AI作画升级!一键帮你用Stable Diffusion 生成无限缩放效果视频
在这一篇文章中,我们介绍了利用OpenVINO™优化和加速Stable Diffusion模型的推理,在英特尔®独立显卡上能够根据我们输入的指令(prompt),快速生成我们喜爱的AI画作。今天,我们对这一应用场景再次升级,除了能够作画,利用OpenVINO对Stable Diffusion v2模型的支持及优化,我们还能够在在英特尔®独立显卡上快速生成带有无限缩放效果的视频,使得AI作画的效果更具动感,其效果也更加震撼。话不多说,接下来还是让我们来划划重点,看看具体是怎么实现的吧。
本次无限缩放Stable Diffusion v2视频生成的全部代码请戳这里openvino_notebooks/236-stable-diffusion-v2-infinite-zoom.ipynb at main · openvinotoolkit/openvino_notebooks · GitHub OpenVINO Notebooks运行环境的安装请您参考我们的上一篇AI作画博客
此次我们应用的深度学习模型是Stable Diffusion v2模型,相比它的上一代v1模型,它具有一系列新特性,包括配备了一个新的鲁棒编码器OpenCLIP,由LAION创建,并得到了Stability AI的帮助,与V1版本相比,此版本显著增强了生成的照片。另外,v2模型在之前的模型基础上增加了一个更新的修复模块(inpainting)。这种文本引导的修复使切换图像中的部分比以前更容易。也正是基于这一新特性,我们可以利用stabilityai/stable-diffusion-2-inpainting模型,生成带有无限缩放效果的视频。
在图像编辑中,Inpainting是一个恢复图片缺失部分的过程。最常用于重建旧的退化图像,从照片中去除裂纹、划痕、灰尘斑点或红眼。但凭借AI和Stable Diffusion模型的力量,Inpainting可以实现更多的功能。例如,它可以用来在现有图片的任何部分渲染全新的东西,而不仅仅是恢复图像中缺失的部分。只要发挥你的想象力,你可以做出更多炫酷效果的作品来。
下面的工作流程图解释了用于Inpainting的Stable Diffusion inpainting流水线是如何工作的:
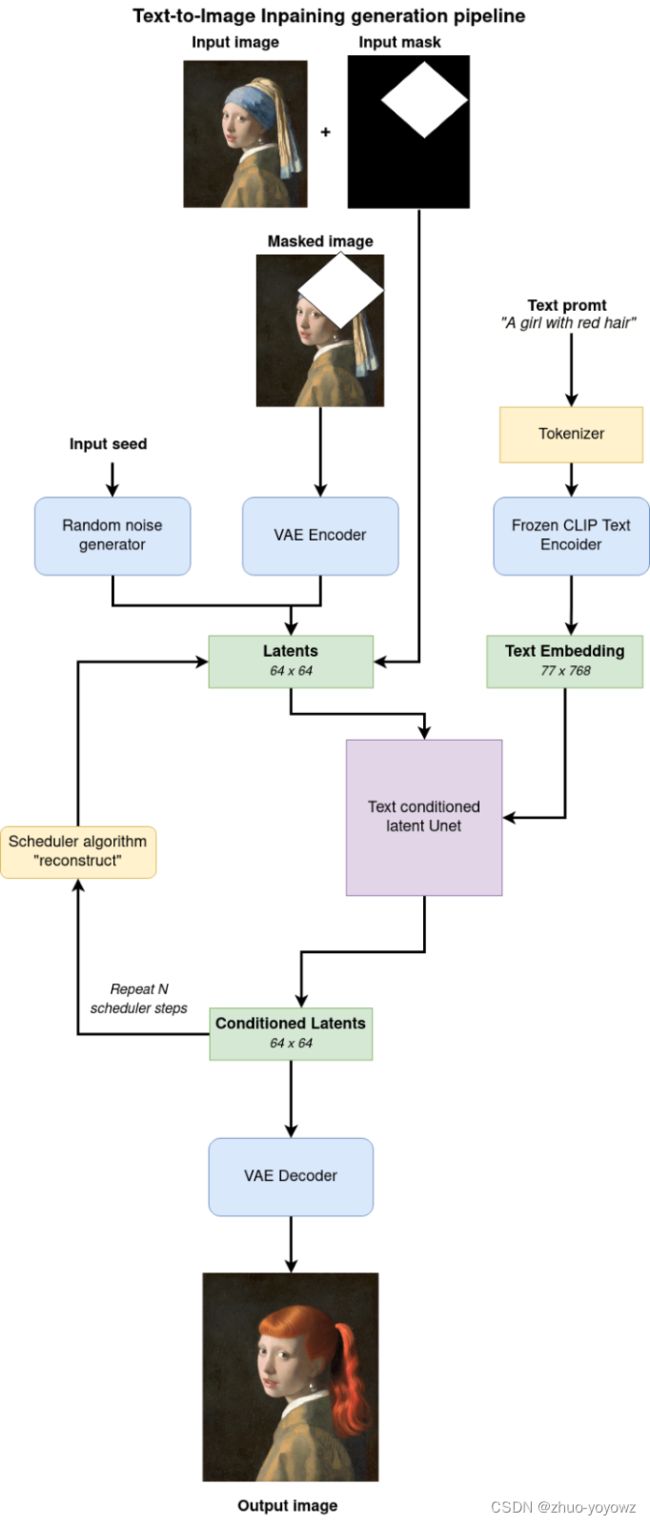
在此次的代码示例中,我们将完成以下几个步骤:
-
将PyTorch 模型转换为ONNX格式。
-
利用Model Optimizer 工具,将ONNX 模型转换为OpenVINO IR 格式。
-
运行Stable Diffusion v2 inpainting 流水线,生成无限缩放效果视频。
现在,让我们来重点来看看如何配置推理流水线的代码。
这里主要分以下三个步骤:
-
在推理的硬件设备上加载模型Load models on device
-
配置分词器和调度器Configure tokenizer and scheduler
-
创建OvStableDiffusionInpaintingPipeline 类的示例
我们在配备英特尔锐炫™独立显卡的机器上加载模型并运行推理,因此推理设备我们选择“GPU”。默认情况下,它使用“ AUTO”,并会自动切换至检测到的 GPU。代码如下:
from openvino.runtime import Core
core = Core()
tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-large-patch14')
text_enc_inpaint = core.compile_model(TEXT_ENCODER_OV_PATH_INPAINT, "GPU")
unet_model_inpaint = core.compile_model(UNET_OV_PATH_INPAINT, " GPU ")
vae_decoder_inpaint = core.compile_model(VAE_DECODER_OV_PATH_INPAINT, "GPU")
vae_encoder_inpaint = core.compile_model(VAE_ENCODER_OV_PATH_INPAINT, "GPU")
ov_pipe_inpaint = OVStableDiffusionInpaintingPipeline(
tokenizer=tokenizer,
text_encoder=text_enc_inpaint,
unet=unet_model_inpaint,
vae_encoder=vae_encoder_inpaint,
vae_decoder=vae_decoder_inpaint,
scheduler=scheduler_inpaint,
) 
接下来,我们输入文本提示,运行视频生成的代码吧。
import ipywidgets as widgets
zoom_prompt = widgets.Textarea(value="valley in the Alps at sunset, epic vista, beautiful landscape, 4k, 8k", description='positive prompt', layout=widgets.Layout(width="auto"))
zoom_negative_prompt = widgets.Textarea(value="lurry, bad art, blurred, text, watermark", description='negative prompt', layout=widgets.Layout(width="auto"))
zoom_num_steps = widgets.IntSlider(min=1, max=50, value=20, description='steps:')
zoom_num_frames = widgets.IntSlider(min=1, max=50, value=3, description='frames:')
mask_width = widgets.IntSlider(min=32, max=256, value=128, description='edge size:')
zoom_seed = widgets.IntSlider(min=0, max=10000000, description='seed: ', value=9999)
zoom_in = widgets.Checkbox(
value=False,
description='zoom in',
disabled=False
)
widgets.VBox([zoom_prompt, zoom_negative_prompt, zoom_seed, zoom_num_steps, zoom_num_frames, mask_width, zoom_in]) 
在这一步中,我把步骤设置为 20。理想情况下,我将使用 50,以提供最好看的结果。另外,这里还可以自行设置生成的图画数量,所有生成的图画将组合起来构成最后的无限缩放效果视频。当然,我们同样还生成了 GIF 文件,以便大家多种形式可视化展示生成结果。
最终结果。
stable_diffusion_video
总结
当下,如果您想了解“Stable Diffusion”的工作原理,以及英特尔硬件的加速方式,OpenVINO Notebooks 无疑是首选。如果您有任何疑问或想要展示您的一些最佳成果,请在下方评论或通过我们的 GitHub 讨论板发表评论! 祝大家编码快乐啦。