【面试题】前端面试复习6---性能优化
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库
性能优化
一、性能指标
要在 Chrome 中查看性能指标,可以按照以下步骤操作:
- 打开 Chrome 浏览器,并访问你想要测试的网页。
- 使用快捷键 F12 或右键点击页面并选择 “检查”,打开开发者工具。
- 在开发者工具中,切换到 “Performance”(性能)选项卡。
- 点击开始录制按钮,即红色的圆点按钮。开始加载页面。
- 等待页面加载完成,然后停止录制,点击红色的圆点按钮或按下快捷键 Ctrl + E。
- 在性能分析结果中,你会看到一些性能指标图表。在 “Timings”(时间)图表中,你可以找到各个性能指标的时间点。
常规指标
- DCL:DOMContentLoaded 事件
- L:Onload 事件
- FP - First Paint:首次绘制,浏览器开始将像素绘制到屏幕上的时间点。
- FCP - First Contentful Paint:首次内容绘制,表示浏览器在加载页面时第一次绘制了一部分页面内容(文本、图像等)的时间点。它标志着用户可见的内容开始出现在屏幕上的时间。
- FMP - First Meaningful Paint:首次有意义绘制,指⻚面关键元素渲染时间。这个概念并没有标准化定义,因为关键元素可以由开发者自行定义——究竟什么是“有意义”的内容,只有开发者或者产品经理自己了解。
- TTI - Time To Interactive:用户可以与页面进行交互的时间点。一般来讲,我们认为是 domready 的时间,因为我们通常会在这时候绑定事件操作。如果⻚面中涉及交互的脚本没有下载完成,那么当然没有到达所谓的用户可交互时间。那么如何定义 domready 时间呢?
- TTFB - Time To First Byte:发出⻚面请求到接收到应答数据第一个字节所花费的毫秒数。
Chrome 最新指标
- LCP - Largest Contentful Paint:最大内容绘制,衡量⻚面的加载体验,它表示视口内可⻅的最大内容元素的渲染时间。相比 FCP,这个指标可以更加真实地反映具体内容加载速度。比如,如果⻚面渲染前有一个 loading 动画,那么 FCP 可能会以 loading 动画出现的时间为准,而 LCP 定义了 loading 动画加载后,真实渲染出内容的时间。
- FID - First Input Delay:首次输入延迟,衡量可交互性,它表示用户和⻚面进行首次交互操作所花费的时间。它比 TTI(Time To Interactive)更加提前,这个阶段虽然⻚面已经显示出部分内容,但并不能完全具备可交互性,对于用户的响应可能会有较大的延迟。
- CLS - Cumulative Layout Shift:积累布局位移,是一个衡量页面布局稳定性的性能指标,它衡量页面上元素在加载过程中发生的意外布局变化的总和。CLS 反映了用户在浏览页面时会遇到的突然、意外的元素移动,导致用户难以准确点击操作或浏览内容。CLS 的值通常为在加载期间发生布局变化的元素面积的百分比,范围是从 0 到 1。CLS 值越接近 0,表示页面布局越稳定,用户体验越好。如果 CLS 值较高,则可能需要优化页面布局,例如确定元素的固定尺寸、合理设置图片和广告的尺寸等。通过监测 CLS,可以改进页面的布局稳定性,提高用户体验和满意度。
总下载时间
⻚面所有资源加载完成所需要的时间。一般可以统计 window.onload 时间,这样可以统计出同步加载的资源全部加载完的耗时。如果⻚面中存在较多异步渲染,也可以将异步渲染全部完成的时间作为总下载时间。
DOMContentLoaded 与 load 事件的区别
DOMContentLoaded 指的是文档中 DOM 结构加载完毕的时间,也就是说 HTML 结构已经完整。但是我们知道,页面可能包含了图片,特殊字体,视频,音频等资源,这些资源由网络请求获取,DOM 结构加载完毕时,由于这些资源往往额外的网络请求,这些资源可能还有没有请求或者渲染完成。而当页面上所有资源加载完成后,load 时间见才会被触发。因此,在时间线上,load 事件往往会落后于 DOMContentLoaded 事件。
关于 DOMContentLoaded 和 domReady
我们简单说一下,浏览器是从上到下,从左到右,一个个字符串读入,大致可以认为两个同名的开标签和闭标签就是一个 DOM(有的是没有闭标签),这时候就忽略掉两个标签之间的内容。页面上有许多标签,但标签会生成同样多的 DOM,因为有的标签下允许存在特定的子标签,比如:tr 下面一定是 td, th, select 下面一定是 opgrounp, option, 而 option 下面,就算你写了 ,它都会忽略掉,option 只存在文本,这就是我们需要自定义下拉框的原因。
我们说过,这个顺序是从上到下的,有的元素很简单,构建的很快,但是标签存在 src, href 属性,它们会引用外部资源,这就要区别对待了。比如说,script 标签,它一定会等 src 指定的脚本文件加载下来,然后全部执行了里面的脚本,才会分析下一个标签,这种现象叫做堵塞。
堵塞是一种非常致命的现象,因为浏览器渲染引擎是单线程的,如果头部引入的脚本过多会导致白屏,影响用户体验,因此雅虎的 20 军规中就有一条提到,所有的 script 标签都放到 body 之后。
此外,style 标签 与 link 标签,它们在加载样式文件时是不会堵塞的,但是它们一旦加载好,就会立即开始渲染已经构建好的节点元素,这可能会引起 reflow ,这也影响速度。
另外一个影响 DOM 树构建的是 iframe,它也会加载资源,虽然不会堵塞 DOM 构建,但它由于发出 HTTP 请求,而 HTTP 请求时有限的,它会与父标签的其它需要加载外部资源的标签产生竞争。我们经常看到一些新闻网上面挂了很多 iframe 广告,这些页面一开始加载时就很卡就是就是这个缘故。
此外还有 object 元素,用来加载 flash。document.getElementById() 等等,这些东西会影响到 DOM 树的构建过程。因此在这时候,当我们贸贸然使用 getElementById, getElementsByTagName 获取元素,然后操作它们,就会很大几率碰到元素为 null 的异常,这时候目标元素还有转换为 DOM 节点,还只是一个普通的字符串呢!
二、如何获取这些指标
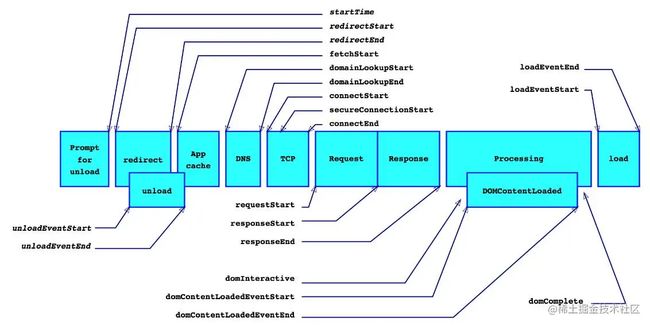
通过 performance.timing 获取
performance.timing
| 字段 | 含义 |
|---|---|
| navigationStart | 加载的起始时间,如果没有前一个页面的 unload,则与 fetchStart 值相等 |
| redirectStart | 重定向开始时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回开始重定向的 fetchStart 的值。其他情况则返回 0) |
| redirectEnd | 重定向结束时间(如果发生了 HTTP 重定向,每次重定向都和当前文档同域的话,就返回最后一次重定向接受完数据的时间。其他情况则返回 0) |
| fetchStart | fetchStart 浏览器发起资源请求时,如果有缓存,则返回读取缓存的开始时间 |
| domainLookupStart | DNS 域名开始查询的时间,如果本地有缓存或 keep-alive 等,则返回 fetchStart |
| domainLookupEnd | DNS 域名结束查询的时间,如果没有发起 DNS 请求同上 |
| connectStart | TCP 开始建立连接的时间,如果有本地的缓存或 keep-alive 等,则与 fetchStart 值相等 |
| secureConnectionStart | https 连接开始的时间如果不是安全连接则为 0 |
| connectEnd | TCP 完成握手的时间,如果有本地的缓存或 keep-alive 等,则与 connectStart 值相 |
| requestStart | HTTP 请求读取真实文档的开始时间,包括从本地文件读取 |
| requestEnd | HTTP 请求读取真实文档的结束时间,包括从本地文件读取 |
| responseStart | 浏览器从服务器收到(或从本地缓存读取)第一个字节的时间 |
| responseEnd | 浏览器从服务器收到(或从本地缓存读取,或从本地资源读取)最后一个字节的时间 |
| unloadEventStart | 前一个⻚面的 unload 的时间戳如果没有则为 0 |
| unloadEventEnd | 与 unloadEventStart 相对应,返回的是 unload 函数执行完成的时间戳 |
| domLoading | 这是当前网⻚ DOM 结构开始解析时的时间戳,是整个过程的起始时间,浏览器即将开始解析第一批收到的 HTML 文档字节,此时 document.readyState 变成 loading,并将抛出 readyStateChange 事件 |
| domInteractive | 返回当前网⻚ DOM 结构结束解析、开始加载内嵌资源时时间戳,document.readyState 变成 interactive,并将抛出 readyStateChange 事件(注意只是 DOM 树解析完成,这时候并没有开始加载网⻚内的资源) |
| domContentLoadedEventStart | 网⻚ domContentLoaded 事件开始执行时间 |
| domContentLoadedEventEnd | 网⻚ domContentLoaded 事件执行结束时间,domReady 的时间 |
| domComplete | DOM 树解析完成,且资源也准备就绪的时间,document.readyState 变成 complete。并将抛出 readystatechange 事件 |
| loadEventStart | load 事件发送给文档,onLoad 开始执行的时间 |
| loadEventEnd | load onLoad 开执行结束的时间 |
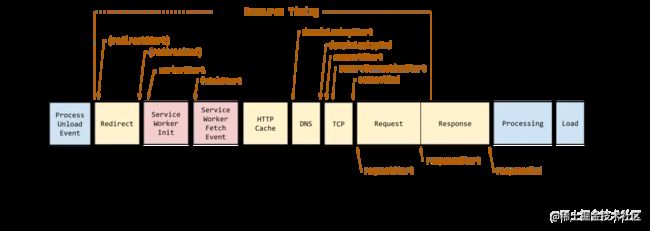
相关参数计算
| 字段 | 描述 | 计算方式 | 意义 |
|---|---|---|---|
| unload | 前一个⻚面卸载耗时 | unloadEventEnd - unloadEventStart | |
| redirect | 重定向耗时 | redirectEnd - redirectStart | 重定向的时间 |
| appCache | 缓存耗时 | domainLookupStart - fetchStart | 读取缓存的时间 |
| dns | DNS 解析耗时 | domainLookupEnd - domainLookupStart | 可观察域名解析服务是否正常 |
| tcp | TCP 连接耗时 | connectEnd - connectStart | 建立连接的耗时 |
| ssl | SSL 安全连接耗时 | connectEnd - secureConnectionStart | 反映数据安全连接建立耗时 |
| ttfb | TimetoFirstByte(TTFB)网络请求耗时 | responseStart - requestStart | TTFB 是发出⻚面请求到接收到应答数据第一个字节所花费的毫秒数 |
| response | 响应数据传输耗时 | responseEnd - responseStart | 观察网络是否正常 |
| dom | DOM 解析耗时 | domInteractive - responseEnd | 观察 DOM 结构是否合理,是否有 JS 阻塞⻚面解析 |
| dcl | DOMContentLoaded 事件耗时 | domContentLoadedEventEnd - domContentLoadedEventStart | 当 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,无需等待样式表、图像和子框架的完成加载 |
| resources | 资源加载耗时 | domComplete - domContentLoadedEventEnd | 可观察文档流是否过大 |
| 首次渲染耗时 | 首次渲染耗时 | responseEnd - fetchStart | 加载文档到看到第一帧非空图像的时间,也叫白屏时间 |
| 首次可交互时间 | 首次可交互时间 | domInteractive-fetchStart | DOM 树解析完成时间,此时 document.readyState 为 interactive |
| 首包时间耗时 | 首包时间 | responseStart-domainLookupStart | DNS 解析到响应返回给浏览器第一个字节的时间 |
| ⻚面完全加载时间 | ⻚面完全加载时间 | loadEventStart-fetchStart | |
| onLoad | onLoad 事件耗时 | loadEventEnd - loadEventStart |
使用 demo
Document
parent
child
son
www.baidu.com
常见的性能条目
- frame:帧信息,包括每秒的帧数(FPS)和每帧的时间间隔(Frame Interval)。
- navigation:页面导航相关的性能数据,包括重定向、DNS 查询、TCP 握手、页面加载的时间等。
- resource:资源加载相关的性能数据,如图片、样式表、脚本等资源的加载时间和大小。
- paint:绘制相关的性能数据,如首次绘制的时间点和绘制区域的尺寸等。
- mark:由 performance.mark() 创建的时间戳标记,用于标记代码执行的特定点。
- measure:由 performance.measure() 创建的自定义性能度量,用于测量特定代码块的执行时间。
- longtask:表示执行时间超过 50 毫秒的长任务的性能数据。
- layout-shift:布局偏移相关的性能数据,用于衡量页面上元素位置发生变化的情况。
- element:与元素相关的性能数据,例如测量元素大小和位置的信息。
代码获取首次绘制,首次内容绘制,最大内容绘制
new PerformanceObserver((entryList, observer) => {
let entries = entryList.getEntries()
for (let i = 0; i < entries.length; i++) {
if (entries[i].name === 'first-paint') {
console.log('FP', entries[i].startTime)
}
if (entries[i].name === 'first-contentful-paint') {
console.log('FCP', entries[i].startTime)
}
}
observer.disconnect()
}).observe({ entryTypes: ['paint', 'largest-contentful-paint'] })
new PerformanceObserver((entryList, observer) => {
let entries = entryList.getEntries()
const lastEntry = entries[entries.length - 1]
console.log('LCP', lastEntry.startTime)
observer.disconnect()
}).observe({ entryTypes: ['largest-contentful-paint'] })
代码获取一些常用指标
setTimeout(() => {
const {
fetchStart,
connectStart,
connectEnd,
requestStart,
responseStart,
responseEnd,
domLoading,
domInteractive,
domContentLoadedEventStart,
domContentLoadedEventEnd,
loadEventStart,
} = performance.timing
const info = `
connectTime(TCP链接耗时): ${connectEnd - connectStart}
ttfbTime(获取到第一个字节耗时): ${responseStart - requestStart}
responseTime(Response响应耗时): ${responseEnd - responseStart}
parseDOMTime(DOM 解析渲染耗时): ${loadEventStart - domLoading}
domContentLoaded(事件耗时):${domContentLoadedEventEnd - domContentLoadedEventStart}
TimeToInteractive(首次可交互时间):${domInteractive - fetchStart}
loadTime(完整的加载时间): ${loadEventStart - fetchStart}
`
console.log(info)
}, 2000)
// 写在 setTimeout 里面页面完成显示完成再打印,延迟执行时间根据实际情况设定
三、从什么维度来剖析性能?
维度 1:I/O(network)维度

在 App cache/HTTP Cache 阶段
强缓存(Cache-Control 和 Expires)和协商缓存(ETag 和 Last-Modified)是两种常见的缓存机制,用于在客户端和服务器之间优化资源的请求和响应。
强缓存是指客户端直接使用本地缓存的资源,而无需向服务器发送请求。主要通过以下两种方式实现:
-
Cache-Control:在服务器的响应头部中,设置 Cache-Control 指令来控制资源的缓存机制。常用的指令包括:
- public:表示资源可以被任何缓存(包括客户端和代理服务器)缓存。
- private:表示资源只能被客户端缓存,不可被代理服务器缓存。
- max-age:指定资源的有效时间,单位为秒。客户端在该时间内可以直接使用本地缓存而无需发送请求。
-
Expires:在服务器的响应头部中,设置 Expires 字段来指定资源的过期时间。它是一个具体的时间点,表示在该时间点之后,客户端不能再使用本地缓存,而是需要向服务器发送请求。
协商缓存是指客户端先向服务器发送请求,服务器通过对请求的验证来判断是否返回资源的实际内容。主要通过以下两种方式实现:
- ETag:在服务器的响应头部中,设置 ETag 字段来标识资源的版本号。客户端可以在后续请求中使用 If-None-Match 头部字段将上次响应中的 ETag 值发送给服务器,服务器通过比较资源的 ETag 值判断资源是否发生了变化,如果未发生变化,则返回 304 状态码,告知客户端可以使用缓存的资源。
- Last-Modified:在服务器的响应头部中,设置 Last-Modified 字段来表示资源的最后修改时间。客户端可以在后续请求中使用 If-Modified-Since 头部字段将上次响应中的 Last-Modified 时间发送给服务器,服务器通过比较资源的最后修改时间判断资源是否发生了变化,如果未发生变化,则返回 304 状态码,告知客户端可以使用缓存的资源。
需要注意的是,强缓存是由客户端自身决定是否使用缓存,而协商缓存是由服务器来决定是否返回实际内容。通常情况下,当资源处于强缓存的有效期内时,客户端直接使用本地缓存的资源,不会发送请求到服务器;而当资源过期或存在其他的缓存验证字段时,客户端会发送请求到服务器并进行缓存的验证。两种缓存机制可以结合使用,实现更灵活和高效的缓存策略。
有缓存
无缓存
强缓存
没过期
已过期
协商缓存
可用
不可用
HTTP请求
是否有缓存
强缓存或协商缓存?
直接向后端获取数据
页面呈现
缓存是否过期?
不发送请求,读取浏览器缓存
重新向后端获取数据
向后端发送ETag或Last-Modified
后端判断缓存是否可用
返回304
读取浏览器缓存
返回200
后端返回新的数据
缓存中有哪些细节需要注意?
-
304 状态码是好还是不好?
- 如果多:意味着,我的协商缓存就比较多;如果少:意味着,我的 JS 文件可能存在频繁更新的情况。
-
直接在浏览器端输入的 http://xxx.xxx.com/index.html,该文件是不会被缓存的。
-
webpack 中的 hash 指纹,需要合理的利用,去让“该缓存的内容被缓存”
- 不经常更新的文件改用 contentHash,例如:公共的样式文件,工具类 js 文件。
-
协商缓存中的 Modified 是根据时间判断,精确到秒,一秒时间内可能引发很多问题。
- 如果同时有多个资源在同一秒内发生了修改,服务器可能无法准确识别出每个资源的变化,导致缓存失效。
- 如果服务器的时间与浏览器的时间存在偏差,可能导致资源的修改时间在服务器和浏览器之间不一致,进而造成缓存验证不准确。
为了避免以上问题,通常建议在修改资源的同时,将"Last-Modified"时间向上取整到秒级,以增加时间的准确性。此外,还可以使用更精确的缓存验证机制,如 ETag,来解决精度不足的问题,以确保资源的缓存验证更为准确和可靠。
-
在 CDN 下,hash 缓存是否能够有比较好的缓存效果?
在 CDN 下,哈希缓存具有非常好的缓存效果。
哈希缓存是指在文件名中添加一个唯一的哈希值,当文件内容发生改变时,哈希值也会改变。CDN 会根据文件名来缓存和分发资源,因此当哈希值改变时,CDN 会将最新的文件缓存并提供给用户。
哈希缓存在 CDN 下可以实现以下优点:
- 强制缓存更新:哈希缓存可以强制浏览器或 CDN 节点在文件内容发生变化时获取最新的资源。由于哈希值的改变,文件名也会改变,这会触发浏览器或 CDN 节点重新请求该资源,确保用户获得最新的版本。
- 缓解缓存一致性问题:在 CDN 集群中,缓存一致性是一个重要的问题。使用哈希缓存可以避免不同 CDN 节点之间的缓存不一致性问题。当文件内容发生变化时,哈希值改变,文件名也改变,这样 CDN 将不再提供旧版本的资源,而是提供最新的版本。
- 消除浏览器缓存问题:浏览器缓存也是需要考虑的因素。通过哈希缓存,浏览器会将每个版本的资源看作是一个新的文件,并缓存该版本。这避免了浏览器在引用更新资源时使用旧版本的缓存。
总结起来,哈希缓存在 CDN 下具有非常好的缓存效果。通过强制缓存更新、解决缓存一致性问题和消除浏览器缓存问题,哈希缓存可以确保用户获取到最新的资源版本,提高缓存命中率并加快内容传输速度,从而提升用户的访问体验。
-
没有了强缓存的必要字段值,浏览器还会走强缓存吗?
- 答案是肯定的。(heuristic expiration time/试探性过期时间/启发式缓存/)
- 强缓存有效期由 Expires 和 Cache-Control 中的 max-age 来决定的,那么如果响应头中不存在这两个字段,缓存的有效期怎么计算呢?浏览器还会走强缓存吗?答案是肯定的,这就是我们要现在要了解的 启发式缓存 。
- 当报头中没有用来确定强缓存时间的字段时,浏览器会触发启发式缓存,缓存有效期计算公式:
(date - last-modified) * 10%,取响应报头中 date 与 last-modified 值之差的百分之十作为缓存时间。启发式缓存比较容易忽略,不了解启发式缓存可能会因为这种默认的缓存方式而掉入坑里,但一旦你了解了浏览器启发式缓存的机制,很多问题都可以得到解决。
TCP 阶段
HTTP(Hypertext Transfer Protocol)是用于在 Web 上进行通信的协议。它的不同版本有不同的特性和改进。以下是 HTTP 各个版本的主要区别:
-
HTTP/1.0:
- 请求-响应模型:每个请求只能获得一个响应。
- 无状态:每个请求都是相互独立的,服务器不会保留之前的请求信息。
- 每个请求建立新的连接:每个请求都需要在客户端和服务器之间建立一个新的 TCP 连接。
- 无持久连接:每个请求的响应结束后,连接会被关闭。
- 每个资源一个请求:每个页面元素(如图片、样式表、脚本等)都需要单独的 HTTP 请求。
-
HTTP/1.1:
- 持久连接:多个请求可以在同一个连接上进行,提高效率。
- 管道化(Pipeline):允许在一个连接上同时发送多个请求,减少延迟。
- Host 头部字段:允许在同一台服务器上提供多个域名的不同网站。
- 增加了缓存机制:引入了更多的缓存控制头部字段,可以更好地利用缓存。
- 引入了分块传输编码(Chunked Transfer Encoding):允许服务器逐块发送响应,有利于大文件的传输。
-
HTTP/2:
- 多路复用(Multiplexing):多个请求可以在同一个连接上同时进行,提高性能。
- 二进制传输:HTTP/2 使用二进制格式传输数据,替代了 HTTP/1.x 的文本格式,提高了效率和解析速度。
- 头部压缩:使用 HPACK 算法对报文头部进行压缩,减少了数据传输量。
- 服务器推送(Server Push):服务器可以主动推送资源给客户端,减少了客户端的请求次数。
-
HTTP/3:
- 基于 QUIC 协议:HTTP/3 基于 QUIC(Quick UDP Internet Connections)协议,使用 UDP 替代 TCP,提供更低的延迟和更好的性能。
- 支持多路复用和头部压缩:HTTP/3 也继承了 HTTP/2 的多路复用和头部压缩特性。
这些是 HTTP 协议各个版本的主要区别。随着协议的发展,每个版本都试图改进性能、安全性和效率,以提供更好的 Web 体验。选择使用哪个版本取决于服务器和客户端的支持情况以及具体的需求。
Keep-Alive 是一种持久连接机制,旨在改善 HTTP 协议的性能表现。在传统的 HTTP/1.0 中,每个客户端请求都需要与服务器建立一个新的 TCP 连接,这样会导致每个请求都要经历 TCP 连接的建立和释放的过程,增加了延迟和资源消耗。而使用 Keep-Alive,可以重复使用已经建立的 TCP 连接,减少了连接的建立和关闭过程。
具体而言,Keep-Alive 通过以下方式实现:
- 持久连接:在 HTTP 头部中添加
Connection: keep-alive,表示客户端希望与服务器端保持持久连接。当服务器端收到这个头部后,会在响应中回复相同的头部,表示同意持久连接。
- 复用连接:客户端发送请求后,在服务器端响应结束后,TCP 连接并不会立即关闭,而是保持打开状态,以便进行下一个请求。
- 设置超时时间:连接在一段时间内没有新的请求时会自动关闭。
使用 Keep-Alive 可以带来以下优点:
- 减少延迟:避免了 TCP 连接的建立和关闭过程,因此减少了连接的延迟。
- 减少资源消耗:连接的复用减少了服务器端的负担,并且降低了网络带宽的占用。
- 提升性能:在一个连接上可以发送多个请求,实现并行请求,减少了网络拥塞和串行请求的影响。
需要注意的是,Keep-Alive 并不是默认开启的,需要在请求头部明确指定。在 HTTP/1.1 中,Keep-Alive 是默认开启的,除非明确指定 Connection: close。而在 HTTP/2 和 HTTP/3 中,持久连接是默认开启的,不再需要单独指定。
使用 Keep-Alive 可以有效改善 HTTP 的性能,提高网络请求的效率。然而,具体的实现和支持程度可能因服务器和客户端的配置和版本而有所不同。
request 和 response 阶段
-
首先式静态资源包的体积,如何缩到极致?
- 例如 webpack 脚手架中,用 uglify,minify 插件对文件进行压缩。它们可以去除代码中的空格、注释、无效的代码,并使用各种技术(如变量重命名、函数替换等)来对文件进行压缩。
- runtime:保证运行时,垫片(polyfill)按需加载。
- Tree shaking:摇树优化是指通过静态代码分析的方式剔除掉未被使用的代码,以减少最终打包生成的代码的大小。
- 图片格式:
- 根据场景考虑能不能使用体积最小的 webp 格式
- 用 base64 图片体积会变大 1/3 倍,不用 base64 多一个 http 请求,一般情况大于 64kb 不建议用 base64
-
首屏加载的内容,如何进行分解?
- code splitting:以 vue 项目为例,首页是单独的 bundle
const routes = [
{
path: '/',
name: 'home',
component: () => import(/* webpackChunkName: "home" */ '../views/HomeView.vue'),
},
]
-
如何在 TCP 请求数量之间权衡?
- Chrome 同源下最多 6 个并发
- 在 TCP 请求数量之间存在一个权衡(tradeoff)。增加 TCP 请求的数量可以提高并发性和响应速度,但也会增加网络开销和资源消耗。反之,减少 TCP 请求的数量可以节省网络资源和降低开销,但可能会牺牲一定的并发性和响应速度。
下面是一些可以帮助你在 TCP 请求数量方面做出权衡的建议:
- 批量请求:对于需要发送多个相似请求的情况,可以将其批量处理为一个更少的请求。例如,可以使用合适的数据格式(如 JSON)将多个数据项一次性发送给服务器,从而减少请求的数量。
- 长连接和连接池:通过使用长连接和连接池,可以避免频繁建立和断开 TCP 连接的开销。长连接可以在多个请求之间保持连接状态,而连接池可以重用现有连接,从而减少连接建立和拆除的开销。
- 并发限制和调整:可以根据网络和服务器的容量限制并发请求数量。过多的并发请求可能会导致网络拥塞和服务器负载过重,从而影响性能。因此,需要找到一个合适的并发请求数量,既能满足需求,又不会过度压力网络和服务器。
- 缓存和本地存储:利用缓存和本地存储减少对服务器的请求。缓存可以在客户端保留数据的副本,以便在需要时快速访问。本地存储(如浏览器的 localStorage)可以将数据存储在客户端,避免不必要的请求,提高响应速度。
- 延迟加载和懒加载:对于大型应用或页面,可以延迟加载或懒加载一些资源,以减少初始请求的数量。只加载当前所需的资源,而不是一次性加载所有资源,可以提高初始加载速度,并根据需要动态加载其他资源。
以上是一些常见的权衡措施,可以根据具体的应用场景和需求进行调整。需要综合考虑网络环境、服务器性能、用户体验和应用需求,并根据实际情况进行优化和调整。最佳实践是进行基准测试和性能测试,以评估不同参数和策略对应用性能的影响,并找到最合适的配置。
Processing 阶段/ DOM 加载阶段
- 一般情况要将样式文件放在 head 内,因为样式文件一旦加载好就会立即渲染已经构建好的节点元素,如果样式文件放在 body 标签中间引入很容易造成回流/重排。
- 将脚本放在
- 放在
script 标签放在
- 除了上述两种常见的放置位置外,还可以使用异步加载和延迟加载来优化脚本加载行为。这些技术可以通过
async 和 defer 属性来实现,允许脚本的异步或延迟加载,以优化页面加载性能。
默认模式:
download-execute
------parse------ ------parse------
defer 模式(推迟执行模式):
download execute
------parse--------------------parse------
async 模式(异步下载模式):
download-execute
------parse--------------- ------parse------
维度 2:渲染维度
如何有效避免频繁操作 DOM?
- createDocumentFragment
- 添加列表的时候不要每列单独 appendChild,而是将所有列先存起来最后在进行 appendChild
回流与重绘
回流(reflow)和重绘(repaint)是浏览器在渲染网页时执行的两个关键过程。
回流/重排(reflow),也称为布局(layout),是浏览器根据 DOM 树中的元素和 CSS 样式计算每个元素在页面中的几何位置和大小的过程。这是一个相对昂贵的操作,需要浏览器重新计算元素的布局,并重新绘制受影响的部分。
回流会在以下情况下被触发:
- 添加、删除、修改 DOM 元素
- 修改元素的位置、尺寸(包括宽度、高度、边距、填充)
- 修改元素的内容(文字、图片)
- 浏览器窗口的尺寸变化
- 触发 CSS 动画和过渡
- 计算某些属性的值
- offsetTop、offsetLeft、offsetWidth、offsetHeight :读取这些属性会触发浏览器计算元素的布局,可能引发回流。
- clientWidth、clientHeight :读取这些属性会获取元素可见区域的宽度和高度,不会引起回流。
- scrollWidth、scrollHeight :读取这些属性会获取元素内容区域的宽度和高度,不会引起回流。
- getComputedStyle() :调用此方法可以获取元素的计算样式,由于需要获取实时计算后的样式,可能会触发回流。
- getBoundingClientRect() :调用此方法会获取元素在视口中的位置和尺寸信息,这将触发回流。
- offsetParent :读取这个属性会触发回流。
- clientTop、clientLeft :读取这些属性会获取元素的内边距的大小,不会触发回流。
- offsetParent :读取这个属性会触发回流。
当回流发生时,浏览器会从渲染树的根节点开始,递归遍历整个渲染树,确定每个元素的几何位置和大小。然后,浏览器重新绘制受影响的部分,并更新布局。
重绘(repaint) 是指浏览器根据已计算的元素样式重新绘制页面的过程,而不会影响元素的几何位置和大小。重绘是相对较快的操作,因为它只需要更新元素的可见样式。
重绘会在以下情况下被触发:
- 修改元素的颜色、背景色、文本颜色等可见样式
- 切换 CSS 类名
- 使用 CSS 伪类(:hover、:active)等
当重绘发生时,浏览器会重新绘制受影响的部分,但不会重新计算元素的布局。
回流和重绘的频繁发生会导致性能问题,因为它们会占用大量的计算资源。优化网页性能的关键是尽量减少回流和重绘的次数。
为了减少回流和重绘的次数,可以采取以下优化策略:
- 避免多次读取上述属性,在使用前先缓存起来。
- 将样式修改集中在一次操作中,可以使用 CSS 类名的切换来批量修改样式。
- 使用 CSS3 的 transform 属性来进行位移、缩放和旋转,它不会引起回流。
- 使用
requestAnimationFrame 方法来进行动画的更新,它能够优化性能并避免不必要的回流和重绘。
- 使用文档片段(
DocumentFragment)进行 DOM 操作,以减少对实际文档的修改。
CSS 的 transform 属性不会造成回流的主要原因是,它对元素进行了一种视觉上的变换,而不影响元素在布局上的位置和大小。具体原因如下:
- 硬件加速:当应用 transform 属性时,浏览器会将该元素视为一个单独的图层,并通过硬件加速来处理该图层的变换操作。因为硬件加速是在图层级别进行的,不影响其他元素的布局,所以不会触发回流。
- 独立图层:在某些情况下,浏览器会自动将某些元素创建为独立的图层,例如使用 3D 变换、透明度动画、嵌套的 CSS 动画等。这些独立的图层也能够享受硬件加速的好处,不会引起回流。
- 位置不变:transform 属性的变换并不改变元素在文档流中的位置,元素的原始位置仍然被保留。因此,当元素应用 transform 变换时,并不需要改变布局来适应变换后的状态。
需要注意的是,虽然 transform 不会引起回流,但仍然会触发重绘(repaint)。因为元素的可见样式发生了变化,浏览器需要重新绘制元素来反映变化。但相比于回流,重绘的开销要小得多。
因此,对于需要对元素进行平移、旋转、缩放等视觉上的变换操作,使用 CSS 的 transform 属性是一种推荐的做法,可以获得更好的性能和流畅的动画效果,同时避免回流的影响。
前端面试题库 (面试必备) 推荐:★★★★★
地址:前端面试题库