离线数仓搭建流程以及遇到的问题Hadoop3.3.1-hive3.1.2-spark 3.3.1
目录
简言
数仓选型
前期准备
更改三个节点主机名:
新增用户组以及用户:
配置互信
JDK安装
mysql安装
Zookeeper3.8安装
Hadoop3.3.1搭建
Hive3.1.3搭建
Spark3.3.1安装
想在idea上开发spark的话
Kettle在Windows版本节点安装以及连接hive、mysql、hadoop
安装 dolphinscheduler3.1.3
dolphinscheduler的使用
结语
简言
搭建背景:公司想要转型数字化, 想要发展BI系统, 就需要从0开始搭建数仓进行数据整合, 数据治理, 也就是ETL的过程, 我之前并没有做过这些, 但是经过慢慢摸索, 从网上搜索文章, 进行组件安装测试, 以及许多bug的解决, 最后搭建了一个基础数仓架构, 感谢网上的那些大佬, 特写此文来记载我数仓的搭建流程以及遇到的问题.
以下是整体流程的简述
选型:先选择组件 根据业务需求 组件之间版本的兼容
搭建: 考虑搭建顺序, 主要根据组件之间的依赖,比如说hive依赖hadoop, 而且我使用的是spark on hive 所以spark又依赖hive
启动测试: 每个组件搭建之后启动,测试其功能
调优: 配置调优
数仓选型
结合业务背景:需要从不同的数据源里面有mysql、oracle、sas还有excel的形式,进行数据拉取,拉取到hadoop集群,然后使用hive进行数据清洗, 但是后面我觉得hive数据处理的时间太长了,决定使用spark on hive模式进行处理,最后还需要将结果表数据导出至mysql,然后使用帆软进行数据报表输出。
所以我最后选择的架构是,如下图所示:

然后就是版本选择了, 因为我喜欢高版本的(毕竟功能多),所以我选择的数仓架构组件版本以及搭建顺序如下:
zookeeper3.4.6 -> mysql 5.7 -> kettle 8 -> Hadoop3.3.1 高可用-> hive3.1.2 -> spark 3.3.1 -> dolphinschedule3.1.3
我准备了三台机子,每个节点搭建的角色如下:
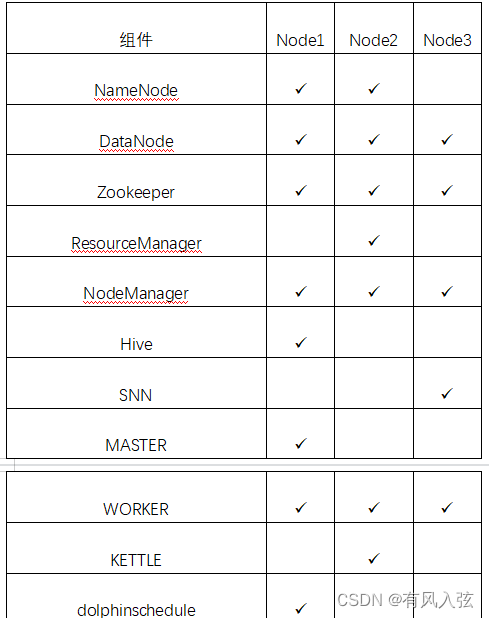
前期准备
由于我这三个节点的防火墙已经关闭了,建议把各个节点的防火墙也关了, 还要设置成开机停止自启
更改三个节点主机名:
- hostnamectl set-hostname <修改后主机名字>
- 重启reboot
新增用户组以及用户:
每个节点总共新增两个用户 mysql以及hadoop,以hadoop为例
- groupadd hadoop
- useradd -d /home/hadoop -m hadoop -s /bin/bash -g Hadoop
- passwd Hadoop
配置互信
以使用root用户进行互信开始,使用root进行以下操作
- 执行命令ssh-keygen -P ''执行后会提示输入文件保存路径,直接回车即可,文件默认在当前用户的.ssh文件夹下。
- 切换到路径cd ~/.ssh
- 执行命令ssh-copy-id -i ~/.ssh/id_rsa.pub [email protected],执行后按照提示输入服务器root用户密码
- 不同节点都要执行一遍
还需要把hadoop用户的互信也完成
JDK安装
查看JDK软件包列表
yum search java | grep -i
yum install -y java-1.8.0-openjdk-devel.x86_64查看JDK是否安装成功
java -versionJDK默认安装路径/usr/lib/jvm
在/etc/profile文件添加如下命令
JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-3.b13.el7_5.x86_64
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME PATH保存关闭profile文件,执行如下命令生效
source /etc/profilemysql安装
这个可以参考其他博主比如的安装,(50条消息) mysql-5.7 Linux安装教程_linux安装mysql5.7_路灯下的程序员的博客-CSDN博客
讲的很详细,按照这个安装我没出现问题
Zookeeper3.8安装
这个可以参考:
zookeeper3.8安装
记一下启停以及查看状态的命令:
/home/software/zookeeper-3.8.0/bin/zkServer.sh start|stop|status扩展:编写shell脚本 一键脚本启动。
本质:在node1机器上执行shell脚本,由==shell程序通过ssh免密登录==到各个机器上帮助执行命令。脚本具体路径你们自己决定
一键关闭脚本
[root@node1 ~]# vim stopZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "/export/server/zookeeper/bin/zkServer.sh stop"
done一键启动脚本
[root@node1 ~]# vim startZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start"
done注意:
1. 关闭java进程时候 根据进程号 直接杀死即可就可以关闭。启动java进程的时候 需要JDK
2. shell程序ssh登录的时候不会自动加载/etc/profile 需要shell程序中自己加载。
Hadoop3.3.1搭建
这个我是参考(52条消息) Hadoop3_Java朱老师的博客-CSDN博客这位老师的, 推荐哈, 很详细
其中四个配置文件推荐看我下面的, 我进行了补充了的
core-site.xml
fs.defaultFS
hdfs://node1:9000
io.file.buffer.size
131072
hadoop.tmp.dir
file:/home/hadoop/hadoop_data/tmp
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
hdfs-site.xml配置
dfs.namenode.secondary.http-address
node3:9001
dfs.namenode.name.dir
file: /home/hadoop/hadoop_data/dfs/name
dfs.datanode.data.dir
file: /home/hadoop/hadoop_data/dfs/data
dfs.replication
3
dfs.webhdfs.enabled
true
yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
node2
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.log-aggregation-enable
true
yarn.log.server.url
http://node1:19888/jobhistory/logs
yarn.nodemanager.remote-app-log-dir
/tmp/logs
yarn.log-aggregation.retain-seconds
604800
mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
node1:10020
mapreduce.jobhistory.webapp.address
node1:19888
最后hadoop启动顺序是:
先在node1主节点启动 start-dfs.sh之后再在规划的resourcemanager节点node2上启动yarn集群 start-yarn.sh。
关闭时, 先在node2 执行stop-yarn.sh 再去node1执行stop-dfs.sh
当然也可以写个启动脚本.
Hive3.1.3搭建
具体的搭建步骤也是参考(52条消息) Hive3详细教程(一)Hive3+Hadoop3环境安装_Java朱老师的博客-CSDN博客 这位老师的
其中hive的配置文件需要按照下面来修改一下:
hive-site.xml
javax.jdo.option.ConnectionURL
jdbc:mysql://node1:3306/metastore?createDatabaseIfNotExist=true&useSSL=false
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
mysql
javax.jdo.option.ConnectionPassword
*******
hive.server2.thrift.bind.host
node1
hive.metastore.uris
thrift://node1:9083
hive.metastore.schema.verification
false
hive.metastore.event.db.notification.api.auth
false
hive.metastore.warehouse.dir
/user/hive/warehouse
hive.server2.thrift.port
10000
hive.server2.enable.doAs
false
搭建完成之后开启metastore以及hiveserver2
命令是:
nohup hive --service metastore &
nohup hive --service hiveserver2 &分别开启, 这样就可以使用外部软件链接hive了, 比如dbeaver等等, 但是可能需要稍等一下才能连接, 等hiveserver2完全启动
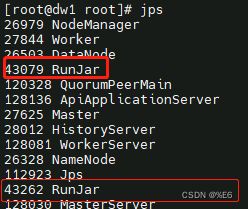
启动成功的标志是输入jps, 出现两个RunJar进程
Spark3.3.1安装
由于我不仅需要安装spark还需要配置成spark on hive, 所以参考了spark3.3.1安装 以及spark-on-hive
注意在安装spark的时候, 其中的两个配置我做了一下修改:
spark-defaults.conf:
spark.master spark://node1:7077
spark.yarn.historyServer.address node1:18080
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:9000//user/spark/log
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 5g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"spark-env.sh:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.362.b08-1.el7_9.x86_64
export SPARK_CONF_DIR=/home/software/spark-3.3.1/conf
export HADOOP_HOME=/home/software/hadoop
export HADOOP_CONF_DIR=/home/software/hadoop/etc/hadoop
export YARN_CONF_DIR=/home/software/hadoop/etc/hadoop
export HIVE_HOME=/home/software/hive
export SCALA_HOME=/home/software/scala-2.13.10
# 指定spark的master
export SPARK_MASTER_HOST=node1
# 指定spark可从hdfs上读写数据
export SPARK_DIST_CLASSPATH=$(/home/software/hadoop/bin/hadoop classpath)
# 解除运行时无法加载本地hadoop库的提醒
export LD_LIBRARY_PATH=/home/software/hadoop/lib/native
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node1:9000//user/spark/log"注意!!!!!
配置完之后还需要将hive下面的hive-site.xml复制到spark的conf目录下面,包括hadoop的etc下面的core-site.xml等等四个文件都放进去
启动
start-master.sh
start-workers.sh
start-history-server.sh停止顺序相反
注意: spark的jobhistoryserver启动之后打开jobhistoryserver的UI界面会出现没有显示任务,这个是正常的, 需要提交一个任务之后就会正常(我一开始以为是真的报错, 找了好久,晕死。。。)
想在idea上开发spark的话
可以参考idea开发spark
出现的问题 : 将代码打包到linux之后可能会出现问题, 但是日志也找不到报错点, 此时可以通过
##后面跟着的是任务的applicationID,可以在yarn日志找到
yarn logs -applicationId application_1681894239134_0016来查看具体出错的原因
我出现的路径问题 需要修改包的标记:
我发现是因为我的idea包的标记问题,可以参考我下面的来修改, java和scala标记上Sources Root,

然后在你需要运行的任务类右键->Copy Path ->Copy Reference 复制相对路径 再去运行spark-submit
记一下我所用的spark-submit代码
/home/software/spark-3.3.1/bin/spark-submit \
--master yarn \
--deploy-mode client \
--class com.xhgj.bigdata.firstProject.Test \
--num-executors 4 \
--executor-memory 6g \
--executor-cores 2 \
/home/project/ykb/command/data_analysis_xh_ceshi-1.0.jar此外:
完整的Pom.xml文件
4.0.0
org.example
data_analysis_xh
1.0-SNAPSHOT
8
8
UTF-8
2.13.10
3.3.1
3.3.1
1.2.17
org.scala-lang
scala-library
${scala.version}
org.apache.spark
spark-core_2.13
${spark.version}
org.apache.spark
spark-sql_2.13
${spark.version}
mysql
mysql-connector-java
5.1.34
org.apache.hadoop
hadoop-client
${hadoop.version}
org.apache.spark
spark-hive_2.13
${spark.version}
org.scala-lang.modules
scala-parallel-collections_2.13
1.0.4
com.twitter
chill_2.13
0.10.0
com.alibaba
fastjson
1.2.36
log4j
log4j
${log4j.version}
target/classes
target/test-classes
data_analysis_xh-1.0
${project.basedir}/src/main/resources
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
Maven需要下载 然后settings.xml需要设置到阿里云mvn仓库, 文件内容入下:
ali
ali Maven
*
https://maven.aliyun.com/repository/public/
有可能还会出现Class path contains multiple SLF4J bindings:
这是因为引入的依赖有多个slf4j的实现
解决方法: 安装报错日志提醒的地址去删除其中的log4j-slf4j-impl 的jar包, 保留一个即可
spark日志级别的设置: 因为使用idea会打印很多的日志, 导致很难看, 就从网上查看, 发现修改log4j.properties就可以限制日志级别, 但是发现完全没有用, 照样出现大量INFO级别的日志
后面检查发现现在使用的spark3.3.1需要用log4j2.properties, 改了个文件名就好了, 真的很离谱. 至于在linux上日志级别的设置, 直接去安装目录下面的conf目录修改log4j2.properties内容即可(如果只有log4j2.properties.template,那就改个名字就好)
Kettle在Windows版本节点安装以及连接hive、mysql、hadoop
- 先安装jdk
- 安装kettle
- kettle需要连接mysql还需要将mysql驱动包移到kettle的lib目录下面
- kettle需要链接hive 需要将hive下jdbc目录下面的hive-jdbc-3.1.2-standalone.jar包放在kettle的lib目录下面,还有hive-site.xml放在
D:\pdi-ce-8.3.0.0-371\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30下面, 还要将服务器hive安装路径下的lib目录中的所有hive开头的jar包下下来安装在
D:\pdi-ce-8.3.0.0-371\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30\lib目录下(原来的删除)
- 使用kettle连接hadoop需要 修改data-integration\plugins\pentaho-big-data-plugin\plugin.properties路径下面的plugin.properties将active.hadoop.configuration=hdp30写上,然后去服务器将相关配置文件下下来,替换
D:\pdi-ce-8.3.0.0-371\data-integration\plugins\pentaho-big-data-plugin\hadoop-configurations\hdp30目录下面的core-site.xml等四个文件
之后,新建hadoop clusters,里面hdfs的port要和core-site.xml一样 hostname也要一样
- 直接写在hdfs会没有权限可以通过在Spoon.bat中添加
在set OPT=这一行后面提添加内容: “-DHADOOP_USER_NAME=root”
- 要部署到linux,就直接把windows的包打包上传就行
- 在linux执行kettle的任务(需要提前给/home/software/pdi-ce-8.3.0.0-371/data-integration/目录下面所有sh文件执行权限)
- 执行转换:/home/software/pdi-ce-8.3.0.0-371/data-integration/pan.sh -file /data/kettle_job/mysql2hdfs.ktr
- 执行作业:/home/software/pdi-ce-8.3.0.0-371/data-integration/pan.sh -file /data/kettle_job/mysql2hdfs.kjb
- Kettle 抽取Oracle或者MYSQL数据到HDFS发生串行(即数据量对不上等)
在从Oracle或者MYSQL数据库拉取想要的数据至ODS层的时候,有时候会发现数据量对不上,数据的条数变多,这种情况下很有可能是数据库内容中有特殊字符导致,常见的导致数据串行的特殊字符有制表符(chr(9)),换行符(chr(10))和回车符(chr(13))。我们可以用replace函数去除oracle字符串中的特殊字符,其他数据库也是类似
修改表输入的SQL语句, 以下图为例
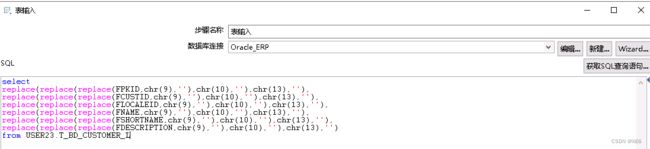
使用replace的函数方法将数据进行清洗, 防止出现串行的情况发生
还有一点, 就是由于导入至hive时间过长, 所以考虑直接将文件导入至hdfs的hive路径下, 此时需要再添加一个replace,将逗号都替换成其他不会影响值的符号
- kettle抽取hive数据到mysql出现 cannot be null 空值问题
在hive中有空字符串的字段在使用kettle进行数据拉取导入至mysql库时,会出现自动把字符串转换成null值的情况, 这样会导致一些mysql不能为null的字段报错,
解决方法:
windows下: 前往C:\Users\用户名\.kettle路径下面找到kettle.properties配置文件, 进行编辑加入
KETTLE_EMPTY_STRING_DIFFERS_FROM_NULL=Y在Linux下: 前往安装kettle的用户下面的~目录, 找到.kettle目录, 编辑加入上面的配置
安装 dolphinscheduler3.1.3
按照以下链接进行安装dolphinschedule安装以及官方文档
最好根据自己系统参考这两个安装流程, 在安装之前先看看我列的注意事项:
- dolphinscheduler用户的ssh免密,按照上面第一个链接的来
- 初始化数据库按照官网的来
- 修改dolphinscheduler_env.sh中 SPRING_DATASOURCE_URL这个配置按照官网的来但是其中ip地址改成mysql所在的ip
- mysql-connector-java 驱动 (8.0.16)除了要放在api-server/libs 和 alert-server/libs 和 master-server/libs 和 worker-server/libs下面还需要放在tools/libs下面
- 用root启动之后就不要用dolphinscheduler启动了,除非去/tmp/dolphinscheduler/下面把对应日志删除
- Dolphinscheduler3.1.3需要的zookeeper版本是3.8.0,不然会报错
dolphinscheduler的使用
A. Dolphinscheduler3.1.3邮件告警模块的使用(52条消息) DolphinScheduler 进阶(告警通知)_dolphinscheduler告警_Alienware^的博客-CSDN博客
B. 在工作流实例中,点击执行的意思是现在立马执行,只有点击定时调度,再点上线,就是定时处理
C. 在执行shell脚本时通过${date}来获取外界传入的日期.
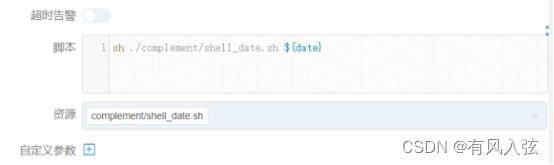
然后点击保存

这里要设计全局变量, 就是将刚刚那个参数设置值,注意这里$[yyyy-MM-dd-1]用的是方括号,而且是当前日期减一
D.补数就是是否需要补前几天日期的数据
DolphinScheduler的端口复用
DolphinScheduler的端口复用是指在Worker节点进程退出时,没有及时地释放其占用的端口,导致下一次启动Worker节点时无法绑定到原先使用的端口。避免DolphinScheduler的端口复用,您可以执行以下操作:
在配置文件conf/worker.properties中,设置worker.mode=stop参数。该参数可以使在Worker节点退出时,能够及时地将原先绑定的端口释放掉。当然,这样设置会在每次Worker节点进程退出后需要重新启动一个新的进程,会有一定的性能开销,因此需要根据实际情况进行权衡。如果您不想停止Worker节点的重启模式,可以通过其他方式在Worker节点退出时释放相应端口,例如通过crontab定时任务进行端口资源释放,或者使用运维工具进行进程监控和管理。
另外,可以通过调整Worker节点的心跳间隔时间、线程池大小等参数,减轻Worker节点的压力,从而缓解端口复用问题。例如,可以通过在配置文件conf/worker.properties中配置worker.heartbeat.interval=60来调整Worker节点的心跳间隔时间,以便更及时地检测和处理Worker节点的异常情况。当然,在修改配置文件后,需要重启DolphinScheduler的Worker节点以使配置生效。
结语
至此, 这个基本的数仓架构搭建完毕, 接下来小伙伴们就是需要根据自己的需求进行spark yarn hadoop hive mysql 的性能优化了.
再次感谢我文章里面链接的作者, 给我了很大的方便, 让我在短时间内搭建起来了这个简单的集群.
之后我也会分享我在开发过程中出现的问题以及好的想法, 感谢各位的查阅, 如果能帮到你们, 我很荣幸