爬虫selenium获取元素定位方法总结(动态获取元素)
目录
元素
查看元素信息
元素定位
通过元素id定位
通过元素name定位
通过xpath表达式定位
绝对路径
相对路径
通过完整超链接定位
通过部分链接定位
通过标签定位
通过类名进行定位
通过css选择器进行定位
id选择器
class选择器
标签选择器
属性选择器
定位带空格的复合class属性
selenium 4.0以后版本用法
元素
要想操作一个元素,首先应该识别这个元素。人有各种的特征(属性),可以通过其特征找到人,如通过身份证号、姓名、家庭住址。同理,界面的某个元素会有各种的特征(属性),可以通过这个属性找到这对象。
例如:
driver.find_element(By.CSS_SELECTOR, 'img[title="点击图片重新获取验证码"]')该代码寻找属性标识着为 “点击图片重新获取验证码图” 的图片验证码。
元素:由标签头 + 标签尾 + 标签头和标签尾包括的文本内容
元素定位最终就是通过元素的信息或者元素的层级结构来进行元素定位
查看元素信息
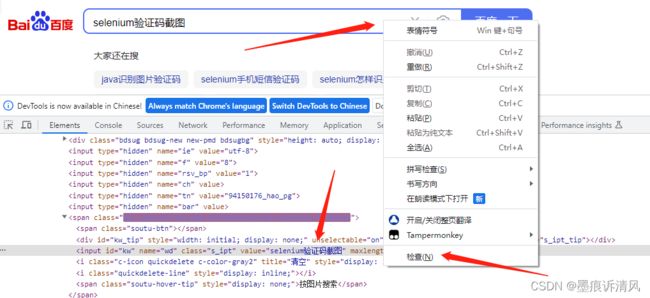
选中元素,右键点击“检查”,即可查看到该控件的所有属性
元素定位
selenium提供了常用的8种方法:
定位一个元素
定位多个元素
- 通过元素id定位
-
find_element_by_id
-
find_elements_by_id
-
-
通过元素name定位
-
find_element_by_name
-
find_elements_by_name
-
-
通过xpath表达式定位
-
find_element_by_xpath
-
find_elements_by_xpath
-
-
通过完整超链接定位
-
find_element_by_link_text
-
find_elements_by_link_text
-
-
通过部分链接定位
-
find_element_by_partial_link_text
-
find_elements_by_partial_link_text
-
-
通过标签定位
-
find_element_by_tag_name
-
find_elements_by_tag_name
-
-
通过类名进行定位
-
find_element_by_class_name
-
find_elements_by_class_name
-
-
通过css选择器进行定位
-
find_element_by_css_selector
-
find_elements_by_css_selector
-
通过元素id定位
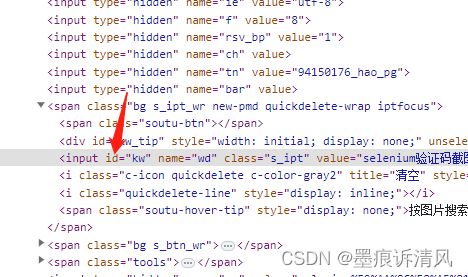
find_element_by_id("kw")?
通过元素name定位
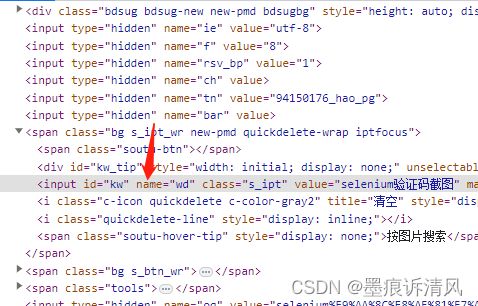
find_element_by_name("wd")?
通过xpath表达式定位
Xpath是一种在XML和HTML文档中查找信息的语言,通过Xpath路径来定位元素的时候也是分绝对路径和相对路径。
绝对路径
鼠标单机右键-Copy-Copy full XPath即可获取其XPath绝对路径
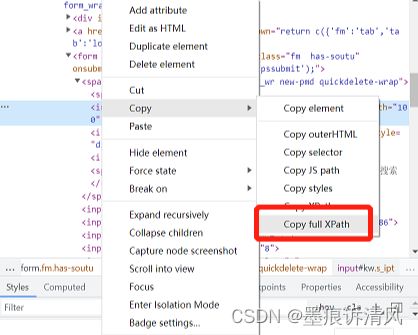
/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input
selenium通过xpath定位语句:
find_element_by_xpath('/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[1]/input')
相对路径
鼠标单机右键-Copy-Copy XPath即可获取其XPath相对路径
//*[@id="kw"]
selenium通过xpath定位语句:
find_element_by_xpath('//*[@id="kw"]')
相对路径的xpath定位表达式更加简洁,但是偶然会出现错误的寻址,但如果可以推荐使用相对路径的xpath表达式。
通过完整超链接定位
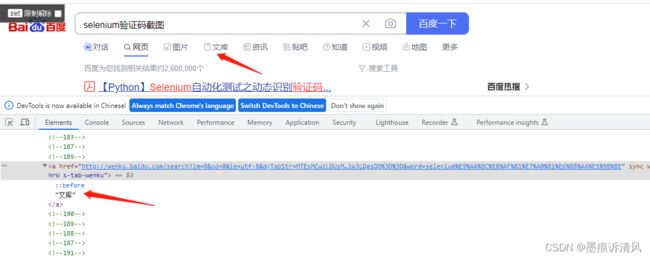
find_element_by_link_text('文库')
通过部分链接定位
find_element_by_partial_link_text('库')
通过标签定位
HTML是通过tag来定义一类功能的,比如input是输入,table是表格,tbody是表格主体等。每个元素其实就是一个tag,由于一个tag用来定义一类功能,一个网页往往有很多同类tag,所以很难通过tag去区分不同的元素。
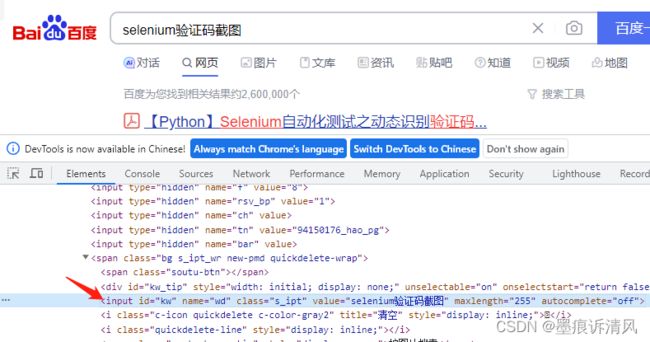
find_element_by_tag_name('input')?
通过类名进行定位
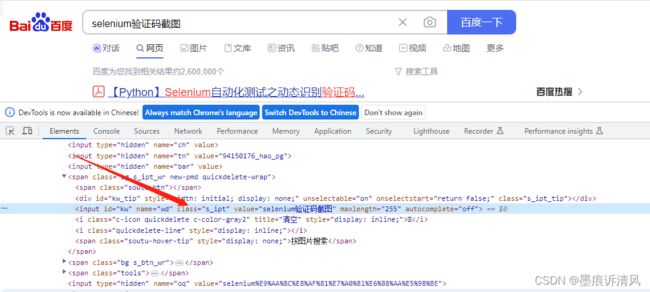
find_element_by_class_name('s_ipt')
如果class的值中有空格,则需要借助CSS选择器。
通过css选择器进行定位
在Selenium官网当中是更加推荐Css Selector()方法来进行页面元素的定位的,Css定位可以通过id选择器、class选择器、标签选择器和属性选择器。
id选择器
通过 # 来定义,通过元素的id属性来定位
find_element_by_css_selector("#kw")?
class选择器
通过 .来定义,通过元素的class属性来定位
find_element_by_css_selector(".s_ipt")?
标签选择器
通过标签的名字来定位元素
find_element_by_css_selector("input")?
属性选择器
find_element_by_css_selector('[id="kw"]')?
find_element_by_css_selector('input[id="kw"]')?
定位带空格的复合class属性
以百度上方栏目元素为例,其class属性带有空格。
class="s-top-left-new?s-isindex-wrap"
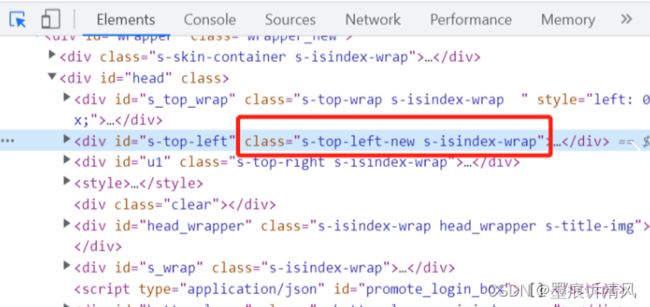
直接通过class属性定位是会报错的,需要通过css selector按class属性定位。
find_element_by_css_selector('[class="s-top-left-new?s-isindex-wrap"]')
selenium 4.0以后版本用法
from?selenium.webdriver.common.by?import?By
element?=?web.find_element(By.ID,'kw')
element?=?web.find_element(By.NAME,'wd')
element?=?web.find_element(By.CLASS_NAME,'s_ipt')
element?=?web.find_element(By.TAG_NAME,'input')
element?=?web.find_element(By.LINK_TEXT,'新闻')
element?=?web.find_element(By.PARTIAL_LINK_TEXT,'闻')
element?=?web.find_element(By.XPATH,'//*[@id="kw"]')
element?=?web.find_element(By.CSS_SELECTOR,'#kw')
element?=?web.find_element(By.CSS_SELECTOR,'[id="kw"]')
element?=?web.find_element(By.CSS_SELECTOR,'input[id="kw"]')