QT中QThread的各个方法,UI线程关系,事件关系详解(1)
两种QThread类的详细使用方式
Qt提供QThread类以进行多任务处理。与多任务处理一样,Qt提供的线程可以做到单个线程做不到的事情。例如,网络应用程序中,可以使用线程处理多种连接器。
QThread继承自QObject类,且提供QMutex类以实现同步。线程和进程共享全局变量,可以使用互斥体对改变后的全局变量值实现同步。因此,必须编辑全局数据时,使用互斥体实现同步,其它进程则不能改变或浏览全局变量值。
什么是互斥体?
互斥体实现了“互相排斥”(mutual exclusion)同步的简单形式(所以名为互斥体(mutex))。互斥体禁止多个线程同时进入受保护的代码“临界区”(critical section)。
在任意时刻,只有一个线程被允许进入代码保护区。任何线程在进入临界区之前,必须获取(acquire)与此区域相关联的互斥体的所有权。如果已有另一线程拥有了临界区的互斥体,其他线程就不能再进入其中。这些线程必须等待,直到当前的属主线程释放(release)该互斥体。
什么时候需要使用互斥体呢?
互斥体用于保护共享的易变代码,也就是,全局或静态数据。这样的数据必须通过互斥体进行保护,以防止它们在多个线程同时访问时损坏。
Qt线程基础
QThread的创建和启动
class MyThread : public QThread
{
Q_OBJECT
protected:
void run();
};
void MyThread :: run(){
...
}
如上述代码所示,如果要创建线程,则必须继承QThread类。MyThread使用成员函数run()才会实现线程。
Qt提供的线程类
Qt提供的线程类
线程类 说明
QAtomicInt 提供了Integer上与平台无关的Qtomic运算
QAtomicPointer 提供了指针上Atomic运算的模板函数
QFuture 显示异步运算结果的类
QFutureSynchronizer QFuture类简化同步而提供的类
QFutureWatcher 使用信号和槽,允许QFuture监听
QMutex 访问类之间的同步
QMutecLocker 简化Lock和Unlock Mutex的类
QReadWriteLock 控制读写操作的类
QReadLocker 为了读访问而提供的
QWriteLocker 为了写访问而提供的
QRunnable 正在运行的所有对象的父类,且定义了虚函数run()
QSemaphore 一般的Count互斥体类
QThread 提供与平台无关的线程功能的类
QThreadPool 管理线程的类
QThreadStorage 提供每个线程存储区域的类
QWaitCondition 确认线程间同步的类的状态值
同步QThread的类
为了同步线程,Qt提供了QMutex、QReadWriteLock、QSemaphore和QWaitCondition类。主线程等待与其他线程的中断时,必须进行同步。例如:两个线程同时访问共享变量,那么可能得不到预想的结果。因此,两个线程访问共享变量时,必须进行同步。
一个线程访问指定的共享变量时,为了禁止其他线程访问,QMutex提供了类似锁定装置的功能。互斥体激活状态下,线程不能同时访问共享变量,必须在先访问的线程完成访问后,其他线程才可以继续访问。
一个线程访问互斥体锁定的共享变量期间,如果其他线程也访问此共享变量,那么该线程将会一直处于休眠状态,直到正在访问的线程结束访问。这称为线程安全。
QReadWriteLock和QMutex的功能相同,区别在于,QReadWriteLock对数据的访问分为读访问和写访问。很多线程频繁访问共享变量时,与QMetex相对,使用QReadWriteLock更合适。
QSemaphore拥有和QMutex一样的同步功能,可以管理多个按数字识别的资源。QMutex只能管理一个资源,但如果使用QSemaphore,则可以管理多个按号码识别的资源。
条件符合时,QWaitCondition允许唤醒线程。例如,多个线程中某个线程被阻塞时,通过QWaitCondition提供的函数wakeOne()和wakeAll()可以唤醒该线程。
可重入性与线程安全
可重入性:两个以上线程并行访问时,即使不按照调用顺序重叠运行代码,也必须保证结果;
线程安全:线程并行运行的情况下,虽然保证可以使程序正常运行,但访问静态空间或共享(堆等内存对象)对象时,要使用互斥体等机制保证结果。
一个线程安全的函数不一定是可重入的;一个可重入的函数缺也不一定是线程安全的!
可重入函数主要用于多任务环境中,一个可重入的函数简单来说就是可以被中断的函数,也就是说,可以在这个函数执行的任何时刻中断它,转入OS调度下去执行另外一段代码,而返回控制时不会出现什么错误;而不可重入的函数由于使用了一些系统资源,比如全局变量区,中断向量表等,所以它如果被中断的话,可能会出现问题,这类函数是不能运行在多任务环境下的。
编写可重入函数时,若使用全局变量,则应通过关中断、信号量(即P、V操作)等手段对其加以保护。若对所使用的全局变量不加以保护,则此函数就不具有可重入性,即当多个线程调用此函数时,很有可能使有关全局变量变为不可知状态。
满足下列条件的函数多数是不可重入的:
函数体内使用了静态的数据结构和全局变量,若必须访问全局变量,利用互斥信号量来保护全局变量;;
函数体内调用了malloc()或者free()函数;
函数体内调用了标准I/O函数。
常见的不可重入函数有:
printf --------引用全局变量stdout
malloc --------全局内存分配表
free --------全局内存分配表
也就是说:本质上,可重入性与C++类或者没有全局静态变量的函数相似,由于只能访问自身所有的数据变量区域,所以即使有两个以上线程访问,也可以保证安全性。
QThread和QObjects
QThread类继承自QObjects类。因此,线程开始或结束时,QThread类发生发送信号事件。信号与槽的功能是QThread类从QObject类继承的,可以通过信号与槽处理开始或结束等操作,所以可以实现多线程。QObject是基于QTimer、QTcpSocket、QUdpSocket和QProcess之类的非图形用户界面的子类。
基于非图形用户界面的子类可以无线程操作。单一类运行某功能时,可以不需要线程。但是,运行单一类的目标程序的上级功能时,则必须通过线程实现。
线程A和线程B没有结束的情况下,应设计使主线程时间循环不结束;而若线程A迟迟不结束而导致主线程循环也迟迟不能结束,故也要防止线程A没有在一定时间内结束。
处理QThread的信号和槽的类型
Qt提供了可以决定信号与槽类型的枚举类,以在线程环境中适当处理事物。
决定信号与槽类型的枚举类
常量 值 说明
Qt::AutoConnection 0 如果其他线程中发生信号,则会插入队列,像QueuedConnection一样,否则如DirectConnection一样,直接连接到槽。发送信号时决定Connection类型。
Qt::DirectConnection 1 发生信号事件后,槽立即响应
Qt::QueuedConnection 2 返回收到的线程事件循环时,发生槽事件。槽在收到的线程中运行
Qt::BlockingQueuedConnection 3 与QueuedConnection一样,返回槽时,线程被阻塞。建立在事件发生处使用该类型
使用QtConcurrent类的并行编程
QtConcurrent类提供多线程功能,不使用互斥体、读写锁、等待条件和信号量等低级线程。使用QtConcurrent创建的程序会根据进程数自行调整使用的线程数。
QThread类
简述
QThread类提供了与系统无关的线程。
QThread代表在程序中一个单独的线程控制。线程在run()中开始执行,默认情况下,run()通过调用exec()启动事件循环并在线程里运行一个Qt的事件循环。
详细描述
QThread类可以不受平台影响而实现线程。QThread提供在程序中可以控制和管理线程的多种成员函数和信号/槽。通过QThread类的成员函数start()启动线程。
QThread通过信号函数started()和finished()通知开始和结束,并查看线程状态;可以使用isFinished()和isRunning()来查询线程的状态;使用函数exit()和quit()可以结束线程。
如果使用多线程,有时需要等到所有线程终止。此时,使用函数wait()即可。线程中,使用成员函数sleep()、msleep()和usleep()可以暂停秒、毫秒及微秒单位的线程。
一般情况下,wait()和sleep()函数应该不需要,因为Qt是一个事件驱动型框架。考虑监听finished()信号来取代wait(),使用QTimer来取代sleep()。
静态函数currentThreadId()和currentThread()返回标识当前正在执行的线程。前者返回该线程平台特定的ID,后者返回一个线程指针。
要设置线程的名称,可以在启动线程之前调用setObjectName()。如果不调用setObjectName(),线程的名称将是线程对象的运行时类型(QThread子类的类名)。
线程管理
可以将常用的接口按照功能进行以下分类:
线程启动
void start(Priority priority = InheritPriority) [slot]
调用后会执行run()函数,但在run()函数执行前会发射信号started(),操作系统将根据优先级参数调度线程。如果线程已经在运行,那么这个函数什么也不做。优先级参数的效果取决于操作系统的调度策略。特别是那些不支持线程优先级的系统优先级将会被忽略(例如在Linux中,更多细节请参考http://linux.die.net/man/2/sched_setscheduler)。
线程执行
int exec() [protected]
进入事件循环并等待直到调用exit(),返回值是通过调用exit()来获得,如果调用成功则范围0。
void run() [virtual protected]
线程的起点,在调用start()之后,新创建的线程就会调用这个函数,默认实现调用exec(),大多数需要重新实现这个函数,便于管理自己的线程。该方法返回时,该线程的执行将结束。
线程退出
void quit() [slot]
告诉线程事件循环退出,返回0表示成功,相当于调用了QThread::exit(0)。
void exit(int returnCode = 0)
告诉线程事件循环退出。 调用这个函数后,线程离开事件循环后返回,QEventLoop::exec()返回returnCode,按照惯例,0表示成功;任何非0值表示失败。
void terminate() [slot]
终止线程,线程可能会立即被终止也可能不会,这取决于操作系统的调度策略,使用terminate()之后再使用QThread::wait(),以确保万无一失。当线程被终止后,所有等待中的线程将会被唤醒。
警告:此函数比较危险,不鼓励使用。线程可以在代码执行的任何点被终止。线程可能在更新数据时被终止,从而没有机会来清理自己,解锁等等。。。总之,只有在绝对必要时使用此函数。
void requestInterruption()
请求线程的中断。该请求是咨询意见并且取决于线程上运行的代码,来决定是否及如何执行这样的请求。此函数不停止线程上运行的任何事件循环,并且在任何情况下都不会终止它。
线程等待
void msleep(unsigned long msecs) [static] //强制当前线程睡眠msecs毫秒
void sleep(unsigned long secs) [static] //强制当前线程睡眠secs秒
void usleep(unsigned long usecs) [static] //强制当前线程睡眠usecs微秒
bool wait(unsigned long time = ULONG_MAX) //线程将会被阻塞,等待time毫秒。和sleep不同的是,如果线程退出,wait会返回。
线程状态
bool isFinished() const //线程是否结束
bool isRunning() const //线程是否正在运行
bool isInterruptionRequested() const //如果线程上的任务运行应该停止,返回true。可以使用requestInterruption()请求中断。
//此函数可用于使长时间运行的任务干净地中断。从不检查或作用于该函数返回值是安全的,但是建议在长时间运行的函数中经常这样做。注意:不要过于频繁调用,以保持较低的开销。
线程优先级
void setPriority(Priority priority)
设置正在运行线程的优先级。如果线程没有运行,此函数不执行任何操作并立即返回。使用的start()来启动一个线程具有特定的优先级。优先级参数可以是QThread::Priority枚举除InheritPriortyd的任何值。
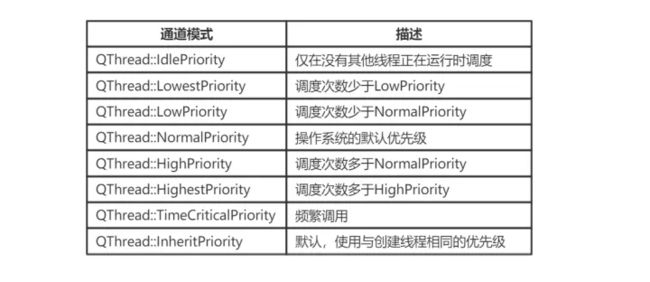
Qt多线程优先级
常量 值 优先级
QThread::IdlePriority 0 没有其它线程运行时才调度
QThread::LowestPriority 1 比LowPriority调度频率低
QThread::LowPriority 2 比NormalPriority调度频率低
QThread::NormalPriority 3 操作系统的默认优先级
QThread::HighPriority 4 比NormalPriority调度频繁
QThread::HighestPriority 5 比HighPriority调度频繁
QThread::TimeCriticalPriority 6 尽可能频繁的调度
QThread::InheritPriority 7 使用和创建线程同样的优先级. 这是默认值
QThread类使用方式
QThread的使用方法有如下两种:
QObject::moveToThread()
继承QThread类
QObject::moveToThread
方法描述:
定义一个继承于QObject的worker类,在worker类中定义一个槽slot函数doWork(),这个函数中定义线程需要做的工作;
在要使用线程的controller类中,新建一个QThread的对象和woker类对象,使用moveToThread()方法将worker对象的事件循环全部交由QThread对象处理;
建立相关的信号函数和槽函数进行连接,然后发出信号触发QThread的槽函数,使其执行工作。
例子:
#ifndef WORKER_H
#define WORKER_H
#include
#include
#include
class Worker:public QObject //work定义了线程要执行的工作
{
Q_OBJECT
public:
Worker(QObject* parent = nullptr){}
public slots:
void doWork(int parameter) //doWork定义了线程要执行的操作
{
qDebug()<<"receive the execute signal---------------------------------";
qDebug()<<" current thread ID:"<
{
++parameter;
}
qDebug()<<" finish the work and sent the resultReady signal\n";
emit resultReady(parameter); //emit啥事也不干,是给程序员看的,表示发出信号发出信号
}
signals:
void resultReady(const int result); //线程完成工作时发送的信号
};
#endif // WORKER_H
#ifndef CONTROLLER_H
#define CONTROLLER_H
#include
#include
#include
class Controller : public QObject //controller用于启动线程和处理线程执行结果
{
Q_OBJECT
QThread workerThread;
public:
Controller(QObject *parent= nullptr);
~Controller();
public slots:
void handleResults(const int rslt) //处理线程执行的结果
{
qDebug()<<"receive the resultReady signal---------------------------------";
qDebug()<<" current thread ID:"<
signals:
void operate(const int); //发送信号触发线程
};
#endif // CONTROLLER_H
#include "controller.h"
#include
Controller::Controller(QObject *parent) : QObject(parent)
{
Worker *worker = new Worker;
worker->moveToThread(&workerThread); //调用moveToThread将该任务交给workThread
connect(this, SIGNAL(operate(const int)), worker, SLOT(doWork(int))); //operate信号发射后启动线程工作
connect(&workerThread, &QThread::finished, worker, &QObject::deleteLater); //该线程结束时销毁
connect(worker, SIGNAL(resultReady(int)), this, SLOT(handleResults(int))); //线程结束后发送信号,对结果进行处理
workerThread.start(); //启动线程
qDebug()<<"emit the signal to execute!---------------------------------";
qDebug()<<" current thread ID:"<
}
Controller::~Controller() //析构函数中调用quit()函数结束线程
{
workerThread.quit();
workerThread.wait();
}
继承QThread类
方法描述
自定义一个继承QThread的类MyThread,重载MyThread中的run()函数,在run()函数中写入需要执行的工作;
调用start()函数来启动线程。
例子:
#ifndef MYTHREAD_H
#define MYTHREAD_H
#include
#include
class MyThread : public QThread
{
Q_OBJECT
public:
MyThread(QObject* parent = nullptr);
signals: //自定义发送的信号
void myThreadSignal(const int);
public slots: //自定义槽
void myThreadSlot(const int);
protected:
void run() override;
};
#endif // MYTHREAD_H
#include "mythread.h"
MyThread::MyThread(QObject *parent)
{
}
void MyThread::run()
{
qDebug()<<"myThread run() start to execute";
qDebug()<<" current thread ID:"<
for(int i = 0;i!=1000000;++i)
{
++count;
}
emit myThreadSignal(count);
exec();
}
void MyThread::myThreadSlot(const int val)
{
qDebug()<<"myThreadSlot() start to execute";
qDebug()<<" current thread ID:"<
for(int i = 0;i!=1000000;++i)
{
++count;
}
}
#include "controller.h"
#include
Controller::Controller(QObject *parent) : QObject(parent)
{
myThrd = new MyThread;
connect(myThrd,&MyThread::myThreadSignal,this,&Controller::handleResults);
connect(myThrd, &QThread::finished, this, &QObject::deleteLater); //该线程结束时销毁
connect(this,&Controller::operate,myThrd,&MyThread::myThreadSlot);
myThrd->start();
QThread::sleep(5);
emit operate(999);
}
Controller::~Controller()
{
myThrd->quit();
myThrd->wait();
}
两种方法的比较
两种方法来执行线程都可以,随便你的喜欢。不过看起来第二种更加简单,容易让人理解。不过我们的兴趣在于这两种使用方法到底有什么区别?其最大的区别在于:
moveToThread方法,是把我们需要的工作全部封装在一个类中,将每个任务定义为一个的槽函数,再建立触发这些槽的信号,然后把信号和槽连接起来,最后将这个类调用moveToThread方法交给一个QThread对象,再调用QThread的start()函数使其全权处理事件循环。于是,任何时候我们需要让线程执行某个任务,只需要发出对应的信号就可以。其优点是我们可以在一个worker类中定义很多个需要做的工作,然后发出触发的信号线程就可以执行。相比于子类化的QThread只能执行run()函数中的任务,moveToThread的方法中一个线程可以做很多不同的工作(只要发出任务的对应的信号即可)。
子类化QThread的方法,就是重写了QThread中的run()函数,在run()函数中定义了需要的工作。这样的结果是,我们自定义的子线程调用start()函数后,便开始执行run()函数。如果在自定义的线程类中定义相关槽函数,那么这些槽函数不会由子类化的QThread自身事件循环所执行,而是由该子线程的拥有者所在线程(一般都是主线程)来执行。如果你不明白的话,请看,第二个例子中,子类化的线程的槽函数中输出当前线程的ID,而这个ID居然是主线程的ID!!事实的确是如此,子类化的QThread只能执行run()函数中的任务直到run()函数退出,而它的槽函数根本不会被自己的线程执行。
QThread的信号与槽
启动或终止线程时,QThread提供了信号与槽。
QThread的信号
信号 含义
void finished() 终止线程实例运行,发送信号
void started() 启动线程实例,发送信号
void terminated() 结束线程实例,则发送信号
QThread的槽
槽 含义
void quit() 线程终止运行槽
void start(Priority) 线程启动槽
void terminate() 线程结束槽
/***********************************************************************************
子线程在start()后,距离处理事件还得稍等片刻。
qthread::start();//执行run(),run()里面如果有exec()结尾,可进入事件循环。
qthread::msleep(100);//确保子线程准备好。
emit_signal();//触发子线程的槽函数。
/************************************************************************************
- 概述
- 优雅的开始我们的多线程编程之旅
- 我们该把耗时代码放在哪里?
- 再谈 moveToThread()
- 启动线程前的准备工作
- 开多少个线程比较合适?
- 设置栈大小
- 启动线程/退出线程
- 启动线程
- 优雅的退出线程
- 操作运行中的线程
- 获取状态
- 运行状态
- 线程标识
- 更为精细的事件处理
- 操作线程
- 安全退出线程必备函数:wait()
- 线程间的礼让行为
- 线程的中断标志位
- 获取状态
- 为每个线程提供独立数据
- 附:所有函数
1. 概述
在阅读本文之前,你需要了解进程和线程相关的知识,详情参考《Qt 中的多线程技术》。
在很多文章中,人们倾向于把 QThread 当成线程的实体,区区创建一个 QThread 类对象就被认为是开了一个新线程。当然这种讨巧的看法似乎能快速的让我们入门,但是只要深入多线程编程领域后就会发现这种看法越来越站不住脚,甚至编写的代码脱离我们的控制,代码越写越复杂。最典型的问题就是“明明把耗时操作代码放入了新线程,可实际仍在旧线程中运行”。造成这种情况的根源在于继承 QThread 类,并在 run() 函数中塞入耗时操作代码。
追溯历史,在 Qt 4.4 版本以前的 QThread 类是个抽象类,要想编写多线程代码唯一的做法就是继承 QThread 类。但是之后的版本中,Qt 库完善了线程的亲和性以及信号槽机制,我们有了更为优雅的使用线程的方式,即 QObject::moveToThread()。这也是官方推荐的做法,遗憾的是网上大部分教程没有跟上技术的进步,依然采用 run() 这种腐朽的方式来编写多线程程序。
2. 优雅的开始我们的多线程编程之旅
在 Qt 4.4 版本后,之所以 Qt 官方对 QThread 类进行了大刀阔斧地改革,我认为这是想让多线程编程更加符合 C++ 语言的「面向对象」特性。继承的本意是扩展基类的功能,所以继承 QThread 并把耗时操作代码塞入 run() 函数中的做法怎么看都感觉不伦不类。
2.1 我们该把耗时代码放在哪里?
暂时不考虑多线程,先思考这样一个问题:想想我们平时会把耗时操作代码放在哪里?一个类中。那么有了多线程后,难道我们要把这段代码从类中剥离出来单独放到某个地方吗?显然这是很糟糕的做法。QObject 中的 moveToThread() 函数可以在不破坏类结构的前提下依然可以在新线程中运行。

假设现在我们有个 QObject 的子类 Worker,这个类有个成员函数 doSomething(),该函数中运行的代码非常耗时。此时我要做的就是将这个类对象“移动”到新线程里,这样 Worker 的所有成员函数就可以在新线程中运行了。那么如何触发这些函数的运行呢?信号槽。在主线程里需要有个 signal 信号来关联并触发 Worker 的成员函数,与此同时 Worker 类中也应该有个 signal 信号用于向外界发送运行的结果。这样思路就清晰了,Worker 类需要有个槽函数用于执行外界的命令,还需要有个信号来向外界发送结果。如下列代码:
// Worker.h
#ifndef WORKER_H
#define WORKER_H
#include
class Worker : public QObject
{
Q_OBJECT
public:
explicit Worker(QObject *parent = nullptr);
signals:
void resultReady(const QString &str); // 向外界发送结果
public slots:
void on_doSomething(); // 耗时操作
};
#endif // WORKER_H
// Worker.cpp
#include "worker.h"
#include
#include
Worker::Worker(QObject *parent) : QObject(parent)
{
}
void Worker::on_doSomething()
{
qDebug() << "I'm working in thread:" << QThread::currentThreadId();
emit resultReady("Hello");
}
在 Worker 类中,总共也就两个成员:on_doSomething() 槽函数被外界触发来执行耗时操作,操作的结果用 resultReady() 信号发射出去,我们这里将“Hello”字符串作为结果发射出去。为了体现是在不同线程中执行的,我们在 on_doSomething() 槽函数中打印当前线程 ID。
// Controller.h
#ifndef CONTROLLER_H
#define CONTROLLER_H
#include
#include
#include "worker.h"
class Controller : public QObject
{
Q_OBJECT
public:
explicit Controller(QObject *parent = nullptr);
~Controller();
void start();
signals:
void startRunning(); // 用于触发新线程中的耗时操作函数
public slots:
void on_receivResult(const QString &str); // 接收新线程中的结果
private:
QThread m_workThread;
Worker *m_worker;
};
#endif // CONTROLLER_H
在作为“外界”的 Controller 类中,由于要发送命令与接收结果,因此同样是有两个成员:startRunning() 信号用于启动 Worker 类的耗时函数运行,on_receivResult() 槽函数用于接收新线程的运行结果。注意别和 Worker 类的两个成员搞混了,在本例中信号对应着槽,即“外界”的信号触发“新线程”的槽,“外界”的槽接收“新线程”的信号结果。
// Controller.cpp
#include "controller.h"
#include
#include
Controller::Controller(QObject *parent) : QObject(parent)
{
qDebug() << "Controller's thread is :" << QThread::currentThreadId();
m_worker = new Worker();
m_worker->moveToThread(&m_workThread);
connect(this, &Controller::startRunning, m_worker, &Worker::on_doSomething);
connect(&m_workThread, &QThread::finished, m_worker, &QObject::deleteLater);
connect(m_worker, &Worker::resultReady, this, &Controller::on_receivResult);
m_workThread.start();
}
Controller::~Controller()
{
m_workThread.quit();
m_workThread.wait();
}
void Controller::start()
{
emit startRunning();
}
void Controller::on_receivResult(const QString &str)
{
qDebug() << str;
}
在 Controller 类的实现里,首先实例化一个 Worker 对象并把它“移动”到新线程中,然后就是在新线程启动前将双方的信号槽连接起来。同 Worker 类一样,为了体现是在不同线程中执行的,我们在构造函数中打印当前线程 ID。
// main.cpp
#include
#include
#include
#include "controller.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
qDebug() << "The main threadID is :" << QThread::currentThreadId();
Controller controller;
controller.start();
return a.exec();
}
在 main.cpp 中我们实例化一个 Controller 对象,并运行 start() 成员函数发射出信号来触发 Worker 类的耗时操作函数。来看看运行结果:

从结果可以看出,Worker 类对象的成员函数是在新线程中运行的。而 Controller 对象是在主线程中被创建,因此它就隶属于主线程。
2.2 再谈 moveToThread()
“移动到新线程”是一个很形象的描述,作为入门的认知是可以的,但是它的本质是改变线程亲和性(也叫关联性)。为什么要强调这一点?这是因为如果你天真的认为 Worker 类对象整体都移动到新线程中去了,那么你就会本能的认为 Worker 类对象的控制权是由新线程所属,然而事实并不是如此。「在哪创建就属于哪」这句话放在任何地方都是适用的。比如上一节的例子中,Worker 类对象是在 Controller 类中创建并初始化,因此该对象是属于主线程的。而 moveToThread() 函数的作用是将槽函数在指定的线程中被调用。当然,在新线程中调用函数的前提是该线程已经启动处于就绪状态,所以在上一节的 Controller 构造函数中,我们把各种信号槽连接起来后就可以启动新线程了。
使用 moveToThread() 有一些需要注意的地方,首先就是类对象不能有父对象,否则无法将该对象“移动”到新线程。如果类对象保存在栈上,自然销毁由操作系统自动完成;如果是保存在堆上,没有父对象的指针要想正常销毁,需要将线程的 finished() 信号关联到 QObject 的 deleteLater() 让其在正确的时机被销毁。其次是该对象一旦“移动”到新线程,那么该对象中的计时器(如果有 QTimer 等计时器成员变量)将重新启动。不是所有的场景都会遇到这两种情况,但是记住这两个行为特征可以避免踩坑。
3. 启动线程前的准备工作
3.1 开多少个线程比较合适?
说“开线程”其实是不准确的,这种事儿只有操作系统才能做,我们所能做的是管理其中一个线程。无论是 QThread thread 还是 QThread *thread,创建出来的对象仅仅是作为操作系统线程的接口,用这个接口可以对线程进行一些操作。虽然这样说不准确,但下文我们仍以“开线程”的说法,只是为了表述方便。作为入门教程,能在主线程之外“开”一个线程就已经够了,那么讲解“开”多个线程的内容实在没有必要。本节的目的是想在叩开多线程大门的同时能向里望一望多线程领域的世界,就当是抛砖引玉吧。

我们来思考这样一个问题:“线程数是不是越大越好”?显然不是,“开”一千个线程是没有意义的。根据《Qt 中的多线程技术》中所讲的,线程的切换是要消耗系统资源的,频繁的切换线程会使性能降低。线程太少的话又不能完全发挥 CPU 的性能。一般后端服务器都会设置最大工作线程数,不同的架构师有着不同的经验,有些业务设置为 CPU 逻辑核心数的4倍,有的甚至达到32倍。如上图所示,Chrome 浏览器运行时就开了36个线程。
So, the minimum number of threads is equal to the number of available cores. If all tasks are computation intensive, then this is all we need. Having more threads will actually hurt in this case because cores would be context switching between threads when there is still work to do. If tasks are IO intensive, then we should have more threads.
When a task performs an IO operation, its thread gets blocked. The processor immediately context switches to run other eligible threads. If we had only as many threads as the number of available cores, even though we have tasks to perform, they can't run because we haven't scheduled them on threads for the processors to pick up.
If tasks spend 50 percent of the time being blocked, then the number of threads should be twice the number of available cores. If they spend less time being blocked—that is, they're computation intensive—then we should have fewer threads but no less than the number of cores. If they spend more time being blocked—that is, they're IO intensive—then we should have more threads, specifically, several multiples of the number of cores.
So, we can compute the total number of threads we'd need as follows:
Number of threads = Number of Available Cores / (1 - Blocking Coefficient)
在 Venkat Subramaniam 博士的《Programming Concurrency on the JVM》这本书中提到关于最优线程数的计算,即线程数量 = 可用核心数/(1 - 阻塞系数)。可用核心数就是所有逻辑 CPU 的总数,这可以用 QThread::idealThreadCount() 静态函数获取,比如双核四线程的 CPU 的返回值就是4。但是阻塞系数比较难计算,这需要用一些性能分析工具来辅助计算。如果只是粗浅的计算下线程数,最简单的办法就是 CPU 核心数 * 2 + 2。更为精细的找到最优线程数需要不断的调整线程数量来观察系统的负载情况。
3.2 设置栈大小
根据《Qt 中的多线程技术》所述,线程“与进程内的其他线程一起共享这片地址空间,基本上就可以利用进程所拥有的资源而无需调用新的资源”,这里所指的资源之一就是堆栈空间。每个线程都有自己的栈,彼此独立,由编译器分配。一般在 Windows 的栈大小为2M,在 Linux 下是8M。
Qt 提供了获取以及设置栈空间大小的函数:stackSize()、setStackSize(uint stackSize)。其中 stackSize() 函数不是返回当前所在线程的栈大小,而是获取用 stackSize() 函数手动设置的栈大小。如果是用编译器默认的栈大小,该函数返回0,这一点需要注意。为什么要设置栈的大小?这是因为有时候我们的局部变量很大(常见于数组),当超过编译器默认大小时程序就会因为栈溢出而报错,这时候就需要手动设置栈大小了。

以上文「2.1 我们该把耗时代码放在哪里?」中的代码为例,在 Linux 操作系统环境下,假如我们在 on_doSomething() 函数中添加一个9M大小的数组 array,可以看出在程序运行时会由于栈溢出而导致异常退出,因为 Linux 默认的栈空间仅为8M。

如果我们设置了栈大小为10m,那么程序会正常运行,不会出现栈溢出的问题。
4. 启动线程/退出线程
4.1 启动线程
调用 start() 函数就可以启动函数在新线程中运行,运行后会发出 started() 信号。
在「1.概述」中我们知道将耗时函数放入新线程有 moveToThread() 和继承 QThread 且重新实现 run() 函数两种方式。有这么一种情况:此时我有 fun1() 和 fun2() 两个耗时函数,将 fun1() 中的代码放入 run() 函数,而将 fun2() 以 moveToThread() 的方式也放到这个线程中。那新线程该运行哪个函数呢?其实调用 start() 函数后,新线程会优先执行 run() 中的代码,即先执行 fun1() 函数,其次才会运行 fun2() 函数。这种情况不常见,但了解这种先后顺序有助于我们理解 start() 函数。
说到 run() 函数就不得不提 exec() 函数。这是个 protected 函数,因此只能在类内使用。默认 run() 函数会调用 exec() 函数,即启用一个局部的不占 CPU 的事件循环。为什么要默认启动个事件循环呢?这是因为没有事件循环的话,耗时代码只要执行完线程就会退出,频繁的开销线程显然很浪费资源。因此,如果使用上述第二种“开线程”的方式,别忘了在 run() 函数中调用 exec() 函数。
4.2 优雅的退出线程
退出线程可是个技术活,不是随随便便就可以退出。比如我们关闭主进程的同时,里面的线程可能还处在运行状态,尤其线程上跑着耗时操作。这时候你可以用 terminate() 函数强制终止线程,调用该函数后所有处于等待状态的线程都会被唤醒。该函数是异步的,也就是说调用该函数后虽然获得了返回值,但此时线程依然可能在运行。因此,一般是在后面跟上 wait() 函数来保证线程已退出。当然强制是很暴力的行为,有可能会造成局部变量得不到清理,或者无法解锁互斥关系,种种行为都是很危险的,除非必要时才会使用该函数。
上文「4.1 启动线程」结尾提到“默认 run() 函数会调用 exec() 函数”,耗时操作代码执行完后,线程由于启动了事件循环是不退出的。所以,正常的退出线程其实质是退出事件循环,即执行 exit(int returnCode = 0) 函数。返回0代表成功,其他非零值代表异常。quit() 函数等价于 exit(0)。线程退出后会发出 finished() 信号。
5. 操作运行中的线程
5.1 获取状态
(1)运行状态
根据《Qt 中的多线程技术》中的「1.3 线程的生命周期」所述,线程的状态有很多种,而往往我们只关心一个线程是运行中还是已经结束。QThread 提供了 isRunning()、isFinished() 两个函数来判断当前线程的运行状态。
(2)线程标识
Returns the thread handle of the currently executing thread.
Warning: The handle returned by this function is used for internal purposes and should not be used in any application code.
Note: On Windows, this function returns the DWORD (Windows-Thread ID) returned by the Win32 function GetCurrentThreadId(), not the pseudo-HANDLE (Windows-Thread HANDLE) returned by the Win32 function GetCurrentThread().
关于 currentThreadId() 函数,很多人将该函数用于输出线程ID,这是错误的用法。该函数主要用于 Qt 内部,不应该出现在我们的代码中。那为什么还要开放这个接口?这是因为我们有时候想和系统线程进行交互,而不同平台下的线程 ID 表示方式不同。因此调用该函数返回的 Qt::HANDLE 类型数据并转化成对应平台的线程 ID 号数据类型(例如 Windows 下是 DWORD 类型),利用这个转化后的 ID 号就可以与系统开放出来的线程进行交互了。当然,这就破坏了移植性了。
需要注意的是,这个 Qt::HANDLE 是 ID 号而不是句柄。句柄相当于对象指针,一个线程可以被多个对象所操控,而每个线程只有一个全局线程 ID 号。正确的获取线程 ID 做法是:调用操作系统的线程接口来获取。以下是不同平台下获取线程 ID 的代码:
#include
#include
#ifdef Q_OS_LINUX
#include
#endif
#ifdef Q_OS_WIN
#include
#endif
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
#ifdef Q_OS_LINUX
qDebug() << pthread_self();
#endif
#ifdef Q_OS_WIN
qDebug() << GetCurrentThreadId();
#endif
return a.exec();
}
我们自己的程序内部可以调用 currentThread() 函数来获取 QThread 指针,有了线程指针就可以对线程进行一些操作了。
3)更为精细的事件处理
在《Qt 中的事件系统 - 有什么难的呢?》一文中我们提到事件的整个运行流程,文中所提及的 QCoreApplication::processEvents() 等传递事件方法其实是很简单的,但如果再深入下去就无能为力了。Qt 提供了 QAbstractEventDispatcher 类用于更为精细的事件处理,该类精细到可以管理 Qt 事件队列,即接收到事件(来自操作系统或者 Qt 写的程序)后负责发送到 QCoreApplication 或者 QApplication 实例以进行处理。而文中讲的是从 QCoreApplication 接收到事件开始,再往后的事情了。
线程既然可以开启事件循环,那么就可以调用 eventDispatcher()、setEventDispatcher() 函数来设置和获取事件调度对象,然后对事件进行更为精细的操作。
除此以外,loopLevel() 函数可以获取有多少个事件循环在线程中运行。正如下文所说,这个函数本来在 Qt 4 中被删除了,但是对于那些想知道有多少事件循环的人来说该函数还是有用的。所以在 Qt 5 中又加了进来。
This function used to reside in QEventLoop in Qt 3 and was deprecated in Qt 4. However this is useful for those who want to know how many event loops are running within the thread so we just make it possible to get at the already available variable.
5.2 操作线程
(1)安全退出线程必备函数:wait(unsigned long time = ULONG_MAX)
在本文「4.2 优雅的退出线程」中已经提到“一般是在后面跟上 wait() 函数来保证线程已退出”,线程退出的时候不要那么暴力,告诉操作系统要退出的线程后,给点时间(即阻塞)让线程处理完。也可以设置超时时间 time,时间一到就强制退出线程。一般在类的析构函数中调用,正如本文开头「2.1 我们该把耗时代码放在哪里?」的示例代码那样:
Controller::~Controller()
{
m_workThread.quit();
m_workThread.wait();
}
(2)线程间的礼让行为
这是个很有意思的话题,一般我们都希望每个线程都能最大限度的榨干系统资源,何来礼让之说呢?有时候我们采用多线程并不只是运行耗时代码,而是和主 GUI 线程分开,避免主界面卡死的情况发生。那么有些线程上跑的任务可能对实时性要求不高,这时候适当的缩短被 CPU 选中的机会可以节约出系统资源。
除了调用 setPriority()、priority() 优先级相关的函数以外,QThread 类还提供了 yieldCurrentThread() 静态函数,该函数是在通知操作系统“我这个线程不重要,优先处理其他线程吧”。当然,调用该函数后不会立马将 CPU 计算资源交出去,而是由操作系统决定。
QThread 类还提供了 sleep()、msleep()、usleep() 这三个函数,这三个函数也是在通知操作系统“在未来 time 时间内我不参与 CPU 计算”。从我们直观的角度看,就好像当前线程“沉睡”了一段时间。
(3)线程的中断标志位
Qt 为每一个线程都设置了一个布尔变量用来标记当前线程的终端状态,用 isInterruptionRequested() 函数来获取,用 requestInterruption() 函数来设置中断标记。这个标记不是给操作系统看的,而是给用户写的代码中进行判断。也就是说调用 requestInterruption() 函数并不能中断线程,需要我们自己的代码去判断。这有什么用处呢?
while (ture) {
if (!isInterruptionRequested()) {
// 耗时操作
......
}
}
这种设计可以让我们自助的中断线程,而不是由操作系统强制中断。经常我们会在新线程上运行无限循环的代码,在代码中加上判断中断标志位可以让我们随时跳出循环。好处就是给了我们程序更大的灵活性。
6. 为每个线程提供独立数据
思考这样一个问题,如果线程本身存在全局变量,那么修改一处后另一个线程会不会受影响?我们以一段代码为例:
// main.cpp
#include
#include "workthread.h"
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
WorkThread thread1;
WorkThread thread2;
thread1.start();
thread2.start();
return a.exec();
}
// WorkThread.h
#ifndef WORKTHREAD_H
#define WORKTHREAD_H
#include
class WorkThread : public QThread
{
public:
WorkThread();
protected:
virtual void run() override;
};
#endif
// WorkThread.cpp
#include "workthread.h"
#include
#include
WorkThread::WorkThread()
{
}
quint64 g_value1 = 0;
void WorkThread::run()
{
g_value1 = quint64(currentThreadId());
qDebug() << g_value1;
}
我们继承 QThread 类并重写 run() 函数,函数中的全局变量 g_value1 由线程 ID 赋值。实例化出两个线程对象并均启动。其结果输出如下:

可以看到两个输出的结果是一样的,这并非是同一个线程输出两次,而是线程 thread1 对全局变量的修改影响了线程 thread2。造成这个现象的原因也很好理解,根据《Qt 中的多线程技术》中的「1.2 多核CPU」所述,“线程隶属于某一个进程,与进程内的其他线程一起共享这片地址空间”。也就是说全局变量属于公共资源,被所有线程所共享,只要一个线程修改了这个全局变量自然就会影响其他线程对该全局变量的访问。
而 QThreadStorage 类为每个线程提供了独立的数据存储功能,即使在线程中用到全局变量,只要存在 QThreadStorage 中,也不会影响到其他线程。我们对上面的 workthread.cpp 进行稍加修改,从结果来看,每个线程都有属于各自的全局变量,而互不影响。如下图所示:

需要注意的是,QThreadStorage 的析构函数并不会删除所储存的数据,只有线程退出才会被删除。
附:所有函数
- 启动前的准备工作
- 构造函数:QThread(QObject *parent = nullptr)
- 系统理想的线程数量:[static]int idealThreadCount()
- 堆栈大小
- 获取:uint stackSize() const
- 设置:void setStackSize(uint stackSize)
- 启动/退出
- 启动
- 执行:[slots]void start(QThread::Priority priority = InheritPriority)
- 信号:void started()
- 事件循环:[protected]int exec()
- 退出
- 执行
- void exit(int returnCode = 0)
- [slots]void quit()
- 信号:void finished()
- 强制中止[不常用]
- [slots]void terminate()
- [static protected]void setTerminationEnabled(bool enabled = true)
- 执行
- 启动
- 运行中
- 状态获取
- 是否运行
- bool isRunning() const
- bool isFinished() const
- 标识:
- 当前线程:[static]QThread * currentThread()
- 线程ID:[static]Qt::HANDLE currentThreadId()
- 更为精细的事件管理
- 获取:QAbstractEventDispatcher * eventDispatcher() const
- 设置:void setEventDispatcher(QAbstractEventDispatcher *eventDispatcher)
- 循环级别:int loopLevel() const
- 是否运行
- 行为
- 阻塞:bool wait(unsigned long time = ULONG_MAX)
- 线程之间的礼让
- 优先级
- 获取:QThread::Priority priority() const
- 设置:void setPriority(QThread::Priority priority)
- 切换线程:[static]void yieldCurrentThread()
- 睡眠
- [static]void sleep(unsigned long secs) const
- [static]void msleep(unsigned long msecs)
- [static]void usleep(unsigned long usecs)
- 优先级
- 请求中断
- 判断:bool isInterruptionRequested() const
- 执行:void requestInterruption()
- 状态获取
- 其他(仅支持C++17)
- [static]QThread * create(Function &&f, Args &&... args)
- [static]QThread * create(Function &&f)