java线程池简述,线程池的7个参数(面试必考)
java线程池简述(面试必考)
- 线程池的优势:
- 代码案例:
-
- 1,创建基础线程池(不可扩容):
- 2,创建高级线程池(可扩容):
- 线程池原理(线程池有哪些参数,面试常问这个问题):
-
- 线程池参数(7个):
-
-
- 1. corePoolSize:线程池中的常住线程数
- 2. maximumPoolSize:线程池中能够容纳同时执行的最大线程数,必须>= 1
- 3. keepAliveTime:多余的空闲线程额存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁知道只剩下corePoolSize个线程位置。
- 4. unit:keepAliveTime的单位。
- 5. workQueue:任务队列,被提交但尚未执行的任务。
- 6. threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认即可。
- 7. handler:拒绝策略,表示当队列满了,并且工作线程>=线程池的最大线程数(maximumPoolSize),这是如何来拒绝请求执行的runnabel的策略
-
- 创建线程池注意点:
- 线程池的4种拒绝策略:
线程池的优势:
线程池的工作就是控制运行线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
翻译:就是一开始就创建一定数量的线程。来一个用一个,用完了不销毁,返还到池子里等着被下一次调用。 如果需要的线程大于了我线程池准备好的线程,那么久等待,空出来一个,用一个。
线程池主要特点:
- 线路复用 :降低资源消耗。复用以创建的线程,降低新线程创建销毁造成的消耗。
- 控制最大并发数:当任务到达时,不用等待线程创建就能立即执行。
- 管理线程:对线程进行统一的分配、调优、监控
代码案例:
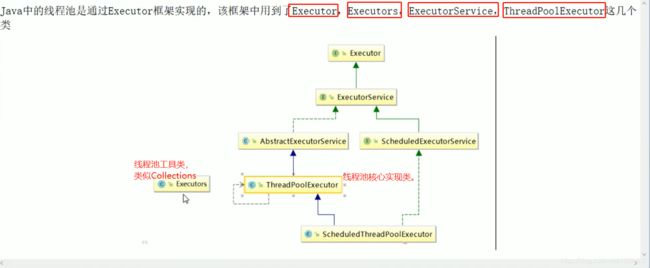
先看看线程池所需要的类的结构图:
1,创建基础线程池(不可扩容):
public static void main(String[] args) {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
try {
for(int i = 1 ; i <= 10;i++){
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName()+"开始工作");
});
}
}catch (Exception e){
e.printStackTrace();
}finally {
threadPool.shutdown();
}
}
- Executors.newFixedThreadPool(5),创建线程池,这个方法表示,创建一个包含5个线程的线程池。
- for循环十次,模拟有10个请求过来使用线程池,每个线程打印出自己线程的名字。
结果:
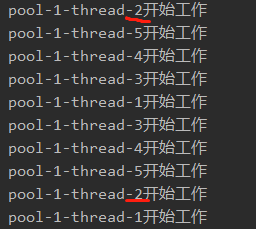
可以看到,线程最大就跑到5,说明之前==newFixedThreadPool(5)==参数有效。而有部分线程多次出现,这里就说明,某个线程结束自己的工作之后,马上回到了线程池,接受并执行了下一个业务请求!
2,创建高级线程池(可扩容):
试想一下上面的代码,在某些超大项目中,如果我们把线程数量写死。一旦请求多了起来,来了1000个请求希望用线程池中的线程,而我们仅仅只有5个备用的线程。那程序还不得被卡死啊?
所以出现了一种创建线程的方法,让线程池遇强则强,可扩容!
ExecutorService threadPool = Executors.newCachedThreadPool();
结果:
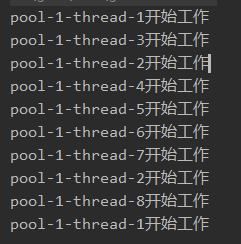
多次测试结果都不同,线程数根据程序访问强度而或多或少。
线程池原理(线程池有哪些参数,面试常问这个问题):
1. 固定线程数newFixedThreadPool(5)原理:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
最终返回一个ThreadPoolExecutor对象,是不是很眼熟??没错就是上面架构图中线程池的核心实现类!
2. 可扩容线程数newCachedThreadPool()原理:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
同样是返回一个ThreadPoolExecutor对象,只是创建对象所传的构造方法参数不同。 而参数的数量都是一样的 5个!
线程池参数(7个):
public ThreadPoolExecutor(int corePoolSize, 1
int maximumPoolSize, 2
long keepAliveTime, 3
TimeUnit unit, 4
BlockingQueue<Runnable> workQueue, 5
ThreadFactory threadFactory, 6
RejectedExecutionHandler handler 7
) {
}
1. corePoolSize:线程池中的常住线程数
2. maximumPoolSize:线程池中能够容纳同时执行的最大线程数,必须>= 1
3. keepAliveTime:多余的空闲线程额存活时间,当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁知道只剩下corePoolSize个线程位置。
4. unit:keepAliveTime的单位。
5. workQueue:任务队列,被提交但尚未执行的任务。
6. threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认即可。
7. handler:拒绝策略,表示当队列满了,并且工作线程>=线程池的最大线程数(maximumPoolSize),这是如何来拒绝请求执行的runnabel的策略
线程池使用流程:
- 进来一个任务,看看参数1有没有满,如果没满,就使用,如果满了。。
- 查看参数5满没满,没满,把任务加入队列,如果满了。。。
- 查看参数2有没有满,如果没满,创建新的线程直到线程数量等于参数2。如果满了。。。。
- 调用参数7,拒绝。

创建线程池注意点:

代码案例:
ExecutorService threadPool = new ThreadPoolExecutor(
2,
5,
2L,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
线程池的4种拒绝策略:
- AbortPolicy:默认策略,将抛出异常
- CallerRunsPolicy:不抛弃任务,也不抛出异常,而是将任务退回给线程调用处,由调用处来处理任务!
- DiscardPolicy:抛弃当前任务
- DiscardOldestPolicy:抛弃队列中等待 时间最久的任务,然后把当前任务加入到队列
好了 基本已经讲完,欢迎大家评论区指出不足,一起学习进步!
大家看完了点个赞,码字不容易啊。。。