Python基本语法
学习网站:【1】
数据类型
相互转换 / general
List、Array数组的拼接、合并
列表【list】
- 对列表ls中每个元素进行运算:(以开方为例),见Link
sqls = list(map(lambda x: math.sqrt(x), ls))
sqls = [math.sqrt(x) for x in ls]
- 两个list列表逐元素相减,见 Link
a = [1,2,3,4,5]
b = [5,4,3,2,1]
c = [a[i] - b[i] for i in range(len(a))]
print(c)
# print: [-4, -2, 0, 2, 4]
- 时间戳列表求逐段时间间隔,即: { t } 1 h → { Δ t } 1 , 2 h − 1 , h \{t\}_1^h \rightarrow \{\Delta t\}_{1,2}^{h-1,h} {t}1h→{Δt}1,2h−1,h(列表长度减1)
dt = [t[i+1] - t[i] for i in range(len(t)-1)]
- Python 如果发现重复项,则取列表中值的平均值,见Link
from collections import OrderedDict
d = OrderedDict()
for x, y in zip(tv, sv):
d.setdefault(x, []).append(y)
# OrderedDict([(t0=t1, [s0, s1]), (t2, [s2]), (t3, [s3])])
tva, sva = zip(*((k, sum(v) / len(v)) for k, v in d.items()))
- 查找列表中已知元素的索引:
a.index(4) - 统计词频:见Link
from collections import CounterCounter(list1)
元组【tuple】
Numpy库 – 数组【array】
- 矩阵转置:见 Numpy数组转置的三种方法 T、transpose、swapaxes
- 基本生成:见 python:np.array的操作
- 乱序生成:
samp=np.random.permutation(9) - 随机(可重复):
np.random.randint(0,10,size=[3,3]) - 随机(无重复):
random.sample(range(1, 10), 5) - 数组复制:
np.repeat([1,10],3),np.tile([1,10],3)。见 Link - 数组合并:
np.c_,np.r_
最值
- 取最值:
arr.min()整个,arr.min(0)按列,arr.min(1或-1)按行。见Link - 两个数组对应取最值:
np.minimum(arr1, arr2)。见Link
索引
- 选择取出:
trc = trb[:8,:10] - 间隔取出:
trc = trb[::2,:] - 查找符合条件的元素索引:
np.argwhere(x > 3) - 查找最大元素的索引:
np.argmax(x) - NumPy数组 搜索:
np.where(arr == 4) - NumPy数组 交集:
np.intersect1d(arr1, arr2)。见Link - NumPy数组 交集索引:
np.nonzero(np.in1d(tra, trb))。见Link
排序
- Numpy数组排序
- 根据某列排序:
data = data[np.argsort(data[:,0])]。见Link z[::-1]:倒序- 堆排序:
ih = heapq.nsmallest(k, range(len(h)), h.__getitem__) # 获取前k个h值最小的id
Pandas库 – 数据帧【dataframe】
## Dataframe插入一列
df.insert(4,'E',[11,12,13,14,15])
# pd.DataFrame(np.insert(df.values, 0, values=[2, 3, 4], axis=1))
## Dataframe插入一行
pd.DataFrame(np.insert(df.values, 0, values=[2, 3, 4], axis=0))
pandas: DataFrame数据的更改、插入新增的列和行
pandas: DataFrame指定位置增加删除一行一列
pandas: 添加行
索引
- Series / DataFrame 重新设置索引
b.reset_index(drop=True)
- DataFrame 设置索引
##局部修改
df.rename(columns={'改前':'改后'},index={'改前':'改后'})
##全部修改
df.index=ls
df = df.set_index('month') ## 将df其中的一列时间戳设置成索引
- DataFrame 按索引提取:【1】 【2】
df.iloc[index, :] # 这里的 :可以改为具体的索引
df.loc[index, :]
# df.loc[0:5] 取出0~5,共6行
# df.iloc[0:5] 取出0~4,共5行
df1 = df.iloc[:,[0,1,2]]
df1 = df[['name_a','name_b']]
# df1 = df.iloc[:,['a','b','c']] # 不太对呢
当用行索引的时候, 尽量用 iloc 来进行索引; 而用标签索引的时候用 loc
python 列表 按照 指定索引 排序
拼接str
# 一行 series
seriesxxx.str.cat(sep='_') # sep分隔符, na_rep缺失值填补
# 二维 dataframe
dfxxx['last_name'].map(str).str.cat([ncvt22['first_name'], ncvt22['middle_name']],sep='_',na_rep='?')
数据清洗
- 删除重复数据: drop_duplicates去重
data.drop_duplicates(subset=['A','B'],keep='first',inplace=True)
循环语句、条件语句
- 见 【While】、【For】、【If Else】
文件操作
txt文件
- 读取txt
voter = pd.read_csv('xxx.txt', sep='\t') # 分隔符sep
csv 文件
- numpy 导入/导出:python – 借助numpy保存数据为csv格式
json 文件
- 读取json
with open("xxx.json") as f1:
data0 = json.load(f1)
# data = np.array(data0)
- 存储json
with open(outpath, 'w') as f2:
json.dump(data0, f2)
# json.dump(data.tolist(), f2)
os模块
os.chdir():改变当前工作目录到指定的路径。
os.chdir('..'):切换当前路径到上一层目录,可用于临时协调相对路径不一致的函数import引用os.getcwd():获取调用脚本的路径
files = os.listdir(path) # 读取文件夹下的所有文件名
os.mkdir(outpath) # 创建新文件夹
os.path.exists(path) # 判断路径是否存在
os.path.join('C', 'programe files', 'users') # 合成路径
- 若不存在路径,则自动创建:仍然使用with open,但是mode参数为a,则当文件不存在时会自动创建,不会报错。
# 1)
with open("test.txt",mode='a',encoding='utf-8') as ff:
# 2)
if not os.path.isdir(dir_name):
os.makedirs(dir_name)
# 3)
fp = open("CSDN.txt",'w')#如果有这个文件就打开,如果没有这个文件就创建一个名叫CSDN的txt文件
- 若已有同名文件file,则重命名新文件 file0, file1,…。代码如下:
def check_filename_available(tt):
'''
:param tt: 纯文件名(不含扩展名.png)
:return: 如果已有同名文件,则创建编号0,1,2,...,以避免保存新文件覆盖旧文件
'''
n = [0]
def check_meta(file_name):
file_name_new = file_name
if os.path.isfile(file_name):
file_name_new = file_name[:file_name.rfind('.')] + '_' + str(n[0]) + file_name[file_name.rfind('.'):]
n[0] += 1
if os.path.isfile(file_name_new):
file_name_new = check_meta(file_name)
return file_name_new
return_name = check_meta('./Figures/'+tt+'.png')
return return_name
import
【1】 Python-import 导入上级目录文件
【2】 python3 使用相对路径 import模块
基本运算
| 运算 | 符号 | 例子 |
|---|---|---|
| 幂 | ** | 4**3 = 64 |
| 异或 | ^ | 4^3 = 7 |
| 整除 | // | 9//2 = 4 |
- 计算组合数:see here
from scipy.special import comb, perm
perm(3, 2) ## A_3^2 = 6.0
comb(3, 2) ## C_3^2 = 3.0
Scipy 、Sympy - 科学计算、符号计算
- 【1】 用python解决高数所有计算题–sympy求解极限、积分、微分、二元一次方程等
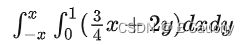
>>> f = (4/3)*x + 2*y
>>> integrate(f, (x, 0, 1), (y, -x, x))
x
- 【2】 高数计算,我Python替你承包了
- 【3】 用python的库 scipy 求二重(多重)积分
例:
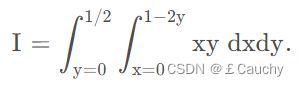
from scipy import integrate
def f(x, y):
return x*y
def bounds_y():
return [0, 0.5]
def bounds_x(y):
return [0, 1-2*y]
print(integrate.nquad(f, [bounds_x, bounds_y]))
基本操作
数据类型 之 转换
-
Python数据分析中Numpy和Pandas对比
-
dataframe ↔ array 相互转换:见 Link
计时
import time
tic = time.time()
toc = time.time()
print('the time used:{} s'.format(toc - tic))
删除变量
- 删除单个变量:
del a - 清除所有变量:
reset→ (y/[n])? →y
路径
- 默认保存路径获取:
pwd
构造函数 Class
- Python构造函数的使用
C++类-构造函数的重载
python @classmethod
作图
函数作图
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1/(1+np.exp(-x)) # sigmoid函数
x = np.arange(-6.0,6.0,0.1) # 限定x的范围,给什么区间画出来的就是在哪个区间
y = sigmoid(x) # 求y值
plt.plot(x,y)
plt.title("sigmoid")
plt.ylim(0,1) # 指定y轴的范围,画出来的效果不一样
plt.show()
连续作图、保存
import matplotlib.pyplot as plt
plt.figure()
# plt.hold(True)
plt.plot(x11,y11,'bp--')
plt.xlabel('kh')
plt.ylabel('precision')
# plt.legend()
plt.title('repeat'+str(qn))
plt.ylim(0.55,1.05)
plt.savefig('./precision2000/os_'+str(os))
plt.show()
Pyplot
import matplotlib.pyplot as plt
Python绘图——Matplotlib教程(详细版)前半部分
Python绘图——Matplotlib文档(详细版)后半部分
Pyplot tutorial
Python 绘图,我只用 Matplotlib(二)
Seaborn [数据可视化]
import seaborn as sns
数据可视化 Seaborn简单介绍
10分钟python图表绘制 | seaborn入门(一):distplot与kdeplot
等高线
matplotlib contour 画等高线图
编程习惯
快捷键
- Spyder 加注释:按住 Ctrl + 1;多行注释也可用
'''_________'''括起。 - PyCharm 加注释:按住 Ctrl + /;多行注释也可用
'''_________'''括起。 - PyCharm 运行选中部分:按住 Shift + Alt + E,即 表示运行的 “▶” 形状,(从下往上按键)。
- PyCharm 查找 / 替换:按住 Ctrl + F / 按住 Ctrl + R
- 批量给print添加括号:使用正则表达式批量给print添加括号
定义函数、测试
- assert 断言:表达式条件为False的时候触发异常。断言是一个调试工具。它用于发现异常,而不是用于处理异常。用法:
assert· tl >= tlq, "please adjust tl or tlq" sys.exit():直接结束进程- Pytest:@pytest.mark.parametrize(args_name,args_value),注意.py文件必须以test_开头或者_test结尾。(注意事项)
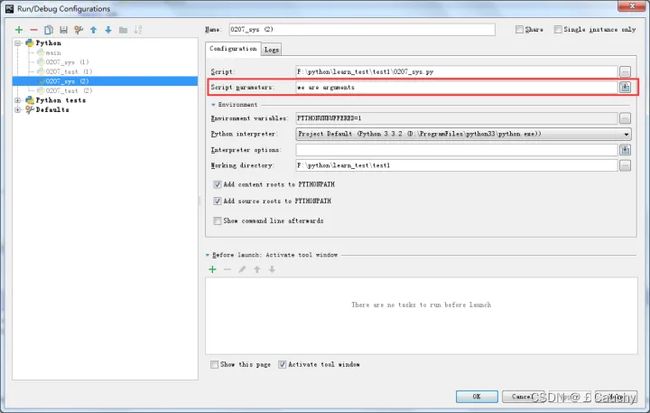
- sys.argv:Pycharm设置形参

面试题
Q1:如何用 Pandas 打开和处理超大的 CSV 文件?
A1:【1】【2】使用 read_csv() 函数的 chunksize 参数来分块读取文件。这将返回一个迭代器,可以逐块读取文件。
import pandas as pd
chunksize = 1000000 # 设置块大小为100万行
for chunk in pd.read_csv('large_file.csv', chunksize=chunksize):
# 在这里处理每个块