腾讯云 Finops Crane 开发者集训营 - 云成本优化一站式解决方案实践
一、 相关活动介绍:
自从上次参加完CSDN联合腾讯云发起的《云原生之降本增效》活动后,只是停留聚焦在优秀实践方法论、资源与弹性、架构设计上的了解,本次《腾讯云 Finops Crane 开发者集训营》是深入了解并实践基于 FinOps 框架开展的一个成本优化项目Crane。
- 活动相关链接:
https://marketing.csdn.net/p/038ae30af2357473fc5431b63e4e1a78
- 相关讲座视频回放链接:
https://live.csdn.net/room/csdnnews/CPEN2JKh
https://live.csdn.net/room/csdnnews/83xhNo4C
二、 背景来由:
1.云上资源利用率低,导致浪费成本:

2.在后云原生时代,成本管理面临着诸多挑战?

- 面临云原生上的降本挑战:
面对云原生成本管理现状与挑战,FinOps 定义了一系列云财务管理规则和最佳实践,通过助力工程和财务团队、技术和业务团队彼此合作, 进行数据驱动的成本决策,使组织能够获得最大收益。
三、 什么是FinOps?
腾讯的云原生降本增效最佳实践是基于FinOps框架开展的。
FinOps团队的日常工作涵盖降本增效战略、成本分析与浪费识别、目标制定与下发、费率优化、业务侧优化、平台侧优化。
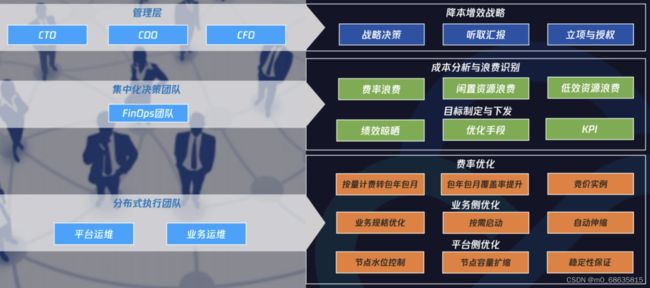
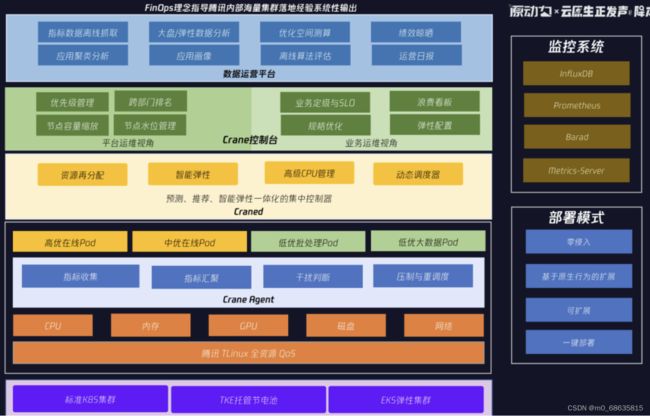
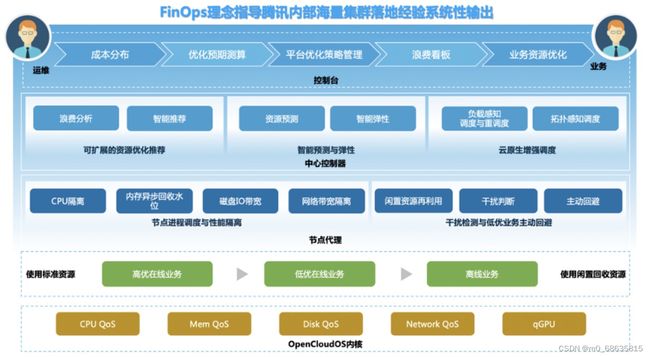

基于以上的方法论,腾讯开源了一个成本优化项目Crane(Cloud Resource Analytics and Economics)。
四、 什么是Crane?
Crane是由腾讯云主导开源的国内第一个基于云原生技术的成本优化项目,遵循FinOps标准,已经获得FinOps基金会授予的全球首个认证降本增效开源方案。
Crane项目开源链接,可以star和收藏:
https://github.com/gocrane/crane
1.成就:

2.价值:
Crane 能够帮助云原生用户充分发挥云上资源的最大价值,从而实现企业降本增效。

3.功能:
Crane 依托于云原生技术,结合监控预测、调度增强、业务混部等多项硬核科技,将优化措施应用到了云成本优化的多个关键环节,从而辅助用户决策、简化运维效率、提升系统稳态、全面降本增效。

4.组成部分:

五、 Crane的应用:

六、 公司Crane可行性分析:
公司的业务集群中的业务大多是内存消耗型的,因此极易出现内存利用率很高的节点,并且各个节点的内存利用率分布也很不平均。

1.公司目前业务服务k8s的使用情况:
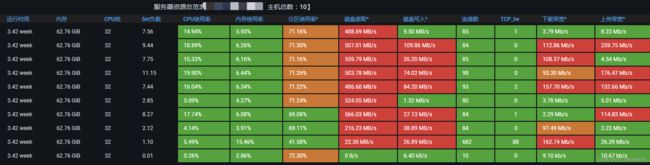
2.公司业务报表相关服务使用情况:
 3. 相关CPU与内存使用率:
3. 相关CPU与内存使用率:
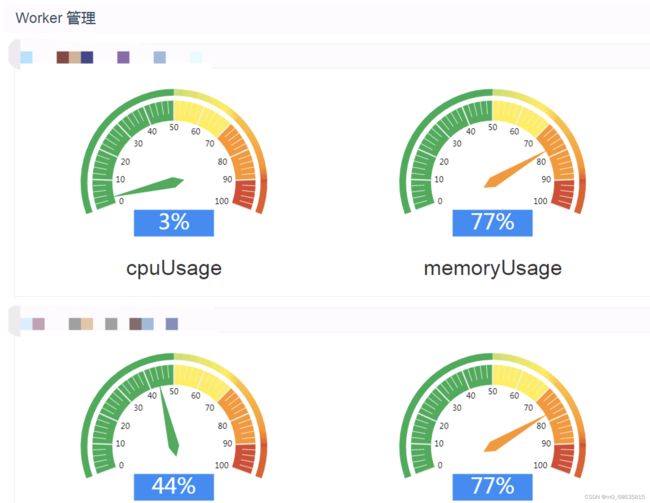
4. 慢SQL导致系统缓慢:

5. 针对于大型活动内存使用率:

6. 大量的阻塞任务:

七、 本地环境实验:
需要一些提前的预装的软件:docker、kubectl、Helm、kind,如果环境中已经有,不需要再安装
1.安装docker:
curl -fsSL https://get.docker.com | bash -s docker --mirror Aliyun
 2. 安装 kubectl:
2. 安装 kubectl:
# 下载最新发行版:
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
# 下载 kubectl 校验和文件:
curl -LO "https://dl.k8s.io/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl.sha256"
# 基于校验和文件,验证 kubectl 的可执行文件:
echo "$(cat kubectl.sha256) kubectl" | sha256sum –check
# 安装 kubectl
sudo install -o root -g root -m 0755 kubectl /usr/local/bin/kubectl
# 执行测试,以保障你安装的版本是最新的:
kubectl version --client

3. 安装 Helm:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
![]()
- 安装 kind:
# For AMD64 / x86_64
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.19.0/kind-linux-amd64
# For ARM64
[ $(uname -m) = aarch64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.19.0/kind-linux-arm64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind

5. 安装本地的 Kind 集群和 Crane 组件:
curl -sf https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh | sh -

提示:Pod 的启动需要一定的时间,等几分钟后输入命令查看后集群状态是否都 Running
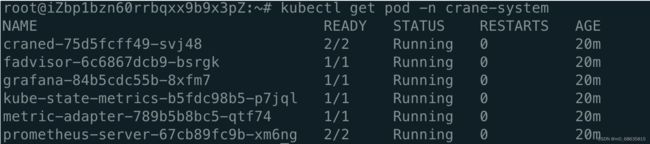
- 确保所有 Pod 都正常运行:
export KUBECONFIG=${HOME}/.kube/config_crane
kubectl get pod -n crane-system
 7. 访问 Crane Dashboard:
7. 访问 Crane Dashboard:
kubectl -n crane-system port-forward service/craned --address 0.0.0.0 9090:9090

8. 添加本地集群:
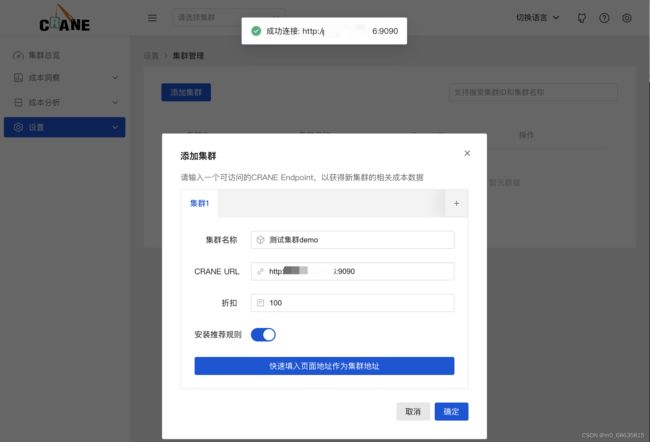

后续的终端操作请在新窗口操作,每一个新窗口操作前请把配置环境变量加上(不然会出现8080端口被拒绝的提示)
export KUBECONFIG=${HOME}/.kube/config_crane
八、 使用智能弹性 EffectiveHPA:
- HPA的不足:

2. EHPA 的主要架构:
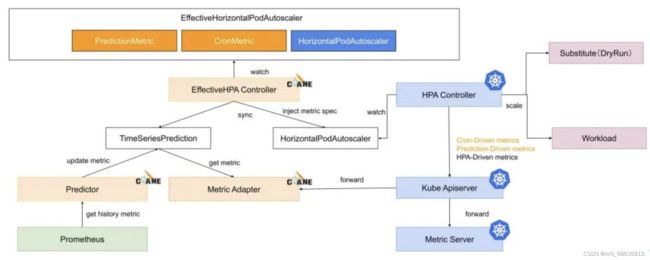

3. 实验:
3.1 安装Metrics Server:
kubectl apply -f installation/components.yaml
kubectl get pod -n kube-system
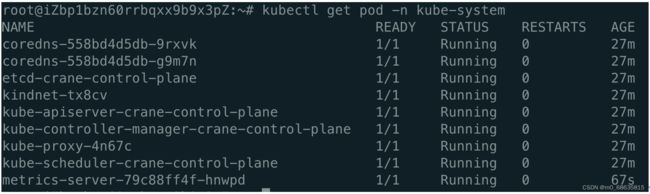
3.2 创建测试应用:
用以下命令启动一个 Deployment 用 hpa-example 镜像运行一个容器, 然后将其暴露为一个 服务(Service):
kubectl apply -f installation/php-apache.yaml
kubectl apply -f installation/nginx-deployment.yaml
3.3 创建 EffectiveHPA:
kubectl apply -f installation/effective-hpa.yaml
运行以下命令查看 EffectiveHPA 的当前状态:
kubectl get ehpa

3.4 增加负载:
# 在单独的终端中运行它
# 如果你是新创建请配置环境变量
export KUBECONFIG=${HOME}/.kube/config_crane
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
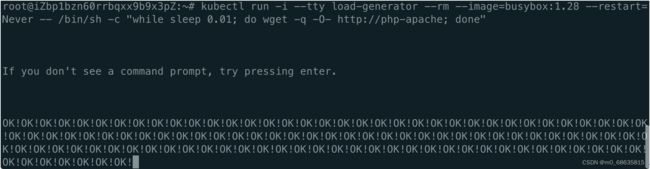
随着请求增多,CPU利用率会不断提升,可以看到 EffectiveHPA 会自动扩容实例。
说明:预测数据需要两天以上的监控数据才能出现。

 可以看到蓝色的预测数据与绿色的实时监控数据几乎吻合,表示预测数据的准确性。同时黄色曲线即为上文所说的未来时间内预测数据的最大值,所以将预测指标也作为 HPA 的阈值之一就可以达到提前扩容的效果。
可以看到蓝色的预测数据与绿色的实时监控数据几乎吻合,表示预测数据的准确性。同时黄色曲线即为上文所说的未来时间内预测数据的最大值,所以将预测指标也作为 HPA 的阈值之一就可以达到提前扩容的效果。
- Crane Dashboard显示:
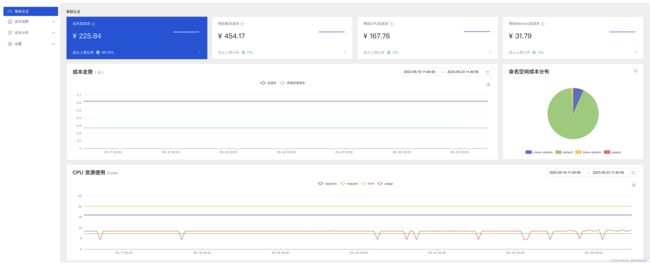
- 当月总成本:过去一个月集群总成本。从安装Crane时间开始,按小时累加集群成本
- 预估每月成本:以最近一小时成本估算未来一个月的成本。每小时成本 * 24 * 30
- 预估CPU总成本:以最近一小时CPU成本估算未来一个月的CPU成本。每小时CPU成本 * 24 * 30
- 预估Memory总成本:以最近一小时Memory成本估算未来一个月的Memory成本。每小时Memory成本 * 24 * 30
成本洞察->集群总览:
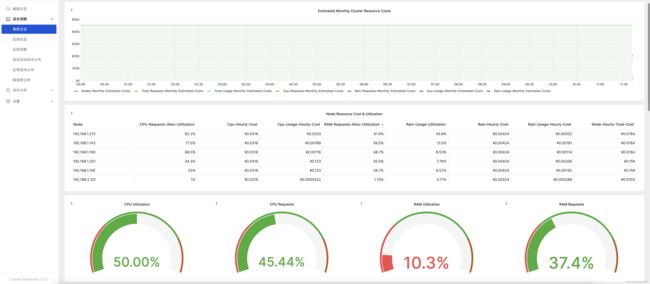
成本洞察->应用成本分布:

六、总结:
毫无疑问,Crane 已经是 K8s 集群中用于云资源分析和经济的最佳 FinOps 平台了。目前,腾讯云 Crane 已进入 CNCF LandScape,这意味着 Crane 已成为云原生领域的重要项目。面向未来,腾讯云还将持续反馈开源社区、共建开源生态,帮助更多企业通过云原生全面释放生产力,加速实现数字化和绿色化双转型。