LINUX学习------Linux自动化运维——LVS
lvs介绍
LVS(Linux Virtual Server)是一个虚拟的服务器集群系统,可以在unix/linux平台下实现负载均衡集群功能。 LVS是一种集群(Cluster)技术,采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序

LVS的模型中有两个角色:
调度器:Director Server(DS),又称为Dispatcher,Balancer (调度器主要用于接受用户请求)
真实主机:Real Server,简称为RS。 (用于真正处理用户的请求)角色的IP地址分为以下三种:
Director Virtual IP:调度器用于与客户端通信的IP地址,简称为VIP
Director IP:调度器用于与RealServer通信的IP地址,简称为DIP。
Real Server : 后端主机的用于与调度器通信的IP地址,简称为RIP。
LVS的IP负载均衡技术是通过IPVS模块来实现的,IPVS实现负载均衡机制有三种,分别是NAT(-m)、TUN(-i)和DR(-g)
LVS的三种调度模式
LVS-NAT (Network Address Transform)

原理:
基于ip伪装MASQUERADES,原理是多目标DNAT。 所以请求和响应都经由Director调度器。LVS-NAT的优点与缺点
1、优点:
支持端口映射
RS可以使用任意操作系统
节省公有IP地址。
RIP和DIP都应该使用同一网段私有地址,而且RS的网关要指向DIP。
使用nat另外一个好处就是后端的主机相对比较安全。2、缺点:
请求和响应报文都要经过Director转发;极高负载时,Director可能成为系统瓶颈。效率低下。
LVS-TUN (IP Tuneling)

原理:
基于隧道封装技术。在IP报文的外面再包一层IP报文。 当Director接收到请求的时候,选举出调度的RealServer
当接受到从Director而来的请求时,RealServer则会使用lo接口上的VIP直接响应CIP。
这样CIP请求VIP的资源,收到的也是VIP响应。
LVS-TUN的优点与缺点
优点:
RIP,VIP,DIP都应该使用公网地址,且RS网关不指向DIP;
只接受进站请求,解决了LVS-NAT时的问题,减少负载。
请求报文经由Director调度,但是响应报文不需经由Director。缺点:
不指向Director所以不支持端口映射。
RS的OS必须支持隧道功能。
隧道技术会额外花费性能,增大开销。
LVS-DR (Direct Routing)

原理
当Director接收到请求之后,通过调度方法选举出RealServer。 讲目标地址的MAC地址改为RealServer的MAC地址。
RealServer接受到转发而来的请求,发现目标地址是VIP。RealServer配置在lo接口上。
处理请求之后则使用lo接口上的VIP响应CIP。
LVS-DR的优点与缺点
优点:
RIP可以使用私有地址,也可以使用公网地址。
只要求DIP和RIP的地址在同一个网段内。
请求报文经由Director调度,但是响应报文不经由Director。
RS可以使用大多数OS
缺点:
不支持端口映射。
不能跨局域网。
LVS的八种基本调度方法
静态方法:仅依据算法本身进行轮询调度
1、RR:Round Robin,轮调
一个接一个,自上而下
2、WRR:Weighted RR,加权论调
加权,手动让能者多劳。
3、SH:SourceIP Hash
来自同一个IP地址的请求都将调度到同一个RealServer
4、DH:Destination Hash
不管IP,请求特定的东西,都定义到同一个RS上。动态方法:根据算法及RS的当前负载状态进行调度
1、LC:least connections(最小链接数)
链接最少,也就是Overhead最小就调度给谁。
假如都一样,就根据配置的RS自上而下调度。2、WLC:Weighted Least Connection (加权最小连接数)
这个是LVS的默认算法。3、SED:Shortest Expection Delay(最小期望延迟)
WLC算法的改进。4、NQ:Never Queue
SED算法的改进。
一、lvs集群的搭建
server1(负载均衡器)
yum install -y ipvsadm
ip addr add 172.25.22.100/24 dev eth0
ipvsadm -C ##清除原有策略
ipvsadm -A -t 172.25.22.100:80 -s rr ##添加虚拟服务,lvs默认80端口
ipvsadm -a -t 172.25.22.100:80 -r 172.25.22.2:80 -g ##关联真实服务
ipvsadm -a -t 172.25.22.100:80 -r 172.25.22.3:80 -g
ipvsadm ##启用策略
ipvsadm -ln ##查看节点状态,Masq代表 NAT模式
ipvsadm-save > /etc/sysconfig/ipvsadm ##保存策略
ipvsadm -d -t 172.25.22.100:80 -r 172.25.22.2 ##删除单条策略


DR模式
server2
yum install httpd -y
systemctl enable --now httpd
echo server2 > /var/www/html/index.html
server3
yum install httpd -y
systemctl enable --now httpd
echo server3 > /var/www/html/index.html
当客户端访问真实主机时,会把资源扔到后台导致无法访问,但实际客户端是有访问记录的,这时就需要通过vip来进行访问


ip addr add 172.25.22.100/32 dev eth0 ##添加vip

当设置vip后客户端访问real server时,因为在同一个vlan中,客户端访问的vip在real
server上,此时需要arptables禁用real server的vip地址
server2(apache)
arp -an |grep 100 ##查询ip
yum install arptables.x86_64 -y
ip addr add 172.25.22.100/32 dev eth0
arptables -A INPUT -d 172.25.22.100 -j DROP
arptables -A OUTPUT -s 172.25.22.100 -j mangle --mangle-ip-s 172.25.22.2 ##屏蔽vip
arptables -nL ##查看策略
arptables-save > /etc/sysconfig/arptables ##保存策略

server3(apache)
yum install arptables.x86_64 -y
ip addr add 172.25.22.100/32 dev eth0
arptables -A INPUT -d 172.25.22.100 -j DROP
arptables -A OUTPUT -s 172.25.22.100 -j mangle --mangle-ip-s 172.25.22.3
arp -d 172.25.22.100 ##删除客户端vip
arp -an | grep 100 ##重新查询后显示的时调度器ip
二、ipvsadm+keepalived高可用
Keepalived是Linux下一个轻量级别的高可用解决方案。高可用(High
Avalilability,HA),其实两种不同的含义:广义来讲,是指整个系统的高可用行,狭义的来讲就是之主机的冗余和接管
Keepalived和LVS,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层交换机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点高可用:两台业务系统启动着相同的服务,如果有一台故障,另一台自动接管,我们将将这个称之为高可用
健康检查
server1
ip addr del 172.25.22.100/24 dev eth0
ipvsadm -C ##清除之前的策略,确保无手动添加的记录
yum install -y keepalived
yum install -y mailx
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost ##本机发送邮件
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 22 ##master和backup在同一虚拟机,id号一致
priority 100 ##优先级,谁优先级高谁是master
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress { ##vip
172.25.22.100
}
}
virtual_server 172.25.22.100 80 {
delay_loop 3
lb_algo rr
lb_kind DR
#persistence_timeout 50
protocol TCP
real_server 172.25.22.2 80 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.25.22.3 80 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
systemctl start keepalived.service
ip addr
ipvsadm -ln
测试
systemctl stop httpd (server2)

高可用
备机(master)server4
yum install -y keepalived
yum install -y mailx
scp keepalived.conf server4:/etc/keepalived/keepalived.conf
vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email {
root@localhost
}
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 22
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
172.25.22.100
}
}
virtual_server 172.25.22.100 80 {
delay_loop 3
lb_algo rr
lb_kind DR
#persistence_timeout 50
protocol TCP
real_server 172.25.22.2 80 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 172.25.22.3 80 {
weight 1
TCP_CHECK {
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
systemctl start keepalived.service
测试
systemctl stop keepalived.service (server2)
server4成为调度器,当serve1启动,因为优先级较高重新成为master

三、Haproxy
Haproxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。Haproxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。Haproxy运行在当前的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中, 同时可以保护你的web服务器不被暴露到网络上。
Haproxy实现了一种事件驱动, 单一进程模型,此模型支持非常大的并发连接数。多进程或多线程模型受内存限制 、系统调度器限制以及无处不在的锁限制,很少能处理数千并发连接。事件驱动模型因为在有更好的资源和时间管理的用户空间(User-Space)
server1
yum install -y haproxy
systemctl stop httpd.service 需要用80端口 停止httpd
vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
#Example configuration for a possible web application. See the
#full configuration options online.
#
#http://haproxy.1wt.eu/download/1.4/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
#Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
#common defaults that all the 'listen' and 'backend' sections will
#use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
stats uri /status
stats auth admin:westos
#---------------------------------------------------------------------
#main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main *:80
#acl url_static path_beg -i /static /images /javascript /stylesheets
#acl url_static path_end -i .jpg .gif .png .css .js
#use_backend static if url_static
default_backend app
#---------------------------------------------------------------------
#static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
#backend static
#balance roundrobin
#server static 127.0.0.1:4331 check
#---------------------------------------------------------------------
#round robin balancing between the various backends
#---------------------------------------------------------------------
backend app
balance roundrobin
server app1 172.25.22.2:80 check ##可配置权重,weight=2
server app2 172.25.22.3:80 check
systemctl start haproxy.service
server2
清除server2,server3上的残留策略
ip addr del 172.25.22.100/32 dev eth0
systemctl stop arptables.service
server3
ip addr del 172.25.22.100/32 dev eth0
systemctl stop arptables.service
测试
刷新网页,负载均衡
 浏览器访问172.25.22.1/status 图形显示后台服务是否成功
浏览器访问172.25.22.1/status 图形显示后台服务是否成功
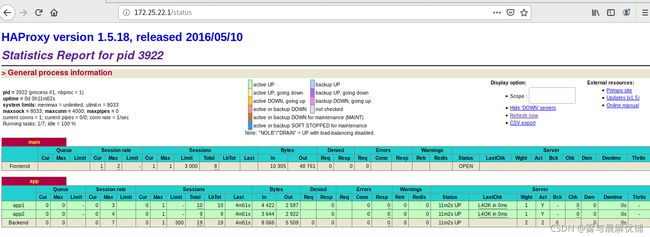
Haproxy个性化配置
浏览器访问配置文件中以’path_beg‘开头、 ’path_end‘结尾访问指定网页
server1
vim /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
#Example configuration for a possible web application. See the
#full configuration options online.
#
#http://haproxy.1wt.eu/download/1.4/doc/configuration.txt
#
#---------------------------------------------------------------------
#---------------------------------------------------------------------
#Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
#
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
#
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
#common defaults that all the 'listen' and 'backend' sections will
#use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
stats uri /status
stats auth admin:westos
#---------------------------------------------------------------------
#main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main *:80
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app
#---------------------------------------------------------------------
#static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend static
balance roundrobin
server static 172.25.22.3:80 check
#---------------------------------------------------------------------
#round robin balancing between the various backends
#---------------------------------------------------------------------
backend app
balance roundrobin
server app1 172.25.22.2:80 check
#server app2 172.25.22.3:80 check
systemctl reload haproxy.service
mkdir /var/www/html/images
vim.jpg
测试
配置conf文件,正常访问只能访问server2,当以策略文件中’path_beg‘开头、 ’path_end‘结尾 访问server3


设置黑名单
server1
acl blacklist src 172.25.22.250 ##当时用此ip访问
#block if blacklist ##禁止访问404报错
#errorloc 403 http://www.baidu.com ##报错403,并重定向
#redirect location http://www.taobao.com ##直接重定向
acl write method PUT
acl write method POST
use_backend static if write ##当有写入功能,定向use_backend static
#use_backend static if url_static
default_backend app
systemctl restart httpd.service
server2
cd /var/www/html
index.php index.html
mkdir upload
systemctl restart httpd.service
server3
cd /var/www/html
index.php index.htm
mkdir upload
systemctl restart httpd.service
systemctl restart httpd.service




当访问网页时访问server2,有写入功能时访问server3

pacemaker+haproxy双机热备
Pacemaker是 Linux环境中使用最为广泛的开源集群资源管理器, Pacemaker利用集群基础架构(Corosync或者
Heartbeat)提供的消息和集群成员管理功能,实现节点和资源级别的故障检测和资源恢复,从而最大程度保证集群服务的高可用。
server1
systemctl status keepalived.service
systemctl stop haproxy.service
sshd-keygen
ssh-copy-id server4:
cd /etc/yum.repos.d/
vim /etc/yum.repos.d/dvd.repo
yum install -y pacemaker pcs psmisc policycoreutils-python
scp dvd.repo server4:/etc/yum.repos.d/
ssh server4 yum install -y pacemaker pcs psmisc policycoreutils-python
systemctl enable --now pcsd.service
ssh server4 systemctl enable --now pcsd.service
echo westos | passwd --stdin hacluster
ssh server4 'echo westos | passwd --stdin hacluster'
pcs cluster auth server1 server4
pcs cluster setup --name mycluster server1 server4 ##在同一节点使用pcs集群生成和同步crosync配置
pcs cluster start --all ##启动集群
pcs cluster enable --all ##开机自启
crm_verify -LV
pcs property set stonith-enabled=false
crm_verify -LV ##查看集群状态
pcs status ##显示状态
pcs resource standards
pcs resource providers
pcs resource agents ocf:heartbeat
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.22.100 op monitor interval=30s ##设置vip
pcs resource create haproxy systemd:haproxy op monitor interval=60s
pcs resource group add hagroup vip haproxy
server4
systemctl status keepalived.service
systemctl stop haproxy.service
crm_mon ##监控
测试
pcs node standby ##关闭
pcs node unstandby ##开启


fence结合pacemaker防止文件系统脑裂
在高可用(HA)系统中,当联系2个节点的“心跳线”断开时,本来为一整体、动作协调的HA系统,就分裂成为2个独立的个体。由于相互失去了联系,都以为是对方出了故障。两个节点上的HA软件像“裂脑人”一样,争抢“共享资源”、争起“应用服务”,就会发生严重后果——或者共享资源被瓜分、2边“服务”都起不来了;或者2边“服务”都起来了,但同时读写“共享存储”,导致数据损坏(常见如数据库轮询着的联机日志出错)。
真机
yum install -y fence-virtd
yum install -y fence-virtd-multicast
yum install -y fence-virtd-libvirt
mkdir /etc/cluster
cd /etc/cluster/
dd if=/dev/urandom of=fence_xvm.key
scp fence_xvm.key [email protected]:/etc/cluster
scp fence_xvm.key [email protected]:/etc/cluster
![]()
selinux setenforce 0/防火墙
fence_virtd -c
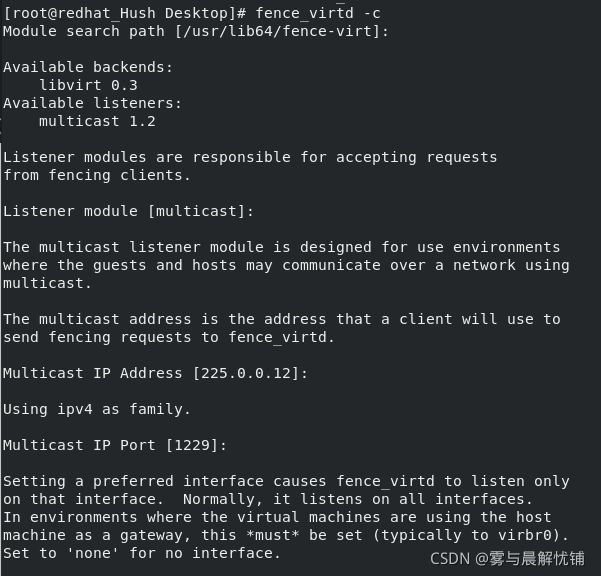



systemctl restart fence_virtd.service
server1
yum install -y fence-virt
mkdir /etc/cluster
stonith_admin -I
 stonith_admin -M -a fence_xvm
stonith_admin -M -a fence_xvm

pcs stonith create vmfence fence_xvm pcmk_host_map="server1:server1;server4:server4" op monitor interval=30s ##hsostname:虚拟化服务的域名
pcs property set stonith-enabled=true
crm_verify -LV
测试:
server1
ip link set down eth0 ##server1服务器的网卡down掉,master切换server4
server4
yum install -y fence-virt
mkdir /etc/cluster
echo c > /proc/sysrq-trigger ##破坏内核,master切换server1
fence和master是对立的,当fence在server1,master就在server2
