mongodb高级聚合查询
在工作中会经常遇到一些mongodb的聚合操作,特此总结下。mongo存储的可以是复杂类型,比如数组、对象等mysql不善于处理的文档型结构,并且聚合的操作也比mysql复杂很多。
注:本文基于 mongodb v3.6
目录
- mongo与mysql聚合类比
- aggregate简介
- aggregate语法
- aggregate常用pipeline stage介绍(本文核心)
- node操作mongo聚合查询(本文核心)
mongo与mysql聚合类比
为了便于理解,先将常见的mongo的聚合操作和mysql的查询做下类比:
| SQL 操作/函数 | mongodb聚合操作 |
| where | $match |
| group by | $group |
| having | $match |
| select | $project |
| order by | $sort |
| limit | $limit |
| sum() | $sum |
| count() | $sum |
| join | $lookup (v3.2 新增) |
下面举了一些常用的mongo聚合例子和mysql对比,假设有一条如下的数据库记录(表名:orders)作为例子:

{
cust_id: "abc123",
ord_date: ISODate("2012-11-02T17:04:11.102Z"),
status: 'A',
price: 50,
items: [ { sku: "xxx", qty: 25, price: 1 },
{ sku: "yyy", qty: 25, price: 1 } ]
}
1. 统计orders表所有记录
db.orders.aggregate( [
{
$group: {
_id: null,
count: { $sum: 1 }
}
}
] )
类似mysql:
SELECT COUNT(*) AS count FROM orders
2.对orders表计算所有price求和
db.orders.aggregate( [
{
$group: {
_id: null,
total: { $sum: "$price" }
}
}
] )
类似mysql;
SELECT SUM(price) AS total FROM orders
3.对每一个唯一的cust_id, 计算price总和
db.orders.aggregate( [
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
}
] )
类似mysql:
SELECT cust_id,
SUM(price) AS total
FROM orders
GROUP BY cust_id
4.对每一个唯一对cust_id和ord_date分组,计算price总和,不包括日期的时间部分
db.orders.aggregate( [
{
$group: {
_id: {
cust_id: "$cust_id",
ord_date: {
month: { $month: "$ord_date" },
day: { $dayOfMonth: "$ord_date" },
year: { $year: "$ord_date"}
}
},
total: { $sum: "$price" }
}
}
] )
类似mysql:
SELECT cust_id,
ord_date,
SUM(price) AS total
FROM orders
GROUP BY cust_id,
ord_date
5.对于有多个记录的cust_id,返回cust_id和对应的数量
db.orders.aggregate( [
{
$group: {
_id: "$cust_id",
count: { $sum: 1 }
}
},
{ $match: { count: { $gt: 1 } } }
] )
类似mysql:
SELECT cust_id,
count(*)
FROM orders
GROUP BY cust_id
HAVING count(*) > 1
6.对每个唯一的cust_id和ord_date分组,计算价格总和,并只返回price总和大于250的记录,且排除日期的时间部分
db.orders.aggregate( [
{
$group: {
_id: {
cust_id: "$cust_id",
ord_date: {
month: { $month: "$ord_date" },
day: { $dayOfMonth: "$ord_date" },
year: { $year: "$ord_date"}
}
},
total: { $sum: "$price" }
}
},
{ $match: { total: { $gt: 250 } } }
] )
类似mysql:
SELECT cust_id,
ord_date,
SUM(price) AS total
FROM orders
GROUP BY cust_id,
ord_date
HAVING total > 250
7.对每个唯一的cust_id且status=A,计算price总和
db.orders.aggregate( [
{ $match: { status: 'A' } },
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
}
] )
类似mysql:
SELECT cust_id,
SUM(price) as total
FROM orders
WHERE status = 'A'
GROUP BY cust_id
8.对每个唯一的cust_id且status=A,计算price总和并且只返回price总和大于250的记录
db.orders.aggregate( [
{ $match: { status: 'A' } },
{
$group: {
_id: "$cust_id",
total: { $sum: "$price" }
}
},
{ $match: { total: { $gt: 250 } } }
] )
类似mysql:
SELECT cust_id,
SUM(price) as total
FROM orders
WHERE status = 'A'
GROUP BY cust_id
HAVING total > 250
9.对于每个唯一的cust_id,将与orders相关联的相应订单项order_lineitem的qty字段进行总计
db.orders.aggregate( [
{ $unwind: "$items" },
{
$group: {
_id: "$cust_id",
qty: { $sum: "$items.qty" }
}
}
] )
类似mysql:
SELECT cust_id,
SUM(li.qty) as qty
FROM orders o,
order_lineitem li
WHERE li.order_id = o.id
GROUP BY cust_id
10.统计不同cust_id和ord_date分组的数量,排除日期的时间部分
db.orders.aggregate( [
{
$group: {
_id: {
cust_id: "$cust_id",
ord_date: {
month: { $month: "$ord_date" },
day: { $dayOfMonth: "$ord_date" },
year: { $year: "$ord_date"}
}
}
}
},
{
$group: {
_id: null,
count: { $sum: 1 }
}
}
] )
类似mysql:
SELECT COUNT(*)
FROM (SELECT cust_id, ord_date
FROM orders
GROUP BY cust_id, ord_date)
as DerivedTable
Aggregate简介
db.collection.aggregate()是基于数据处理的聚合管道,每个文档通过一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的结果。
通过这张图,可以了解Aggregate处理的过程。
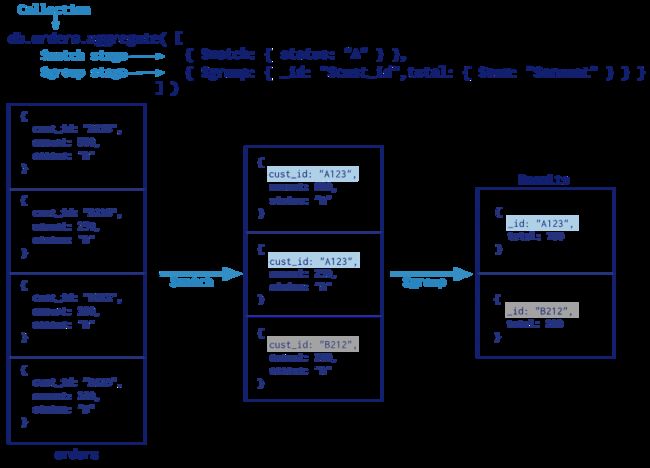
1、db.collection.aggregate() 可以用多个构件创建一个管道,对于一连串的文档进行处理。这些构件包括:筛选操作的match、映射操作的project、分组操作的group、排序操作的sort、限制操作的limit、和跳过操作的skip。
2、db.collection.aggregate()使用了MongoDB内置的原生操作,聚合效率非常高,支持类似于SQL Group By操作的功能,而不再需要用户编写自定义的JavaScript例程。
3、 每个阶段管道限制为100MB的内存。如果一个节点管道超过这个极限,MongoDB将产生一个错误。为了能够在处理大型数据集,可以设置allowDiskUse为true来在聚合管道节点把数据写入临时文件。这样就可以解决100MB的内存的限制。
4、db.collection.aggregate()可以作用在分片集合,但结果不能输在分片集合,MapReduce可以 作用在分片集合,结果也可以输在分片集合。
5、db.collection.aggregate()方法可以返回一个指针(cursor),数据放在内存中,直接操作。跟Mongo shell 一样指针操作。
6、db.collection.aggregate()输出的结果只能保存在一个文档中,BSON Document大小限制为16M。可以通过返回指针解决,版本2.6中后面:DB.collect.aggregate()方法返回一个指针,可以返回任何结果集的大小。
Aggregate语法
基本格式:
db.collection.aggregate(pipeline, options)参数说明:
| 参数 | 类型 | 描述 |
| pipeline | array | 一系列数据聚合操作或阶段。详见聚合管道操作符 |
| options | document | 可选。 aggregate()传递给聚合命令的其他选项。 |
注意:
使用db.collection.aggregate()直接查询会提示错误,但是传一个空数组如db.collection.aggregate([])则不会报错,且会和find一样返回所有文档。
pipeline有很多stage,但这里我只记录我经常用到的几个,如果后续用到再补充。stage详见官网。
接下来介绍这几个常用的stage:
$count , $group, $match, $project, $unwind, $limit, $skip, $sort, $sortByCount, $lookup, $out, $addFields
aggregate常用pipeline stage介绍
$count
释义:
返回包含输入到stage的文档的计数,理解为返回与表或视图的find()查询匹配的文档的计数。
db.collection.count()方法不执行find()操作,而是计数并返回与查询匹配的结果数。
语法:
{ $count: } $count阶段相当于下面$group+$project的序列:
db.collection.aggregate( [
{ $group: { _id: null, myCount: { $sum: 1 } } }, #这里myCount自定义,相当于mysql的select count(*) as myCount
{ $project: { _id: 0 } } # 返回不显示_id字段
] )举例:
示例数据:
{ "_id" : 1, "subject" : "History", "score" : 88 }
{ "_id" : 2, "subject" : "History", "score" : 92 }
{ "_id" : 3, "subject" : "History", "score" : 97 }
{ "_id" : 4, "subject" : "History", "score" : 71 }
{ "_id" : 5, "subject" : "History", "score" : 79 }
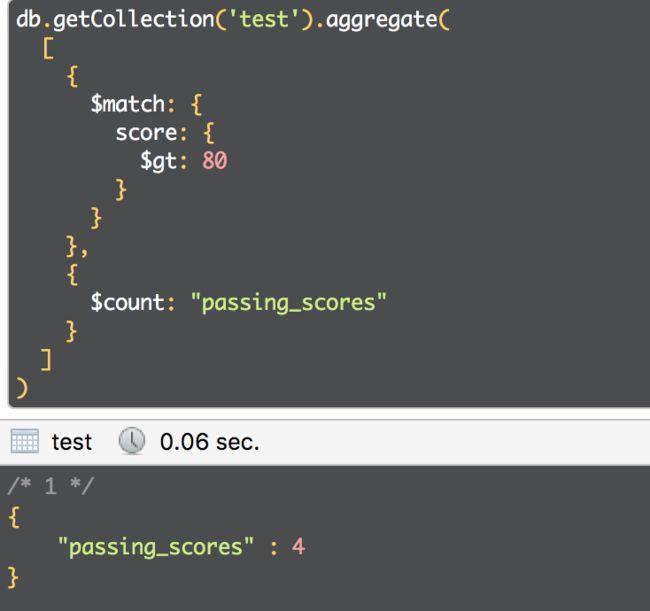
{ "_id" : 6, "subject" : "History", "score" : 83 }执行:
1)$match 阶段排除score小于等于80的文档,将大于80的文档传到下个阶段
2)$count阶段返回聚合管道中剩余文档的计数,并将该值分配给名为passing_scores的字段。
执行结果:
$group
释义:
按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个_id字段,该字段按键包含不同的组。
输出文档还可以包含计算字段,该字段保存由$group的_id字段分组的一些accumulator表达式的值。 $group不会输出具体的文档而只是统计信息。
语法:
{ $group: { _id: , : { : }, ... } } - _id字段是必填的;但是,可以指定_id值为null来为整个输入文档计算累计值。
- 剩余的计算字段是可选的,并使用
运算符进行计算。 - _id和
表达式可以接受任何有效的表达式。
accumulator操作符
| 名称 | 描述 | 类比sql |
| $avg | 计算均值 | avg |
| $first | 返回每组第一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的第一个文档。 | limit 0,1 |
| $last | 返回每组最后一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的最后个文档。 | - |
| $max | 根据分组,获取集合中所有文档对应值得最大值。 | max |
| $min | 根据分组,获取集合中所有文档对应值得最小值。 | min |
| $push | 将指定的表达式的值添加到一个数组中。 | - |
| $addToSet | 将表达式的值添加到一个集合中(无重复值,无序)。 | - |
| $sum | 计算总和 | sum |
| $stdDevPop | 返回输入值的总体标准偏差(population standard deviation) | - |
| $stdDevSamp | 返回输入值的样本标准偏差(the sample standard deviation) | - |
$group阶段的内存限制为100M。默认情况下,如果stage超过此限制,$group将产生错误。但是,要允许处理大型数据集,请将allowDiskUse选项设置为true以启用$group操作以写入临时文件。
友情备注:
- "$addToSet":expr,如果当前数组中不包含expr,那就将它添加到数组中。
- "$push":expr,不管expr是什么只,都将它添加到数组中。返回包含所有值的数组。
在版本2.6中进行了更改:对于$group阶段,MongoDB引入了100M内存的限制以及allowDiskUse选项来处理大数据集的操作。
举例:
示例数据:
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-03-01T08:00:00Z") }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-03-01T09:00:00Z") }
{ "_id" : 3, "item" : "xyz", "price" : 5, "quantity" : 10, "date" : ISODate("2014-03-15T09:00:00Z") }
{ "_id" : 4, "item" : "xyz", "price" : 5, "quantity" : 20, "date" : ISODate("2014-04-04T11:21:39.736Z") }
{ "_id" : 5, "item" : "abc", "price" : 10, "quantity" : 10, "date" : ISODate("2014-04-04T21:23:13.331Z") }
1. 以下汇总操作使用$group阶段按月份,日期和年份对文档进行分组,并计算total price和average quantity,并计算每个组的文档数量:
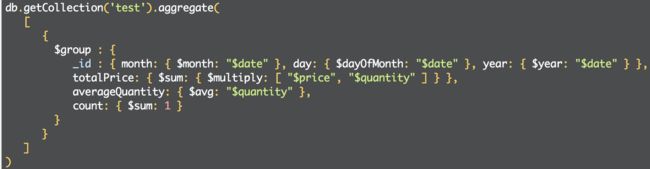
返回:
/* 1 */
{
"_id" : {
"month" : 4,
"day" : 4,
"year" : 2014
},
"totalPrice" : 200,
"averageQuantity" : 15.0,
"count" : 2.0
}
/* 2 */
{
"_id" : {
"month" : 3,
"day" : 15,
"year" : 2014
},
"totalPrice" : 50,
"averageQuantity" : 10.0,
"count" : 1.0
}
/* 3 */
{
"_id" : {
"month" : 3,
"day" : 1,
"year" : 2014
},
"totalPrice" : 40,
"averageQuantity" : 1.5,
"count" : 2.0
}
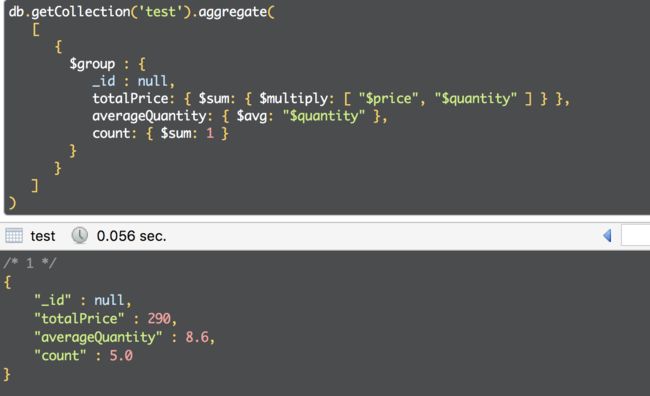
2. group null , 以下聚合操作将指定组_id为null,计算集合中所有文档的总价格和平均数量以及计数:
3. 查询distinct values
以下汇总操作使用$group阶段按item对文档进行分组以检索不同的项目值:
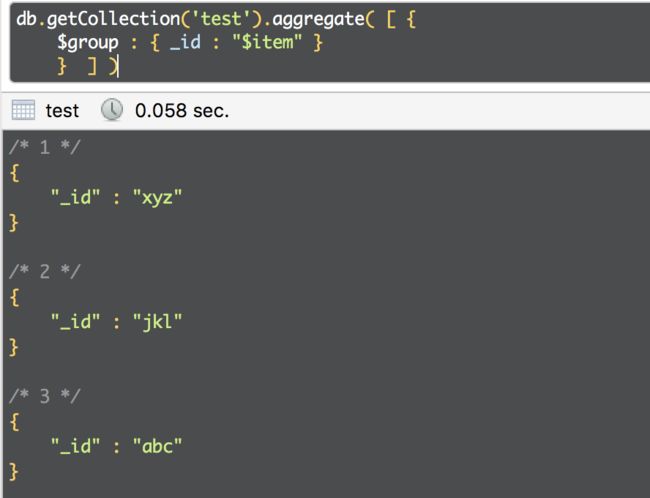
4. 数据转换
1)将集合中的数据按price分组转换成item数组
返回的数据id值是group中指定的字段,items可以自定义,是分组后的列表
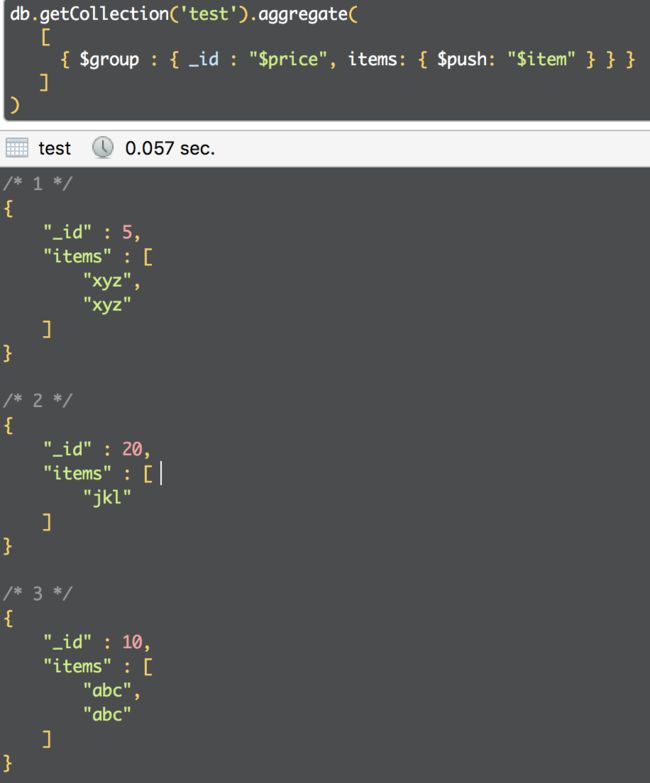
2)下面聚合操作实用系统变量$$ROOT按item对文档进行分组,生成的文档不得超过BSON文档大小限制。

返回:
/* 1 */
{
"_id" : "xyz",
"books" : [
{
"_id" : 3,
"item" : "xyz",
"price" : 5,
"quantity" : 10,
"date" : ISODate("2014-03-15T09:00:00.000Z")
},
{
"_id" : 4,
"item" : "xyz",
"price" : 5,
"quantity" : 20,
"date" : ISODate("2014-04-04T11:21:39.736Z")
}
]
}
/* 2 */
{
"_id" : "jkl",
"books" : [
{
"_id" : 2,
"item" : "jkl",
"price" : 20,
"quantity" : 1,
"date" : ISODate("2014-03-01T09:00:00.000Z")
}
]
}
/* 3 */
{
"_id" : "abc",
"books" : [
{
"_id" : 1,
"item" : "abc",
"price" : 10,
"quantity" : 2,
"date" : ISODate("2014-03-01T08:00:00.000Z")
},
{
"_id" : 5,
"item" : "abc",
"price" : 10,
"quantity" : 10,
"date" : ISODate("2014-04-04T21:23:13.331Z")
}
]
}
$match
释义:
过滤文档,仅将符合指定条件的文档传递到下一个管道阶段。
$match接受一个指定查询条件的文档。查询语法与读操作查询语法相同。
语法:
{ $match: { } } 管道优化:
$match用于对文档进行筛选,之后可以在得到的文档子集上做聚合,$match可以使用除了地理空间之外的所有常规查询操作符,在实际应用中尽可能将$match放在管道的前面位置。这样有两个好处:一是可以快速将不需要的文档过滤掉,以减少管道的工作量;二是如果再投射和分组之前执行$match,查询可以使用索引。
限制:
- 不能在$ match查询中使用$作为聚合管道的一部分。
- 要在$match阶段使用$text,$match阶段必须是管道的第一阶段。
- 视图不支持文本搜索。
举例:
示例数据:
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("512bc962e835e68f199c8687"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b258"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b259"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25a"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("55f5a1d3d4bede9ac365b25b"), "author" : "ty", "score" : 95, "views" : 1000 }
1.使用 $match做简单的匹配查询
返回:
/* 1 */
{
"_id" : ObjectId("512bc95fe835e68f199c8686"),
"author" : "dave",
"score" : 80,
"views" : 100
}
/* 2 */
{
"_id" : ObjectId("512bc962e835e68f199c8687"),
"author" : "dave",
"score" : 85,
"views" : 521
}
2. 使用$match管道选择要处理的文档,然后将结果输出到$group管道以计算文档的计数:

返回:
/* 1 */
{
"_id" : null,
"count" : 5.0
}$unwind
释义:
从输入文档解构数组字段以输出每个元素的文档。简单说就是 可以将数组拆分为单独的文档。
语法:
{ $unwind: } 要指定字段路径,在字段名称前加上$符并用引号括起来。
v3.2+支持如下语法:
{
$unwind:
{
path: ,
includeArrayIndex: , #可选,一个新字段的名称用于存放元素的数组索引。该名称不能以$开头。 preserveNullAndEmptyArrays: #可选,default :false,若为true,如果路径为空,缺少或为空数组,则$unwind输出文档 }
}
如果为输入文档中不存在的字段指定路径,或者该字段为空数组,则$unwind默认会忽略输入文档,并且不会输出该输入文档的文档。
版本3.2中的新功能:要输出数组字段丢失的文档,null或空数组,请使用选项preserveNullAndEmptyArrays。
举例:
1. 示例数据1:
{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }以下聚合使用$unwind为sizes数组中的每个元素输出一个文档:
db.getCollection('test').aggregate(
[ { $unwind : "$sizes" } ]
)
返回:
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
每个文档与输入文档相同,除了sizes字段的值是原始sizes数组的值。
2. 再如下示例数据:
{ "_id" : 1, "item" : "ABC", "sizes": [ "S", "M", "L"] }
{ "_id" : 2, "item" : "EFG", "sizes" : [ ] }
{ "_id" : 3, "item" : "IJK", "sizes": "M" }
{ "_id" : 4, "item" : "LMN" }
{ "_id" : 5, "item" : "XYZ", "sizes" : null }1)以下$unwind操作使用includeArrayIndex选项来输出数组元素的数组索引。
db.getCollection('test').aggregate( [ { $unwind: { path: "$sizes", includeArrayIndex: "arrayIndex" } } ] )
返回:
{ "_id" : 1, "item" : "ABC", "sizes" : "S", "arrayIndex" : NumberLong(0) }
{ "_id" : 1, "item" : "ABC", "sizes" : "M", "arrayIndex" : NumberLong(1) }
{ "_id" : 1, "item" : "ABC", "sizes" : "L", "arrayIndex" : NumberLong(2) }
{ "_id" : 3, "item" : "IJK", "sizes" : "M", "arrayIndex" : null }
2)以下$unwind操作使用preserveNullAndEmptyArrays选项在输出中包含缺少size字段,null或空数组的文档。
db.inventory.aggregate( [
{ $unwind: { path: "$sizes", preserveNullAndEmptyArrays: true } }
] )
返回:
{ "_id" : 1, "item" : "ABC", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC", "sizes" : "L" }
{ "_id" : 2, "item" : "EFG" }
{ "_id" : 3, "item" : "IJK", "sizes" : "M" }
{ "_id" : 4, "item" : "LMN" }
{ "_id" : 5, "item" : "XYZ", "sizes" : null }
$project
释义:
$project可以从文档中选择想要的字段,和不想要的字段(指定的字段可以是来自输入文档或新计算字段的现有字段
),也可以通过管道表达式进行一些复杂的操作,例如数学操作,日期操作,字符串操作,逻辑操作。
语法:
{ $project: { } } $project 管道符的作用是选择字段(指定字段,添加字段,不显示字段,_id:0,排除字段等),重命名字段,派生字段。
specifications有以下形式:
_id: <0 or false> 是否指定_id字段
- 默认情况下,_id字段包含在输出文档中。要在输出文档中包含输入文档中的任何其他字段,必须明确指定$project中的包含。 如果指定包含文档中不存在的字段,$project将忽略该字段包含,并且不会将该字段添加到文档中。
- 默认情况下,_id字段包含在输出文档中。要从输出文档中排除_id字段,必须明确指定$project中的_id字段为0。
- v3.4版新增功能-如果指定排除一个或多个字段,则所有其他字段将在输出文档中返回。 如果指定排除_id以外的字段,则不能使用任何其他$project规范表单:即,如果排除字段,则不能指定包含字段,重置现有字段的值或添加新字段。此限制不适用于使用REMOVE变量条件排除字段。
- v3.6版本中的新功能- 从MongoDB 3.6开始,可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段。
- 要添加新字段或重置现有字段的值,请指定字段名称并将其值设置为某个表达式。
- 要将字段值直接设置为数字或布尔文本,而不是将字段设置为解析为文字的表达式,请使用$literal操作符。否则,$project会将数字或布尔文字视为包含或排除该字段的标志。
- 通过指定新字段并将其值设置为现有字段的字段路径,可以有效地重命名字段。
- 从MongoDB 3.2开始,$project阶段支持使用方括号[]直接创建新的数组字段。如果数组规范包含文档中不存在的字段,则该操作会将空值替换为该字段的值。
- 在版本3.4中更改-如果$project 是一个空文档,MongoDB 3.4和更高版本会产生一个错误。
- 投影或添加/重置嵌入文档中的字段时,可以使用点符号。如:
"contact.address.country": <1 or 0 or expression>
或
contact: { address: { country: <1 or 0 or expression> } }举例:
示例数据:
{
"_id" : 1,
title: "abc123",
isbn: "0001122223334",
author: { last: "zzz", first: "aaa" },
copies: 5,
lastModified: "2016-07-28"
}
1. 以下$project阶段的输出文档中只包含_id,title和author字段:
db.getCollection('test').aggregate( [ { $project : { title : 1 , author : 1 } } ] )返回:
{ "_id" : 1, "title" : "abc123", "author" : { "last" : "zzz", "first" : "aaa" } }2. _id字段默认包含在内。要从$ project阶段的输出文档中排除_id字段,请在project文档中将_id字段设置为0来指定排除_id字段。
db.getCollection('test').aggregate( [ { $project : { _id: 0, title : 1 , author : 1 } } ] )返回:
{ "title" : "abc123", "author" : { "last" : "zzz", "first" : "aaa" } }3.以下$ project阶段从输出中排除lastModified字段:
db.getCollection('test').aggregate( [ { $project : { "lastModified": 0 } } ] )4.从嵌套文档中排除字段, 在$ project阶段从输出中排除了author.first和lastModified字段:
db.test.aggregate( [ { $project : { "author.first" : 0, "lastModified" : 0 } } ] )或者可以将排除规范嵌套在文档中:
db.test.aggregate( [ { $project: { "author": { "first": 0}, "lastModified" : 0 } } ] )返回:
{
"_id" : 1,
"title" : "abc123",
"isbn" : "0001122223334",
"author" : {
"last" : "zzz"
},
"copies" : 5,
}
3.6版本中的新功能。从MongoDB 3.6开始,可以在聚合表达式中使用变量REMOVE来有条件地禁止一个字段。
示例数据:
{
"_id" : 1,
title: "abc123",
isbn: "0001122223334",
author: { last: "zzz", first: "aaa" },
copies: 5,
lastModified: "2016-07-28"
}
{
"_id" : 2,
title: "Baked Goods",
isbn: "9999999999999",
author: { last: "xyz", first: "abc", middle: "" },
copies: 2,
lastModified: "2017-07-21"
}
{
"_id" : 3,
title: "Ice Cream Cakes",
isbn: "8888888888888",
author: { last: "xyz", first: "abc", middle: "mmm" },
copies: 5,
lastModified: "2017-07-22"
}
5. 下面的$project阶段使用REMOVE变量来排除author.middle字段,前提是它等于"":
db.books.aggregate( [
{
$project: {
title: 1,
"author.first": 1,
"author.last" : 1,
"author.middle": {
$cond: {
if: { $eq: [ "", "$author.middle" ] },
then: "$$REMOVE",
else: "$author.middle"
}
}
}
}
] )
返回:
{ "_id" : 1, "title" : "abc123", "author" : { "last" : "zzz", "first" : "aaa" } }
{ "_id" : 2, "title" : "Baked Goods", "author" : { "last" : "xyz", "first" : "abc" } }
{ "_id" : 3, "title" : "Ice Cream Cakes", "author" : { "last" : "xyz", "first" : "abc", "middle" : "mmm" } }包含来自嵌入文档的指定字段(结果只返回包含嵌套文档的字段,当然也包括_id)
示例文档:
{ _id: 1, user: "1234", stop: { title: "book1", author: "xyz", page: 32 } }
{ _id: 2, user: "7890", stop: [ { title: "book2", author: "abc", page: 5 }, { title: "book3", author: "ijk", page: 100 } ] }只返回stop字段中的title字段:
db.bookmarks.aggregate( [ { $project: { "stop.title": 1 } } ] )
或
db.bookmarks.aggregate( [ { $project: { stop: { title: 1 } } } ] )返回:
{ "_id" : 1, "stop" : { "title" : "book1" } }
{ "_id" : 2, "stop" : [ { "title" : "book2" }, { "title" : "book3" } ] }包含计算字段
示例数据:
{
"_id" : 1,
title: "abc123",
isbn: "0001122223334",
author: { last: "zzz", first: "aaa" },
copies: 5
}
返回字段新增了isbn, lastname和copiesold
db.books.aggregate(
[
{
$project: {
title: 1,
isbn: {
prefix: { $substr: [ "$isbn", 0, 3 ] },
group: { $substr: [ "$isbn", 3, 2 ] },
publisher: { $substr: [ "$isbn", 5, 4 ] },
title: { $substr: [ "$isbn", 9, 3 ] },
checkDigit: { $substr: [ "$isbn", 12, 1] }
},
lastName: "$author.last",
copiesSold: "$copies"
}
}
]
)
上面执行的返回结果:
{
"_id" : 1,
"title" : "abc123",
"isbn" : {
"prefix" : "000",
"group" : "11",
"publisher" : "2222",
"title" : "333",
"checkDigit" : "4"
},
"lastName" : "zzz",
"copiesSold" : 5
}
投影出新数组字段
示例数据:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "x" : 1, "y" : 1 }下面的聚合操作将返回新的数组字段myArray:
db.collection.aggregate( [ { $project: { myArray: [ "$x", "$y" ] } } ] )返回:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "myArray" : [ 1, 1 ] }如果返回的数组包含了不存在的字段,则会返回null:
db.collection.aggregate( [ { $project: { myArray: [ "$x", "$y", "$someField" ] } } ] )返回:
{ "_id" : ObjectId("55ad167f320c6be244eb3b95"), "myArray" : [ 1, 1, null ] }$limit
限制传递到管道中下一阶段的文档数
语法:
{ $limit: } 示例:
db.article.aggregate(
{ $limit : 5 }
);此操作仅返回管道传递给它的前5个文档。 $limit对其传递的文档内容没有影响。
注意:
当$sort在管道中的$limit之前立即出现时,$sort操作只会在过程中维持前n个结果,其中n是指定的限制,而MongoDB只需要将n个项存储在内存中。当allowDiskUse为true并且n个项目超过聚合内存限制时,此优化仍然适用。
$skip
跳过进入stage的指定数量的文档,并将其余文档传递到管道中的下一个阶段
语法:
{ $skip: } 示例:
db.article.aggregate(
{ $skip : 5 }
);此操作将跳过管道传递给它的前5个文档。 $skip对沿着管道传递的文档的内容没有影响。
$sort
对所有输入文档进行排序,并按排序顺序将它们返回到管道。
语法:
{ $sort: { : , : ... } }
$sort指定要排序的字段和相应的排序顺序的文档。
- 1指定升序。
- -1指定降序。
- {$meta:“textScore”}按照降序排列计算出的textScore元数据。
示例:
要对字段进行排序,请将排序顺序设置为1或-1,以分别指定升序或降序排序,如下例所示:
db.users.aggregate(
[
{ $sort : { age : -1, posts: 1 } }
]
)比较不同BSON类型的值时,MongoDB使用以下比较顺序,从最低到最高:
1 MinKey (internal type)
2 Null
3 Numbers (ints, longs, doubles, decimals)
4 Symbol, String
5 Object
6 Array
7 BinData
8 ObjectId
9 Boolean
10 Date
11 Timestamp
12 Regular Expression
13 MaxKey (internal type)
$sortByCount
v3.4新增。根据指定表达式的值对传入文档分组,然后计算每个不同组中文档的数量。每个输出文档都包含两个字段:包含不同分组值的_id字段和包含属于该分组或类别的文档数的计数字段,文件按降序排列。
语法:
{ $sortByCount: } MongoDB招贤纳士,加入MongoDB请关注微信公众号
