Python接口自动化之正则用例参数化
前言
我们在做接口自动化的时候,处理接口依赖的相关数据时,通常会使用正则表达式来进行提取相关的数据。
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(Regular Expression,在代码中常简写为regex、regexp或RE) 。它是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。在很多文本编辑器里,正则表达式通常被用来检索、替换那些匹配某个模式的文本。而Python 自1.5版本起增加了re模块,它提供 Perl 风格的正则表达式模式。
一、正则表达式语法
1.1表示单字符
单字符:即表示一个单独的字符,比如匹配数字用\d,匹配非数字用\D。
除以下语法,也可以匹配指定的具体字符,可以是1个也可以是多个。
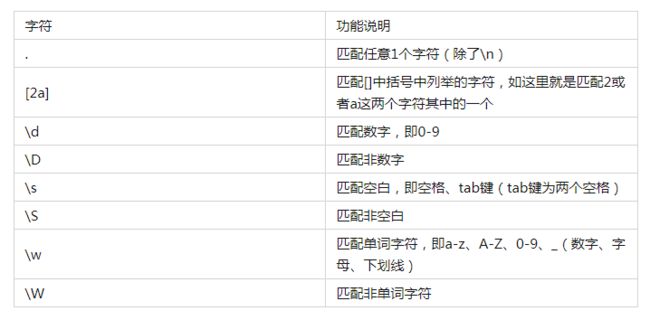
实例如下,这里先说明一下findall(匹配规则,要匹配的字符串)这个方法是查找所有匹配的数据,以列表的形式返回,后面会在re模块进行详解:
import re
# .:匹配任意1个字符
re1 = r'.'
res1 = re.findall(re1, '\nj8?0\nbth\nihb')
print(res1) # 运行结果:['j', '8', '?', '0', 'b', 't', 'h', 'i', 'h', 'b']
# []:匹配列举中的其中一个
re2 = r"[abc]"
res2 = re.findall(re2, '1iugfiSHOIFUOFGIDHFGFD2345a6a78b99cc')
print(res2) # 运行结果:['a', 'a', 'b', 'c', 'c']
# \d:匹配一个数字
re3 = r"\d"
res3 = re.findall(re3, "dfghjkl32212dfghjk")
print(res3) # 运行结果:['3', '2', '2', '1', '2']
# \D:匹配一个非数字
re4 = r"\D"
res4 = re.findall(re4, "d212dk?\n$%3;]a")
print(res4) # 运行结果:['d', 'd', 'k', '?', '\n', '$', '%', ';', ']', 'a']
# \s:匹配一个空白键或tab键(tab键实际就是两个空白键)
re5 = r"\s"
res5 = re.findall(re5,"a s d a 9999")
print(res5) # 运行结果:[' ', ' ', ' ', ' ', ' ']
# \S: 匹配非空白键
re6 = r"\S"
res6 = re.findall(re6, "a s d a 9999")
print(res6) # 运行结果:['a', 's', 'd', 'a', '9', '9', '9', '9']
# \w:匹配一个单词字符(数字、字母、下划线)
re7 = r"\w"
res7 = re.findall(re7, "ce12sd@#a as_#$")
print(res7) # 运行结果:['c', 'e', '1', '2', 's', 'd', 'a', 'a', 's', '_']
# \W:匹配一个非单词字符(不是数字、字母、下划线)
re8 = r"\W"
res8 = re.findall(re8, "ce12sd@#a as_#$")
print(res8) # 运行结果:['@', '#', ' ', '#', '$']
# 匹配指定字符
re9 = r"python"
res9 = re.findall(re9, "cepy1thon12spython123@@python")
print(res9) # 运行结果:['python', 'python']1.2表示数量
如果要匹配某个字符多次,就可以在字符后面加上数量进行表示,具体规则如下:
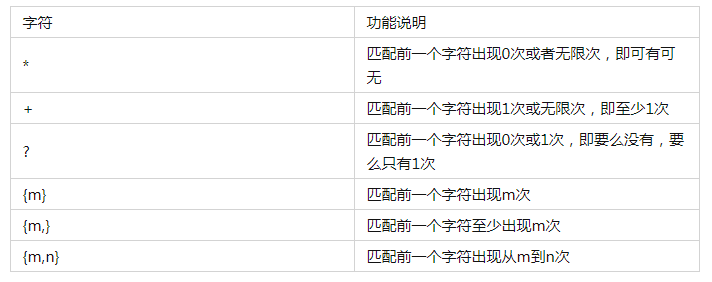
实例如下:
import re
# *:表示前一个字符出现0次以上(包括0次)
re21 = r"\d*" # 这里匹配的规则,前一个字符是数字
res21 = re.findall(re21, "343aa1112df345g1h6699") # 如匹配到a时,属于符合0次,但因为没有值所以会为空
print(res21) # 运行结果:['343', '', '', '1112', '', '', '345', '', '1', '', '6699', '']
# ? : 表示0次或者一次
re22 = r"\d?"
res22 = re.findall(re22, "3@43*a111")
print(res22) # 运行结果:['3', '', '4', '3', '', '', '1', '1', '1', '']
# {m}:表示匹配一个字符m次
re23 = r"1[3456789]\d{9}" # 手机号:第1位为1,第2位匹配列举的其中1个数字,第3位开始是数字,且匹配9次
res23 = re.findall(re23,"sas13566778899fgh256912345678jkghj12788990000aaa113588889999")
print(res23) # 运行结果:['13566778899', '13588889999']
# {m,}:表示匹配一个字符至少m次
re24 = r"\d{7,}"
res24 = re.findall(re24, "sas12356fgh1234567jkghj12788990000aaa113588889999")
print(res24) # 运行结果:['1234567', '12788990000', '113588889999']
# {m,n}:表示匹配一个字符出现m次到n次
re25 = r"\d{3,5}"
res25 = re.findall(re25, "aaaaa123456ghj333yyy77iii88jj909768876")
print(res25) # 运行结果:['12345', '333', '90976', '8876']1.2.1匹配分组

实例如下:
import re
# 同时定义多个规则,只要满足其中一个
re31 = r"13566778899|13534563456|14788990000"
res31 = re.findall(re31, "sas13566778899fgh13534563456jkghj14788990000")
print(res31) # 运行结果:['13566778899', '13534563456', '14788990000']
# ():匹配分组:在匹配规则的数据中提取括号里的数据
re32 = r"aa(\d{3})bb" # 如何数据符合规则,结果只会取括号中的数据,即\d{3}
res32 = re.findall(re32, "ggghjkaa123bbhhaa672bbjhjjaa@45bb")
print(res32) # 运行结果:['123', '672']1.3 表示边界
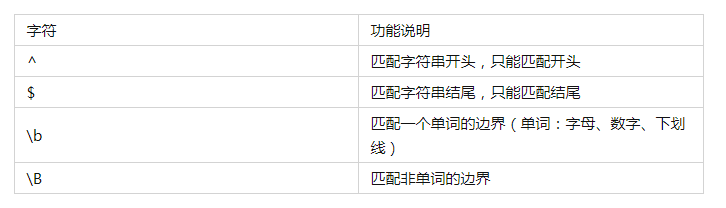
实例如下:
import re
# ^:匹配字符串的开头
re41 = r"^python" # 字符串开头为python
res41 = re.findall(re41, "python999python") # 只会匹配这个字符串的开头
res411 = re.findall(re41, "1python999python") # 因为开头是1,第1位就不符合了
print(res41) # 运行结果:['python']
print(res411) # 运行结果:[]
# $:匹配字符串的结尾
re42=r"python$" # 字符串以python结尾
res42 = re.findall(re42, "python999python")
print(res42) # 运行结果:['python']
# \b:匹配单词的边界,单词即:字母、数字、下划线
re43 = r"\bpython" # 即匹配python,且python的前一位是不是单词
res43 = re.findall(re43, "1python 999 python") # 这里第1个python的前1位是单词,因此第1个是不符合的
print(res43) # 运行结果:['python']
# \B:匹配非单词的边界
re44 = r"\Bpython" # 即匹配python,且python的前一位是单词
res44 = re.findall(re44, "1python999python")
print(res44) # 运行结果:['python', 'python']二、贪婪模式
python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符,而非贪婪模式则是尝试匹配尽可能少的字符,在表示数量的表达式后加上问号(?)就可以关闭贪婪模式。
如下例子,匹配2个以上的数字,如果符合条件它会一直匹配到不符合才停止,如其中的34656fya,34656符合2个数字以上,那么它会一直匹配到6为止,如果关闭贪婪模式,那么在满足2个数字时就会停止,最后可以匹配到34、65。
import re
# 默认的贪婪模式下
test = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']
# 关闭贪婪模式
res2 = re.findall(r'\d{2,}?', test)
print(res2) # 运行结果:['12', '34', '65', '12', '12']三、re模块
在python中使用正则表达式,就会用到re模块来进行操作,提供的方法一般需要传入两个参数:
- 参数1: 匹配的规则
- 参数2:要进行匹配的字符串
3.1 re.findall()
查找所有符合规范的字符串,以列表的形式返回。
import re
test = 'aa123aaaa34656fyaa12a123d'
res = re.findall(r'\d{2,}', test)
print(res) # 运行结果:['123', '34656', '12', '123']3.2re.search()
查找第一个符合规范的字符串,返回的是一个匹配对象,可以通过group()将匹配到的数据直接提取出来。
import re
s = "123abc123aaa123bbb888ccc"
res2 = re.search(r'123', s)
print(res2) # 运行结果:
# 通过group将匹配到的数据提取出来,返回类型为str
print(res2.group()) # 运行结果:123 返回的匹配对象中,span为匹配到的数据的下标范围,match则是匹配到的值。
group()参数说明:
- 不传参数:获取的是匹配到的所有内容
- 传入数值:可以通过参数来指定,获取第几个分组中的内容(获取第1个分组,传入参数1,获取第2个分组,传入参数2,依次类推。)
import re
s = "123abc123aaa123bbb888ccc"
re4 = r"aaa(\d{3})bbb(\d{3})ccc" # 这里分组就是前面说到的匹配语法:()
res4 = re.search(re4, s)
print(res4)
# group不传参数:获取的是匹配到的所有内容
# group通过参数指定,获取第几个分组中的内容(获取第1个分组,传入参数1,获取第2个分组,传入参数2,依次类推..
print(res4.group())
print(res4.group(1))
print(res4.group(2))3.3 re.match()
从字符串的起始位置进行匹配,匹配成功则返回匹配到的对象,如果开头的位置不符合匹配的规则,不会继续往后面去匹配,直接返回None。re.match()与re.search()都是只匹配一个,不一样的是,前者只匹配字符串的开头,后者则是会匹配整个字符串,但只获取第一个符合的数据。
import re
s = "a123abc123aaa1234bbb888ccc"
# match:只匹配字符串的开头,开头不符合就返回None
res1 = re.match(r"a123", s)
res2 = re.match(r"a1234", s)
print(res1) # 运行结果:
print(res2) # 运行结果:None 3.4re.sub()
检索和替换:用于替换字符串中的匹配项
re.sub()参数说明:
- 参数1:待替换的字符串
- 参数2:目标字符串
- 参数3:要进行替换操作的字符串
- 参数4:可以指定最多替换的次数,非必填(默认替换所有符合规范的字符串)
import re
s = "a123abc123aaa123bbb888ccc"
# 参数1:待替换的字符串
# 参数2:目标字符串
# 参数3:要进行替换操作的字符串
# 参数4:可以指定最多替换的次数,非必填(默认替换所有符合规范的字符串)
res5 = re.sub(r'123', "666", s, 4)
print(res5) # 运行结果:a666abc666aaa666bbb888ccc四、用例参数化
在接口自动化测试中,我们的测试数据都是保存在excel中的,有些参数如果写死一个数据,可能换个场景或者换个环境就不能用了,那么切换环境时就需要先把新环境的测试数据准备好,并且能支持去跑我们的脚本,或者把excel的数据修改为适合新环境的测试数据,维护的成本较高。因此就需要把我们的自动化脚本测试数据尽量地参数化,降低维护成本。
我们先看简单版的参数化,以登录为例,登录时用到的账号、密码等信息都可以提取出来放到配置文件,修改数据或更换环境时直接在配置文件中统一修改就可以了。

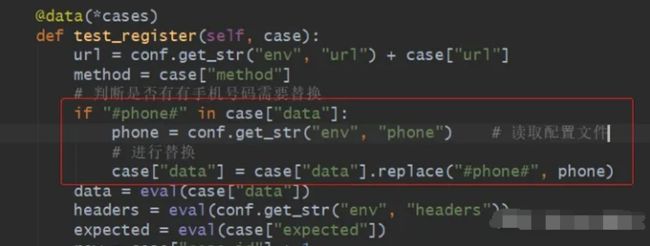
但如果有多个不同的数据需要参数化呢,每个参数都加个判断去替换数据吗?这样的代码既啰嗦又不好维护,这时re模块就可以用上了,直接看一个实例:
import re
from common.myconfig import conf
class TestData:
"""用于临时保存一些要替换的数据"""
pass
def replace_data(data):
r = r"#(.+?)#" # 注意这个分组()内的内容
# 判断是否有需要替换的数据
while re.search(r, data):
res = re.search(r, data) # 匹配出第一个要替换的数据
item = res.group() # 提取要替换的数据内容
key = res.group(1) # 获取要替换内容中的数据项
try:
# 根据替换内容中的数据项去配置文件中找到对应的内容,进行替换
data = data.replace(item, conf.get_str("test_data", key))
except:
# 如果在配置文件中找不到就在临时保存的数据中找,然后替换
data = data.replace(item, getattr(TestData, key))
return data 注意这里的正则表达式是有使用?关闭贪婪模式的,因为测试数据中可能会需要参数化2个或以上的数据,如果不关闭贪婪模式,它就只能匹配搭配一个数据,举例如下:
import re
data = '{"mobile_phone":"#phone#","pwd":"#pwd#","user":#user#}'
r1 = "#(.+)#"
res1 = re.findall(r1, data)
print(res1) # 运行结果:['phone#","pwd":"#pwd#","user":#user'] 注意这里单引号只有一个数据
print(len(res1)) # 运行结果:1
r2 = "#(.+?)#"
res2 = re.findall(r2, data)
print(res2) # 运行结果:['phone', 'pwd', 'user']
print(len(res2)) # 运行结果:3另外提到的一个用于临时保存数据的类,这里主要用于保存接口返回的数据,因为有些测试数据是动态变化的,可能要依赖于某个接口,后面的测试用例又需要这些数据,那么我们在接口返回时就可以保存到这个类里作为一个类属性,接着在需要用这个数据的测试用例时,把这个类属性提取出来替换到测试数据中即可。提示:设置属性setattr(对象, 属性名, 属性值),获取属性值getattr(对象, 属性名)。
最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

软件测试面试小程序
被百万人刷爆的软件测试题库!!!谁用谁知道!!!全网最全面试刷题小程序,手机就可以刷题,地铁上公交上,卷起来!
涵盖以下这些面试题板块:
1、软件测试基础理论 ,2、web,app,接口功能测试 ,3、网络 ,4、数据库 ,5、linux
6、web,app,接口自动化 ,7、性能测试 ,8、编程基础,9、hr面试题 ,10、开放性测试题,11、安全测试,12、计算机基础

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!