python pandas数据处理与简单绘图
目录
- 1.根据某列的值去重
- 2.统计属性值出现次数
- 3.根据某列的某个属性值查找
- 4.时间切分
- 5.可以写正则表达式处理
- 6.写回csv文件
- 7.KMeans聚类
- 8.绘图(条形图、饼图、折线图、热力图)
-
- 条形图
- 饼图
- 折线图
- 条形图进阶
- 热力图
1.根据某列的值去重
import pandas as pd
from dateutil.parser import *
import warnings
warnings.filterwarnings('ignore')
"""获取数据"""
df = pd.read_csv('E://data//hockey//DC_crime_analysis//block_split.csv')
"""显示数据"""
print(df.head())
# 根据BLOCK_NEW列去重
df.drop_duplicates(subset=['BLOCK_NEW'], keep='first', inplace=True)
#结果写入文件
df.to_csv("BLOCK_NEW_split.csv",sep=",")
2.统计属性值出现次数
op = pd.read_csv('E://data//hockey//DC_crime_analysis//block_split.csv')
# 统计BLOCK_NEW每个属性出现次数
df2=op.BLOCK_NEW.value_counts()
#结果写入文件
target=pd.DataFrame(df2)
target.to_csv("BLOCK_NEW_sum.csv",sep=",")
#获取BLOCK_NEW列属性值ARSON的数量
print(op.BLOCK_NEW.value_counts(0)["ARSON"])
# 根据BLOCK_NEW合并两张表
tar1=pd.read_csv("BLOCK_NEW_sum.csv")
tar2=pd.read_csv("BLOCK_NEW_split.csv")
target1=pd.merge(tar1,tar2,on='BLOCK_NEW')
target1.to_csv("BLOCK_NEW_xy.csv",sep=",")
3.根据某列的某个属性值查找
#查找OFFENSE列中属性值为ROBBERY的列
robbery = df[df.OFFENSE.str.contains('ROBBERY')]
#输出结果的行列,类似(10,5),10条记录,5列
print(robbery.shape)
"""统计METHOD列属性值对应的记录条目数,降序输出"""
print(robbery.groupby('METHOD').size().sort_values(ascending=False))
4.时间切分
"""对时间数据START_DATE列进行切分,加入robbery变成新的一列month"""
robbery["month"] = robbery.START_DATE.apply(lambda x: parse(x).month)
robbery["hour"] = robbery.START_DATE.apply(lambda x: parse(x).hour)
5.可以写正则表达式处理
regex = r"\d+\s*\-*\s*\d+\s*(?P.*)"
subst = "\\g"
op1 = pd.read_csv('E://data//hockey//DC_crime_analysis//Crime_Incidents_in_2019.csv')
op1["BLOCK_NEW"]=op1.BLOCK.str.replace(regex, subst) # 正则表达式的格式
6.写回csv文件
robbery.to_csv("tocsvfile.csv",sep=",")
7.KMeans聚类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
import pandas as pd
#显示图像
import pylab
tar1=pd.read_csv("BLOCK_NEW_xy.csv",usecols=[2,4,5])
print(tar1.head())
# 绘制数据分布图
plt.figure(figsize=(10, 10))
plt.scatter(tar1.X.loc[:], tar1.Y.loc[:], c="red", marker='o', label='BLOCK_NEW')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend(loc=2)
plt.show()
estimator = KMeans(n_clusters=5) # 构造聚类器 ,5类
estimator.fit(tar1) # 聚类
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果___5类
x0 = tar1[label_pred == 0]
x1 = tar1[label_pred == 1]
x2 = tar1[label_pred == 2]
x3= tar1[label_pred == 3]
x4= tar1[label_pred == 4]
#输出聚类结果
print("第1类")
print(x0)
print("第2类")
print(x1)
print("第3类")
print(x2)
print("第4类")
print(x3)
print("第5类")
print(x4)
#绘图
plt.figure(figsize=(10, 10))
plt.scatter(x0.X.loc[:], x0.Y.loc[:], c="red", marker='o', label='label0')
plt.scatter(x1.X.loc[:], x1.Y.loc[:], c="blue", marker='o', label='label1')
plt.scatter(x2.X.loc[:], x2.Y.loc[:], c="green", marker='o', label='label2')
plt.scatter(x3.X.loc[:], x3.Y.loc[:], c="purple", marker='o', label='label3')
plt.scatter(x4.X.loc[:], x4.Y.loc[:], c="yellow", marker='o', label='label4')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend(loc=2)
plt.show()
"""聚类结果评价指标"""
import sklearn.metrics
score = sklearn.metrics.silhouette_score(tar1,label_pred)
print(score)
聚类数为2-15,依次计算聚类结果并评价,然后绘制折线图
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
import pandas as pd
#显示图像
import pylab
import sklearn.metrics
tar1=pd.read_csv("BLOCK_NEW_xy.csv",usecols=[2,4,5])
print(tar1.head())
sse = []
score=[]
"""聚类数为2-15,依次计算聚类结果并评价,然后绘制折线图"""
for i in range(2, 15):
mid = KMeans(n_clusters=i)# 最终聚类个数为i
mid.fit(tar1)
label_pred = mid.labels_ # 获取聚类标签
score.append(sklearn.metrics.silhouette_score(tar1,label_pred))
sse.append(mid.inertia_) # 每次的距离,14个元素,SSE
print(sse)
plt.plot(range(2, 15), sse, marker='o')
# plt.plot(range(2,15),score,marker='*')
plt.xlabel('k')
plt.ylabel('SSE')
plt.show()
print(score)
plt.figure()#figsize=(10, 10)
plt.plot(range(2,15),score,marker='*')
plt.xlabel('k')
plt.ylabel('score')
plt.show()
8.绘图(条形图、饼图、折线图、热力图)
条形图
import pandas as pd
from dateutil.parser import *
import warnings
warnings.filterwarnings('ignore')
"""获取数据"""
df = pd.read_csv('E://data//hockey//DC_crime_analysis//Crime_Incidents_in_2019.csv')
print(df.head())
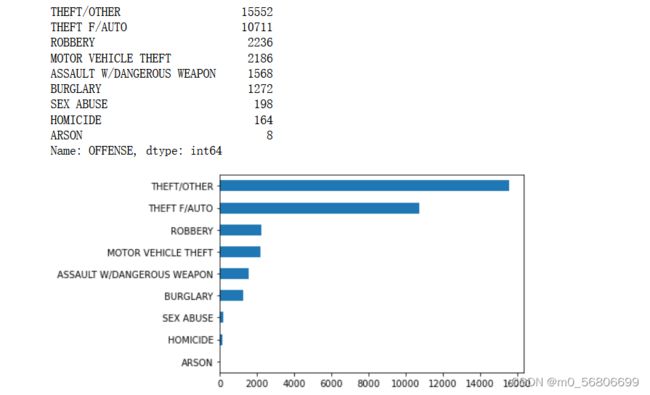
"""统计OFFENSE列属性值出现的次数,绘图为横向条形图"""
print(df.OFFENSE.value_counts().iloc[:9])# OFFENSE是列名,计数并取前9类
ax = df.OFFENSE.value_counts().iloc[:9].sort_values().plot.barh()
fig = ax.get_figure()
fig.savefig('统计结果.png',bbox_inches='tight')
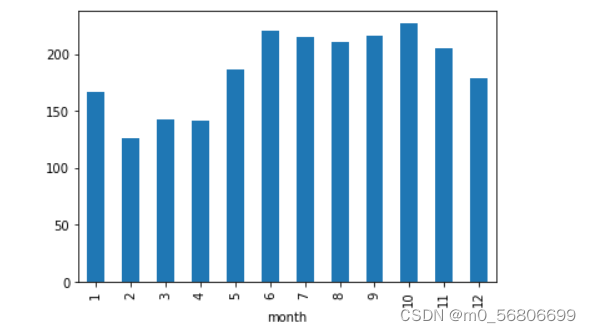
"""竖直条形图"""
ax = robbery.groupby('month').size().plot.bar()
fig = ax.get_figure()
fig.savefig('统计.png')
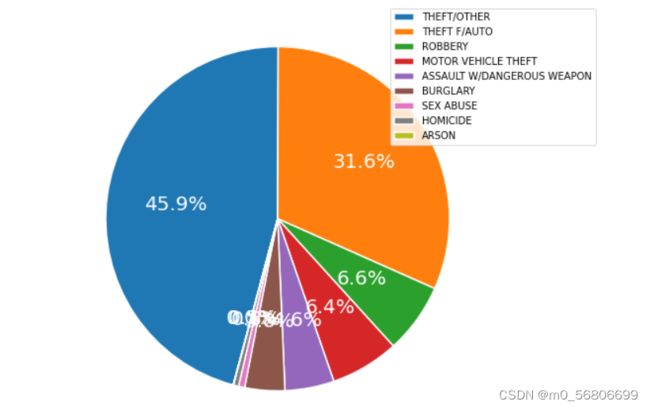
饼图
# 饼图的绘制
# 构建序列
data = df.OFFENSE.value_counts().iloc[:9]
# 将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data.name = ''
# 控制饼图为正圆
plt.axes(aspect = 'equal')
# plot方法对序列进行绘图
ax00=data.plot(kind = 'pie', # 选择图形类型
autopct='%.1f%%', # 饼图中添加数值标签
radius = 2, # 设置饼图的半径
startangle = 255, # 设置饼图的初始角度
counterclock = False, # 将饼图的顺序设置为顺时针方向
title = '', # 为饼图添加标题
wedgeprops = {'linewidth': 1.5, 'edgecolor':'white'}, # 设置饼图内外边界的属性值
textprops = {'fontsize':20, 'color':'white'}, # 设置文本标签的属性值
legend=True
)
ax00.legend(bbox_to_anchor=(1, 1.5), loc='upper left')
# 显示图形
plt.show()
折线图
#折线图
fig, ax = plt.subplots()
#按hour列分类并计数
line3, = ax.plot(robbery.groupby('hour').size().iloc[:], label="2019", linestyle='--')
line4, = ax.plot(robbery2.groupby('hour').size().iloc[:], label="2020", linewidth=2)
# Create a legend for the first line.
first_legend = ax.legend(handles=[line3], loc='upper right')
# Add the legend manually to the Axes.
ax.add_artist(first_legend)
# Create another legend for the second line.
ax.legend(handles=[line4], loc='lower right')
plt.show()

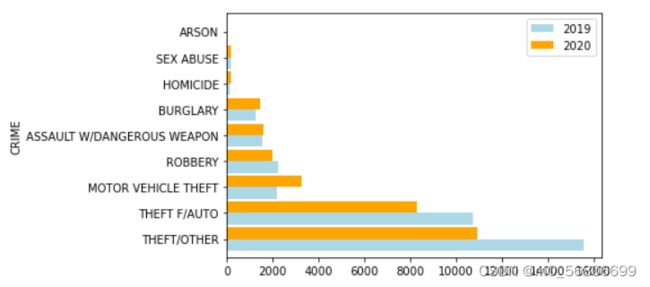
条形图进阶
df2_crime=[]
df_crime=[]
#crime_po是OFFENSN列的属性值
crime_po=['THEFT/OTHER',
'THEFT F/AUTO' ,
'MOTOR VEHICLE THEFT',
'ROBBERY',
'ASSAULT W/DANGEROUS WEAPON' ,
'BURGLARY' ,
'HOMICIDE',
'SEX ABUSE',
'ARSON' ]
#统计OFFENSN列各属性值的数目
for i in range(len(crime_po)):
df2_crime.append(df2.OFFENSE.value_counts(0)[crime_po[i]])
df_crime.append(df.OFFENSE.value_counts(0)[crime_po[i]])
dfi = pd.DataFrame({"date_x":[2019]*9,
"Occurance_x":df_crime,
"CRIME":crime_po,
"date_y":[2020]*9,
"Occurance_y":df2_crime})
ax = dfi[["CRIME","Occurance_x","Occurance_y"]].plot(x='CRIME',
kind='barh',
color=["lightblue","orange"],
width=0.9,
rot=0)
ax.legend(["2019","2020"], loc='upper right');
热力图
import numpy as np
from matplotlib import pyplot as plt
from matplotlib import cm
from matplotlib import axes
# 定义热图的横纵坐标
xLabel = ['dawn', 'morning', 'noon', 'afternoon', 'evening','midnight']
yLabel = ['W1', 'W2', 'W3', 'W4', 'W5','W6','W7']
# 准备数据阶段
data1=[[ 77, 37, 28, 26, 27, 38, 71],
[ 18, 26, 26, 28, 35, 24, 16],
[ 24, 30 , 24, 42, 34, 30, 24],
[ 44 , 62 , 69, 77, 60, 74, 52],
[ 84, 77, 80, 75, 84, 74, 64],
[111 , 70, 58, 72, 72, 88, 104]]
# 作图阶段
fig = plt.figure()
# 定义画布为1*1个划分,并在第1个位置上进行作图
ax = fig.add_subplot(111)
# 定义横纵坐标的刻度
ax.set_xticks(range(len(yLabel)))
ax.set_xticklabels(yLabel)
ax.set_yticks(range(len(xLabel)))
ax.set_yticklabels(xLabel)
# 作图并选择热图的颜色填充风格,这里选择hot
im = ax.imshow(data1, cmap=plt.cm.Blues)
# 增加右侧的颜色刻度条
plt.colorbar(im)
# 增加标题
plt.title("week_time_pic")
# show
plt.show()
