段每个阶段会针对这些节点进行优化将不必要的冗余节点优化简略,EscapeAnalysis(逃逸分析)就是众多阶段之一。
逃逸分析总结来讲就是用来分析js代码中产生对象作用域的一种机制,假设有以下代码:
function foo(){
let a = {x:0, y:1};
return a;
}
let b = foo();
此代码中的对象a就属于逃逸对象,由于逃逸对象在函数执行完毕后不会被回收所以逃逸分析阶段不会去优化简略逃逸对象。对代码进行一些修改:
function foo(){
let a = {x:0, y:1};
a.x = a.x + a.y;
return a.x * a.y;
}
let b = foo();
以上代码经过优化后等同于:
function foo(){
return (0 + 1)*1;
}
let b = foo();
IR图:

对于以上代码由于对象a未逃逸其作用域仅限于函数内所以将其优化删除。
逻辑代码分析
逻辑流程
逃逸分析阶段代码逻辑大致分为三步:
EscapeAnalysis====>EscapeAnalysisResult====>EscapeAnalysisReducer
- EscapeAnalysis:执行逃逸分析算法逻辑,负责标记节点是否为逃逸(escaped_)。
- EscapeAnalysisResult:保存逃逸分析结果,EscapeAnalysisTracker的包装类,里面保存逃逸的节点。
- EscapeAnalysisReducer:将逃逸分析结果应用到图中(Node Graph),将非逃逸对象从图中删除实际上就是将节点从图中孤立出来,将其value置为其node本身再将其effect和control都置为nullptr。
EscapeAnalysis
此阶段从EscapeAnalysisPhase::Run函数开始:
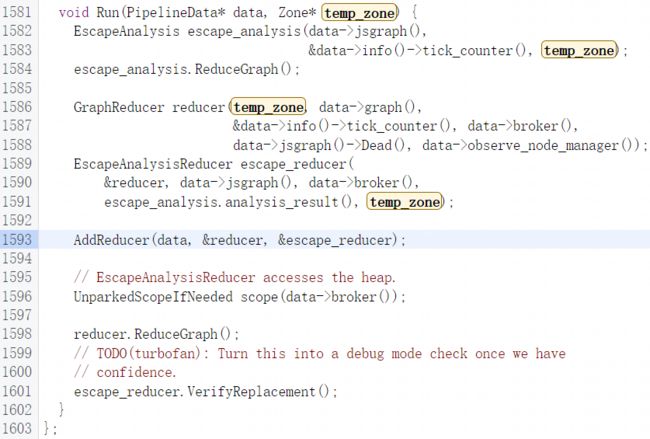
先创建EscapeAnalysis对象,EscapeAnalysis构造函数中主要就是用函数参数来初始化结构成员。

随后执行ReduceGraph函数,ReduceGraph会去调用ReduceFrom函数并将图中根节点传入:
![]()
此处涉及到一个graph对象,此对象是图对象,该对象通过end函数可以获取到图中末尾的end节点,同时对应的还有一个start函数用于获取获取start节点,一个zone函数获取zone对象。

ReduceFrom函数采用DFS(深度优先)算法从根节点开始遍历图:

先将根节点压入栈中,当栈不为空时去判断其input_index是否小于当前节点子节点个数,input_index为当前节点所依赖节点的下标,假设当前节点有两个子节点那该节点就有两个依赖节点,左子节点index为0,右子节点为1。随后根据input_index来获取依赖节点并将input_index+1以便处理下一个依赖节点。

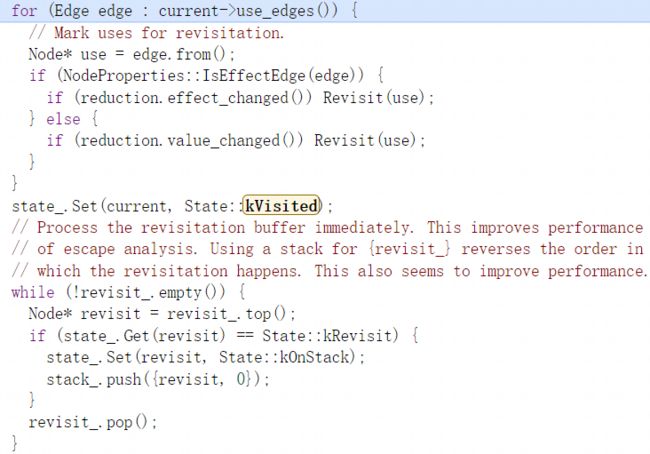
随后是一个switch,此开关语句通过节点state来判断如何处理input,当为前两个分支时不做处理原因在注释中说明,当为后两个分支时先将input状态置为kOnStack表示当前节点已在栈中,然后将input压入栈以便在下一次循环时访问当前input的依赖子节点进行处理。

随后按照循环继续运行,当当前节点的依赖节点都遍历完后,就会进行优化处理,先将节点从栈中弹出,随后进入相应的reduce函数对节点进行优化分析处理。

执行完优化分析后再通过use_edges函数获取输出边并处理此边(edge),关于use_edges函数可查看node结构分析中关于edge边的部分,之后通过边来调用from函数获取依赖于current节点的的节点,也就是把current节点作为input的节点。随后判断edge是否是效果边,如果是就在去判断effect_changed_标记是否为真,如果为真的话就表示需要重新进行访问处理,所以就需要调用Revisit函数将use节点状态设为kVisited,如果不为效果边就默认视为值边,并判断value_changed_标记是否为真,如果为真就将use节点状态设为kVisited与效果边处理相同。
 然后再来回头看看相应的优化分析处理函数观察其定义可以看出是一个函数指针
然后再来回头看看相应的优化分析处理函数观察其定义可以看出是一个函数指针![]()
![]()
通过调试可知此处实际会去调用EscapeAnalysis::Reduce函数,此函数先获取节点的op_,然后用node与reduction初始化EscapeAnalysisTracker::Scope对象,最后再去调用ReduceNode函数:

ReduceNode函数会根据节点的opcode进行相应的处理。
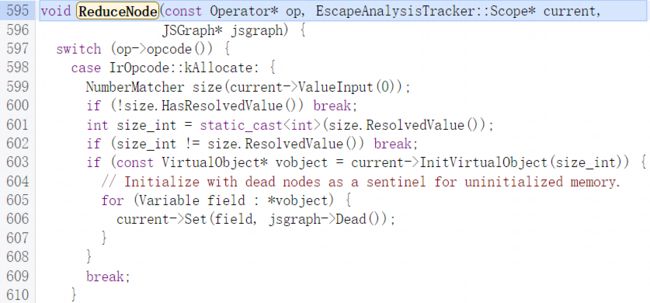
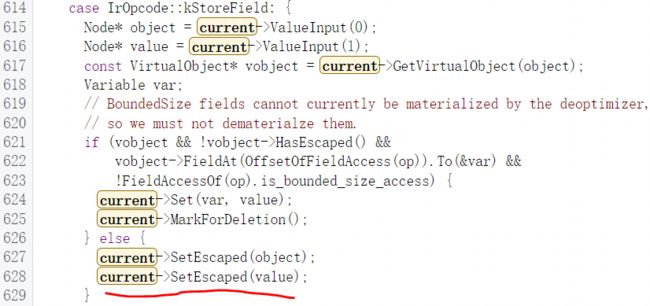
ReduceNode函数的一个主要作用就是通过一些条件去分析判断节点是否是逃逸的,如果是就调用setEscaped函数将其相关的一些节点的VirtualObject标记为逃逸。

当然对于一些特殊的节点也会有一些特殊的操作,由于节点类型比较多此处不去一一的说明分析。此处就以Allocate节点为例来进行说明,此节点主要处理对象创建,所有创建的对象都先会通过Allocate节点处理分支为其分配临时内存,具体的处理函数就是InitVirtualObject,对于刚通过allocate节点分配的临时内存先用Dead节点进行初始化,在后期的节点处理分支中会为分配的临时内存设置具体的节点并决定是否将其设为逃逸:


EscapeAnalysisResult
至此就执行完了逃逸分析的算法流程,分析完的结果会通过一个EscapeAnalysisResult对象返回,EscapeAnalysisResult对象实际上就是tracker的封装类:

tracker对象在EscapeAnalysis对象创建时创建并初始化:

也就是说实际的分析结果保存在tracker对象中。
![]()
EscapeAnalysisReducer
逃逸分析完成后会去创建GraphReducer与EscapeAnalysisReducer对象,GraphReducer对象用于操作图将优化应用到图中,EscapeAnalysisReducer对象用于保存各项用于优化的各项数据例如EscapeAnalysisResult。

之后会去调用AddReducer函数:
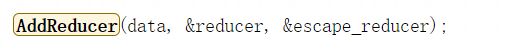
该函数会再去调用GraphReducer对象的成员函数AddReducer:
 GraphReducer::AddReducer函数将escape_reducer优化对象压入GraphReducer的优化列表:
GraphReducer::AddReducer函数将escape_reducer优化对象压入GraphReducer的优化列表:

随后会去调用GraphReducer::ReduceGraph函数,GraphReducer::ReduceGraph会去调用GraphReducer::ReduceNode函数并将图中的末尾根节点传入:
![]()
![]()
ReduceNode函数也会去遍历图中节点,与前面的ReduceFrom函数一样也使用DFS算法进行遍历处理的逻辑也基本一致:
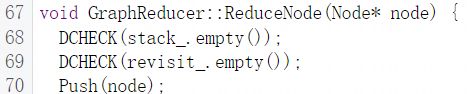
先将末尾节点压入栈,随后进入循环,当节点处理栈不为空时去执行ReduceTop函数此函数主要用来对图进行操作此函数比较重要先简单略过,详细说明会放在后面:

继续往下当栈为空时先判断用于存放需要重新访问的节点的列表(revisit_)是否为空,如果不为空就需要再去判断节点状态是否为kRevisit,如果是就将其压入节点处理栈,并将节点从revisit_列表中弹出:

当节点处理栈与revisit_列表都为空时,说明所有节点都已经处理完毕,然后获取在前面通过AddReducer函数压入优化列表的Reducer对象,由于该阶段是逃逸分析阶段所以此处获取到的应该是EscapeAnalysisReducer对象,然后去调用EscapeAnalysisReducer对象的成员函数Finalize:

通过代码可知此函数主要用于处理ArgumentsElements节点,搜先会去遍历获取收录在arguments_elements_列表里的所有ArgumentsElements节点并将其保存在node中,如果node的第一个(index为0)input不为kArgumentsLength就阻断后续步骤的执行重新循环,如果是就获取到arguments_length节点继续执行:

如果是ArgumentsLength就去遍历获取ArgumentsLength节点的所有use边,然后对每条边都会先通过from函数获取依赖此节点的节点,此处姑且就将其称为output当然这种叫法并不是很正确,然后判断其output是否是指定的几个类型,如果是就将arguments_length节点更新为ArgumentsLengthState节点。

之后依然是去获取所有的use边,只不过是ArgumentsEelement节点node的所有use边:

随后依然通过from函数获取所有依赖于ArgumentsEelement node的节点,此处将该节点也成为output,随后判断当前edge是否是value edge或者是否不为空,如果不是value edge或者edge为空的话就阻断后续流程获取下一个edge。

如果流程不被阻断的话就会根据output的op进入不同的分支进行处理,这些分支的处理主要目的就是为了将需要优化的节点放入loads列表中,对于StateValues、TypedStateValue、ObjectState、TypedObjectState节点不做处理,对于LoadElement节点会先去判断其mapped_count是否为0,mapped_count大致就是用来标记节点的引用次数,如果是就说明此节点不再被使用就将其放入loads列表中以备之后将其优化,否则就将escaping_use设为true表示不能将此节点优化或者删除,对于LoadField节点先获取字段的访问描述符再通过该描述符获取offset并于FixedArray::kLengthOffset进行比较,如果相同就代表需要将节点存入loads列表中,否则就将escaping_use设为true,对于其他节点一律将escaping_use设为true:

然后去判断escaping_use标志,当为false时先创建ArgumentsElementsState节点,并用ArgumentsElementsState节点去替换node也就是ArgumentsElements节点:

然后通过循环从loads列表中去除需要处理的节点,并根据节点的opcode进入不同的分支进行处理:

当load为LoadField节点时,就获取之前获取过的ArgumentsLength节点,并用ArgumentsLength节点去替换LoadField节点并将LoadField节点从图中去除:

当load为LoadElements节点时,将LoadElements节点替换为LoadStackArgument节点,并将第一个与第二个input分别替换为ExternalPointer与用NumberAdd函数获取的推测值


当EscapeAnalysisReducer::Finalize()函数执行结束后 GraphReducer::ReduceNode函数的一次循环流程就结束了,当revisit_列表为空就说明没有需要处理的节点了需要跳出循环结束流程,如果不为空就进行下一次循环去访问处理需要重新访问的节点:

然后再回头再去看ReduceTop函数,该函数是在GraphReducer::ReduceNode函数中具体处理节点的函数,ReduceNode函数先从栈顶取出要处理的节点entry,再根据entry.node获取到要处理的节点node,如果此节点为Dead节点那就不做处理直接从栈中弹出:
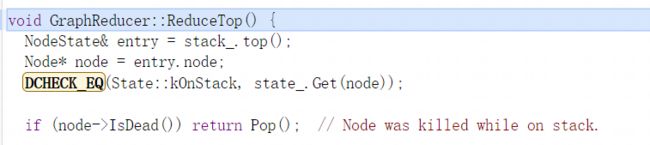
如果不为dead节点就继续执行,首先获取节点所有的input,entry.input_index是在push节点时被初始化的,在push后直接调用此值应该为0,然后判断该值是否大于node的输入节点个数,如果大于或等于就将start置为0,否则将直接获取entry.input_index赋值给start。

![]()
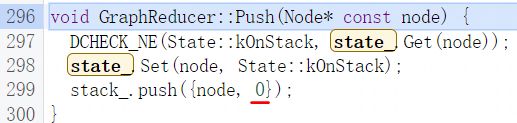
随后以start为基数,node input个数为上限值开始循环处理input,主要处理方式就是判断input是否不等于node,并且input是否可以进行递归处理,如果可以就将entry.input_index+1然后返回到GraphReducer::ReduceNode函数进行下一轮节点遍历处理:
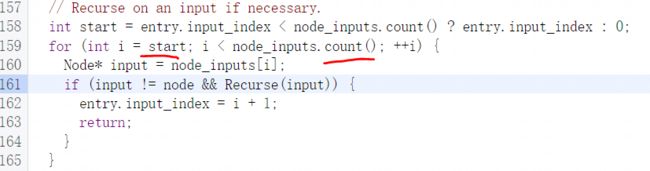

递归判断函数Recurse定义如下,当传入的node状态不等于kOnStack与kVisited时就将node压入节点处理栈中以便在下一轮节点处理循环中处理该节,然后返回true代表可以递归处理,否则直接返回false代表不可递归处理:


随后再以0为基数,start为上限值判断input是否可递归,此处处理与上一处循环处理原理一致主要是为了防止当entry.input_index>0时在此下标之前有漏检的节点:

然后通过图中所有节点数-1得到max_id,再去调用GraphReducer::Reduce函数执行优化,最后检查是否有减少节点,如果没有就将节点弹出:

GraphReducer::Reduce函数会将优化列表的末尾元素设为需要跳过的优化,随后循环获取并传入node以及node监视器进行执行优化,此处传入的node是节点处理栈栈顶的一个节点:
![]()

这其中会获取到EscapeAnalysisReducer::Reduce函数执行优化,此函数会先获取node的replacement,replacement是node的替换节点,所以如果replacement不为空就用replacement替换node:

replacement如果为空就继续执行,用node->op_来获取节点类型,再根据类型对不同节点进行处理,此处只对Allocate、TypeGuard、FinishRegion、NewArgumentsElements节点进行处理,其余节点默认都为FrameState节点:

通常情况下Allocate节点与FinishRegion节点是相互关联的,Allocate只有一个output那就是FinishRegion:

当EscapeAnalysisReducer::Reduce函数遇到Allocate或TypeGuard节点时会先判断其是否时逃逸节点并且为其分配了临时内存,如果是非逃逸且分配了临时内存那就放松allocate节点,使allocate节点不可达:

当遇到FinishRegion节点时先获取FinishRegion节点的效果输入节点,如果effect node是BeginRegion节点就将FinishRegion与BeginRegion节点都放松:

如果node是NewArgumentsElements节点就将node插入argumrnts_elements_列表中:

其余节点一律进入ReduceFrameStateInputs()函数对FrameState节点进行优化缩减

ReduceFrameStateInputs函数会遍历获取node的输入节点,随后判断输入节点是否是FrameState节点,如果是那就先初始化Deduplicator对象,该对象用于识别FrameState树中重复出现的VirtualObject对象:

随后进入ReduceDeoptState函数获取用于替换FrameState的新节点,此函数会先检查节点是否是FrameState,如果是就通过循环按照列表中的顺序获取相应的input_index,然后根据input_index获取FrameState的相应Input节点然后再进递归执行重新执行ReduceDeoptState函数获取用于替换FrameState input的节点:
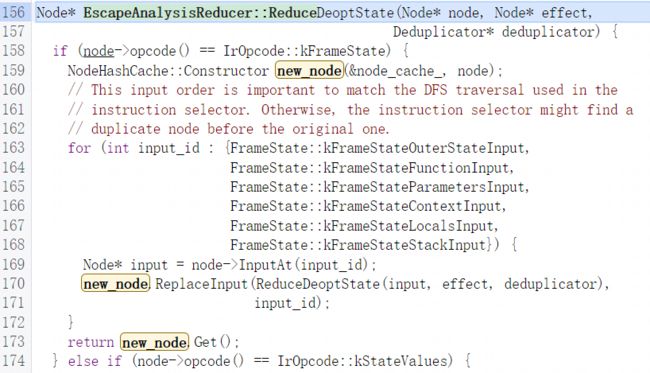
当传入的node不是FrameState节点时,也就是当传入的是FrameState的input节点时会先去判断是否是SateValue节点,在处理SateValue节点时会先获取其所有value输入节点随后继续递归ReduceDeoptState函数获取替换节点,随后用于替换StateValue的value输入节点

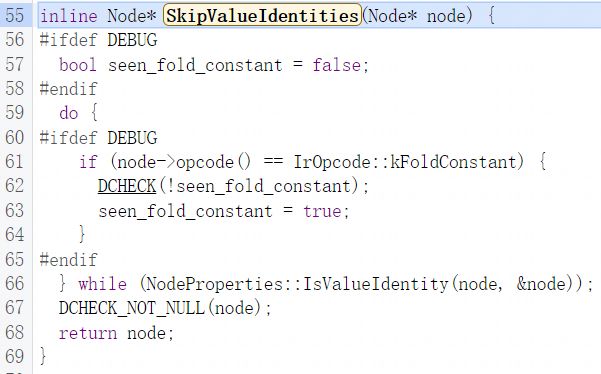
FrameState节点及其输入节点可以简单视为一个子树,FrameState节点为根节点,而ReduceDeoptState函数就是用于处理该子树在遍历算法上也使用DFS,前两个if分支,第一个if分支用于处理子树的根节点也就是FrameState节点,第二个if分支用于处理FrameSate的StateValue输入节点,当执行至第三个if分支时意味着ReduceDeoptState函数已遍历完了FrameState节点与StateValue节点要开始处理StateValue节点的input节点,首先要获取节点的vobject,在获取vobject时会调用SkipValueIdentities函数:
![]()
SkipValueIdentities函数用于跳过value input,实际上就是当遇到的是TypeGuard与FoldConstant节点时就跳过获取其input:
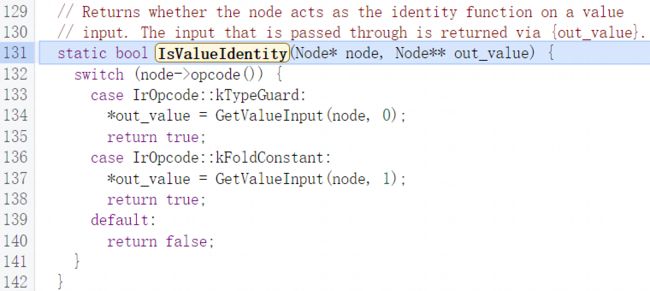
获取到vobject对象后如果不为空,先判断是否是逃逸对象如果是逃逸对象那就直接返回节点,否则就去调用SeenBefore函数查找缓存中是否存在存在说明为重复的虚拟对象直接从缓存中获取并返回相应节点,如果之前的条件都不满足就循环获取vobject的各字段节点,最后如果不为dead节点就继续递归ReduceDeoptState函数处理获取替换节点,最后将得到的节点压入input列表,再根据input列表创建新的节点并返回,关于FrameState节点的缩减操作递归调用较多需要结合调试进行分析:

在通过一些善后处理后(例如:Changed、NoChange、Pop没有什么需要特别说明)最后回退至EscapeAnlysisPhase::Run函数,该函数最后一步调用EscapeAnalysisReducer::VerifyReplacement函数对本阶段的一些主要功能的执行结果进行检查,检查的主要内容获取图中所有节点,并逐个访问确保将存在未逃逸对象的Allocate节点及其VirtualObject对象已经被删除,如果检查失败直接报错:

总结
本阶段最主要的功能就是检查对象是否为逃逸,将逃逸对象保留的同时将未逃逸的对象删除,除此之外此阶段还会将一些不必要的节点简化或替换为其他节点。