WebMagic的学习(三)——使用和定制Pipeline,爬取数据存储到MySql数据库
一、Pipeline介绍
Pipeline的接口定义如下:
public interface Pipeline {
// ResultItems保存了抽取结果,它是一个Map结构,
// 在page.putField(key,value)中保存的数据,可以通过ResultItems.get(key)获取
public void process(ResultItems resultItems, Task task);
}可以看到,Pipeline其实就是将PageProcessor抽取的结果,继续进行了处理的,其实在Pipeline中完成的功能,你基本上也可以直接在PageProcessor实现。使用其的原因如下:
- 为了模块分离。“页面抽取”和“后处理、持久化”是爬虫的两个阶段,将其分离开来,一个是代码结构比较清晰,另一个是以后也可能将其处理过程分开,分开在独立的线程以至于不同的机器执行。
- Pipeline的功能比较固定,更容易做成通用组件。每个页面的抽取方式千变万化,但是后续处理方式则比较固定,例如保存到文件、保存到数据库这种操作,这些对所有页面都是通用的。WebMagic中就已经提供了控制台输出、保存到文件、保存为JSON格式的文件几种通用的Pipeline。
在WebMagic里,一个Spider可以有多个Pipeline,使用Spider.addPipeline()即可增加一个Pipeline。这些Pipeline都会得到处理,例如可以使用:
spider.addPipeline(new ConsolePipeline()).addPipeline(new FilePipeline())实现输出结果到控制台,并且保存到文件的目标。
二、爬取数据并存储到数据库
这里使用的数据库是MySql数据库,主要流程是这样:
①爬取页面数据
②实现Pipeline,重写process,定制自己的存储规则。
这里也以之前爬取csdn为例来进行爬取,爬取代码就不再多讲,可以看我之前写的博客:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.ConsolePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
public class csdnMysql implements PageProcessor {
private Site site = Site.me().setSleepTime(1000).setRetryTimes(3);
private static int count=0;
public static final String URL_LIST = "https://blog\\.csdn\\.net/qq_41061437/article/list/\\d";
public static final String URL_POST = "https://blog\\.csdn\\.net/qq_41061437/article/details/\\d{1,}";
@Override
public void process(Page page) {
//列表页
if (page.getUrl().regex(URL_LIST).match()) {
page.addTargetRequests(page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[2]").links().regex(URL_POST).all());
page.addTargetRequests(page.getHtml().links().regex(URL_LIST).all());
//文章页
} else {
page.putField("title", page.getHtml().xpath("//*[@id=\"mainBox\"]/main/div[1]/div/div/div[1]/h1/text(0)").toString());
page.putField("context", page.getHtml().xpath("//div[@class='article_content']/allText()").toString());
count++;
System.err.println("爬取第"+count+"条数据");
}
}
@Override
public Site getSite() {
return site;
}
public static void main(String args[]){
long startTime, endTime;
System.out.println("开始爬取数据");
startTime = System.currentTimeMillis();
Spider.create(new csdnMysql())
.addUrl("https://blog.csdn.net/qq_41061437/article/list/1")
.addPipeline(new ConsolePipeline())
.addPipeline(new mysqlPipeline())
.thread(5)
.run();
endTime = System.currentTimeMillis();
System.err.println("爬取结束,耗时约" + ((endTime - startTime) / 1000) + "秒,抓取了"+count+"条记录");
}
}
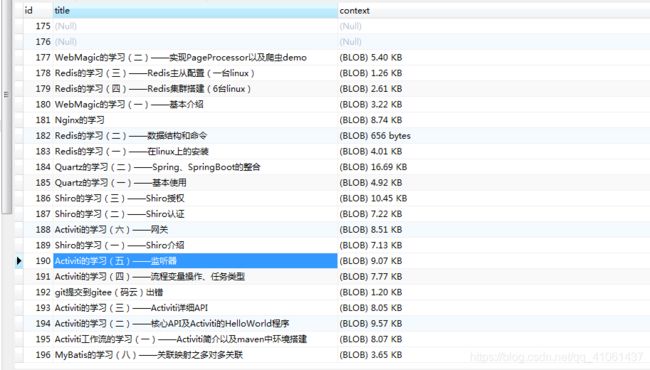
接着可以新建一个数据库,这里我就弄了三个字段,id、title、context这三个字段,主要保存文章标题和文章内容,由于文章内容较多,这里数据库使用的数据类型是mediumblob,可以存储16M的数据。数据库如下:
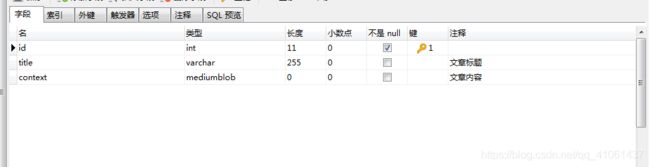
这里使用原生JDBC就行,要使用其它ORM框架的话,可以自己再结合我这里来进行修改:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JdbcUtil {
private static final String URL="jdbc:mysql://localhost:3306/csdnmysql";
private static final String USER="root";
private static final String PASSWORD="123456";
private static Connection conn = null;
static {
try{
//1.加载驱动
Class.forName("com.mysql.jdbc.Driver");
//2.获得数据库的连接
conn = DriverManager.getConnection(URL, USER, PASSWORD);
} catch(ClassNotFoundException e){
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Connection getConnection(){
return conn;
}
}接下来就是实现Pipeline接口,重写里面的process方法:
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.Pipeline;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
/**
* 将爬取到的内容保存到数据库
*/
public class mysqlPipeline implements Pipeline {
@Override
public void process(ResultItems resultItems, Task task) {
Connection conn = JdbcUtil.getConnection();
String title = resultItems.get("title"); //文章题目
String context = resultItems.get("context"); //文章内容
String sql = "INSERT INTO csdn (title, context) VALUES (?,?)";
try {
PreparedStatement ptmt = conn.prepareStatement(sql);
ptmt.setString(1,title);
ptmt.setString(2,context);
ptmt.execute();
} catch (SQLException e) {
e.printStackTrace();
}
}
}然后运行,可以看到控制台输出了爬取的数据,然后检查数据库发现也将文章标题、内容存到了数据库里面: