2021华为软件精英挑战总结
2021华为软挑32强总结
今年的软挑最终止步于粤港澳赛区第16名,总成本为16亿3979万6349,赛区第一名总成本为15亿3903万4817。
虽然没进入决赛,但是拿到了华为面试直通卡,也喜提广州一日游,算不虚此行了。决赛虽然还在继续,但是已与我无关,遂写一篇博客记录比赛历程,分享经验。
关注公众号 打代码的苏比特,获取java面试百问百答和面试高频算法题~
0.赛题描述
初赛赛题与复赛赛题略有不同,但是我们团队的思路初赛、复赛均适用,所以此处只描述复赛题目。另外,赛题为华为版权所有,此处只做简单描述。
云上资源的规划和调度是云计算场景中非常重要的一个优化问题。好的优化算法能够为云运营商节约上亿的运营成本,并为客户提供更稳定、更流畅的云端体验。
0.1服务器
服务器类型:在公有云的运营场景中,我们的数据中心可以选购的服务器类型有多种,服务器可以分为A 和B两个节点,服务器拥有的资源(CPU 和内存)均匀分布在这两个节点上。
服务器成本:数据中心使用每台服务器的成本由两部分构成:硬件成本和能耗成本。硬件成本是在采购服务器时的一次性支出,能耗成本是后续服务器使用过程中的持续支出。
0.2虚拟机
虚拟机类型:我们面向用户提供了多种类型的虚拟机售卖服务,用户可以根据自己的需求来自由选购。不同的虚拟机类型,有不同的CPU、内存需求。
单节点/双节点部署:由于服务器存在两个节点,对应的虚拟机也存在两种部署方式:单节点部署或双节点部署。单节点部署指的是一台虚拟机所需的资源(CPU和内存)完全由主机上的一个节点提供;双节点部署指的是一台虚拟机所需的资源(CPU 和内存)必须由一台服务器的两个节点同时提供,并且每个节点提供总需求资源的一半。
0.3资源规划与调度
- 容量约束:服务器可以用来容纳用户的虚拟机,但是服务器上的任意一个节点(A和B)上的资源负载(CPU 和内存)均不能超过其容量上限。
- 请求类型:用户的请求共分为两种类型:创建请求和删除请求。
- 请求序列:由一系列请求构成的序列。题目会给出接下来若干天中每一天用户的请求序列,根据每天的请求序列,你需要进行相应的资源规划和调度。
- 数据中心扩容:在得知了一天的请求序列后,你可以在实际进行调度前进行一次数据中心扩容。即购买一些新的服务器来容纳后续用户请求的虚拟机,同时你需要付出所购买服务器相应的硬件成本。
- 虚拟机迁移:在完成扩容后,在处理每一天的新请求之前,你还可以对当前存量虚拟机进行一次迁移,即把虚拟机从一台服务器迁移至另一台服务器。迁移的虚拟机总量不超过当前存量虚拟机数量的百分之三。即假设当前有n 台存量虚拟机,每天你可以迁移的虚拟机总量不得超过3n/100 向下取整。
- 部署虚拟机:在完成扩容和迁移之后,你需要按顺序处理当天所有的新请求。对于每一个创建虚拟机的新请求,你要为虚拟机指定一台服务器进行部署。若虚拟机是单节点部署的,你还需要指明部署在服务器的A 节点还是B 节点。处理请求的过程中,任意一台服务器上每个节点容纳的虚拟机资源总和都不能超出节点本身的资源容量(指CPU 和内存两个维度)。
- 未知请求序列:在初赛中,我们面对的是提前知晓了未来所有用户请求序列的场景,这在实际中是很难作到的。现实场景中,我们往往只能预测后续较短的一段时间内用户可能的请求序列。所以在复赛中,你需要面对这种存在未知的场景,进行云上的资源规划和调度。
0.4输入输出

本题使用交互式评测,你的程序应该从标准输入读取输入,并将输出打印至标准输出。交互协议如下:
- 输入的第一行包含一个整数N(1≤N≤100),表示可以采购的服务器类型数量。
- 接下来N 行,每行描述一种类型的服务器,数据格式为:(型号, CPU 核数, 内存大小, 硬件成本, 每日能耗成本)。
- 接下来一行包含一个整数M(1≤M≤1000),表示售卖的虚拟机类型数量。
- 接下来M 行,每行描述一种类型的虚拟机,数据格式为:(型号, CPU 核数, 内存大小, 是否双节点部署)。
- 接下来一行包含一个整数T(1≤T≤1000)和一个整数K(1≤K≤T),分别表示共有T 天的用户请求序列数据,初始你只知晓前K 天的数据。
- 接下来会按顺序给出K 天的用户请求序列,每一天的数据格式如下:
- 对于每一天的数据,第一行包含一个整数R 表示当天共有R 条请求。
- 接下来R 行,按顺序给出每一条请求数据。请求数据的格式为:(add, 虚拟机型号, 虚拟机ID)或(del, 虚拟机ID)分别表示创建一台虚拟机或者删除一台虚拟机。
- 当读取完前K 天的请求序列数据后,你的程序需要输出第一天的决策信息,每天的决策信息格式如下:
- 首先第一行输出(purchase, Q),其中Q 是一个整数表示你需要扩容购买多少种类型的服务器。Q 不能为负数且不能大于N。
- 接下来Q 行,每行的格式为:(服务器型号, 购买数量)。
- 你所购买的每一台服务器都会被分配一个编号,从零开始。
- 接下来一行输出(migration, W),其中W 是一个整数表示你要迁移的虚拟机的数量。
- 接下来W 行,每行表示一个虚拟机的迁移,格式为(虚拟机ID, 目的服务器ID)或(虚拟机ID, 目的服务器ID, 目的服务器节点)。
- 接下来按输入中请求的顺序,输出对于当前这一天的每一个创建请求,该虚拟机部署的服务器ID,格式为(服务器ID)或者(服务器ID, 部署节点)。
- 当你的程序完整输出了第一天的决策信息后,你将会读取到第K+1 天的请求序列数据。然后你需要输出第二天的决策信息,并且读取第K+2 天的请求序列,以此类推。
- 当你已经完整地读取了所有T 天的请求序列数据后,你只需要按顺序输出剩余的决策信息,不再需要作读入。
0.5输入输出样例
<---- input ----> (用于说明,该行非实际交互数据)
2
(NV603, 92, 324, 53800, 500)
(NV604, 128, 512, 87800, 800)
2
(c3.large.4, 2, 8, 0)
(c3.8xlarge.2, 32, 64, 1)
3 2
2
(add, c3.large.4, 5)
(add, c3.large.4, 0)
2
(del, 0)
(add, c3.8xlarge.2, 1)
<---- output ----> (用于说明,该行非实际交互数据)
(purchase, 2)
(NV603, 1)
(NV604, 1)
(migration, 0)
(0, A)
(0, B)
<---- input ----> (用于说明,该行非实际交互数据)
3
(add, c3.large.4, 2)
(del, 1)
(del, 2)
<---- output ----> (用于说明,该行非实际交互数据)
(purchase, 0)
(migration, 0)
(1)
(purchase, 0)
(migration, 0)
(1, B)
0.6评分规则
总成本低的方案胜出。总成本包含两部分:购买服务器的整体硬件成本以及服务器消耗的整体能耗成本。整体硬件成本即将选手输出的方案中所有购买的服务器的硬件成本相加。整体能耗成本的计算方式为:在处理完每一天的所有操作后(包括迁移,创建和删除),裁判程序会将当前有负载(至少部署了一台虚拟机)的服务器视为开机状态,没有任何负载的服务器视为关机状态,以此计算当天的能耗成本。整体能耗成本即每一天的能耗成本的总和。
1.思路探索(心路历程)
-
baseline。拿到初赛题目的时候,先写了第一个java版本的baseline,直接大力出奇迹,先冲个5000台服务器,能满足所有要求。主要是解决IO以及代码提交的问题。
-
服务器部署策略。部署策略为最简单、朴素的策略,从第一个服务器开始,遍历到能满足当前请求的服务器,将当前请求部署在该服务器上。类似于操作系统中磁盘分配的FirstFit算法。
-
优化购买策略。在第一个大力出奇迹的版本上,加入全新的服务器购买策略。
- 统计当日请求中最大需求的CPU cpuMax及最大内存memoryMax
- 在可购买的服务器列表中,寻找到能满足cpuMax和memoryMax的服务器serverChoose
- 购买和当日请求数量相同台数的serverChoose,这样可以确保能够处理所有的请求
-
实现迁移。
-
定义服务器资源剩余率。计算方式为:(剩余CPU数*100/初始CPU数)+(剩余Memory数*100/初始Memory数),如此初始的资源剩余率为200,随着使用资源剩余率逐渐下降。代码如下:
//当服务器上未部署虚拟机时,资源剩余率为200 A_Core + B_Core) * 100 / CoresInit + (A_Memory + B_Memory) * 100 / MemoriesInit -
server类实现Comparable接口,方便排序
static class Server implements Comparable<Server> -
将serverList按服务器资源利用率进行排序
//因为Server类实现了Comparable接口,所以可以直接调用该方法进行排序 Collections.sort(serverList); -
简单朴素的迁移策略,将服务器利用率小的服务器上的虚拟机,迁移到服务器利用率大的服务器上,争取将利用率高的服务器填满,将利用率低的服务器排空。
-
serverList排序之后,从服务器利用率小的向前遍历,拿到资源利用率最小的服务器,遍历该服务器上的虚拟机,分别拿出每一个虚拟机,再从服务器利用率高的向后遍历,尝试将拿出的虚拟机部署到该服务器上。

-
但是这个遍历策略有一个十分致命的额问题,它采用了三层for循环,时间复杂度过高,后续在提交代码的过程中发生了超时。
-
-
优化购买策略,加入服务器性价比排序。和迁移中的排序一样,定义一个服务器的性价比,购买服务器时,选择能满足要求且性价比最高的购买。性价比的计算方法为:服务器价格/(cpu数+内存数)。计算代码如下:
double performance = (price + 0.0) / (cores + memories); -
新的购买策略。
-
读取当天的所有请求,存入todayRequestList中
-
依次处理todayRequestList中的请求,如果处理成功,则将该条记录从todayRequestList删除
-
若处理失败,则表示当前剩余的服务器资源不足以处理剩余的请求了,需要购买新的服务器。
-
此时,todayRequestList中为剩余的未处理的请求。统计todayRequestList中的请求,计算剩余请求总共需要的CPU及memory(totalCoreRequest和totalMemoRequest),和剩余请求中最大需求的CPU及Memory(maxCore和maxMemory)
-
遍历服务器List,找到可以满足maxCore和maxMemory需求,且花费最小的服务器。其中,花费不仅考虑服务器的价格,还考虑了服务器的电费消耗,即 用购买数量*购买该服务器时剩余待处理数据天数lastDay*电费,代码如下:
int cost = num * serverInfo.price + num * lastDay * serverInfo.powerCost;
-
-
统一输出。将所有的输出信息存入List中,包括服务器购买、迁移、虚拟机部署信息,在合适的时候,统一输出这些信息。
-
细节优化,减小程序运行时间。
- 初始化ArrayList及HashMap时指定初始大小,减少扩容耗时。
- 将除法改为位移
- 将不必要放在for循环内的操作,移到循环外
-
迁移玄学调参。
- 由于迁移三层for循环时间复杂度过高,为避免超时,加入参数进行调节。
- 设置了三个参数
- 资源剩余率小于X的服务器,不向其迁移虚拟机
- 排序后,serverList后半段资源利用率低,所以可以取serverList后Y%进行迁移,而前1-Y%则不考虑迁移
- 同样的,serverList前半段资源利用率高,所以可以去serverList前Z%接收迁移的虚拟机。
- 其中,X、Y、Z为可调参数
2.最终思路
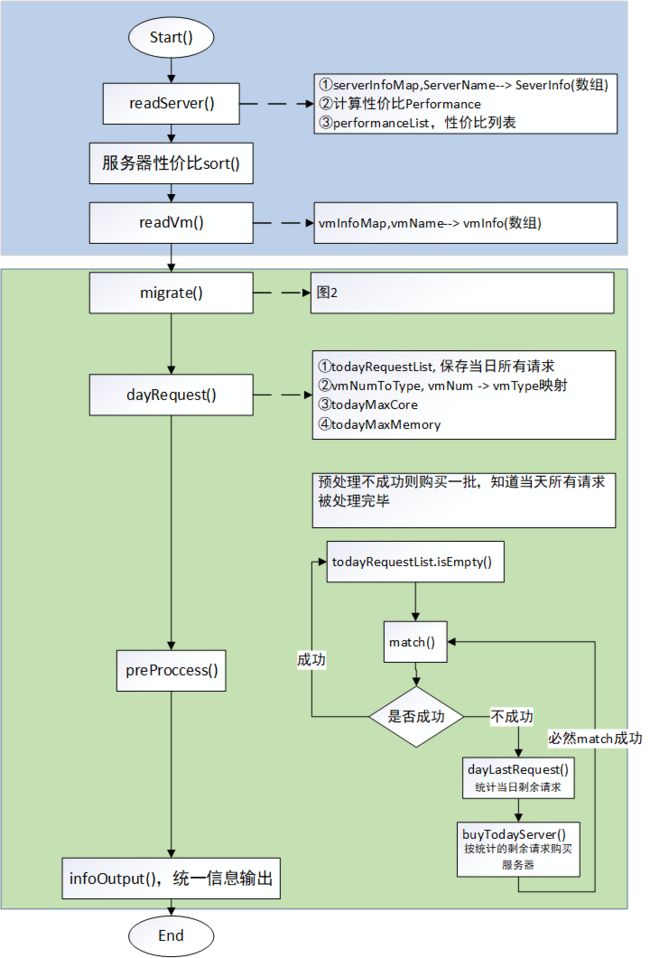
最终的思路基本是延续了上面的心路历程中的最终版本,基本的流程图如上,其中,迁移部分一直使用着最简单朴素的方式,在流程图中未画出。
3.可继续优化的点
- 服务器部署策略。本策略中只采用了最简单的部署方法,类似于操作系统磁盘分配中的FirstFit算法,还可以尝试入NextFit、BestFit等其他算法,可能会有更好的效果。
- 服务器购买策略。本策略中,虽然后续改进了购买策略,但是依然是每次购买能满足剩余最大请求maxCore和maxMemory的服务器,即每次购买的服务器过于单一。如果每天先预处理,每天只买刚好能够处理当天请求的服务器,或许能得到更好的效果。
- 服务器迁移策略。迁移策略时间复杂度太高,并且没有使用类似于BestFit算法等的匹配策略,直接能迁移就迁移,可能没有得到最好的效果。
4.比赛代码(java)
未经整理的代码:https://gitee.com/MicahYin/code-craft2021/tree/master
5.个人总结
- 队友很重要。师弟在比赛中是中流砥柱,发挥了至关重要的作用。
- 变量规范命名。如数据类型为List,则命名为serverList;数据类型为Map,则命名为vmInfoMap。这样会使变量类型一目了然。
- 通过这次比赛学到了很多代码调优小技巧,锻炼了解决问题的能力,同时也很幸运的拿到了华为的面试直通卡。今天要找实习,准备笔试面试,作比赛的时间很紧张,多亏有队友帮助,不然不可能取得这个成绩。如果明年研三有机会,明年的这个时候有offer了,一定全心全意的做一次比赛~~~