音视频基础——音频基础知识
爱情只有落实到穿衣、吃饭、数钱、睡觉,这些实实在在的小事上,才可以长久
一、声音的三要素
1. 音调
人耳对声音高低的感觉称为音调(也叫音频)。音调主要与声波的频率有关。声波的频率高,则音调也高。当我们分别敲击一个小鼓和一个大鼓时,会感觉它们所发出的声音不同。小鼓被敲击后振动频率快,发出的声音比较清脆,即音调较高;而大鼓被敲击后振动频率较慢,发出的声音比较低沉,即音调较低。一般音频 儿童>女生>男生。
人耳听觉音频范围是20Hz-20000Hz(做音频压缩时不在这个范围内的数据就可以砍掉)。
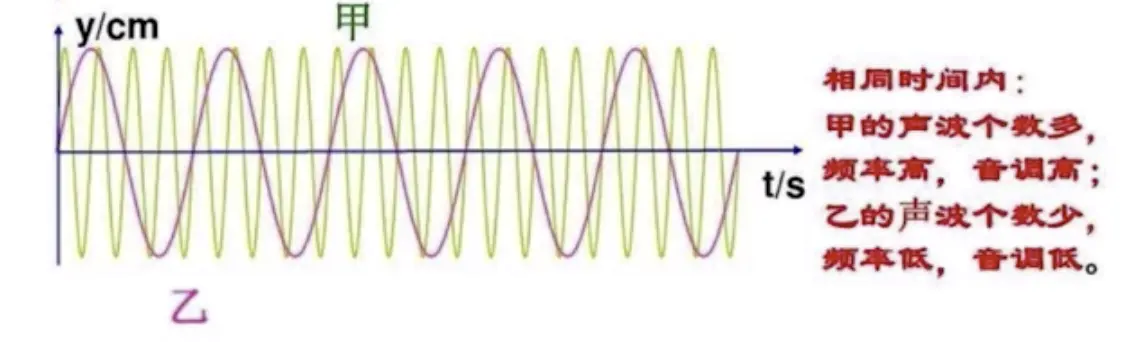
2. 音量
也就是响度。人耳对声音强弱的主观感觉称为响度。响度和声波振动的幅度有关。一般说来,声波振动幅度越大则响度也越大。当我们用较大的力量敲鼓时,鼓膜振动的幅度大,发出的声音响;轻轻敲鼓时,鼓膜振动的幅度小,发出的声音弱。
另外,人们对响度的感觉还和声波的频率有关,同样强度的声波,如果其频率不同,人耳感觉到的响度也不同。
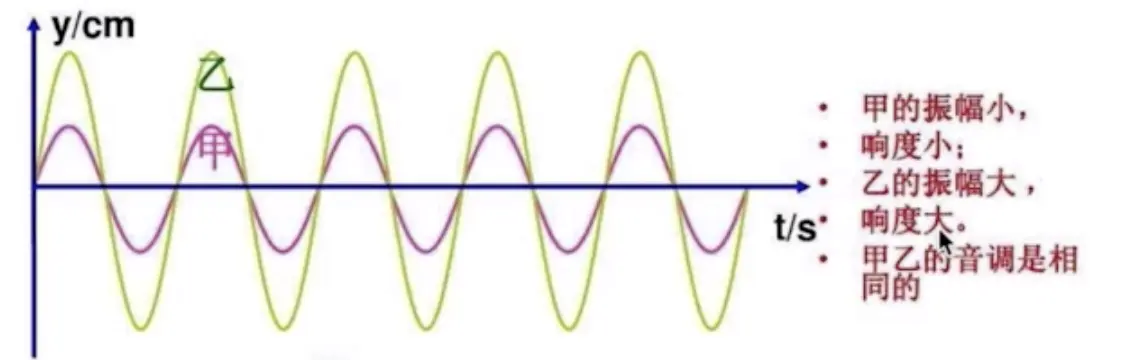
3. 音色
也就是音品。音色是人们区别具有同样响度、同样音调的两个声音之所以不同的特性,或者说是人耳对各种频率、各种强度的声波的综合反应。音色与声波的振动波形有关,或者说与声音的频谱结构有关。
音叉可产生一个单一频率的声波,其波形为正弦波。但实际上人们在自然界中听到的绝大部分声音都具有非常复杂的波形,这些波形由基波和多种谐波构成。谐波的多少和强弱构成了不同的音色。各种发声物体在发出同一音调声音时,其基波成分相同。但由于谐波的多少不同,并且各谐波的幅度各异,因而产生了不同的音色。
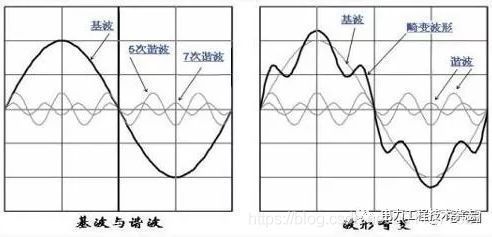
二、音频的量化与编码
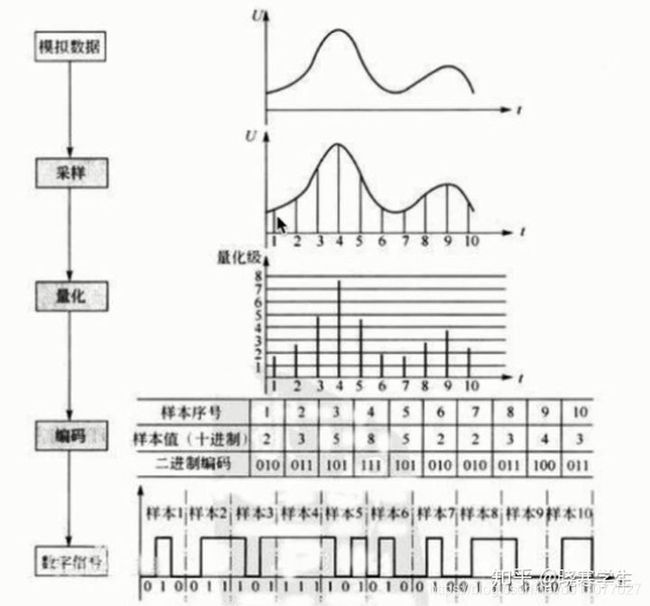
1.音频的量化过程
现实生活中,我们听到的声音都是时间连续的,我们把这种信号叫模拟信号。模拟信号(连续信号)需要量化成数字信号(离散的、不连续的信号)以后才能在计算机中使用。如下图所示量化过程分为5个步骤:
1.1 模拟信号
现实生活中的声音表现为连续的、平滑的波形,其横坐标为时间轴,纵坐标表示声音的强弱。
1.2 采样
按照一定的时间间隔在连续的波上进行采样取值,如下图所示取了10个样。
实现这个步骤使用的设备是模/数转换器(A/D转换器,或者ADC,或者analog to digital convert)采样率决定声音频率的范围(相当于音调)
1.3 量化
将采样得到的值进行量化处理,也就是给纵坐标定一个刻度,记录下每个采样的纵坐标的值。
1.4 编码
将每个量化后的样本值转换成二进制编码。
1.5 数字信号
将所有样本二进制编码连起来存储在计算机上就形成了数字信号。
2.量化的基本概念
2.1 采样大小
又叫采样位数(采样精度),一个采样用多少个bit存放,常用的是16bit(这就意味着上述的量化过程中,纵坐标的取值范围是0-65535,声音是没有负值的)。
2.2 采样率
也就是采样频率(1秒采样次数),一般采样率有8kHz、16kHz、32kHz、44.1kHz、48kHz等,采样频率越高,声音的还原就越真实越自然,当然数据量就越大。
模拟信号中,人类听觉范围是20-20000Hz,如果按照44.1kHz的频率进行采样,对20HZ音频进行采样,一个正弦波采样2200次;对20000HZ音频进行采样,平均一个正弦波采样2.2次。
5kHz的采样率仅能达到人们讲话的声音质量。
11kHz的采样率是播放小段声音的最低标准,是CD音质的四分之一。
22kHz采样率的声音可以达到CD音质的一半,目前大多数网站都选用这样的采样率。
44kHz的采样率是标准的CD音质,可以达到很好的听觉效果。
2.3 声道数
为了播放声音时能够还原真实的声场,在录制声音时在前后左右几个不同的方位同时获取声音,每个方位的声音就是一个声道。声道数是声音录制时的音源数量或回放时相应的扬声器数量,有单声道mono、双声道stereo、多声道。
2.4 码率
也叫比特率,是指每秒传送的bit数。单位为 bps(Bit Per Second),比特率越高,每秒传送数据就越多,音质就越好。
码率计算公式:
码率 = 采样率 * 采样大小 * 声道数
比如采样率44.1kHz,采样大小为16bit,双声道PCM编码的WAV文件:
码率=44.1hHz*16bit*2=1411.2kbit/s。
那么录制1分钟的音乐的大小为(1411.2 * 1000 * 60) / 8 / 1024 / 1024 = 10.09M。
三、音频压缩技术
音频压缩主要包括2种方法:
3.1 消除冗余数据
这种压缩的主要方法是去除采集到的音频冗余信息,这些被删除掉的音频信号是没法恢复的,所以称为有损压缩。
冗余信息包括人类听觉范围之外的音频信号和被掩蔽掉的音频信号。什么是被掩蔽的信号呢?信号的掩蔽分为频域掩蔽和时域掩蔽。
3.1.1 频域掩蔽效应
人类听觉范围是20-20000Hz,但这并不意味着只要是这个频率范围内的声音都可以听到,能否听到还与声音的分贝大小有关,有个分贝临界值,高于这个临界值的声音才能听到,低于这个临界值的声音就听不到,在不同的频率下这个临界值是不一样的。如下图所示,横坐标为频率,纵坐标为分贝值,图中的黑色曲线就是这个临界值曲线,所以位于曲线下方的声音是听不到的。
还有一种情况,比如2个音调差不多的人同时说话,一个声音很大,一个声音很小,声音小的会受到声音大的影响,导致声音小的无法被听到。如下图所示,红色的柱子是一个很大分贝的声音,它会产生掩蔽效应将与它频率相近的小分贝的声音掩蔽掉,红柱子两边的蓝色曲线就是它的掩蔽范围曲线,紫色柱子都在它的掩蔽曲线覆盖的范围内,所以紫色柱子代表的声音是听不到的;而绿色柱子不在其范围内,所以是可以听到的。

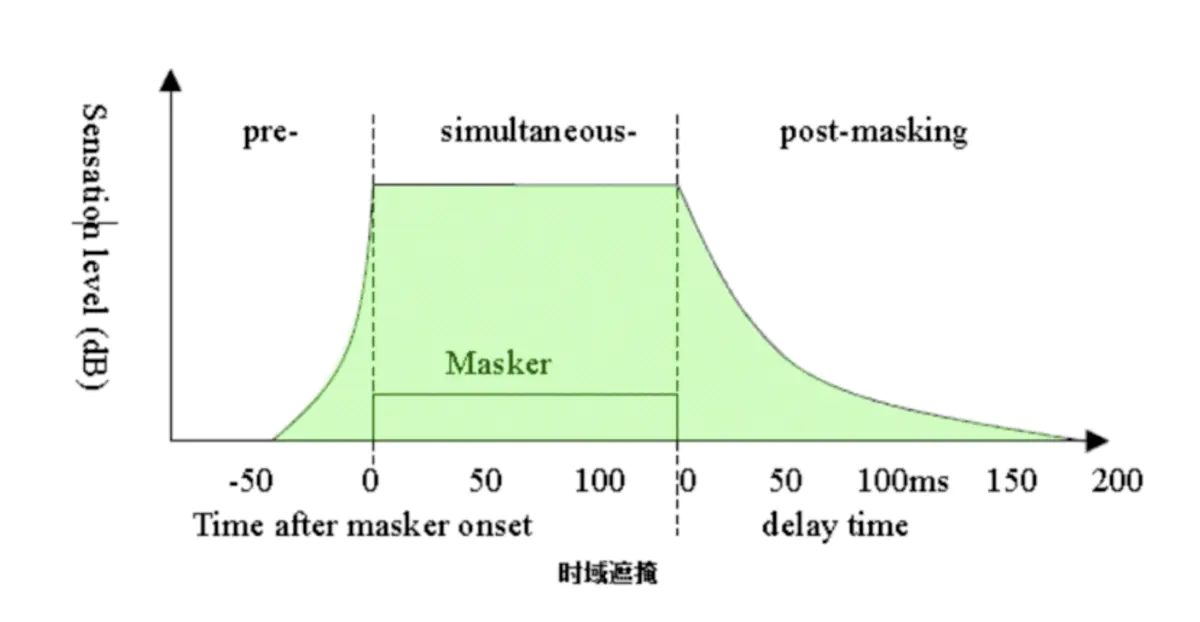
3.1.2 时域掩蔽效应
除了同时发出的声音之间有掩蔽现象之外,在时间上相邻的声音之间也有掩蔽现象,称为时域掩蔽。时域掩蔽又分为超前掩蔽和滞后掩蔽,如下图所示。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。一般来说,超前掩蔽很短,只有大约5~20ms,而滞后掩蔽可以持续50~200ms。
3.2 哈夫曼无损编码
将人类无法识别的声音信号删除掉后,对剩余的声音信号继续进行压缩编码,经过这种压缩后再还原时是可以复原到和原来一样的数据的(当然,复原也只是复原到压缩前的状态,那些删除的人类无法识别的部分是不能复原的),所以称为无损压缩。
四、音频编解码器
4.1 常见音频编解码器
常见的音频编解码器包括OPUS、AAC、Vorbis、Speex、iLBC、AMR、G.711等。目前泛娱乐化直播系统采用rtmp协议,支持AAC和Speex。
性能上来看,OPUS > AAC > Vorbis,其它的逐渐被淘汰。
下图为音频编解码器性能对比,横坐标是码率,纵坐标是音频的采样大小等级划分(比如采样大小为8bit是窄带音频,采样大小为16bit是宽带音频)。
纵轴是音频质量(窄带、宽带、超宽带、全带、全带立体声),横轴是码流大小。

4.2 AAC编解码器介绍
AAC(Advanced Audio Coding)编解码器应用范围特别广,编解码的音频质量高保真,它出现的目的是取代mp3格式,因为mp3是有损压缩,对音频质量有一定损耗,而AAC对于原始数据的损耗就会小很多,而且压缩率很高。目前市面上90%以上的直播系统都是用的AAC(虽然OPUS性能最好,但是rtmp协议不支持OPUS)。
4.2.1 AAC常用规格
AAC目前常用的规格有 AAC LC、AAC HE V1、AAC HE V2。
AAC LC
AAC LC (Low Complexity) 是低复杂度,一般码率128kb/s。
AAC HE V1
AAC HE V1是在AAC LC基础上加入了SBR(Spectral Band Replication)技术,也就是分频复用,加入这种技术后使码流变得更低,而且音质更好。比如按照44.1kHz采样率,20Hz频段一个正弦波采样2200个,这太浪费了,而在20000Hz频段一个正弦波采样2.2次,采样次数太少导致音质较差。采用SBR进行分频处理,在低频段降低采样率,在高频段提高采样率,这样既能降低码率又能提高音质。AAC HE V1一般码率为64kbt/s左右。
AAC HE V2
AAC HE V2在AAC HE V1的基础上又增加了PS(Parametric Stereo)技术。也就是将立体声双声道分别保存,一个声道的数据完整保存,另一个声道只存储一些差异性的参数信息,因为两个声道信息相关性非常强,可以通过那些差异性参数来还原这个声道的信息。AAC HE V2一般码率为32kbt/s左右。

4.2.2 AAC格式
AAC的格式有ADIF和ADTS两种
AAC ADIF(Audio Data Interchange Format)
这种格式的AAC文件只在最开始的地方存有一个头,头里面包括采样率、采样大小、声道数等信息。每拿出一个音频帧都用这个头信息来进行解析。它只能从开头位置开始解码,一般用于磁盘文件中。
AAC ADTS(Audio Data Transport Stream)
这种格式的AAC文件在每一个音频帧的前面都有一个同步字,也就是加一个小的头(7-9个字节),所以它可以从任何位置开始解码。它的优点就是进行流传输时每拿到一个音频帧直接就可以进行解码播放,缺点就是每个音频帧都多出一个头,所以相对于ADIF格式它会多出一些数据量。
五、音频传输
这里主要是指网络传输,通过网络把音频数据传给对方。语音和音乐两种场景下有明显的区别。
对于语音来说,实时性要求很高,主要用RTP/UDP做承载,由于UDP是不可靠传输,会丢包乱序等,影响语音质量,所以要采取相应的措施,主要有PLC(丢包补偿)、FEC(前向纠错)、重传、jitterbuffer等。
对于音乐来说,以前是播放本地音乐文件,近些年随着网络带宽的加大,可以播放云端的音乐文件了。播放时要把音乐文件传给播放器,一般是边播放边下载,播放音乐对实时性要求不高,一般用HTTP/TCP做承载,也就不存在丢包乱序等问题了。
六、音频分析软件
-
免费的音频处理软件Audacity:https://www.audacityteam.org/
-
Sound Forge
是能够非常方便、直观地实现对音频文件(wav文件)以及视频文件(avi文件)中的声音部分进行各种bai处理,满足从最普通用户到最专业的录音师的所有用户的各种要求,所以一直是多媒体开发人员首选的音频处理软件之一。
-
WavePad Audio Editor(WavePad音频编辑器)
是适用于Windows和Mac的音频和音乐编辑器(也适用于iOS和Android)。 它允许用户录制并编辑音乐、录音和其他声音。作为一个编辑器,用户可以在其中剪切、复制、粘贴、删除、插入、静音和自动修剪录音,然后在VST插件和免费音频库的支持下添加增强、归一化、均衡器、包络线、混响、回声、倒放等效果。
-
Adobe Audition
是美国Adobe Systems 公司 (前Syntrillium Software Corporation)开发的一款功能强大、效果出色的多轨录音和音频处理软件。主要用于对MIDI信号的处理加工,它具有声音录制、混音合成、编辑特效等功能。
-
GoldWave
是一个集声音编辑、播放、录制和转换的音频工具。它还可以对音频内容进行转换格式等处理。支持许多格式的音频文件,包括WAV、OGG、VOC、 IFF、AIFF、 AIFC、AU、SND、MP3、 MAT、 DWD、 SMP、 VOX、SDS、AVI、MOV、APE等音频格式。
参考
https://www.jianshu.com/p/f56114df9c0b