数仓第5篇:『数据魔法』ETL
目录
- 导读:
- 一、数据同步之道
-
- 01. sqoop
- 02. DataX
- 03. kettle
- 04. canal
- 05. StreamSets
- 二、ETL之技术栈
-
- 2.1 工具
- 2.2 语言
- 三、ETL加载策略
-
- 01. 增量
- 02. 全量
- 03. 拉链
- 四、结束语
导读:
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。
ETL工具或类ETL的数据集成同步工具或语言,企业生产中工具也非常之多,主流的etl工具有Sqoop、DataX、Canal、flume、Logstash、kettle、DataStage、Informatica、Talend等,语言有强悍的SQL、Shell、Python、Java、Scala等。而数据源多为业务系统,埋点日志,离线文件,第三方数据等。
一、数据同步之道
01. sqoop
Sqoop,SQL-to-Hadoop 即 “SQL到Hadoop和Hadoop到SQL”。
是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。主要用于在Hadoop与关系型数据库之间进行数据转移,可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
sqoop命令的本质是转化为MapReduce程序。sqoop分为导入(import)和导出(export),策略分为table和query,模式分为增量和全量。
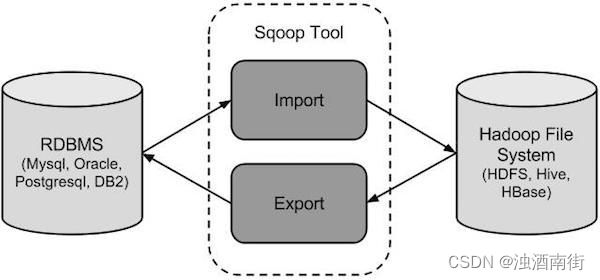
命令简单示例:
02. DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
github地址:https://github.com/alibaba/DataX
支持数据源:
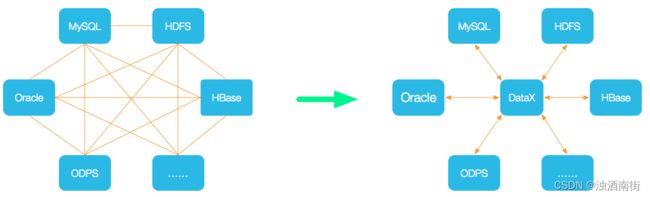
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader+Writer插件,纳入到整个同步框架中。
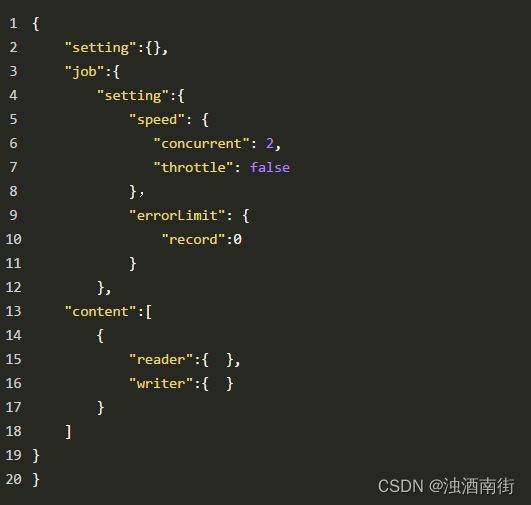
目前已到datax3.0框架设计:

datax使用示例,核心就是编写json配置文件job:
03. kettle
Kettle,中文名:水壶,是一款国外免费开源的、可视化的、功能强大的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。
Kettle家族目前包括4个产品:Spoon、Pan、CHEF、Kitchen。
Kettle的最大特点:
01.免费开源:基于Java免费开源软件
02.易配置:可跨平台,绿色无需安装
03.不同数据库:ETL工具集,可管理不同数据库的数据
04.两种脚本文件:transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制
05.图形界面设计:托拉拽,无需写代码
06.定时功能:在Job下的start模块,有一个定时功能,可以每日,每周等方式进行定时
04. canal
canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL,也支持mariaDB。
很多大型的互联网项目生产环境中使用,包括阿里、美团等都有广泛的应用,是一个非常成熟的数据库同步方案,基础的使用只需要进行简单的配置即可。
github地址:https://github.com/alibaba/canal
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
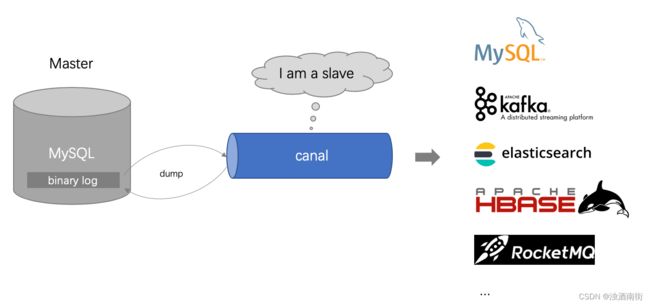
canal是通过模拟成为mysql 的slave的方式,监听mysql 的binlog日志来获取数据,binlog设置为row模式以后,不仅能获取到执行的每一个增删改的脚本,同时还能获取到修改前和修改后的数据,基于这个特性,canal就能高性能的获取到mysql数据数据的变更。
05. StreamSets
Streamsets是一个大数据实时采集ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。
数据源支持MySQL、Oracle等结构化和半/非结构化,目标源支持HDFS、Hive、Hbase、Kudu、Solr、Elasticserach等。创建一个Pipelines管道需要配置数据源(Origins)、操作(Processors)、目的地(Destinations)三部分。
Streamsets的强大之处:
拖拽式可视化界面操作,No coding required 可实现不写一行代码
强大整合力,100+ Ready-to-Use Origins and Destinations,支持100+数据源和目标源
可视化内置调度监控,实时观测数据流和数据质量

二、ETL之技术栈
2.1 工具
重工具,kettle、DataStage、Informatica 三大工具依旧牢牢稳固传统数仓三大主力位置。kettle与时俱进,在大数据数仓,如一些互联网公司也有在使用kettle。
工具本文不再多做介绍。
2.2 语言
开发语言,传统数仓一般SQL/Shell为主,互联网数仓又对Python、Java、Scala提出了新的要求。
不管是传统数仓,还是基于Hadoop生态的构建的(hive、spark、flink)数仓,SQL虽然戏码在下降,但依然是重头戏。强大的存储过程,更是屹立不倒,这么多年都在熠熠生辉。
善于发现的你,一定会发现,在大数据生态,不管哪种数据处理框架,总有一天都会孵化出强大SQL的支持。如Hive SQL,Spark SQL,Blink SQL 等。此时,你或许会得出一个结论:SQL是最好的语言!
对于SQL,基本技能也是必备技能。
各种join、嵌套/标量子查询,强大的分析/窗口函数,变化无穷的正则表达式,层次查询,扩展分组,MODEL,递归with,多维分析,排列组合,行列互转,json解析,执行计划,四大类型(dql、dml、ddl、dcl)等,依然需要每个etl·er熟悉掌握。
SQLjoin,left/rignt/full join,每一个join都是暗藏韵理,on和where也不容小觑。
分析函数 简捷高效,4类30+个分析/窗口函数最全总结
SQL开发规范和执行计划也需要每个erl·er在实际实践中不断加强、提炼、升级。
SQL开发规范 示例:

如果你还在传统数仓领域,如果你还想将薪比薪,建议赶紧开始学Java、scala,拥抱大数据生态Hadoop/Spark/Flink,机会总是垂青有准备的人。
三、ETL加载策略
数据集成加载策略,按类型可包括快照、流水、增量、全量、拉链等。
01. 增量
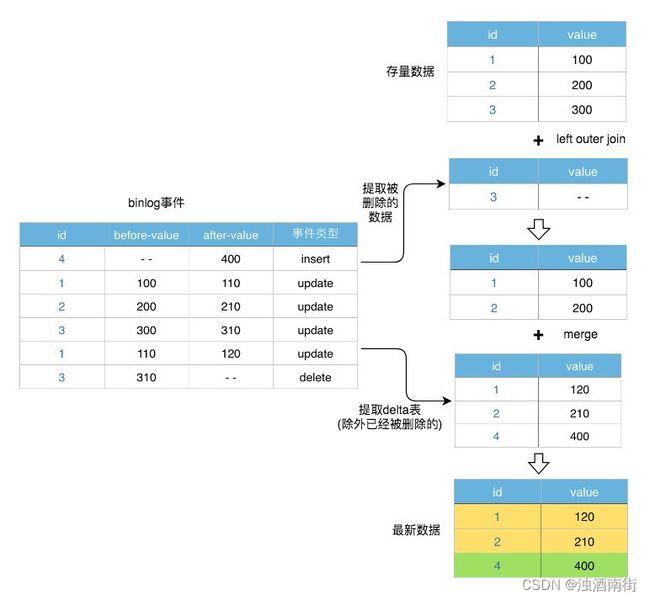
有些表巨大,我们需要选择增量策略,新增delta数据需要和存量数据merge合并。欣赏并学习两种处理方式,直接上图,可斟酌体会:
Merge方式(一)

Merge方式(二)
1)只有新增数据

2)新增+删除
02. 全量
每天一个全量表,也可一个分区一个全量。
03. 拉链
拉链表,记录数据生命周期,记录一条数据生命周期的开始和结束。
建议在设计拉链表的时候不仅要有开始时间和结束时间,最好再加一个生命状态字段,如chain_status:有效 active、失效 expired、历史 history。
回想一下前面文章介绍的缓慢变化维,可类比SCD的TYPE2,有异曲同工之处

全量拉链,或许会存在性能问题,故建议根据实际业务场景中进行取舍,可只和最近一个时间周期(eg:1个月)的进行拉链处理。
四、结束语
学思想,数据思维;
学Java,走大数据;
学实时,不怕被淘汰!