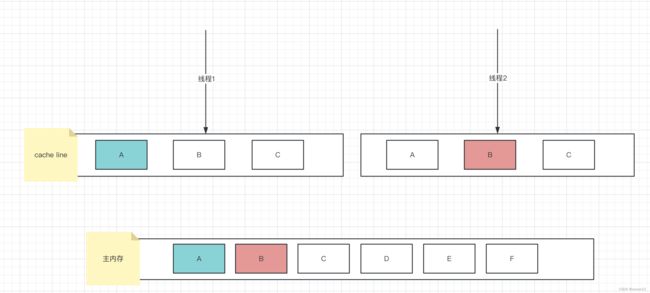
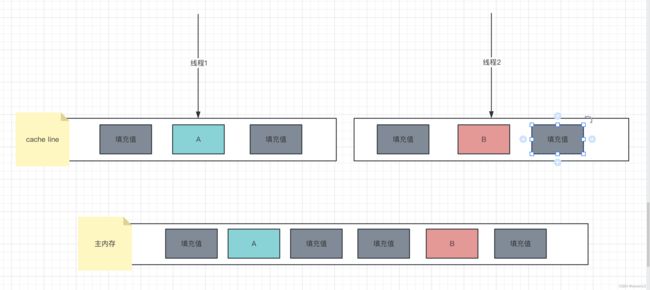
- Netty基础—Netty实现私有协议栈
工业甲酰苯胺
netty
1.私有协议介绍(1)什么是私有协议跨节点的远程服务调用(跨节点通信),除了链路层的物理连接外,还需要对请求和响应消息进行编解码。在请求和应答消息本身以外,也需要携带一些其他控制和管理类指令。例如链路建立的握手请求和响应消息、链路检测的心跳消息等。当这些功能组合到一起后就会形成私有协议。私有协议并没有标准的定义,只要是能够用于跨进程、跨主机数据交换的非标准协议,都可以称为私有协议。(2)公有协议与
- redis长时间未请求,无法自动重连,报异常org.springframework.data.redis.RedisSystemException
小池先生
redis数据库缓存
org.springframework.data.redis.RedisSystemException:Redisexception;nestedexceptionisio.lettuce.core.RedisException:io.netty.channel.unix.Errors$NativeIoException:readAddress(..)failed:Connectionresetb
- Netty基础—6.Netty实现RPC服务三
东阳马生架构
Netty应用与源码NettyRPC服务
大纲1.RPC的相关概念2.RPC服务调用端动态代理实现3.Netty客户端之RPC远程调用过程分析4.RPC网络通信中的编码解码器5.Netty服务端之RPC服务提供端的处理6.RPC服务调用端实现超时功能5.Netty服务端之RPC服务提供端的处理(1)RPC服务提供端NettyServer(2)基于反射调用请求对象的目标方法(1)RPC服务提供端NettyRpcServerpubliccla
- Mina 框架
武涛的技术博客
java框架技术服务器netty
java服务器端开发。J2SE、TCP/UDP协议。mina与netty都是TrustinLee的作品,异步的NIO框架,将UDP当成"面向连接"的协议一、组件管理Mina的底层依赖的主要是JavaNIO库,上层提供的是基于事件的异步接口(1)IoService(最底层[起点])作用:隐藏底层IO的细节,对上提供统一的基于事件的异步IO接口IOSocketAcceptor和IOSocketChan
- socket.io netty java,netty-socketio启动报错
weixin_39726131
socket.ionettyjava
io.netty.channel.ChannelException:UnabletocreateChannelfromclassclassio.netty.channel.socket.nio.NioServerSocketChannelatio.netty.channel.ReflectiveChannelFactory.newChannel(ReflectiveChannelFactory.j
- 基于netty手写Tomcat
Aiden_Coding
nettyjavanettyspringtomcat
基于netty手写Tomcatnetty简介1.环境准备2.基于传统I/O手写Tomcat3.基于netty手写Tomcat4.访问netty简介Netty一个基于NIO的客户、服务器端的编程框架1.环境准备maven依赖io.nettynetty-all4.1.42.FinalRequestMethodEnum请求方式publicenumRequestMethodEnum{GET("GET"),
- SpringBoot整合Netty
晚上睡不着!
#SpringBootspringbootniowebsockettcp/iphttp
前言Netty是一个高性能、异步事件驱动的网络应用程序框架,用于快速开发可维护的高并发协议服务器和客户端。Netty主要基于JavaNIO实现,提供了异步和事件驱动的网络编程工具,简化了TCP和UDP服务器的编程。Netty广泛应用于分布式系统、实时通信、游戏开发等领域,例如,知名的Elasticsearch和Dubbo框架内部都采用了Netty。Netty吸收了多种协议的实现经验,经过精心设计,
- Netty基础—4.NIO的使用简介二
东阳马生架构
Netty应用与源码Netty网络java
大纲1.Buffer缓冲区2.Channel通道3.BIO编程4.伪异步IO编程5.改造程序以支持长连接6.NIO三大核心组件7.NIO服务端的创建流程8.NIO客户端的创建流程9.NIO优点总结10.NIO问题总结4.伪异步IO编程(1)BIO的主要问题(2)BIO编程模型的改进(3)伪异步IO编程(4)伪异步IO的问题(5)伪异步IO可能引起的级联故障(1)BIO的主要问题BIO的主要问题在于
- 深入理解 Reactor Netty 线程配置及启动命令设置
C20611
Javaspringcloudspringjava开发语言
一、引言在使用SpringBoot开发基于ReactorNetty的应用程序时,合理配置ReactorNetty的线程参数对于优化应用性能至关重要。本文将详细介绍reactor.netty.ioSelectCount和reactor.netty.ioWorkerCount这两个关键参数的作用、不同设置值的影响,以及如何在不同环境的启动命令中进行设置。二、ReactorNetty线程参数介绍2.1r
- java线程池最大线程数_Java项目中,线程池中线程数量太大会有什么影响?
徐佳昇
java线程池最大线程数
1.线程栈是需要分配内存空间的,所以有数量上限2.cpu切换线程涉及到上下文恢复,这个是需要耗费时间的,如果线程非常多而且切换频繁(处理IO密集任务),这个时间损耗是非常可观的。线程池应该设置多大,取决于你处理的任务类型。对于CPU密集型的任务,因为线程中基本不会有阻塞导致让出CPU,只有在时间片用完以后,才可能让出CPU,这种情况发生线程切换的次数要少很多,因此不建议设置太大,netty的建议是
- netty做一个posp的网络_Java网络通信基础系列-Netty实现HTTP服务
weixin_39748928
netty做一个posp的网络
一.Netty实现HTTP服务HTTP程序开发:在进行WEB开发过程之中,HTTP是主要的通讯协议,但是你千万要记住一个问题,HTTP都是基于TCP协议的一种应用,HTTP是在TCP的基础上完善出来的。TCP是一种可靠的连接协议,所以TCP的执行性能未必会高。据说google正在开发HTTP3.0技术标准,并且这个技术里面将使用UDP协议作为HTTP基础协议。HTTP里面存在有请求模式:A:HTT
- Netty入门教程
Kale又菜又爱玩
java开发语言
Netty入门教程Netty是一个高性能、低延迟的网络通信框架,广泛应用于高并发、高吞吐量的网络应用程序中。它提供了简洁易用的API,封装了底层的复杂操作,让开发者能够专注于业务逻辑。本文将从基础概念入手,逐步深入Netty的核心组件、使用方法及高级特性,帮助你在生产环境中得心应手地使用Netty。1.什么是Netty?Netty是一个异步、事件驱动的网络通信框架,极大地简化了TCP和UDP网络编
- 历史文章汇总
Nuan_Feng
java
仿照实现项目Nettygit地址VPNgit地址TCP、HTTP、WebSocket、SOCKS5、DNS协议实现git地址实现DNS协议java版java实现socks5Txlcn手写分布式id生成器git地址手写分布式id生成器手写可视化逆向工程git地址手写可视化逆向工程源码解析1.xxljob,阅读3.2w收藏318点赞数124xxljob源码解析2.netty源码解析netty源码解析一
- 探秘 Netty 通信中的 SslHandler 类:保障网络通信安全的基石
小园子的小菜
netty安全web安全nettyjava
引言在当今数字化时代,网络安全是每一个应用程序都必须重视的关键因素。尤其是在数据传输过程中,防止数据被窃取、篡改至关重要。Netty作为一个高性能的网络编程框架,为开发者提供了强大的功能来构建可靠的网络应用。其中,SslHandler类在保障数据传输安全方面扮演着核心角色,它使得Netty应用能够轻松实现SSL/TLS加密通信。本文将深入剖析Netty通信中的SslHandler类,探讨其工作原理
- java 自定义协议_Netty实现自定义协议
林John
java自定义协议
关于协议,使用最为广泛的是HTTP协议,但是在一些服务交互领域,其使用则相对较少,主要原因有三方面:HTTP协议会携带诸如header和cookie等信息,其本身对字节的利用率也较低,这使得HTTP协议比较臃肿,在承载相同信息的情况下,HTTP协议将需要发送更多的数据包;HTTP协议是基于TCP的短连接,其在每次请求和响应的时候都需要进行三次握手和四次挥手,由于服务的交互设计一般都要求能够承载高并
- 项目笔记——RPC框架
NUAA庞
其他
文章目录RPC知识流程图什么是RPC为什么用RPC,不用HTTP(拓展)技术栈流程服务注册意义/场景test服务的POJO类服务信息服务实例注册模块主体注册到注册中心注册中心注销场景注销的钩子函数及前置注册中心注销远程调用意义定义接口test重写jdk动态代理的invoke拓展服务发现负载均衡知识使用网络传输netty知识POJO类netty心跳场景及简介串联其它模块消费端生产端业务处理场景实现粘
- 聊聊Netty那些事儿之Reactor在Netty中的实现(创建篇)
Java小海.
java开发语言后端程序人生springboot
本系列Netty源码解析文章基于4.1.56.Final版本在上篇文章《聊聊Netty那些事儿之从内核角度看IO模型》中我们花了大量的篇幅来从内核角度详细讲述了五种IO模型的演进过程以及ReactorIO线程模型的底层基石IO多路复用技术在内核中的实现原理。最后我们引出了netty中使用的主从ReactorIO线程模型。通过上篇文章的介绍,我们已经清楚了在IO调用的过程中内核帮我们搞了哪些事情,那
- 深入剖析 Netty:高性能网络编程框架的奥秘
艾斯比的日常
网络
引言在当今高并发的网络应用场景下,对网络编程的性能要求越来越高。Netty作为一个基于JavaNIO构建的高性能网络编程框架,凭借其卓越的性能表现,在众多网络应用中得到了广泛的应用。本文将深入剖析Netty性能高的原因,帮助开发者更好地理解和使用Netty。一、异步非阻塞I/O模型1.1传统阻塞I/O的困境在传统的阻塞I/O模型中,当一个线程进行I/O操作时,它会被阻塞,直到操作完成。这意味着在高
- Orleans7.0 游戏服务器全栈开发实战
unity
本课程目标是从零开始搭建一套基于微软Orleans和DotNetty开源方案的游戏服务器框架,框架遵守Actor模型,可以充分利用多核,方便水平扩展。并且使用.NET平台,开发和部署都非常便捷。为了演示功能,也实现了一个简单的Unity客户端框架,最后使用这个框架实现了一个井字棋的对战小案例,来教会大家学以致用。这个案例演示了如何登录、开房间、匹配、对战、结算以及断线重连等一系列回合制游戏的关键节
- Netty是怎么实现Java NIO多路复用的?(源码)
åå
中间件JavaIONettyjavanio后端
目录NIO多路复用实现事件循环是什么?核心源码(1)调用NioEventLoopGroup默认构造器(2)指定SelectorProvider(3)创建`Selector`(4)创建单线程和队列(5)单线程处理就绪IO事件最近想再巩固一下NIO等多路复用的实现思路,本文通过Netty源码来进一步总结NIO多路复用的运用。先上一组简单的NIO多路复用实现,NIO多路复用实现服务端通过selector
- 带你吃透(Netty+Redis+ZooKeeper+高并发实战)从底层原理开始剖析
java熬夜党
Javajava面试redis
前言今天给大家分享的Netty+Redis+ZooKeeper底层原理+高并发实战,希望大家认真阅读,跟上文章的节奏,一步步去提升自己~大公司的面试题从某个侧面映射出生产场景中对专项技术的要求。高并发的面试题以前基本是BAT等大公司的专利,现在几乎蔓延至与Java项目相关的整个行业。例如,与JavaNIO、Reactor模式、高性能通信、分布式锁、分布式ID、分布式缓存、高并发架构等技术相关的面试
- Netty是如何实现零拷贝的?
java1234_小锋
javajava
大家好,我是锋哥。今天分享关于【Netty是如何实现零拷贝的?】面试题。希望对大家有帮助;Netty是如何实现零拷贝的?1000道互联网大厂Java工程师精选面试题-Java资源分享网Netty是一个高性能的Java网络应用框架,它通过多种技术实现了“零拷贝”(Zero-Copy)机制,以提高数据传输的效率,减少CPU的使用率和内存的消耗。零拷贝指的是在数据传输过程中,避免不必要的内存拷贝,提高处
- Netty为什么性能很高?
java1234_小锋
javajava开发语言
大家好,我是锋哥。今天分享关于【Netty为什么性能很高?】面试题。希望对大家有帮助;Netty为什么性能很高?1000道互联网大厂Java工程师精选面试题-Java资源分享网Netty是一款高性能的网络通信框架,主要用于构建高性能的网络应用程序。其高性能的原因可以归结为以下几个方面:1.NIO(Non-blockingI/O)模型Netty基于JavaNIO(即非阻塞I/O)API,能够实现异步
- netty 与 websocket
JIU_WW
websocket网络协议网络nettyjava
目录1.Netty简介2.WebSocket简介3.Netty与WebSocket的关系3.1Netty对WebSocket的支持3.2两者的层级关系3.3常见误解澄清4.Netty的通用性体现4.1多协议支持4.2非WebSocket应用示5.选择Netty实现WebSocket的优势6.总结1.Netty简介Netty是一个高性能、异步事件驱动的网络应用框架,专为开发可扩展和高性能的服务器与客
- Netty长连接
JIU_WW
nettywebsocketjavatcp
1.长连接的概念目录1.长连接的概念2.Netty对长连接的支持2.1内置协议支持2.2连接状态管理2.3资源优化3.Netty长连接与WebSocket的关系4.实现长连接的两种典型方式4.1基于TCP自定义协议4.2基于WebSocket5.长连接的关键优化策略6.性能对比:Nettyvs传统实现总结长连接指客户端与服务器建立一次连接后,保持该连接持续打开,供多次数据传输使用。与短连接(每次请
- Spring Cloud Alibaba Spring Cloud Spring Boot 版本对应关系
马丁半只瞄
javaspringspringbootspringcloud
版本不对应可能有以下报错:Failedtobindpropertiesundermybatis-plus.configuration.result-maps[0]NoClassDefFoundError:reactor/netty/http/server/WebsocketServerSpec$Builderreactor.netty.resources.ConnectionProvider.el
- netty使用场景
酷爱码
java技术教程java
Netty是一个Java网络编程框架,提供了高性能、高可扩展性的网络通信能力。它通常被用于以下场景:服务器端网络编程:Netty可用于构建各种服务器端应用程序,如Web服务器、游戏服务器、聊天服务器等。客户端网络编程:Netty也可以用于构建客户端应用程序,用于与服务器进行通信。分布式系统:Netty可在分布式系统中作为通信框架,用于节点之间的数据传输和通信。高性能网络应用:由于Netty具有高性
- Netty之ByteBuf详解
非ban必选
nettynetty
ByteBuf的结构,如下图所示1.ByteBuf是一个字节容器,容器里面的数据分为三部分,第一部分是已经丢弃的字节,这部分数据是无效的;第二部分是可读字节,这部分数据是ByteBuf的主体数据,从ByteBuf里读取的数据都来自这一部分;最后一部分的数据是可写字节,所有写到ByteBuf的数据都会写到这一段。后面的虚线部分表示该ByteBuf最多还能扩容多少容量。2.以上三部分内容是被两个指针划
- netty详解
p-knowledge
jettyjava
Netty是一个高性能的网络通信框架,广泛用于构建网络应用程序,如高性能的服务器、客户端和分布式系统。以下是Netty的各个组件介绍与原理分析,以及客户端和服务端的实现示例。一、Netty的组件介绍Channel:概念:表示一个连接到网络的对象,负责处理网络I/O操作。可以是TCP、UDP等。作用:提供数据读写操作,并可以注册到事件循环。EventLoop:概念:负责处理I/O操作的事件循环。每个
- Kafka 基础教程 — 可靠的数据传递
码炫课堂-码哥
kafka专题kafka消息队列
作者简介:大家好,我是码炫码哥,前中兴通讯、美团架构师,现任某互联网公司CTO,兼职码炫课堂主讲源码系列专题代表作:《jdk源码&多线程&高并发》,《深入tomcat源码解析》,《深入netty源码解析》,《深入dubbo源码解析》,《深入springboot源码解析》,《深入spring源码解析》,《深入redis源码解析》等联系qq:184480602,加我进群,大家一起学习,一起进步,一起对
- PHP,安卓,UI,java,linux视频教程合集
cocos2d-x小菜
javaUIlinuxPHPandroid
╔-----------------------------------╗┆
- zookeeper admin 笔记
braveCS
zookeeper
Required Software
1) JDK>=1.6
2)推荐使用ensemble的ZooKeeper(至少3台),并run on separate machines
3)在Yahoo!,zk配置在特定的RHEL boxes里,2个cpu,2G内存,80G硬盘
数据和日志目录
1)数据目录里的文件是zk节点的持久化备份,包括快照和事务日
- Spring配置多个连接池
easterfly
spring
项目中需要同时连接多个数据库的时候,如何才能在需要用到哪个数据库就连接哪个数据库呢?
Spring中有关于dataSource的配置:
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"
&nb
- Mysql
171815164
mysql
例如,你想myuser使用mypassword从任何主机连接到mysql服务器的话。
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'%'IDENTIFIED BY 'mypassword' WI
TH GRANT OPTION;
如果你想允许用户myuser从ip为192.168.1.6的主机连接到mysql服务器,并使用mypassword作
- CommonDAO(公共/基础DAO)
g21121
DAO
好久没有更新博客了,最近一段时间工作比较忙,所以请见谅,无论你是爱看呢还是爱看呢还是爱看呢,总之或许对你有些帮助。
DAO(Data Access Object)是一个数据访问(顾名思义就是与数据库打交道)接口,DAO一般在业
- 直言有讳
永夜-极光
感悟随笔
1.转载地址:http://blog.csdn.net/jasonblog/article/details/10813313
精华:
“直言有讳”是阿里巴巴提倡的一种观念,而我在此之前并没有很深刻的认识。为什么呢?就好比是读书时候做阅读理解,我喜欢我自己的解读,并不喜欢老师给的意思。在这里也是。我自己坚持的原则是互相尊重,我觉得阿里巴巴很多价值观其实是基本的做人
- 安装CentOS 7 和Win 7后,Win7 引导丢失
随便小屋
centos
一般安装双系统的顺序是先装Win7,然后在安装CentOS,这样CentOS可以引导WIN 7启动。但安装CentOS7后,却找不到Win7 的引导,稍微修改一点东西即可。
一、首先具有root 的权限。
即进入Terminal后输入命令su,然后输入密码即可
二、利用vim编辑器打开/boot/grub2/grub.cfg文件进行修改
v
- Oracle备份与恢复案例
aijuans
oracle
Oracle备份与恢复案例
一. 理解什么是数据库恢复当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(硬件故障、软件故障、网络故障、进程故障和系统故障)影响数据库系统的操作,影响数据库中数据的正确性,甚至破坏数据库,使数据库中全部或部分数据丢失。因此当发生上述故障后,希望能重构这个完整的数据库,该处理称为数据库恢复。恢复过程大致可以分为复原(Restore)与
- JavaEE开源快速开发平台G4Studio v5.0发布
無為子
我非常高兴地宣布,今天我们最新的JavaEE开源快速开发平台G4Studio_V5.0版本已经正式发布。
访问G4Studio网站
http://www.g4it.org
2013-04-06 发布G4Studio_V5.0版本
功能新增
(1). 新增了调用Oracle存储过程返回游标,并将游标映射为Java List集合对象的标
- Oracle显示根据高考分数模拟录取
百合不是茶
PL/SQL编程oracle例子模拟高考录取学习交流
题目要求:
1,创建student表和result表
2,pl/sql对学生的成绩数据进行处理
3,处理的逻辑是根据每门专业课的最低分线和总分的最低分数线自动的将录取和落选
1,创建student表,和result表
学生信息表;
create table student(
student_id number primary key,--学生id
- 优秀的领导与差劲的领导
bijian1013
领导管理团队
责任
优秀的领导:优秀的领导总是对他所负责的项目担负起责任。如果项目不幸失败了,那么他知道该受责备的人是他自己,并且敢于承认错误。
差劲的领导:差劲的领导觉得这不是他的问题,因此他会想方设法证明是他的团队不行,或是将责任归咎于团队中他不喜欢的那几个成员身上。
努力工作
优秀的领导:团队领导应该是团队成员的榜样。至少,他应该与团队中的其他成员一样努力工作。这仅仅因为他
- js函数在浏览器下的兼容
Bill_chen
jquery浏览器IEDWRext
做前端开发的工程师,少不了要用FF进行测试,纯js函数在不同浏览器下,名称也可能不同。对于IE6和FF,取得下一结点的函数就不尽相同:
IE6:node.nextSibling,对于FF是不能识别的;
FF:node.nextElementSibling,对于IE是不能识别的;
兼容解决方式:var Div = node.nextSibl
- 【JVM四】老年代垃圾回收:吞吐量垃圾收集器(Throughput GC)
bit1129
垃圾回收
吞吐量与用户线程暂停时间
衡量垃圾回收算法优劣的指标有两个:
吞吐量越高,则算法越好
暂停时间越短,则算法越好
首先说明吞吐量和暂停时间的含义。
垃圾回收时,JVM会启动几个特定的GC线程来完成垃圾回收的任务,这些GC线程与应用的用户线程产生竞争关系,共同竞争处理器资源以及CPU的执行时间。GC线程不会对用户带来的任何价值,因此,好的GC应该占
- J2EE监听器和过滤器基础
白糖_
J2EE
Servlet程序由Servlet,Filter和Listener组成,其中监听器用来监听Servlet容器上下文。
监听器通常分三类:基于Servlet上下文的ServletContex监听,基于会话的HttpSession监听和基于请求的ServletRequest监听。
ServletContex监听器
ServletContex又叫application
- 博弈AngularJS讲义(16) - 提供者
boyitech
jsAngularJSapiAngularProvider
Angular框架提供了强大的依赖注入机制,这一切都是有注入器(injector)完成. 注入器会自动实例化服务组件和符合Angular API规则的特殊对象,例如控制器,指令,过滤器动画等。
那注入器怎么知道如何去创建这些特殊的对象呢? Angular提供了5种方式让注入器创建对象,其中最基础的方式就是提供者(provider), 其余四种方式(Value, Fac
- java-写一函数f(a,b),它带有两个字符串参数并返回一串字符,该字符串只包含在两个串中都有的并按照在a中的顺序。
bylijinnan
java
public class CommonSubSequence {
/**
* 题目:写一函数f(a,b),它带有两个字符串参数并返回一串字符,该字符串只包含在两个串中都有的并按照在a中的顺序。
* 写一个版本算法复杂度O(N^2)和一个O(N) 。
*
* O(N^2):对于a中的每个字符,遍历b中的每个字符,如果相同,则拷贝到新字符串中。
* O(
- sqlserver 2000 无法验证产品密钥
Chen.H
sqlwindowsSQL ServerMicrosoft
在 Service Pack 4 (SP 4), 是运行 Microsoft Windows Server 2003、 Microsoft Windows Storage Server 2003 或 Microsoft Windows 2000 服务器上您尝试安装 Microsoft SQL Server 2000 通过卷许可协议 (VLA) 媒体。 这样做, 收到以下错误信息CD KEY的 SQ
- [新概念武器]气象战争
comsci
气象战争的发动者必须是拥有发射深空航天器能力的国家或者组织....
原因如下:
地球上的气候变化和大气层中的云层涡旋场有密切的关系,而维持一个在大气层某个层次
- oracle 中 rollup、cube、grouping 使用详解
daizj
oraclegroupingrollupcube
oracle 中 rollup、cube、grouping 使用详解 -- 使用oracle 样例表演示 转自namesliu
-- 使用oracle 的样列库,演示 rollup, cube, grouping 的用法与使用场景
--- ROLLUP , 为了理解分组的成员数量,我增加了 分组的计数 COUNT(SAL)
- 技术资料汇总分享
Dead_knight
技术资料汇总 分享
本人汇总的技术资料,分享出来,希望对大家有用。
http://pan.baidu.com/s/1jGr56uE
资料主要包含:
Workflow->工作流相关理论、框架(OSWorkflow、JBPM、Activiti、fireflow...)
Security->java安全相关资料(SSL、SSO、SpringSecurity、Shiro、JAAS...)
Ser
- 初一下学期难记忆单词背诵第一课
dcj3sjt126com
englishword
could 能够
minute 分钟
Tuesday 星期二
February 二月
eighteenth 第十八
listen 听
careful 小心的,仔细的
short 短的
heavy 重的
empty 空的
certainly 当然
carry 携带;搬运
tape 磁带
basket 蓝子
bottle 瓶
juice 汁,果汁
head 头;头部
- 截取视图的图片, 然后分享出去
dcj3sjt126com
OSObjective-C
OS 7 has a new method that allows you to draw a view hierarchy into the current graphics context. This can be used to get an UIImage very fast.
I implemented a category method on UIView to get the vi
- MySql重置密码
fanxiaolong
MySql重置密码
方法一:
在my.ini的[mysqld]字段加入:
skip-grant-tables
重启mysql服务,这时的mysql不需要密码即可登录数据库
然后进入mysql
mysql>use mysql;
mysql>更新 user set password=password('新密码') WHERE User='root';
mysq
- Ehcache(03)——Ehcache中储存缓存的方式
234390216
ehcacheMemoryStoreDiskStore存储驱除策略
Ehcache中储存缓存的方式
目录
1 堆内存(MemoryStore)
1.1 指定可用内存
1.2 驱除策略
1.3 元素过期
2 &nbs
- spring mvc中的@propertysource
jackyrong
spring mvc
在spring mvc中,在配置文件中的东西,可以在java代码中通过注解进行读取了:
@PropertySource 在spring 3.1中开始引入
比如有配置文件
config.properties
mongodb.url=1.2.3.4
mongodb.db=hello
则代码中
@PropertySource(&
- 重学单例模式
lanqiu17
单例Singleton模式
最近在重新学习设计模式,感觉对模式理解更加深刻。觉得有必要记下来。
第一个学的就是单例模式,单例模式估计是最好理解的模式了。它的作用就是防止外部创建实例,保证只有一个实例。
单例模式的常用实现方式有两种,就人们熟知的饱汉式与饥汉式,具体就不多说了。这里说下其他的实现方式
静态内部类方式:
package test.pattern.singleton.statics;
publ
- .NET开源核心运行时,且行且珍惜
netcome
java.net开源
背景
2014年11月12日,ASP.NET之父、微软云计算与企业级产品工程部执行副总裁Scott Guthrie,在Connect全球开发者在线会议上宣布,微软将开源全部.NET核心运行时,并将.NET 扩展为可在 Linux 和 Mac OS 平台上运行。.NET核心运行时将基于MIT开源许可协议发布,其中将包括执行.NET代码所需的一切项目——CLR、JIT编译器、垃圾收集器(GC)和核心
- 使用oscahe缓存技术减少与数据库的频繁交互
Everyday都不同
Web高并发oscahe缓存
此前一直不知道缓存的具体实现,只知道是把数据存储在内存中,以便下次直接从内存中读取。对于缓存的使用也没有概念,觉得缓存技术是一个比较”神秘陌生“的领域。但最近要用到缓存技术,发现还是很有必要一探究竟的。
缓存技术使用背景:一般来说,对于web项目,如果我们要什么数据直接jdbc查库好了,但是在遇到高并发的情形下,不可能每一次都是去查数据库,因为这样在高并发的情形下显得不太合理——
- Spring+Mybatis 手动控制事务
toknowme
mybatis
@Override
public boolean testDelete(String jobCode) throws Exception {
boolean flag = false;
&nbs
- 菜鸟级的android程序员面试时候需要掌握的知识点
xp9802
android
熟悉Android开发架构和API调用
掌握APP适应不同型号手机屏幕开发技巧
熟悉Android下的数据存储
熟练Android Debug Bridge Tool
熟练Eclipse/ADT及相关工具
熟悉Android框架原理及Activity生命周期
熟练进行Android UI布局
熟练使用SQLite数据库;
熟悉Android下网络通信机制,S