英飞凌 Tc3xx AURIX 2G多核处理器简介
目录
1、概述
2、AURIX 2G多核架构
2.1、多核简介
2.2、片上总线简介
3、AURIX 2G内核简介
3.1、内核架构
3.2、内核寄存器
3.3、中断处理
4、AURIX 2G内存简介
4.1、内存简介
4.2、内存映射
1、概述
该产品具备多达六核的高性能架构,每个内核的时钟频率最高可达 300 MHz,可实现更高速的计算能力;为了使开发者更便捷地切换,AURIXTM家族内不同代产品的硬件引脚兼容、软件指令兼容,同代产品在同封装下,可实现高、中、低端引脚90%以上相兼容,便于其功能和性能的扩展;在存储能力方面,该产品可达16 MB Flash,并具有A/B切换功能,可帮助车厂便捷地实现空中下载软件更新(SOTA);此外,AURIXTM 2G还完美结合了功能安全和信息安全,配备了多达4个锁步核,能满足集成的器件符合ISO 26262功能安全所要求的最高等级。其内置的硬件加密模块(HSM)可满足最高等级的EVITA标准,适用于驾驶辅助系统、自动驾驶功能等领域,是各类汽车软件应用的理想控制元件。
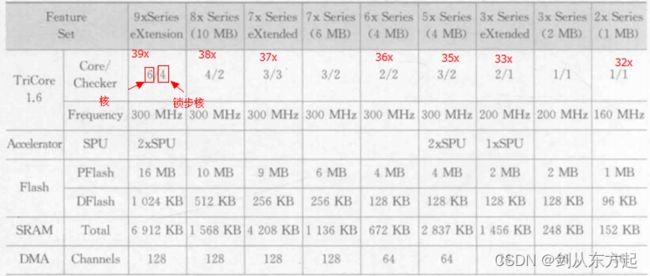
AURIX 2G家族单片机系列家族参数如下:
概念介绍:
- 同构多核架构:多个核运行同一操作系统的架构
- 同构锁步多核架构:在同构多核的基础上增加锁步核,锁步核与主核执行相同的指令,二者进行执行结果比较,对指令执行错误进行有效监控,从而获得较高的安全性能。
- 异构多核架构:运行不同操作系统的多核架构,由系统程序控制器(Hypervisor)协调不同操作系统在共享物理硬件上的工作。

2、AURIX 2G多核架构
2.1、多核简介
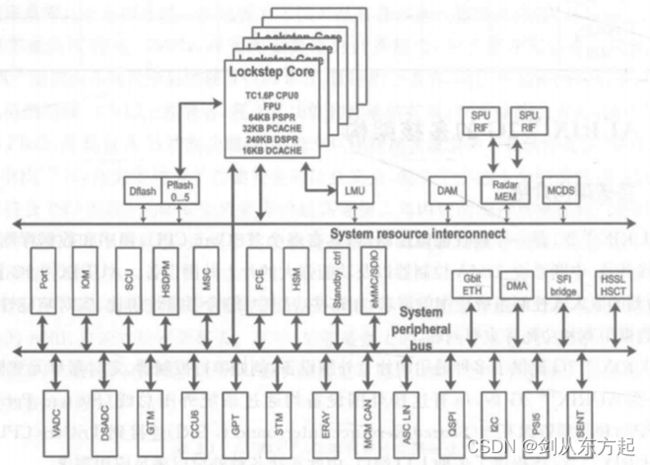
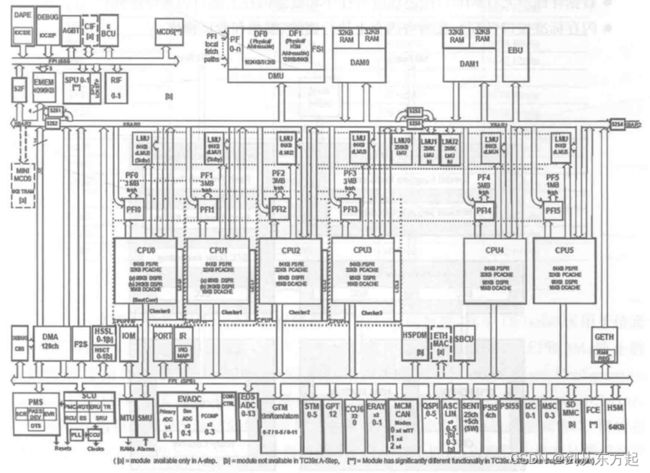
AURIXTM 2G 是一个高性能微控制器,具有多个TriCore CPU(如上图家族参数描述)、程序和数据存储器、总线、总线仲裁、中断系统、DMA控制器以及功能强大的片上外围设备。AURIXTM 2G旨在满足最苛刻的嵌入式控制系统应用的需求,在这些应用中,综合考量性价比、实时响应性、计算能力、数据带宽和功耗等重要问题。AURIXTM 2G 提供了多种通用的片上外围设备,例如串行控制器、定时器单元和模数转换器。在AURIXTM 2G内,所有这些外围设备均通过系统外围总线(System PeripheralBus,SPB)和共享资源互连(Shared Resource Interconnect,SRI)连接到 TriCore CPU 系统中。AURIXTM 2G 还提供了多种 I/O端口,由此连接各种外设以满足应用需求。
平台特点如下:
- 采用多核架构;
- 具有有效的内存组织:
- 指令和数据暂存,高速缓存和本地闪存库;
- 串行通信接口:
- 灵活的同步和异步模式;
- 多通道 DMA 控制器;
- 灵活的中断系统:
- 可配置的中断优先级和目标;
- 硬件安全模块;
10、灵活的 CRC 引擎;
11、高性能片上总线;
12、片上调试和仿真功能;
13、灵活的电源管理。
此外,AURIXTM 2G系列的某些产品还提供以下高级驾驶辅助系统功能:
1、摄像头界面;
2、雷达接口;
3、扩展内存;
4、ADAS 信号处理单元。
TC39x的多核架构如下
AURIXTM 2G 系列中部分型号具有 ED(EmulationDevice)芯片,如下图 所示的 TC39xED,ED 芯片的加持使得开发者对单片机运行的监测和仿真更精准。仿真芯片中既有未做变动产品芯片部分(SoC),也有仿真扩展芯片(Emulation ExtensionChip, EEC)部分,二者处于同一硅片上。ED 与相关的PD 具有相似的封装形式,可用于单个 PCB,以减少设计和制造上的开销。

2.2、片上总线简介
AURIXTM 2G系列单片机的片上通信使用Xbar(Cross Bar Interconnect)系统,基于SRI结构发展而来,具有以下三个独立的片上通信方式:
系统资源互连结构(SRI, System Resource Interconnect Fabric);
系统外设总线(SPB, System Peripheral Bus);
系统骨干总线(BBB,Back Bone Bus)。
SRI 结构将 TriCore CPUs、DMA 模块和其他高带宽请求者连接到高带宽存储器和其他资源,以进行指令提取和数据访问。SRI结构由一个或多个Crossbar组成,它可将一个SRI 域中的所有访问者(Agent)连接起来,承载着域中 SRI 主机和 SRI从机之间的数据交换的任务。这些Crossbar支持单次和突发的数据传输,如果有多个Crossbar,则它们通过S2s桥接器连接。SRI Crossbar 支持不同 SRI-Master 和 SRI-Slave代理之间的并行处理以及从SRI主机到SRI从机的流水线请求。
那些连接到同一 Crossbar 的 SRI 代理(主机、从机)构成一个 SRI域。下图 所示为TC39X-B芯片的X-BAR总线示意图,具有三个域,包含四个CPU的域0、两个CPU的域1以及具有ADAS和调试功能的ED域。S2S桥的特殊之处在于它们存在于两个域中,由于S2S 桥的存在,所有 SRI主机都可以直接寻址(访问)大多数SRI从机,不管主机和从机是否在同一SRI域上。S2S桥是单向的,因此需要在两个SRI域之间以相反的方向放置两个S2S桥来实现双向功能。它们透明地传输所有SRI事件类型(无须更改主标记或地址),旨在降低引入网桥连接后两个域之间传输的延迟。

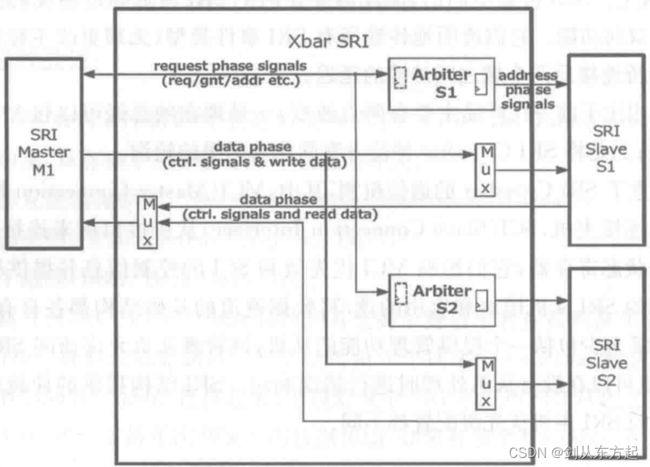
下图示意了SRI Crossbar的通信机制,其中,MCI(Master Connection Interface)表示主机接口用来连接主机,SCI(Slave Connection Interface)从机接口用来连接从机。SRI结构包含控制和状态寄存器,它们影响MCI优先级和SCI的控制信息并提供相关的错误消息。每个连接的 SRI从机模块和启用的读/写数据通道的基础结构都各自有一个仲裁器,SRI结构将始终至少包括一个提供管理功能的从机,该管理从机允许访问SRI结构控制和状态寄存器,也可以在没有从机处理时进行错误响应。SRI结构提供的仲裁功能允许每个SRI从机对应的SRI主机优先级配置都不同。
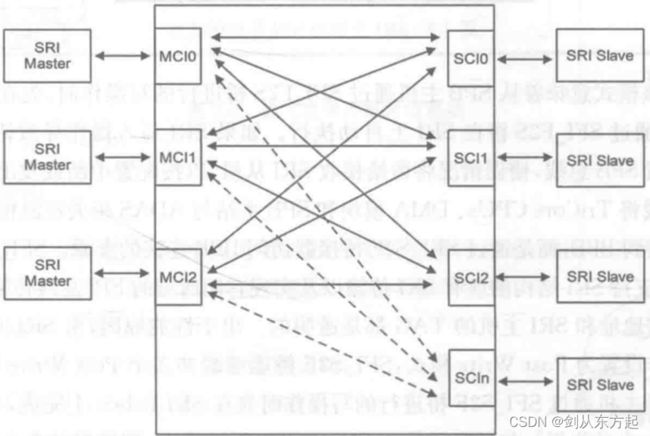
下图示例说明了一个SRI的主机可以同时连接不同的SRI从机,通过优先级和仲裁器进行控制。每个SCI都有一个关联的仲裁器,除了仲裁多个请求外,还可以进行错误捕获,在设备检测到的错误(某些错误由主机检测到)的情况下捕获事务信息,并通过中断路由器(INT)将状态通知系统,出于系统级诊断和安全考量,错误情况下的SRI错误ID和TransactionID 将被记录。
SPB 总线将中、低带宽外围设备连接到 TriCore CPUs、DMA 模块和其他 SPB 主机上。SPB 主机不会直接连接到SRI结构,而是将通过SFI_F2S 桥接器访问SRI相关的资源。SFI_F2S 桥以FPI协议总线为基础,实现了转发到SRI结构的单向总线桥,该桥支持SPB上的所有 FPI 传输以及实现它们所需的 SRI Fabric 传输,对于传输对象的地址和 SPB 主机的 TAG 都是透明的。出于性能原因,从 SPB 主机到 SRI 资源的写入操作将设置为 Post Write 模式,该模式意味着从 SPB 主机通过 SFI_F2S 桥进行的写操作时,先在 SPB 上完成,稍后,其结果通过SFI_F2S桥在SRI上自动执行。如果SRI写入操作导致错误,则错误信息不会传递回SPB总线,错误情况将留给接收SRI从机,以按配置中断或发出警报。
 3、AURIX 2G内核简介
3、AURIX 2G内核简介
如下图所示,英飞凌单片机从早期的单核 8 位经过产品迭代一直发展到目前的多核32 位,TriCore内核也从 1.2 版本发展到现在的 1.6E 和 1.6P 的版本。最新一代的AURIXTM 2G系列单片机也采用的是TriCore V1.6E和TriCore V1.6P的核心组合。随着TriCore版本的提升,其核心的制造工艺也从原先的250 nm提高到现在的65 nm精度,大大提升了运算能力,单核处理速度从原先的 80 MHz 提升到最新的 300 MHz。

3.1、内核架构
TriCore是32位微控制器,专门为实时嵌入式系统进行优化,如下图所示,在一个处理单元中结合了三项强大的技术,从而为嵌入式应用程序实现了更高水平的功率、速度和经济性:

精简指令集计算(RISC)处理器体系结构;
数字信号处理(DSP)结构及寻址模式;
具有片上存储器和外设的微控制器的实时功能。
AURIXTM 2G系列单片机使用的TC1.6.2P CPU是32位哈佛架构,将程序指令存储和数据存储分开。具有以下主要特点:
1、地址范围达到 4 GB(232),分为了 16 段,每一段 256 MB;
2、使用的 16 位和 32 位指令可减少代码大小,大多数指令能够在 1个周期内执行;
3、数据、内存以及 CPU 寄存器在单片机中是小端对齐方式;
4、具有多种寻址方式:绝对、循环、位反转、长十短、基十偏移量;
5、多种指令类型:算术、地址算术、比较、地址比较、逻辑、MAC、移位、协处理器、位逻辑等;
6、通用寄存器组(GPRS)包括 16 个 32 位数据寄存器、16 个 32 位地址寄存器以及 3 个32 位状态和程序计数器寄存器(PSW,PC,PCXI);
7、具有宽内存接口,用于快速上下文切换;调试支持(OCDS,On Chip Debug Support):Level 1 需要 CPS 模块支持,Level 3 则仅支持带有 ED 芯片的单片机;
8、灵活的内存保护系统(MPU):具有 18 个数据存储器保护范围及 10 个代码存储器保护范围,分为 6 组 。
下图示意了TC1.6.2P CPU 的内部存储的结构和连接,虽然2G 系列中TC1.6.2PCPU与上一代AURIXTM系列中使用的TC1.6P处理器拥有相同的核心处理硬件,但也做出了很大的改进和性能的提升:

1、LMU 存储器的一部分(称为 DLMU)分布在处理器之间,以提供对全局SRAM 的高性能访问;
2、PFlash 存储器分布在处理器之间,以提供对本地 PFlash 库(LPB)的高性能访问;
3、增强的内存保护:保护集数量增加到6个(原为4个)PSW,代码保护范围的数量增加到10(原为8),数据保护范围数增加到 18(原为16);
4、临时保护系统得到扩展,以提供专用的异常计时器;
5、实现了独立的内核重置,可以根据需要独立重置单个内核;
6、存储缓冲区数据合并功能得到扩展,可以将连续的半字合并为字,将连续的字合并为双字;
7、安全保护系统已扩展到涵盖对本地DSPR/PSPR和DLMU的读取和写入访问,以及对 LPB的读取访问;
8、CPUID已更改为0x00COC020。
下图所示为取指单元工作的流程。首先取指单元从64位宽的程序存储器接口(PMI)传入的指令进行预取指操作并对齐。指令在处理单元的 fifo 中按预测的程序顺序放置,处理单元 fifo最多缓冲6条指令,并将指令分发到不同的流水线中。指令保护单元检查是针对 PMI 的访问有效性以及从PMI提取的传入指令的完整性。分支单元检查提取的指令的分支条件,并根据先前的分支行为预测最可能的执行通道。程序计数器单元(PC)负责更新程序计数器。
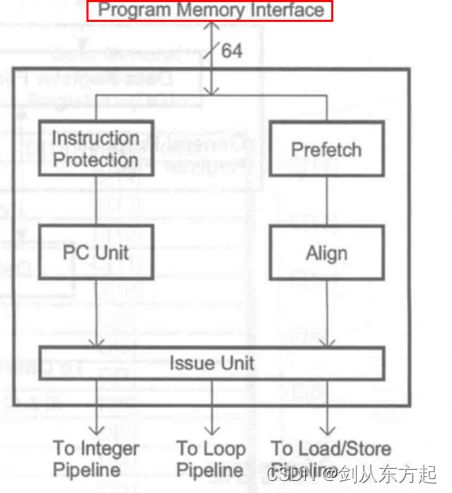
下图所示为CPU子系统中的执行单元流程。执行单元包含整数流水线、加载/存储流水线和循环流水线。三个流水线并行运行,允许在一个时钟周期内执行多达三条指令。在执行单元中,所有指令都要经过一个解码阶段,然后是执行与写回操作。通过在流水线之间使用转发路径,可以将流水线危害(停滞)降到最低,从而使一条指令的结果在结果可用时立即被下一条指令使用。

如下图所示,CPU 具有通用寄存器(GPR)文件,该文件分为地址寄存器文件(寄存器A0-A15)和数据寄存器文件(寄存器D0-D15)。通过地址寄存器文件控制发布到加载/存储流水线的指令的数据流,通过数据寄存器文件控制向整数流水线发出的指令或从整数流水线发出的指令以及向装载/存储流水线发出的数据加载/存储指令的数据流。

3.2、内核寄存器
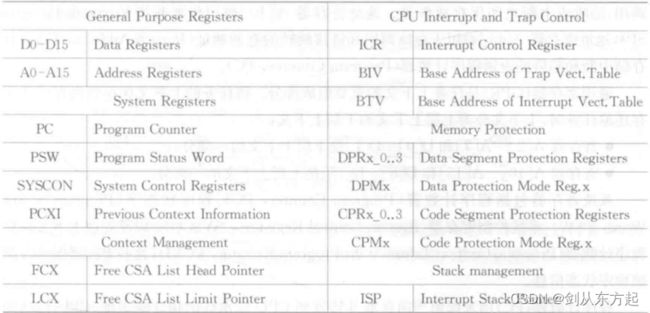
AURIXTM 2G 系列单片机的内核寄存器有通用寄存器(General Purpose Registers,GPR)和核心特殊功能寄存器(Core Special Function Registers, CSFR)两种类型。如下表所示,内核寄存器按功能可分为通用寄存器、系统寄存器、上下文管理寄存器、CPU中断与陷阱寄存器、内存保护寄存器以及堆栈管理寄存器几种类型。
通用寄存器(GPR)被均分为16个数据寄存器(DGPR)D[0]-D[15]以及16个地址寄存器(AGPRS) A[0]-A[15]。数据寄存器和地址寄存器的分离可以并行执行算术和存储器操作,使得指令执行更加高效。如图2.13所示,GPR也支持将2个连续的数据寄存器连接起来,从而使得16个数据寄存器形成8个扩展的寄存器E[0],E[2],E[4],E[6],E[8],E[10],E[12]和E[14],以支持64位值的存储。16个地址寄存器可以以相同的方式形成8个扩展的地址寄存器P[0],P[2],P[4],P[6],P[8],P[10],P[12]和P[14]。
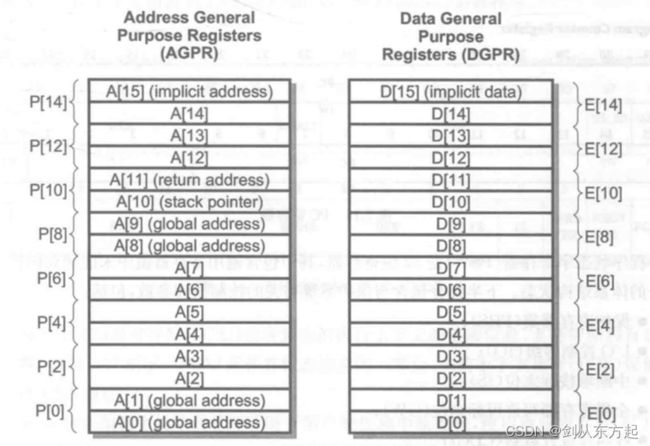
地址寄存器A[0], A[1], A[8]和A[9]被定义为系统全局寄存器,它们的内容不会在调用、陷阱或中断之间保存或恢复。地址寄存器A[10]被用作堆栈指针(Stack Pointer,SP),地址寄存器A[11]被用于存储调用和链接跳转的返回地址(Return Address, RA),并存储中断和陷阱的返回程序计数器(Program Counter,PC)。
通用寄存器(GPR)是任务上下文的重要组成部分。将任务的上下文保存到内存或从内存还原任务时,上下文分为上层上下文和下层上下文:
寄存器 A[2]—A[7]和 D[0]—D[7]是下层上下文的一部分;
寄存器 A[10]-A[15]和D[8]-D[15]是上层上下文的一部分。
系统寄存器包括程序计数器(Program Counter,PC)、程序状态字(Program StatusWord,PSW)、系统控制寄存器(System Control Registers,SYSCON)以及先前上下文信息程序计数器(Previous Context Information Program Counter, PCXI),这些寄存器保存并反映程序状态信息。
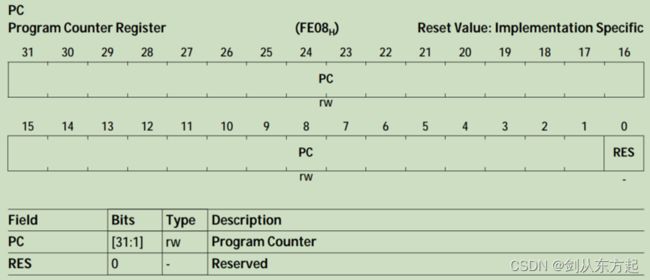
程序计数器(PC)用来保留当前获取并转发到CPU流水线的指令的地址,CPU自动处理 PC 指针的更新。任务在执行过程中通过软件可以获取 PC的当前值,可用于执行代码地址计算。通过 CPU 执行的软件读取 PC 只能使用 MFCR(move to core special functionregister)指令来完成,这样的读取将返回 PC 的 MFCR 指令本身。由于 CPU 可能发生意外行为,因此不得通过MTCR(move to core register)指令对PC 进行显式写入,仅当CPU暂停时才可以写入 PC。CPU 不得在内存段 15中对PC 的映射地址执行加载/存储指令,这将生成 MEM 陷阱。
32位程序计数器(PC)保存着当前正在运行的指令的地址。程序计数器是任务状态信息的一部分。PC应该只在内核停止时写入。如果核心没有处于半状态,则写操作将不起作用。
程序状态字寄存器(PSW)是一个32位寄存器,它包含在通用寄存器值中没有捕获的特定于任务的体系结构状态。下半部保存与保护系统相关的控制值和参数,包括:
保护寄存器集(PRS);
I/O控制等级(IO);
中断堆栈标志位(IS);
全局寄存器写许可标志位(GW);
呼叫深度计数器(CDC);
呼叫深度计数使能位(CDE)。

顾名思义,系统控制寄存器(SYSCON)即是控制系统状态,对各个子系统进行管理,其各个控制位如下图所示,可通过位操作方式设置该寄存器。系统配置寄存器提供以下功能:
使能或禁用临时保护系统;使能或禁用内存保护系统;设置中断处理程序中位 PSW.S 的初始状态;设置陷阱处理程序中位 PSW.S 的初始状态;控制 User-1 模式下对外围设备的访问;控制 User-1 模式对中断系统的使用;Boot 状态下系统保持和释放位控制;指示空闲上下文列表 FCD(Free Context List Depleted)是否耗尽。
 先前上下文信息寄存器(PCXI)包含到先前执行上下文的链接信息,支持中断和自动上下文切换,如图2.17 所示。PCXI是任务状态信息的一部分,先前上下文指针(PCX)保留先前任务的 CSA地址。Tricore 体系架构中的堆栈管理适用于用户堆栈和中断堆栈,使用地址寄存器A[10]、中断堆栈指针(Interrupt Stack Pointer, ISP)和PSW寄存器共同管理堆栈(图2.18)。
先前上下文信息寄存器(PCXI)包含到先前执行上下文的链接信息,支持中断和自动上下文切换,如图2.17 所示。PCXI是任务状态信息的一部分,先前上下文指针(PCX)保留先前任务的 CSA地址。Tricore 体系架构中的堆栈管理适用于用户堆栈和中断堆栈,使用地址寄存器A[10]、中断堆栈指针(Interrupt Stack Pointer, ISP)和PSW寄存器共同管理堆栈(图2.18)。

使用A[10]用作堆栈指针时,该寄存器的初始内容通常由实时操作系统设置,这允许将私有堆栈区分配给各个任务。使用ISP用作堆栈指针,可以防止中断服务例程(ISR)访问私有堆栈区域,并防止其干扰任务的上下文信息。在内核架构中,可以在ISP和专用的堆栈指针之间自动切换并用 PSW.IS 位指示哪个堆栈指针有效。当一个中断发生时,如果被中断的任务正在使用它的私有堆栈(PSW.IS=0),内容与中断任务的上层上下文一起保存,A[10](SP)与ISP的当前内容一起加载。当中断或陷阱发生时,如果中断的任务已经在使用中断堆栈(PSW.IS=1),则不执行A[10](SP)的预加载,中断服务例程(ISR)在中断离开的地方继续使用中断堆栈。通常,在初始化过程中初始化ISP一次,但是,根据应用程序的需要,也可以在执行过程中修改ISP。
3.3、中断处理
在 TriCore 体系架构中,允许有多个中断源包括片上外设以及外部中断事件产生中断请求,以打断中断服务提供者,通常为CPU或DMA通道。
每个中断源都有一个唯一的中断优先级编号,称为服务请求优先级编号(ServiceRequest Priority Number, SRPN)。收到来自中断源的中断请求后,中断控制单元(Interrupt Control Unit,ICU)使用 SRPN在多个并发中断请求之间确定优先级。获胜请求的SRPN与请求的触发一起作为待处理中断优先级编号(Pending Interrupt Priority Number, PIPN)提供给CPU, CPU通过将PIPN与它的当前CPU优先级编号(CCPN)进行比较来决定是否接受请求的中断。如果 CPU 决定接受所请求的中断,则它会以一个中断应答来响应,并返回所采用中断的优先级编号,随后,ICU将清除请求的中断源。
中断处理主要由以下两个CSFR控制:
ICR(Interrupt Control Register):中断控制寄存器;
BIV(Base Interrupt Vector Table Pointer):基本中断向量表指针。
如下图所示,ICR中可以保存当前CPU优先级编号(CCPN)、中断系统(IE)的启用/禁用位、待处理的中断优先级编号(PIPN)以及针对中断仲裁方案的控制位。

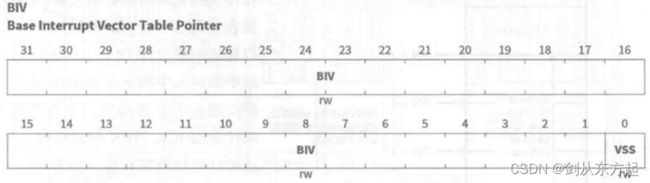
基址寄存器 BIV 存储中断向量表的基址,中断向量按照优先级递增的方式在中断向量表中排序(如下图)。在中断使能之前,系统初始化阶段中可以使用MTCR指令修改BIV寄存器。这样,就可以通过更改 BIV 寄存器的内容来在多个中断向量表之间进行切换。BIV寄存器中的 VSS 位用来设置两个中断向量之间的间隔,可以设置间隔为 32字节或者 8 字节。为了生成指向中断向量表的指针,PIPN左移五位(VSS=0)或三位(VSS=1),并与BIV 寄存器中的地址进行“或”运算以生成指向中断向量的指针表。
一般,中断产生时,CPU会立即响应,但是,在以下情况下,中断不能得到即时响应:
中断系统被全局禁用,中断控制寄存器的 IE 位置 0(ICR.IE=0)
当前的 CPU 优先级(CCPN)等于或高于“挂起中断优先级编号(PIPN)”;
CPU正在进入中断或陷阱服务程序;
CPU在运行不能被中断的陷阱服务;
CPU 正在执行多周期指令;
CPU正在执行的指令涉及修改 ICR 寄存器。
当上述情况都清除后,CPU 即可处理中断请求,通过一系列操作最终进入中断服务程序(ISR)。其详细过程如下:(首先保存当前任务的高级上下文已保存,将当前的PC值更新到返回地址寄存器A[11]用当前的PC更新。如果处理器之前未使用中断堆栈即PSW.IS=0,则将A[10]堆栈指针设置为中断堆栈指针(ISP)并同时将PSW.IS设置为1。将当前保护寄存器集设置为0,即PSW.PRS=000,并清除呼叫深度计数器 PSW.CDC,将呼叫限制设置为64,即PSW.CDC= 0000000,随后启用呼叫深度计数器。将PSW安全位PSW.S 设置为 SYSCON 寄存器中定义的 SYSCON.IS 位,关闭全局寄存器的写权限并关闭全局中断,随后把当前 CPU 优先级编号 ICR.CCPN 保存到先前的 CPU 优先级编号 PCXI.PCPN中,之后,将待处理的中断优先级编号 ICR. PIPN 被保存到当前 CPU 优先级编号ICR.CCPN中。最后进入中断向量表,取出ISR 的第一条指令并开始执行中断服务程序。)要注意的是,每当进入中断服务程序或陷阱处理程序时,全局寄存器写许可都是禁用的PSW.GW=0,这样可确保所有陷阱和中断在处理时不会对PSW.GW位控制的寄存器进行写操作。进入中断服务程序时,全局中断处于关闭状态,并且,当前 CPU 优先级CCPN被设置为要服务的中断的优先级PIPN,因此,由用户在中断服务程序中决定是否再次启用中断系统,并可以选择修改优先级编号CCPN以实现中断优先级或处理特殊情况。使能全局中断可以使用ENABLE 指令,即可将ICR.IE 设置为1, 开始中断服务程序(Begin Interrupt Service Routine,BISR)指令也可以使能中断系统,同时更新ICR.CCPN并保存被中断任务的下层的上下文。中断服务程序通过中断向量表与特定优先级的中断相关联,中断向量表是所有中断服务程序(ISR)入口地址的集合(如下图)。当CPU处理中断进入中断服务程序时,将在中断向量表中计算得出一个与当前中断优先级ICR.PIPN相对应的地址,该地址被加载到程序计数器 PC 中。CPU在中断向量表中的该地址处开始执行指令即该地址开始的代码是处理的中断服务程序ISR。由于ISR的代码量不确定,中断向量表仅仅存储中断服务程序 ISR 的初始部分,例如,使用跳转指令将CPU 引导至存储器中其他位置继续执行 ISR 的其余部分。当中断服务程序发出 RFE(异常返回)指令退出时,硬件会自动恢复其上层上下文,其中包括PCXI寄存器,该寄存器保存了先前的CPU优先级编号PCPN和先前的全局中断使能位PIE状态。把PCXI. PCPN写入ICR.CCPN, PCXIPIE写入ICR.IE,将CPU优先级值设置为中断前的值,随后回到被中断的程序中继续执行。

4、AURIX 2G内存简介
4.1、内存简介
下图所示为 AURIXTM 2G 单片机内存分布,这一代单片机采用的是哈佛(Harvard)架构,即将程序存储器空间和数据存储器空间分开,使得程序存储器和数据存储器各有自己的寻址方式、寻址空间和控制系统。AURIXTM 2G 系列单片机中的 Tricore 内核结构具有 32 位的寻址能力,将4GB的物理地址空间分为16个大小相等的256MB的段。这些段的编号为OH—FH,并由地址的高 4 位标识,不同的段空间可以被配置成具有不同的访问特性的内存空间。升级后的 AURIXTM 2G 系列单片机在内存系统设计相对复杂,采用了多种存储器和存储单元设计,并通过三种不同的总线进行数据交互,使得数据读写的速度和安全性得到了保证。相比于上一代AURIX单片机,本次的主要功能升级体现在内存接口和连接性上:PFlash 存储器分布在处理器之间,以提供对本地 PFlash 库的本地高性能、低延迟访问;LMU 存储器的一部分在处理器之间分布(DirectconnectedLocal Memory Unit, DLMU),以提供对全局SRAM部分的低延迟、高性能访问。
如下图所示为CPU的内存结构模型,对于Tricore架构中的CPU都提供相同的内存结构,其中包括64 KB的PSPR,32 KB 的程序缓存,96~240 KB 大小的 DSPR,16 KB 的数据缓存,64KB的本地DLMU以及一个由本地路径连接的高达3MB的PFlash其中,PFlash对应的内存全都映射到起始地址为80000000H(Cache方式访问)/A0000000H(Non-Cache方式访问)的连续地址空间,本地DLMU和全局的LMU映射到起始地址为90000000H的连续地址空间中。

如下图所示为PMU存储单元的结构,主要包括以下六个硬件部分:
数据存储单元(DMU):控制在所有程序和数据闪存上执行的命令序列;
闪存标准接口(FSI):在所有闪存上执行擦除、编程和验证操作;
程序闪存(PFlash):分为一个或多个存储区,每个存储区均连接到CPU;
程序闪存接口(PFI):将PFlash库与CPU进行点对点连接;
数据闪存(DFlash):分为DFO和DF1两个存储区;
Boot ROM(BROM):通过DMU SRI端口连接到系统,每次复位时都会执行启动软件(SSW)。

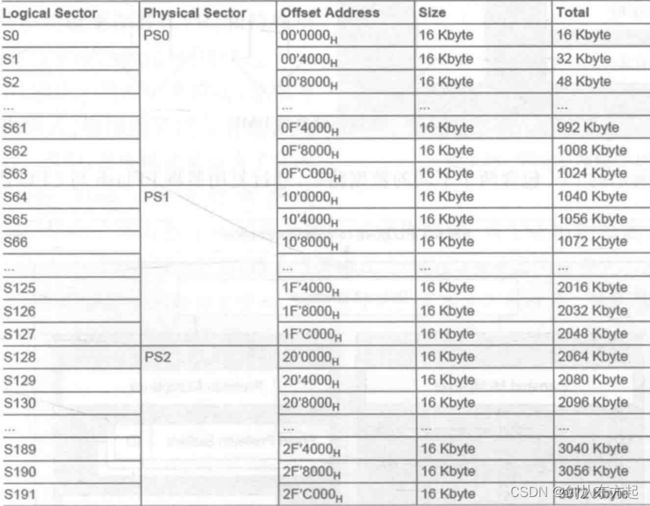
PMU 存储单元控制 PFlash 和 DFlash 两种 NVM 资源。PFlash 常用来存储程序代码和数据常量,读取时间低至 30 ns,每个扇区擦除时间最多为 1 s。所有程序闪存存储区PFlash 都基于相同的扇区结构,按照 PFlash 库的大小实现如图 2.25 所示的逻辑扇区结构。其中:
3 MB 程序闪存存储区包含逻辑扇区 S0—S191;
2 MB 程序闪存存储区包含逻辑扇区 S0—S127;
1 MB 程序闪存存储区包含逻辑扇区 S0—S63。
DFlash 常用来仿真 EEPROM,并存储程序在运行时的数据,其中DFlash0 区用于仿真用户程序的CPU-EEPROM, DFlashl区用于仿真有安全要求的HSM-EEPROM,防止数据被别的应用程序访问。DFlash中的多个用户配置块(Multiple User ConfigurationBlocks,USB)可用于实现基于密码的读保护与写保护。配置扇区(Configuration Sector,CFS)存储的数据是用户无法访问的系统配置数据。NVM 中存储的数据受到 ECC 校验和保护,对于程序闪存PFlash, ECC校验和的计算扩展到整个地址,以提供针对地址错误的读取保护。
4.2、内存映射
Tricore内核架构定义了可缓存内存(Cached memory)、非缓存内存(Non-cachedMemory)以及外设内存空间访问(Peripheral Space)三种不同的内存访问模式。其中针对缓存性,段空间内部的代码取址和数据访问可独立设置。如果使用Cache方式读取代码,则将提取到内存地址空间的代码缓存在CPU中并允许CPU对该内存执行推测性代码提取。同样使用Cache方式读取数据时将数据缓存到CPU并允许CPU进行推测性数据访问。反之,对于 Non-Cache 访问方式,则不会将数据或代码缓存到 CPU,也不允许 CPU进行推测性处理操作。对于外设内存空间的访问仅允许Supervisor以及User-1模式下进行,并且,访问使用Non-Cache模式,在User-0模式下访问外设内存空间将导致MPP陷阱。
在单片机内存系统中,物理地址空间每个段的数据访问的可缓存性由PMA(Programmable Memory Access)寄存器决定。PMA寄存器共有三个其硬件设置,使得段的可缓存性受到以下限制:
外设地址空间不能设置为可缓存;
本地 DSPR 的内容不能保存在本地数据缓存中;
本地PSPR的内容不能保存在本地程序缓存中。
内存可缓存性的默认设置
Tricore 内核将 4 GB 的内存分为 16 个 256 MB 的段空间,编号从 0H—FH,并由地址的高 4 位标识。下面以 TC39x 单片机为例,介绍各段的功能应用。
段0和段2:这两个内存段为功能保留,未作使用。
段1,段3-7:这六个内存段分别对应的是Tricore架构的六个核,其中段1(举例:0x1000 0000) 对应CPU5,段3对应CPU4,段4对应CPU3,段5对应CPU2,段6对应CPU1,段7对应CPU0。这些段空间允许访问 CPU 程序和数据暂存器 SRAM(PSPR,DSPR),程序和数据缓存SRAM(PCACHE, DCACHE)以及与程序和数据缓存相关的TAGSRAM(PTAG SRAM1, DTAG SRAM2)。
段 8:该内存段允许对 PFlash 和 BROM(Boot ROM)进行缓存访问。
段 9:该内存段允许对 LMU 和 EMEM 的缓存访问。
段10:该内存段允许对PFlash, DFlash 和 BROM 进行非缓存访问。
段11:该内存段允许对LMU和EMEM进行非缓存访问。
段12—14:这三个内存段为功能保留,未作使用。
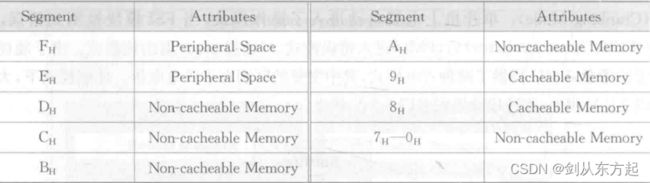
段 15:该段内存为外设空间,将256 MB分为两部分,其中较低的 128MB为SPB总线的寻址空间,较高的128 MB为SRI总线的寻址空间。
下图展示了段 15中的部分映射关系,该段作为外设使用的内存空间,一共有256 MB的空间,按照不同的外设将空间进行分类使用,基本能满足车载ECU外设的使用要求。
