Java后端开发面试题——消息中间篇
RabbitMQ-如何保证消息不丢失

交换机持久化:
@Bean
public DirectExchange simpleExchange(){
// 三个参数:交换机名称、是否持久化、当没有queue与其绑定时是否自动删除
return new DirectExchange("simple.direct", true, false);
}
队列持久化:
@Bean
public Queue simpleQueue(){
// 使用QueueBuilder构建队列,durable就是持久化的
return QueueBuilder.durable("simple.queue").build();
}
消息持久化,SpringAMQP中的的消息默认是持久的,可以通过MessageProperties中的DeliveryMode来指定的
Message msg = MessageBuilder
.withBody(message.getBytes(StandardCharsets.UTF_8)) // 消息体
.setDeliveryMode(MessageDeliveryMode.PERSISTENT) // 持久化
.build();
消费者确认
manual:手动ack,需要在业务代码结束后,调用api发送ack。
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
在消费者出现异常时利用本地重试,设置重试次数,当次数达到了以后,如果消息依然失败,将消息投递到异常交换机,交由人工处理
RabbitMQ消息的重复消费问题如何解决的
场景:
网络抖动
消费者挂了
解决方案:
每条消息设置一个唯一的标识id
幂等方案:【 分布式锁、数据库锁(悲观锁、乐观锁) 】
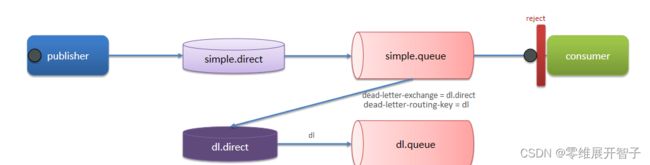
RabbitMQ中死信交换机 ? (RabbitMQ延迟队列有了解过嘛)
延迟队列:进入队列的消息会被延迟消费的队列
场景:超时订单、限时优惠、定时发布
延迟队列=死信交换机+TTL(生存时间)
死信消息:
消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
消息是一个过期消息,超时无人消费(
消息所在的队列设置了存活时间
消息本身设置了存活时间
)
要投递的队列消息堆积满了,最早的消息可能成为死信
队列配置了dead-letter-exchange属性,指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机称为死信交换机


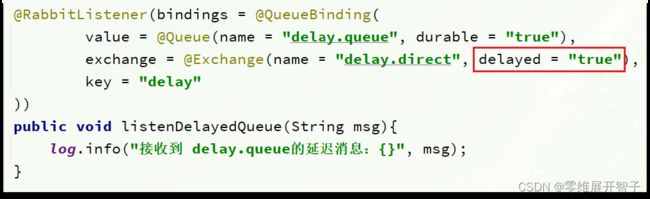
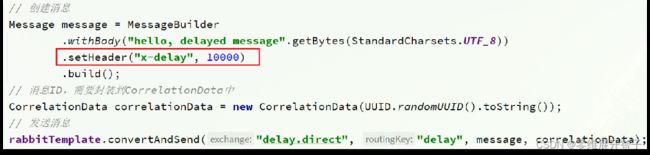
延迟队列插件(方案二)DelayExchange插件,需要安装在RabbitMQ中
DelayExchange的本质还是官方的三种交换机,只是添加了延迟功能。因此使用时只需要声明一个交换机,交换机的类型可以是任意类型,然后设定delayed属性为true即可。
 RabbitMQ如果有100万消息堆积在MQ , 如何解决(消息堆积怎么解决)
RabbitMQ如果有100万消息堆积在MQ , 如何解决(消息堆积怎么解决)
1)增加更多消费者,提高消费速度
2)在消费者内开启线程池加快消息处理速度
3)扩大队列容积,提高堆积上限
3.x)惰性队列
接收到消息后直接存入磁盘而非内存
消费者要消费消息时才会从磁盘中读取并加载到内存
支持数百万条的消息存储


RabbitMQ的高可用机制有了解过嘛
普通集群
会在集群的各个节点间共享部分数据,包括:交换机、队列元信息。不包含队列中的消息。
当访问集群某节点时,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
队列所在节点宕机,队列中的消息就会丢失
镜像集群
交换机、队列、队列中的消息会在各个mq的镜像节点之间同步备份。
创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
一个队列的主节点可能是另一个队列的镜像节点
所有操作都是主节点完成,然后同步给镜像节点
主宕机后,镜像节点会替代成新的主
仲裁队列(集群下丢数据问题解决方案)
与镜像队列一样,都是主从模式,支持主从数据同步
@Bean
public Queue quorumQueue() {
return QueueBuilder
.durable("quorum.queue") // 持久化
.quorum() // 仲裁队列
.build();
}
Kafka是如何保证消息不丢失

生产者发送消息到Brocker丢失
设置异步发送+消息重试
//同步发送
RecordMetadata recordMetadata = kafkaProducer.send(record).get();
//异步发送
kafkaProducer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e != null) {
System.out.println("消息发送失败 | 记录日志");
}
long offset = recordMetadata.offset();
int partition = recordMetadata.partition();
String topic = recordMetadata.topic();
}
});
//设置重试次数
prop.put(ProducerConfig.RETRIES_CONFIG,10);
消息在Brocker中存储丢失

消费者从Brocker接收消息丢失
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition)
topic分区中消息只能由消费者组中的唯一一个消费者处理,不同的分区分配给不同的消费者(同一个消费者组)
禁用自动提交偏移量,改为手动
同步提交
异步提交
同步+异步组合提交

Kafka是如何保证消费的顺序性
场景:
一个topic的数据可能存储在不同的分区中,每个分区都有一个按照顺序的存储的偏移量,如果消费者关联了多个分区不能保证顺序性
解决:
发送消息时指定分区号
发送消息时按照相同的业务设置相同的key
Kafka的高可用机制有了解过嘛
集群模式

Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成
这样如果集群中某一台机器宕机,其他机器上的 Broker 也依然能够对外提供服务。这其实就是 Kafka 提供高可用的手段之一
分区备份机制
一个topic有多个分区,每个分区有多个副本,其中有一个leader,其余的是follower
所有的分区副本的内容是都是相同的,如果leader发生故障时,会自动将其中一个follower提升为leader
具体机制

第一:选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的
第二:如果ISR列表中的follower都不行了,就只能从其他follower中选取
Kafka数据清理机制了解过嘛
存储结构:.index 索引文件
.log 数据文件
.timeindex 时间索引文件
为什么要分段?
删除无用文件方便,提高磁盘利用率
查找数据便捷
清理策略有两个
1、根据消息的保留时间,当消息在kafka中保存的时间超过了指定的时间,就会触发清理过程

2、根据topic存储的数据大小,当topic所占的日志文件大小大于一定的阈值,则开始删除最久的消息。需手动开启

Kafka中实现高性能的设计有了解过嘛
消息分区:不受单台服务器的限制,可以不受限的处理更多的数据
顺序读写:磁盘顺序读写,提升读写效率
页缓存:把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
零拷贝:减少上下文切换及数据拷贝
消息压缩:减少磁盘IO和网络IO
分批发送:将消息打包批量发送,减少网络开销