python3 爬虫(初试牛刀)
此文章仅供学习交流使用
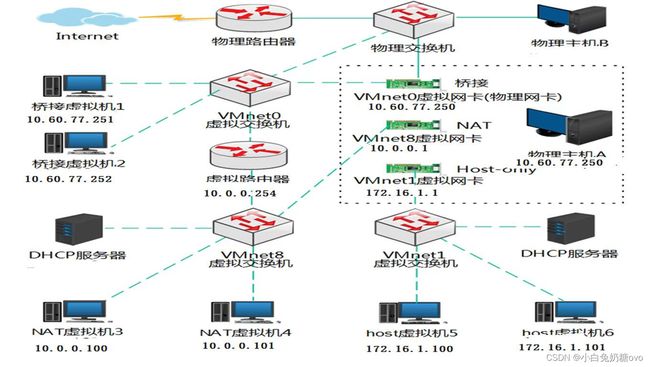
在学习爬虫之前,把最近对于 VMware 的网络学习做个总结
接下来,步入正题!
分析 Robots 协议
- 禁止所有爬虫访问任何目录的代码:
User-agent: *
Disallow:/
- 允许所有爬虫访问任何目录的代码:
User-agent: *
Disallow:
- 禁止所有爬虫访问网站某些目录的代码:
User-agent: *
Disallow: /private/
Disallow: /tmp/
- 只允许某一个爬虫访问的代码:
User-agent: WebCrawler
Disallow:
User-agent: *
Disallow: /
from urllib.robotparser import RobotFileParser
rp = RobotFileParser('http://www.jianshu.com/robots.txt')
rp.read()
// 利用 can_fetch() 方法判断了网页是否可以被抓取
print(rp.can_fetch('*', 'http://www.jianshu.com/p/b67554025d7d'))
print(rp.can_fetch('*', 'https://www.jianshu.com/p/c678ce575f4c'))

抓取bilibili首页
import requests
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
def main():
url = 'https://www.bilibili.com'
html = get_one_page(url)
print(html)
main()
抓取猫眼电影排行
数据存储
- TXT 文本存储
用 requests 将网页源代码获取下来,再使用 pyquery 解析库解析。
import requests
from pyquery import PyQuery as pq
url = 'https://www.zhihu.com/explore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
html = requests.get(url, headers=headers).text
doc = pq(html)
items = doc('.explore-tab .feed-item').items()
for item in items:
question = item.find('h2').text()
author = item.find('.author-link-line').text()
answer = pq(item.find('.content').html()).text()
file = open('explore.txt', 'a', encoding='utf-8')
file.write('\n'.join([question, author, answer])) # type: ignore
file.write('\n' + '=' * 50 + '\n')
file.close()
- JSON 文件存储
想保存 JSON 的格式,可以将 JSON 对象转为字符串,然后再调用文件的 write() 方法写入文本。
import json
data = [{
'name': '张三',
'gender': '女',
'birthday': '1992-10-18'
}]
with open('data.json','w', encoding='utf-8') as file:
file.write(json.dumps(data, indent=2, ensure_ascii=False))

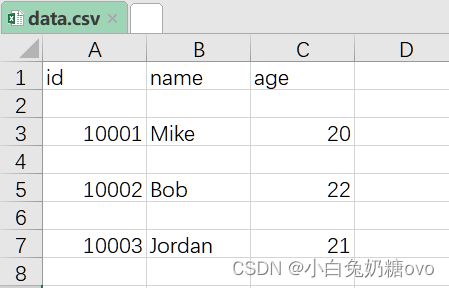
3. CSV 文件存储
import csv
with open('data.csv', 'w') as csvfile:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(csvfile, delimiter=' ', fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20})
writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22})
writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21})
- 读取数据
import pandas
df = pandas.read_csv('data.csv')
print(df)

- 数据库的存储
- MySQL 的存储
import pymysql
db = pymysql.connect(host="localhost", user="root", password="[数据库密码]", port=3306, db="spiders")
cursor = db.cursor()
// 创建表
sql='CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql)
db.close()
- rollback() 执行数据回滚
try:
id = '20120001'
user = 'Bob'
age = 20
sql = 'INSERT INTO students(id, name, age) values(%s, %s, %s)'
cursor.execute(sql, (id, user, age))
db.commit()
except:
db.rollback()
- MongoDB 存储(略)
- Redis 存储(略)
Ajax 数据爬取
- 将前10页的微博全部爬取下来
from pyquery import PyQuery as pq
from urllib.parse import urlencode
import requests
base_url = "https://m.weibo.cn/api/container/getIndex?"
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2830678474',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
params = {
'type': 'uid',
'value': '2830678474',
'containerid': '1076032830678474',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json):
if json:
items = json.get('data').get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['id'] = item.get('id')
weibo['text'] = pq(item.get('text')).text()
weibo['attitudes'] = item.get('attitudes_count')
weibo['comments'] = item.get('comments_count')
weibo['reposts'] = item.get('reposts_count')
yield weibo
if __name__ == '__main__':
for page in range(1, 11):
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)
- 分析 Ajax 爬取今日头条街拍美图
from hashlib import md5
from multiprocessing.pool import Pool
from urllib.parse import urlencode
import os
import requests
def get_page(offset):
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
'count': '20',
'cur_tab': '1',
}
url = 'https://www.toutiao.com/search_content/?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError:
return None
def get_images(json):
if json.get('data'):
for item in json.get('data'):
title = item.get('title')
images = item.get('image_detail')
for image in images:
yield {
'image': image.get('url'),
'title': title
}
def save_image(item):
if not os.path.exists(item.get('title')):
os.mkdir(item.get('title'))
try:
response = requests.get(item.get('image'))
if response.status_code == 200:
file_path = '{0}/{1}.{2}'.format(item.get('title'), md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
def main(offset):
json = get_page(offset)
for item in get_images(json):
print(item)
save_image(item)
GROUP_START = 1
GROUP_END = 20
if __name__ == '__main__':
pool = Pool()
groups = ([x * 20 for x in range(GROUP_START, GROUP_END + 1)])
pool.map(main, groups)
pool.close()
pool.join()
但未运行成功
OCR
tesserocr download
图形验证码的识别
import tesserocr
from PIL import Image
image = Image.open('Code.jpg')
result = tesserocr.image_to_text(image)
print(result)
- 更简单的方法:
import tesserocr
print(tesserocr.file_to_text('Code.jpg'))
另外,还有转灰度,二值化等操作!
极验滑动验证码的识别
使用 Selenium 配置 ChromeDriver
示例代码
点触验证码的识别
示例代码
微博宫格验证码的识别
示例代码
代理的使用:
urllib 与 urllib3 对比
# from urllib.error import URLError
# from urllib.request import ProxyHandler, build_opener
# proxy = '127.0.0.1:9743'
# proxy_handler = ProxyHandler({
# 'http': 'http://' + proxy,
# 'https': 'https://' + proxy
# })
# opener = build_opener(proxy_handler)
# try:
# response = opener.open('http://httpbin.org/get')
# print(response.read().decode('utf-8'))
# except URLError as e:
# print(e.reason)
import urllib3
proxy = urllib3.ProxyManager('http://127.0.0.1:11088', headers={'connection': 'keep-alive'})
resp = proxy.request('get', 'http://httpbin.org/ip')
print(resp.status)
print(resp.data)
代理的获取:
- 代理池的维护
实现一个比较高效的代理池,来获取随机可用的代理。 ADSL拨号代理
设置代理服务器:
安装TinyProxy
App 的爬取
Charles的使用mitmproxy的使用mitmdump爬取“得到” App电子书信息Appium的基本使用Appium爬取微信朋友圈Appium+mitmdump爬取京东商品
pyspider 框架的使用
详情见官网
Scrapy 框架的使用
scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
- 参数解释
- 括号里的参数为可选参数
callback:表示当前的url的响应交给哪个函数去处理meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动method:指定POST或GET请求headers:接收一个字典,其中不包括cookiescookies:接收一个字典,专门放置cookiesbody: 接收json字符串,为POST的数据,发送payload_post请求时使用
meta参数的使用
meta的作用: meta可以实现数据在不同的解析函数中的传递在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):
...
yield scrapy.Request(detail_url, callback=self.parse detail,meta=("item":item))
...
def parse detail(self,response):
#获取之前传入的item
item = resposne.meta["item"]
特别注意
meta参数是一个字典meta字典中有一个固定的键proxy,表示代理ip
反爬虫:
- UA检测
- UA伪装
- post请求 (携带了参数)
- 响应数据是一组
json数据
文章持续更新中…