nginx(二十六)ngx_http_headers_nodule模块
一 add_header指令
1) ngx_http_headers_nodule是'filter'模块
2)特点:nginx接收到完整的'后端响应内容后',才会对'HTTP 响应头'部做'加工'处理
3) 允许通过修改 nginx.conf 配置文件,在返回给用户的响应中'添加(add)'任意的 HTTP 头部
注意: 是无脑'add'的能力,而不是'modify修改'能力模块地址

1)有些'约定俗成响应头'是'浏览器能识别'的 -->"RFC文档中的通用头"
2) 有些'自定义'的响应头是通过'业务代码'来识别 -->"自定义标头"① 基本描述

细节点:
1) nginx配置中'子块[eg:location]'中的'add_header'会'覆盖'父块'[eg:server全局]'
2) 而'不是'继承
通俗: 每一层都可以从'上层继承' add_header;但是如果'当前层'添加了add_header,则是'覆盖'
+++++++++++++++++++ "分割线" +++++++++++++++++++
1) add_header 指令 --> nginx在给客户端响应'content'的时候'增加'的响应头
备注:'默认'当且仅当'上述所列'的部分'2xx和3xx'状态码时才有效
2) 如果提供了'第三个参数 always',那么'无论状态码'是多少,'都会'带上
备注: 即使是'404的错误页面'
3) 每一层都可以'从上层继承 'add_header,
备注: 但是如果'子层'也添加了add_header,则'覆盖'所有的'add_header'
+++++++++++++'不能继承header问题'+++++++++++++
1. 把外层的add_header'复制'一份写到内层
2. 当add_header指令用的'很多'时,可以'抽离成.conf文件',通过include进行引入

参考链接
② add_header丢失或失效
# 特点:坑比较多的指令,处理阶段比location晚;
# 如果写在location中,并且涉及rewrite其它location
# 那么'上一个location中'未被处理的add_header会丢失
location = /wzj1 {
add_header name1 18;
rewrite / /wzj2;
}
location = /wzj2 {
add_header name2 28;
return 204;
}
说明: 'name1'这个头'丢失'典型场景:try_files 指令导致 add_header 失效
失效根因: 相关指令'涉及内部internal重定向',导致add_header指令对应的阶段'未执行','丢失'③ always可选参数 对任意响应码都生效
应用场景1: add_header 在 '错误(4xx)'页面 使用
应用场景2: DELETE请求方法'返回202',导致add_header增加的响应头'丢失'
应用场景3: 实际工作中往往前端需要'捕获服务端异常响应',在nginx跨域add_header上加上always
备注3:跨域涉及'OPTIONS'预检请求的'204'状态码,add_header支持'该状态码'
深层次: 有些'服务'通过获取'特定'的Header来处理业务nginx跨域不生效
补获跨域错误
版本问题导致的报错
遗留:
1) add_header 后面的'always参数'可以用'变量'吗? --> "不可以"
2) add_header 的'Header'可以有'$'特殊符号,但是'nginx不会处理作为变量',而是'$字面字符'
3) add_header 的'header_value'可以使用'$var'变量
location /method {
if ( $request_method = 'DELETE' ){
set $flag "always";
}
add_header Always $flag;
}④ 响应头重复
建议:nginx中同一'level',不能有相同的'响应头'1)响应头重复的原因
1、请求'链路'比较长 eg --> 'waf --> APIG --> nginx -->后端服务'
说明:每一层都'添加'同一个响应头,多次'添加'导致;一定要了解'组网'形式
2、nginx自身'add_header '同一个头'多次'导致2)响应头重复的一些潜在问题
1)在'不同厂家'或者同一厂家'不同版本'的浏览器,对'重复'响应头的处理存在'差异',要具体分析
2)三种策略:将前面的'覆盖'、多个数值'合并'、'并存'
3)可能'引发'的问题
场景:可能导致设置的'响应头'防护'减弱'甚至'失效'
原因:某些响应头'只能识别特定'的参数
3)如何解决
'隐藏'上游的响应头,不要出现'响应头重复'的问题proxy_hide_header
4)最佳实践
1)多个部门进行'协调',只在所有'请求流'的'入口'处设置,例如nginx或者APIG
2)'业务代码层面'不再设置⑤ add_header不生效常见原因
1) '作用域'导致'add_header'被覆盖 --> "如何合理利用"
2) add_header响应头'重复',导致浏览器'错误'识别响应头
3) 部分'非2xx和3xx'状态码和'跨域'导致add_header'失效' --> 需要"always"参数
4) uri重写,涉及'nginx11个阶段'导致'add_hader'丢失
5) add_header 响应头的'Header'带'特殊字符[下划线等]'导致失效
6) 多个'location'路由匹配'客户端请求',正则的优先级导致'下面'location中add_header未生效⑥ 添加安全响应头
涉及的安全响应头
Strict-Transport-Security HSTS
X-Content-Type-Options
X-Download-Options
X-Frame-Options 其它参考
X-XSS-Protection
Content-Security-Policy
# 禁用浏览器的类型猜测
add_header X-Content-Type-Options "nosniff";
# 兼容一些老的浏览器
add_header X-Download-Options "noopen";
# XSS防护的
add_header X-XSS-Protection "1; mode=block";
# 告诉浏览器强制https请求 1年 --> 365天
add_header Strict-Transport-Security "max-age=31536000;includeSubDomains";
# 消减点击劫持
add_header X-Frame-Options "DENY";黑客工具之AppScan详细使用教程
⑦ default_type

+++++++++++ "nginx设置" +++++++++++
1) default_type application/octet-stream; # 默认的'Content-Type'
特点: 如果根据'文件后缀'不能判定'content-type'的资源类型,则返回'默认的default_type'
2) charset utf-8; # 避免'乱码'
解读:
1) nginx在返回'资源类型'的时候,首先根据'文件名后缀'找'mime.types'文件
2) 找不到则'返回'default_type + charset
3) 对应'浏览器'响应头:Content-Type 'application/octet-stream; charset=utf-8';
+++++++++++ '分割线' +++++++++++
add_header Content-Type "application/octet-stream; charset=utf-8";
和上述方式的'区别':default_type 、charset 可以在'子域'定义add_header,不会被覆盖⑧ add_header用在debug阶段
背景:
1) ngin作为'反向代理的时候',后端有'很多节点'
2) 为了让'开发'知道请求落在'哪个'后端节点上,便于'快速'排查
3) 前提: 非'线上的生产环境'、并且没有统一的'日志'查看平台
+++++++++++++++++ "具体的实施" +++++++++++++++++
add_header BACK_IP $upstream_addr;
add_header BACK_CODE $upstream_status⑨ add_header防止重复响应头的另一种做法
思考: nginx能'隐藏'上游的多个'相同的响应头'吗?
前提: 客户端'浏览器'有'两个'响应头
+++++++++ "具体实施" +++++++++
map $upstream_http_cache_control $cache_control {
default "";
"" "no-store";
}
# 后端'没有返回'对应的响应头,则nginx自身'添加'默认值
add_header Cache-Control $cache_control always
'暗含'的知识点:
1) map中只有'变量'被使用的时候,才会执行'map'
2) map作用一个完整'请求-响应'整个'生命'周期
3) add_header指令'后于'$upstream_http_name变量执行 ->
保证:add_header执行的时候'$upstream_http_name'不为空
# 进一步"补充"思考: if($upstream_http_name) { 先隐藏上游,再添加自定义头的值} 保证唯一⑩ 利用不同作用域add_header覆盖的特点进行缓存时效控制
需求场景:
1) 默认'全局'不使用'缓存' --> 'http|server级别颗粒度'
2) location /video/special --> nginx'控制'缓存时间
3) location /wzj --> 后端'控制'缓存时间
注意: location和if in location中的'add_header'是属于'同一层级'的
思路: 把公共的'add_header'部分'抽离'出来放到'add_header.conf'中
二 expires指令
① 基本描述
说明: 这个响应头'控制'浏览器的'访问'行为,控制'页面资源'在'浏览器缓存'的时间
② 与map结合

③ 前置知识
1)浏览器在磁盘存放缓存的位置
'自己linux': /home/kiosk/.config/google-chrome/Default/Application Cache/Cache
原理参考
++++++++++"浏览器的缓存策略"++++++++++
说明: Etag的'优先级'比Last-Modified高
细节:
1) 判断该资源'在浏览器'是否有'上一次缓存'的Etag、Last-Modified
2) 如果'有'根据'优先级别'填充'对应的请求头'中
304: 浏览器可以使用'本地的过期缓存'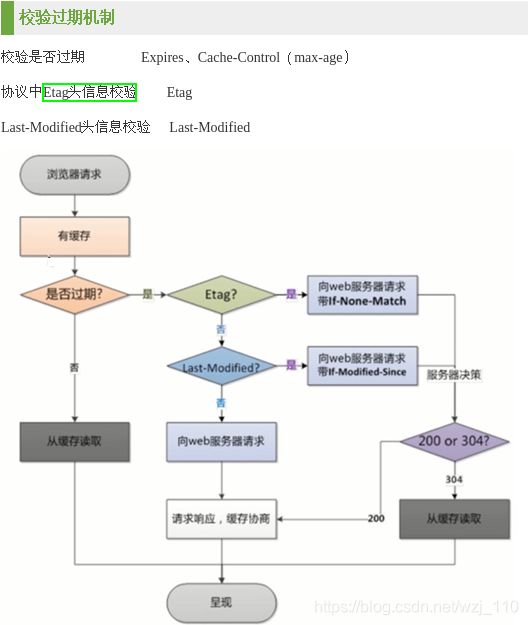
1)Etag响应头

2)Last-Modified 响应头
Last-Modified的属性标记'此文件'在服务器端'最后被修改'的时间3)IF-Modified-Since 请求头

4)IF-None-Match请求头

5)强制浏览器访问不使用本地缓存

说明: 用'chrome'演示浏览器携带'请求头' -->相当于'ctrl+f5'快捷键
备注:
1) HTTP/1.0 caches协议'没有'实现'Cache-Control [在http1.1实现]'
2) HTTP/1.0'实现'了 Pragma: no-cache的功能
HTTP请求头和响应头中cache-control的区别
F5和CTRL+F5两种刷新的区别
④ nginx决策浏览器过期缓存是否有效
nginx服务端: 会计算(使用cpu)'资源的Etag',与请求头的'做比较'1)etag


etag用java解析成可读的案例
2)if_modified_since


nginx 通过 expires、etag、if_modified_since 指令实现对客户端缓存的控制
强缓存和协商缓存、Last-Modified和ETag响应头、If-None-Match和If-Modified-Since请求头
3)not_modified过滤模块原理图
[1]、If-Match
基于: 填充'Etag'
[2]、If-Unmodified-SInce
说明: 基于资源的'修改'时间,填充'Last-Modified'响应头的值
[3]、原理

[4]、curl模拟发送请求
关注点: 'nginx'如何处理这些'请求头'
演示:
1) 浏览器拿着'过期缓存'的请求访问nginx,nginx'依据'哪些指令和头部的比较过程
2) 决定给浏览器返回'304'、'200'、'412'
⑤ expires案例讲解
体会: 设置不同的'expires'指令,返回给'客户端的响应头',进而'如何控制'浏览器的访问行为
nginx决策'浏览器过期缓存'是否有效
观察: 'expires'不同的取值,'响应头'的一些现象
演示:
1) nginx作为web'静态'服务器
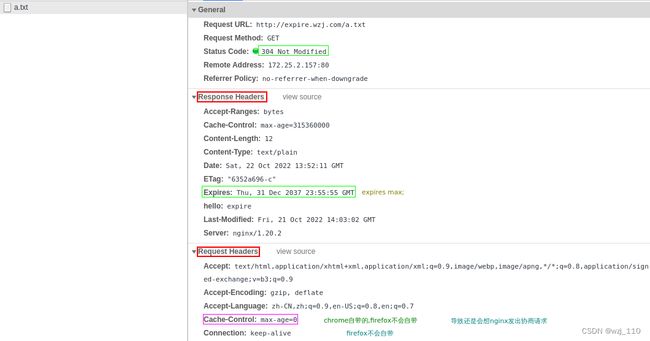
2) 通过'expires'告诉浏览器'资源(缓存)'的过期时间 -->nginx'控制'浏览器去使用缓存1)expire 10m

思考:为什么设置的是'10m'后过期,但是在'缓存有效期'访问总是304,而'不是'200(from cache)
可能原因:
1)chrome'浏览器'行为
请求头自带: 'Cache-Control: max-age=0'
备注:跟'浏览器的厂商'和'浏览器的版本'都有关
2)因为'Expires'使用的是绝对日期,如果服务端和客户端'时钟不同步'的话原因
2)expires max
3)expires -1

4)expires epoch

5)expires @23h10m

三 add_trailer
① 基本描述
解读: 为将自定义的'特殊头信息'添加到'body之后'
② Transfer-Encoding TE
说明: 最新的 'HTTP 规范'里,只定义了一种'传输编码' -->'分块编码[chunked]'
补充: '响应头'1)背景
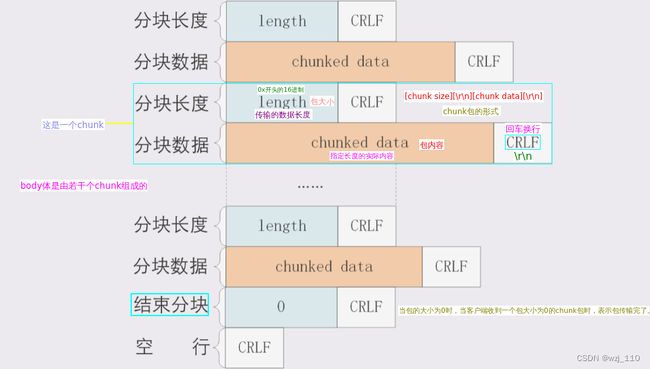
++++++++++ "为什么要使用分块传输" ++++++++++
1)有时候,web服务器生成'动态'HTTP Response是'无法'在'Header(Content-length)'就确定'消息大小'的
2) 服务端通过在响应头设置'Transfer-Encoding: chunked',表示Content Body将用'Chunked编码'传输内容
场景: 而对于'动态的内容'或者在'发送数据前不能判定长度'的情况下,可以使用'分块的方法'来传送编码
补充: 也可以传输'大'文件2)分块传输原理
3)nginx使用chunk传输前提
1) 分块传输是'HTTP1.1'引入的,利用'TCP的连接'复用,'多次'传输,使用HTTP1.1'长连接'
+++++++++++++"(1)nginx配置长连接"+++++++++++++
proxy_http_version 1.1; # 默认http版本为1.0
proxy_set_header Connection ""; # 置空串后,相当于不传递Connection,HTTP1.1默认就是'keep-alive'
+++++++++++++"(2)nginx支持chunk传输"+++++++++++++
chunked_transfer_encoding on # 默认就是'开启的'chunked_transfer_encoding

③ Trailer概念

强调:
1) Trailer生效是'依赖'于分块传输
2) 必须'显示'的设置响应头"Transfer-Encoding: chunked"1)Vertx创建HTTP Server服务
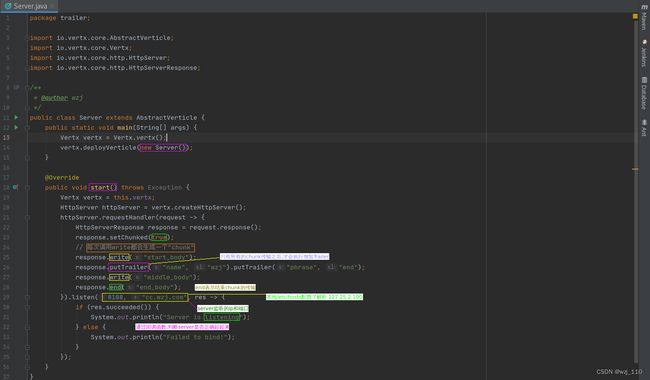
![]()
2)nginx作为代理的配置

3)客户端访问并抓包
说明: 客户端也是'172.25.2.157'
抓包命令: tcpdump -n -X -i any port 80 -w /tmp/chunk.cap![]()
思考: 为什么'原始的trailer'会丢失?
备注: 当'不设置add_trailer',在客户端没有获取到原始传递的'trailer'
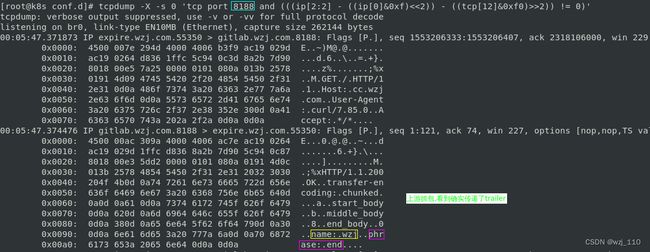
++++++++++++'url'++++++++++++
1) $uri和$document_uri标识'解码后'的请求路径,'不含'查询参数-->可能有'CRCF'攻击
2) $request_uri标识完整的'没有被解码'的url
--> "不带主机名",带参数 [/a/b.html?arg=10]-->"推荐"
补充:$query_string 与$args'相同'nginx非root用户启动