Mycat+分库分表
目录
分库分表
垂直分表
垂直分库
水平分库
水平分表
mycat实操场景:
mycat配置
mysql读写分离配置
(38条消息) mycat 安装与配置_羽之大公公的博客-CSDN博客_mycat
分库分表
众所周知,单表1000w,库5000w ,当数据达到一定维度,即时索引优化也会导致性能严重下降
方案一:
我们可以选择氪金,通过提升服务器硬件,增加存储容量,cpu等等
方案二:
我们可以将数据分散开来,将其分散到不同位置的数据库中——>从而减缓单一数据库性能问题
总结:
而我们的分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来的大数据库->若干个数据库(其实这里只是将数据放到若干个数据库节点上,通过mycat进行发牌),将大表分为多个小表(与上述类似),使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的;
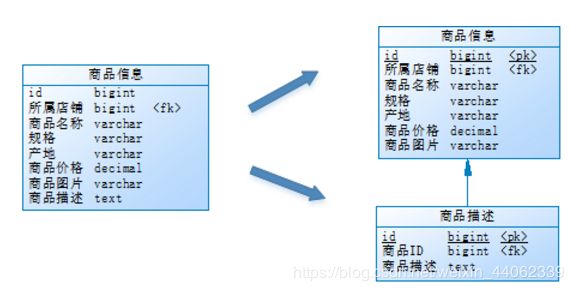
垂直分表
场景:
比如说,用户在浏览商品列表的时候,只对某商品感兴趣爱会看该商品而详细信息,所以说,商品的描述信息字段访问频率会较低(而且占用空间较大,IO时间长),像商品名、商品照片价格这些其他字段访问频率较高;
所以我们可以进行拆表
获取商品列表,可以左外连接两表:
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON s.id = p.[所属店铺]
WHERE...ORDER BY...LIMIT...
获取商品描述信息:
SELECT *
FROM [商品描述]
WHERE [商品ID] = ?
垂直分表定义:
将一个表,按照它的字段分为多个表,每个表存储一部分字段;
它带来的提升是:
1.为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
2.充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累
垂直分库
场景:
垂直分表只是将表分了多个表,但是这样还是在一个库中,在同一个服务器,还是占用同一个物理机的CP、内存、IO
我们可以将下面的卖家库->商品+店铺库,并且将两个库分撒给不同的服务器,我们可以在这不同的服务器中创建对应的表,然后通过Mycat进行发牌(怎么样发,取决于它的schema配置文件,配置节点dataNode的位置以及数据库...)
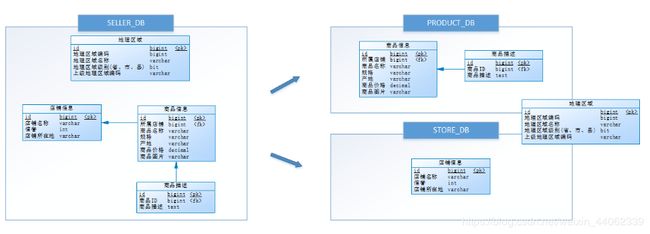
由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此单独被存放在STORE_DB(店铺库)。
垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。——>有微服务那意思,每个服务有自己的数据库
作用:
1.解决业务层面的耦合,业务清晰
2.能对不同业务的数据进行分级管理、维护、监控、扩展等
3.高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
4.垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
水平分库
首先,垂直分库无非就是专库专用,当然在一定程度上是缓解了数据压力(毕竟表被分开放在了不同的数据库上面嘛,所以说。对于高并发场景还是有一定的化解的,分摊压力)
但是,如果我们的商品(Product_DB)库直接就已经超出预算了呢?
场景:
店铺每天都在增长,而且他们的商品每天都在上增,那么我们的商品库肯定压力是很大的,而且他还被经常访问
首先垂直分库肯定不行的,毕竟他只是从逻辑,从业务方面进行分割的
所以我们需要进行水平分库
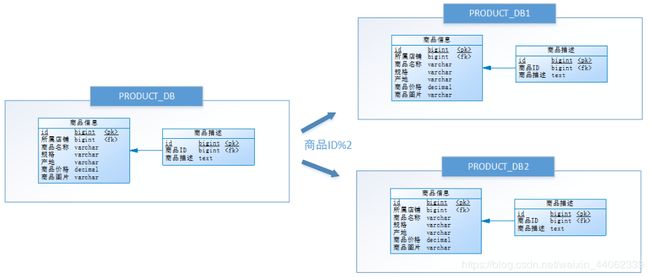
什么是水平分库呢?
就是说将这个库中的表中的数据分到其他数据库中,比如(我们对表中的id进行区分操作):先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。此操作要访问数据库名称的表达式为RRODUCT_DB[店铺ID%2 + 1] ;

里面的数据是两个不同位置库分的
而我们的水平分库也是需要用mycat——>按照一定规则将表中的数据拆分到去数据库中,每个库可以在不同的服务器上,然后我们的不同数据节点会将数据回显给mycat,进行整理再返回
select user()
a
select user()
select user()
区别:
1.水平分库是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上
2.垂直分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构,强调业务
总结:当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
水平分表
个人感觉比较一般,首先它的定义是:将同一个表的数据按照数据行分配到同一个数据库的多张表中,因为是同一个数据库,所以用的资源还是同一个物理机,只是说在一定程度上缓解了单表1000w的压力;
mycat实现分库分表
mycat通过rule.xml来定义表的分片规则来进行分片->包括分片字段与分片算法(hash、取模、xx)

1.Schema:逻辑库,与MySQL中的Database(数据库)对应,一个逻辑库中定义了所包括的Table。
2.Table:逻辑表,即物理数据库中存储的某一张表,与传统数据库不同,这里的表需要声明其所存储的逻辑数据节点DataNode。在此可以指定表的分片规则。
3.DataNode:MyCAT的逻辑数据节点,是存放table的具体物理节点,也称之为分片节点,通过DataSource来关联到后端某个具体数据库上
4.Database:定义某个物理库的访问地址,用于捆绑到Datanode上
5.分片规则:前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度
水平分库
select user()
a
select user()
select user()
rules.xml配置
id
mod-long
3
按照范围进行分片、取模分片
(22条消息) 数据库系列之MySQL基于Mycat的分库分表实现_solihawk的博客-CSDN博客_mysql分库分表怎么实现
mycat实操场景:
当大量请求(双十一)涌入数据库,此时肯定是读>>写操作的,那么我们就需要读写分离,大量服务器承担读操作的压力,写操作因为压力较小,服务器可以配置的较少;
而我们的数据库主从,从机也是可以执行写操作的(与redis那些不一样),只要有该权限的用户,那么就可以进行操作;
mycat场景:如果主机挂掉了,那么配置文件需要修改,那么mysql需要重启,那么java代码部署的项目也要重启
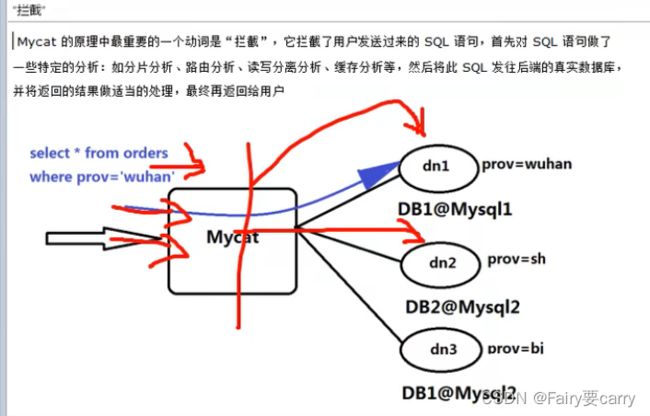
这时候就需要mycat了(一个mysql中间件)——>一端连接数据库,一端连接java,mycat作为中间的拦截请求的作用,sql发给mycat(看是读or写),然后将数据发送配置的dataNode上;
原理:多个数据节点支持同一套数据,得先搭建mysql的主从复制,才能搭建读写分离
(26条消息) sql主从复制搭建_Fairy要carry的博客-CSDN博客
(26条消息) sql主从复制搭建_Fairy要carry的博客-CSDN博客

原理图:

mycat配置
1.schema.xml文件中配置读写分离
数据节点:数据库 、读主机,写主机
4
5
6
7
8
11 select user()
12
13
15
16
18
19
2.验证数据库访问情况:
注意如果报错可能是没有创建这个用户,我们grant一下就行了
grant all privileges on *.* to root@'缺少的host' identified by '123123';3.进入主机数据库
mysql -uroot -p123 -h 192.168.184.1 -P 3306
4.进入远程虚拟机中的数据库
mysql -uroot -p123 -h 192.168.184.129 -P 3306
5.执行mycat(报的java错误)
./mycat console

6. 登录mycat
7.然后进行访问,对mycat节点访问,然后mycat的控制台会有提示
![]()
mysql -umycat -p123 -P 8066 -h 192.168.184.129
可以发现我们这个sql是由mycat提供的访问,验证了mycat中间介质的作用 (可以连接多个数据源)

mycat控制台的提示:
![]()
8. 对数据库执行操作,因为主从复制
这里出现了个小bug,主从复制失效,我们这里mysql用的是mycat,所以start slave会报错,我们另外开启一个控制台远程连接mysql从机,然后stop slave,再reset,最后重新start,弄好之后,再回到mycat那部分,我们quit退出一下,然后从新启动mycat
因为我们重启造成事务回滚
cnm,还是失败这里搞了好久,发现主机的postion发生了变化,从机需要修改位置postion
CHANGE MASTER TO MASTER_HOST='192.168.184.1',
MASTER_USER='slave190401',
MASTER_PASSWORD='123',
MASTER_LOG_FILE='mysqlbin.000001',MASTER_LOG_POS=107;okk 了

然后执行数据库操作
mysql读写分离配置

配置注意:我们需要再次进入schema.xml将balance重新配置为2,然后重启mycat服务,重启完后,我们的mycat节点访问mysql也要重新登录访问;(数据库是TESTDB)
然后select发现分发了,主机从机都有可能;——>读写分离成功

分库
分库就是将表分给名字相同但是位置不同的数据库中;
如何分库,怎么分:
把表分在不同的库上、不同机器上——>如果分在一台机器的不同数据库上,跨库join没问题,但是不同机器就不行了——>所以说,不需要关联的就进行分库
需要干净的库,什么都没有
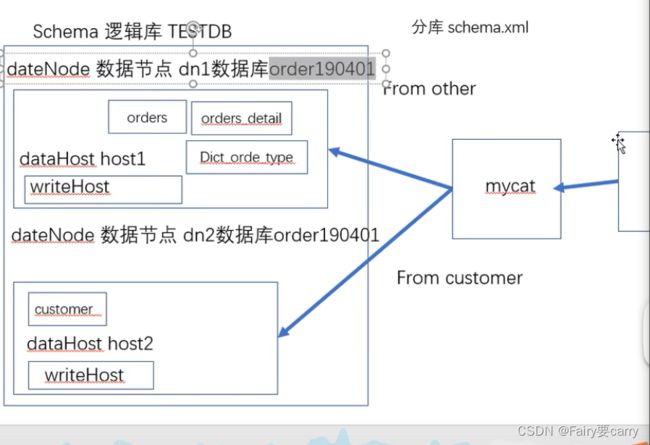
1. 修改配置文件schema.xml
select user()
select user()
2.然后重新启动mycat
![]()
然后我们再在mycat中执行sql操作(mycat核心:拦截)
作用:拦截sql语句,对其进行分析,比如我们创建客户表,然后它会分析是给到那个数据节点,从而达到分库操作
这样好处:每个数据库中的数据量没那么多(毕竟表),缓解了数据库压力
3. 在mycat执行创建customer的语句
#客户表 rows:20万
CREATE TABLE customer(
id INT AUTO_INCREMENT,
NAME VARCHAR(200),
PRIMARY KEY(id)
);
#订单表 rows:600万
CREATE TABLE orders(
id INT AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id)
);
#订单详细表 rows:600万
CREATE TABLE orders_detail(
id INT AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
);
#订单状态字典表 rows:20
CREATE TABLE dict_order_type(
id INT AUTO_INCREMENT,
order_type VARCHAR(200),
PRIMARY KEY(id)
);
select o.*,od.detail,d.order_type
from orders o
inner join orders_detail od on o.id =od.order_id
inner join dict_order_type d on o.order_type=d.id
where o.customer_id=xxxx
发现在这个库中,而不是在本地库中

然后多创建了表,发现都在本地数据库中了
4.远程sqlyog连接一下mycat

mycat作为发牌者,拥有拦截的数据

分表
根据id进行分表(类似于redis集群中插槽,将值分到对应范围内的机器)
1.验证分表:
原理还是mycat的作用,对sql进行拦截,根据配置文件,转发给对应的数据库,然后数据库节点得到数据后回复给mycat,mycat进行整理后,再转发给java;
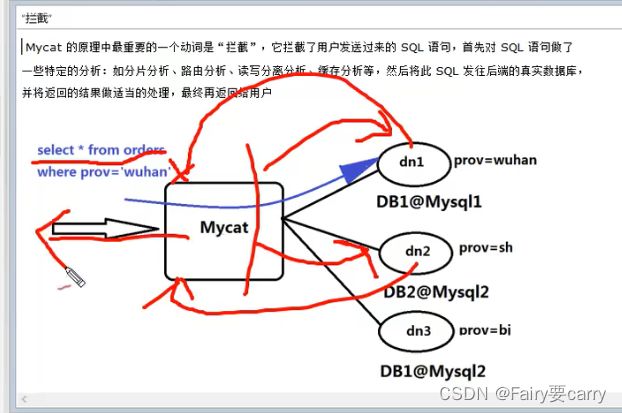
配置文件解析:
customer这个表作dn2数据节点,数据库是order190401,datahost配置为host2,位置是我们虚拟机那台数据库,所以说当对这个表进行操作,数据就会往dn2这个节点做请求,然后dn2会把数据回显给mycat这个发牌者;
select user()
select user()
主机库里的order数据
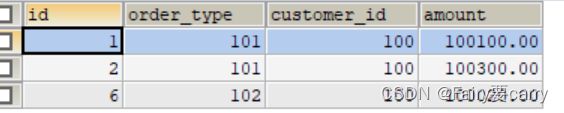
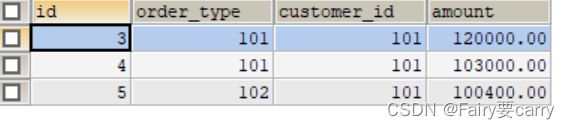
虚拟机这个数据库的order数据
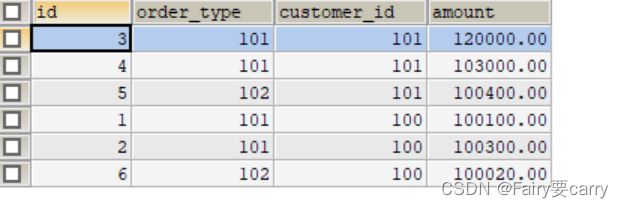
mycat中的order数据
(会发现345一起,126一起,验证了数据节点会回复数据给到mycat,然后进行整理)
订单详情表怎么分?跨库联合查询怎么搞?
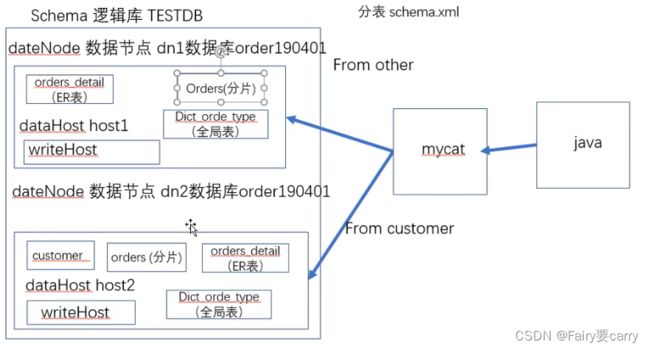
会发现全局表在配置文件配置后,我们再在mycat对该表进行插入数据,本地和虚拟机远程数据库中都有该数据