Datawhale AI夏令营 - 用户新增预测挑战赛 | 学习笔记
任务1:跑通Baseline
# 1. 导入需要用到的相关库
# 导入 pandas 库,用于数据处理和分析
import pandas as pd
# 导入 numpy 库,用于科学计算和多维数组操作
import numpy as np
# 从 sklearn.tree 模块中导入 DecisionTreeClassifier 类
# DecisionTreeClassifier 用于构建决策树分类模型
from sklearn.tree import DecisionTreeClassifier
# 2. 读取训练集和测试集
# 使用 read_csv() 函数从文件中读取训练集数据,文件名为 'train.csv'
train_data = pd.read_csv('train.csv')
# 使用 read_csv() 函数从文件中读取测试集数据,文件名为 'test.csv'
test_data = pd.read_csv('test.csv')
train_data.head()
# 3. 将 'udmap' 列进行 One-Hot 编码
# 数据样例:
# udmap key1 key2 key3 key4 key5 key6 key7 key8 key9
# 0 {'key1': 2} 2 0 0 0 0 0 0 0 0
# 1 {'key2': 1} 0 1 0 0 0 0 0 0 0
# 2 {'key1': 3, 'key2': 2} 3 2 0 0 0 0 0 0 0
# 在 python 中, 形如 {'key1': 3, 'key2': 2} 格式的为字典类型对象, 通过key-value键值对的方式存储
# 而在本数据集中, udmap实际是以字符的形式存储, 所以处理时需要先用eval 函数将'udmap' 解析为字典
# 具体实现代码:
# 定义函数 udmap_onethot,用于将 'udmap' 列进行 One-Hot 编码
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 4. 编码 udmap 是否为空
# 使用比较运算符将每个样本的 'udmap' 列与字符串 'unknown' 进行比较,返回一个布尔值的 Series
# 使用 astype(int) 将布尔值转换为整数(0 或 1),以便进行后续的数值计算和分析
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# 5. 提取 eid 的频次特征
# 使用 map() 方法将每个样本的 eid 映射到训练数据中 eid 的频次计数
# train_data['eid'].value_counts() 返回每个 eid 出现的频次计数
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 6. 提取 eid 的标签特征(不同访问行为的人有不同的target标签)
# 使用 groupby() 方法按照 eid 进行分组,然后计算每个 eid 分组的目标值均值
# train_data.groupby('eid')['target'].mean() 返回每个 eid 分组的目标值均值
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 7. 提取时间戳
# 使用 pd.to_datetime() 函数将时间戳列转换为 datetime 类型
# 样例:1678932546000->2023-03-15 15:14:16
# 注: 需要注意时间戳的长度, 如果是13位则unit 为 毫秒, 如果是10位则为 秒, 这是转时间戳时容易踩的坑
# 具体实现代码:
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({
'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
# 10. 保存结果文件到本地
# 将结果DataFrame保存为一个CSV文件,文件名为 'submit.csv'
# 参数 index=None 表示不将DataFrame的索引写入文件中
result_df.to_csv('submit.csv', index=None)
实操并回答下面问题:
如果将submit.csv提交到讯飞比赛页面,会有多少的分数?
代码中如何对udmp进行了人工的onehot?
1:0.62710
2:对umap列中的字典元素按键取值,初始为一个九维的向量,将字典中键对应的值覆盖到向量中的对应位置。
任务2.1:数据分析与可视化
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
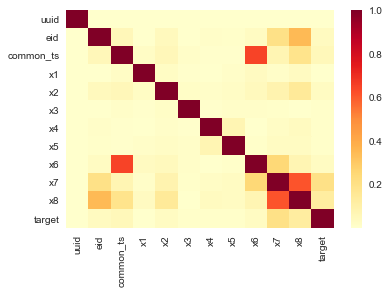
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
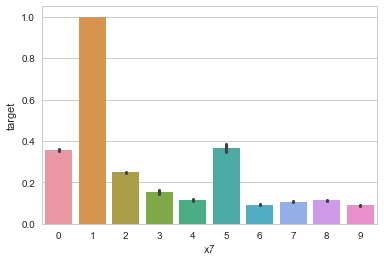
# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)
编写代码回答下面的问题:
- 字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
- 对于数值类型的字段,考虑绘制在标签分组下的箱线图。
- 从common_ts中提取小时,绘制每小时下标签分布的变化。
- 对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
问题一:字段x1至x8为用户相关的属性,为匿名处理字段。添加代码对这些数据字段的取值分析,那些字段为数值类型?那些字段为类别类型?
x1, x2, x3, x4, x5, x6, x7, x8为类别类型,x3,x4,x5为数值类型。
#1:
import pandas as pd
# 假设您的数据已经加载到名为 'data' 的 DataFrame 中
train_data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8']].head(5)
问题二:对于数值类型的字段,考虑绘制在标签分组下的箱线图。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
fig, axes = plt.subplots(nrows=1, ncols=3, figsize=(10, 6))
for i,y in enumerate(['x3', 'x4', 'x5']):
sns.boxplot(x="target", y=y, data=train_data, width=0.5, showfliers=False,ax=axes[i])
ax.set_xlabel('Label')
ax.set_ylabel(f'Feature {col}')
ax.set_title(f'Box Plot of Feature {col}')
ax.yaxis.grid(True)

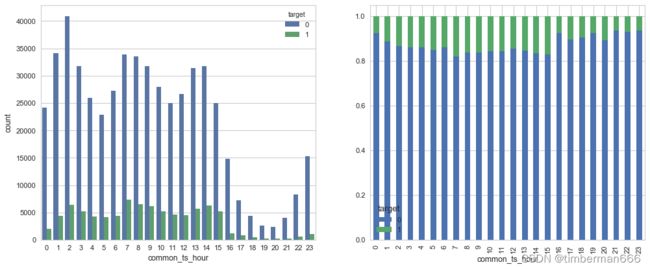
问题三:从common_ts中提取小时,绘制每小时下标签分布的变化。
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(15, 6),dpi=80)
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
# 使用 dt.hour 属性从 datetime 列中提取小时信息,并将提取的小时信息存储在新的列 'common_ts_hour'
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
sns.countplot(x="common_ts_hour",hue='target', data=train_data,ax = axes[0])
new_df = (train_data.groupby('common_ts_hour')['target']
.value_counts(normalize=True)
.sort_index()
.unstack()
)
new_df.plot.bar(stacked=True,ax = axes[1])
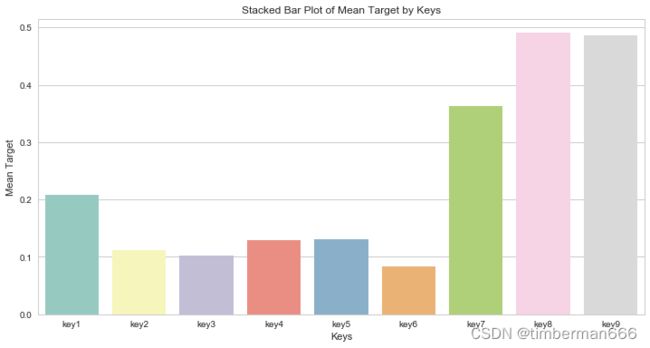
问题四:对udmap进行onehot,统计每个key对应的标签均值,绘制直方图。
train_data = pd.read_csv('train.csv')
def udmap_onethot(d):
v = np.zeros(9) # 创建一个长度为 9 的零数组
if d == 'unknown': # 如果 'udmap' 的值是 'unknown'
return v # 返回零数组
d = eval(d) # 将 'udmap' 的值解析为一个字典
for i in range(1, 10): # 遍历 'key1' 到 'key9', 注意, 这里不包括10本身
if 'key' + str(i) in d: # 如果当前键存在于字典中
v[i-1] = d['key' + str(i)] # 将字典中的值存储在对应的索引位置上
return v # 返回 One-Hot 编码后的数组
# 注: 对于不理解的步骤, 可以逐行 print 内容查看
# 使用 apply() 方法将 udmap_onethot 函数应用于每个样本的 'udmap' 列
# np.vstack() 用于将结果堆叠成一个数组
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
# 为新的特征 DataFrame 命名列名
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 将编码后的 udmap 特征与原始数据进行拼接,沿着列方向拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
key_means = {}
for key in ["key"+str(i) for i in range(1,10)]:
key_mean = train_data[train_data[key]!=0]["target"].mean()
key_means[key] = key_mean
key_means
key_means_df = pd.DataFrame(key_means, index = [0])
plt.figure(figsize=(12, 6))
sns.barplot(data=key_means_df, palette="Set3")
plt.xlabel('Keys')
plt.ylabel('Mean Target')
plt.title('Stacked Bar Plot of Mean Target by Keys')
plt.legend(title='Keys', loc='upper right')
plt.show()
任务2.2:模型交叉验证
# 导入库
import pandas as pd
import numpy as np
# 读取训练集和测试集文件
train_data = pd.read_csv('train.csv')
test_data = pd.read_csv('test.csv')
# 提取udmap特征,人工进行onehot
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
# 编码udmap是否为空
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
# udmap特征和原始数据拼接
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
# 提取eid的频次特征
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
# 提取eid的标签特征
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
# 提取时间戳
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 训练并验证SGDClassifier
pred = cross_val_predict(
SGDClassifier(max_iter=20),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target'],
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target'],
cv=5
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证MultinomialNB
pred = cross_val_predict(
MultinomialNB(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证RandomForestClassifier
pred = cross_val_predict(
RandomForestClassifier(n_estimators=5),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
编写代码回答下面的问题:
- 在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
- 使用树模型训练,然后对特征重要性进行可视化;
- 再加入3个模型训练,对比模型精度;
问题一:在上面模型中哪一个模型的macro F1效果最好,为什么这个模型效果最好?
决策树的F1分数最好,是因为它的建模能力和解释性使其适用于许多问题。
问题二:使用树模型训练,然后对特征重要性进行可视化;
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# s树的特征重要性可视化
def plot_feature_importances_cancer(model):
n_features = train_data.shape[1]-4
plt.barh(range(n_features),model.feature_importances_,align = 'center')
plt.yticks(np.arange(n_features),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1).columns)
plt.xlabel("Feature importance")
plt.ylabel("Feature")
plot_feature_importances_cancer(clf)

问题三:再加入3个模型训练,对比模型精度;
这里分别采用默认参数的岭回归分类器、极度随机树和梯度提升树进行训练得到结果
from sklearn.linear_model import RidgeClassifier
from sklearn.tree import ExtraTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
pred = cross_val_predict(
RidgeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
pred = cross_val_predict(
ExtraTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
pred = cross_val_predict(
BaggingClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
任务2.3:特征工程
对教程中所给的特征工程的方法进行了实验,发现测试集中的x3_freq和x4_freq存在为nan的值,我们考虑去掉这两个特征。
train_data['common_ts_day'] = train_data['common_ts'].dt.day
test_data['common_ts_day'] = test_data['common_ts'].dt.day
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
##x3_freq和x4_freq存在为nan的值
#train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
#test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
#train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
#test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
train_data.head()
# 训练并验证DecisionTreeClassifier
pred = cross_val_predict(
DecisionTreeClassifier(),
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 8. 加载决策树模型进行训练(直接使用sklearn中导入的包进行模型建立)
clf = DecisionTreeClassifier()
# 使用 fit 方法训练模型
# train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1) 从训练数据集中移除列 'udmap', 'common_ts', 'uuid', 'target'
# 这些列可能是特征或标签,取决于数据集的设置
# train_data['target'] 是训练数据集中的标签列,它包含了每个样本的目标值
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1), # 特征数据:移除指定的列作为特征
train_data['target'] # 目标数据:将 'target' 列作为模型的目标进行训练
)
# 9. 对测试集进行预测,并保存结果到result_df中
# 创建一个DataFrame来存储预测结果,其中包括两列:'uuid' 和 'target'
# 'uuid' 列来自测试数据集中的 'uuid' 列,'target' 列将用来存储模型的预测结果
result_df = pd.DataFrame({
'uuid': test_data['uuid'], # 使用测试数据集中的 'uuid' 列作为 'uuid' 列的值
'target': clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)) # 使用模型 clf 对测试数据集进行预测,并将预测结果存储在 'target' 列中
})
#由于这里进行特征工程后存在为0的值表示为nan,我们将nan值填充为0
改进
通用的用于推荐系统的特征
train_data["common_ts_month"] = train_data["common_ts"].dt.month # 添加新特征“month”,代表”当前月份“。
test_data["common_ts_month"] = test_data["common_ts"].dt.month
train_data["common_ts_day"] = train_data["common_ts"].dt.day # 添加新特征“day”,代表”当前日期“。
test_data["common_ts_day"] = test_data["common_ts"].dt.day
train_data["common_ts_hour"] = train_data["common_ts"].dt.hour # 添加新特征“hour”,代表”当前小时“。
test_data["common_ts_hour"] = test_data["common_ts"].dt.hour
train_data["common_ts_minute"] = train_data["common_ts"].dt.minute # 添加新特征“minute”,代表”当前分钟“。
test_data["common_ts_minute"] = test_data["common_ts"].dt.minute
train_data["common_ts_weekofyear"] = train_data["common_ts"].dt.isocalendar().week.astype(int) # 添加新特征“weekofyear”,代表”当年第几周“,并转换成 int,否则 LightGBM 无法处理。
test_data["common_ts_weekofyear"] = test_data["common_ts"].dt.isocalendar().week.astype(int)
train_data["common_ts_dayofyear"] = train_data["common_ts"].dt.dayofyear # 添加新特征“dayofyear”,代表”当年第几日“。
test_data["common_ts_dayofyear"] = test_data["common_ts"].dt.dayofyear
train_data["common_ts_dayofweek"] = train_data["common_ts"].dt.dayofweek # 添加新特征“dayofweek”,代表”当周第几日“。
test_data["common_ts_dayofweek"] = test_data["common_ts"].dt.dayofweek
train_data["common_ts_is_weekend"] = train_data["common_ts"].dt.dayofweek // 6 # 添加新特征“is_weekend”,代表”是否是周末“,1 代表是周末,0 代表不是周末。
test_data["common_ts_is_weekend"] = test_data["common_ts"].dt.dayofweek // 6
通过观察x7的分布图发现,在x7的类别为1的时候,标签几乎全为1,因此构造此特征
train_data["x7_01"] = train_data["x7"] == 1
train_data["x7_01"] = train_data["x7_01"].astype(int)
test_data["x7_01"] = test_data["x7"]==1
test_data["x7_01"] = test_data["x7_01"].astype(int)
通过观察一天内的标签分布构造特征
train_data["common_ts_hoursofday"] = (train_data["common_ts_hour"] < 2) | (train_data["common_ts_hour"] > 13)
train_data["common_ts_hoursofday"] = train_data["common_ts_hoursofday"].astype(int)
test_data["common_ts_hoursofday"] = (test_data["common_ts_hour"] < 2) | (train_data["common_ts_hour"] > 13)
test_data["common_ts_hoursofday"] = test_data["common_ts_hoursofday"].astype(int)