浅析数据库设计三范式
在学习数据设计的时候,N种专业术语,看的头疼。但又不能不学,所以只好把它们整理整理出来,好让自己对它们有一个更深的理解。特别是对三范式(Normal Formal)的理解。
三范式指的是第一(1NF)、第二(2NF)和第三范式(3NF),其作用:解决数据冗余,为数据有效性检查,提高存储效率考虑。
在了解三范式之前,我们先来弄清楚这几个概念(键、函数依赖以及其类型):
一、关键码(键):由一个或多个属性组成,在实际使用中,有下列几种:
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键。注意:(属性集,说明可以是多个)
- 候选键:不含有多余属性的超键
- 主键:用户选作记录标识的候选键
这三个的关系,用数学关系可以做如下表示:
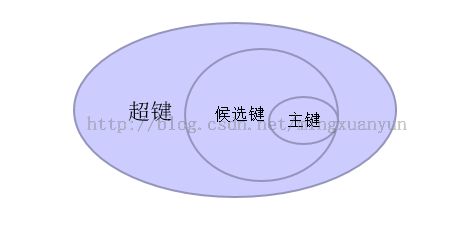
举例:一张学生信息表
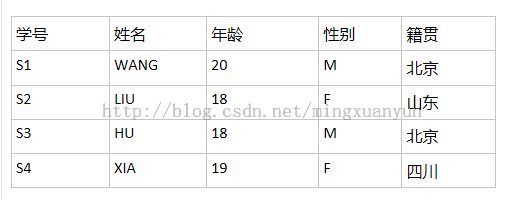
问:超键是?
答曰:学号唯一,是超键;姓名唯一,是超键;(学号,年龄)唯一,是超键;(学号、姓名、年龄)唯一,也是超键。
——从这里我们就可以看出,超键的组合是唯一的,但不可能是最小唯一的。
问:候选键是?
答曰:学号,唯一且没有多余的属性;姓名,唯一且没有多余的属性。
问:主键是?
答曰:既可以选择学号,也可以选择姓名(前提是规定没有重名的)作为主键,所以主键是选中的一个候选键。
数据库设计的目的主要是为了解决数据冗余,对数据进行有效的管理。那么引起数据冗余的主要原因是什么呢?答曰:数据依赖。什么是数据依赖?数据依赖是指在一个关系模式之间的依赖关系。其最典型的例子就是函数依赖。
二、函数依赖:若对于R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y],或者若r1[x]不等于r2[x],则r1[y]不等于r2[y],称X决定Y,或者Y依赖X。
通俗的说:就是我们知道一个之后可以推导出另外一个。
我们都知道,在数据库中,属性之间都是会发生联系。例如,每个学生只有一个姓名,每门课程只有一个任课教师,每个学生学一门课程只能有一个总评成绩。等等,这类联系,我们都可以将其称为函数依赖(FD),所以没必要把这概念弄的那么玄乎。
函数依赖包括以下三种类型:
1.平凡与非平凡依赖:
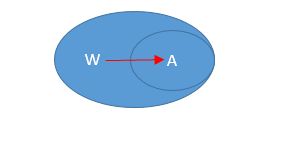
a.平凡依赖
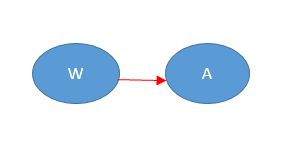
b.非平凡依赖
2.局部依赖与完全依赖:
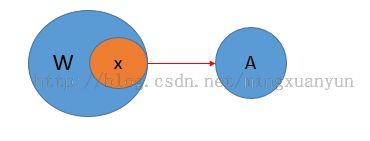
a局部依赖
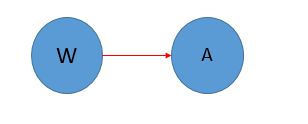
b.完全依赖
图上中:对于W—>A ,如果在X存在与W中,有X—>A成立,那么称W—>A是局部依赖,否则称W—>A是完全依赖。
3.传递依赖:
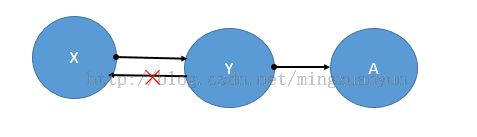
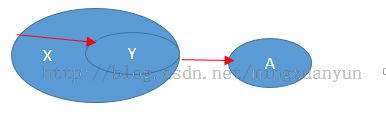
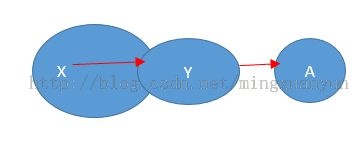
如图: X—>Y,Y—>A,且Y /> X和A不属于Y,那么称X—>A是传递依赖。
最后、三范式的理解:
第一范式:要求每个关系的属性为原子性,不可再分。(能分就分,分到不能再分为止!)
例如:R(学号,姓名,性别)
第二范式:主要是消除局部依赖
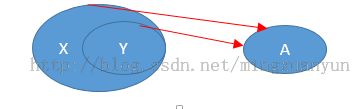
违反第二范式的局部依赖示意图:
例如:有关系模式为:R(学号、课程编号、成绩、教师号、教师职称)等。
R上有两个FD:(学号,课程号)—>(教师号,教师职称)和 课程编号—>(教师工号,教师职称)。由此,可得出前面一个是局部依赖。所以R关系模式不是第二范式模式。此时R的关系就会出现冗余和异常现象。例如,如果一门课程有10个学生选修,那么在关系中就存有10条记录,教师工号和职称也会重复10次。
解决方案:将R分解成R1(课程编号,教师号,教师职称)和R2(学号,课程号,成绩)。此时,R1和R2都是第二范式模式。
第三范式:主要是消除传递依赖
(1)
(2)
(3)

违反3NF的三种传递依赖情示意图
例如:R(课程编号,教师工号,教师职称)关系模式中,如果课程编号—>教师工号,教师工号—>教师职称,那么课程编号—>教师职称就是一个传递依赖。所以不是第三范式。此时R就会出现冗余和异常操作。例如,一个教师开设五门课程,那么关系中就会出现五条记录,教师职称就会重复五次。
解决方案:把R分解为R1(教师工号,教师职称)和R2(课程编号,教师工号)
我们在学习的过程当中,第一次可能只是懵懵懂懂,这很正常。所以不要觉得有什么?放宽心态,踏实的往下学就可以了。随着再往后的学习中,我们会对前面的学习进行一个不断反复的过程,但那时候我们可以在前面的基础上,对他们进行深入的研究。