YOLOv5算法改进(5)— 添加ECA注意力机制

前言:Hello大家好,我是小哥谈。ECA注意力机制是一种用于图像处理中的注意力机制,是在通道注意力机制的基础上做了进一步的改进。通道注意力机制主要是通过提取权重,作用在原特征图的通道维度上,而ECA注意力机制则使用了一维卷积来替代全连接层,以减少计算量。这种方法在不增加过多的计算量的前提下能提升特征图的表达能力,因此被广泛应用于图像处理任务中。总的来说,ECA注意力机制是一种有效的图像注意力机制,能够进一步提升模型的性能。
 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
目录
1.论文
2.ECA注意力机制方法介绍
3.添加ECA注意力机制的方法
步骤1:在common.py中添加ECA模块
步骤2:在yolo.py文件中加入类名
步骤3:创建自定义yaml文件
步骤4:修改yolov5s_ECA.yaml文件
步骤5:验证是否加入成功
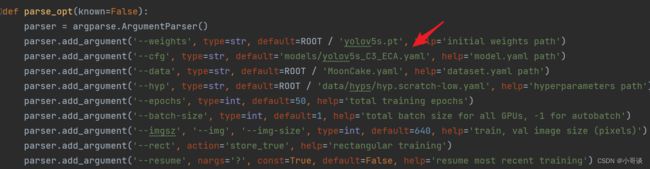
步骤6:修改train.py中的'--cfg'默认参数
4.添加C3_ECA注意力机制的方法(在C3模块中添加)
步骤1:在common.py中添加ECABottleneck和C3_ECA模块
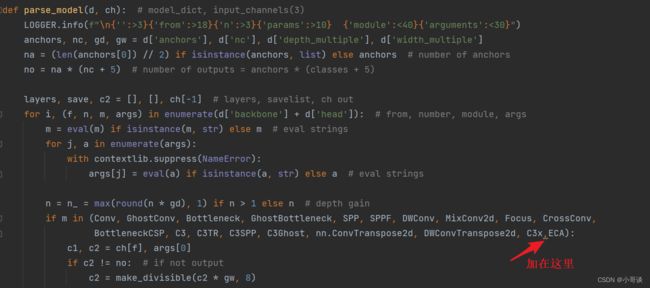
步骤2:在yolo.py文件里parse_model函数中加入类名
步骤3:创建自定义yaml文件
步骤4:验证是否加入成功
步骤5:修改train.py中的'--cfg'默认参数

1.论文
ECANet是对SENet模块的改进,提出了一种不降维的局部跨信道交互策略(ECA模块)和自适应选择一维卷积核大小的方法,从而实现了性能上的提优。在给定输入特征的情况下,SE模块首先对每个通道单独使用全局平均池化,然后使用两个具有非线性的完全连接(FC)层,然后再使用一个Sigmoid函数来生成通道权值。两个FC层的设计是为了捕捉非线性的跨通道交互,其中包括降维来控制模型的复杂性。虽然该策略在后续的通道注意模块中得到了广泛的应用,但作者的实验研究表明,降维对通道注意预测带来了副作用,捕获所有通道之间的依赖是低效的,也是不必要的。
因此,提出了一种针对深度CNN的高效通道注意(ECA)模块,该模块避免了降维,有效捕获了跨通道交互的信息。

论文题目:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文地址:https://arxiv.org/abs/1910.03151
代码实现:GitHub - BangguWu/ECANet: Code for ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
2.ECA注意力机制方法介绍
ECANet的核心思想是提出了一种不降维的局部跨通道交互策略,有效避免了降维对于通道注意力学习效果的影响。适当的跨通道交互可以在保持性能的同时显著降低模型的复杂性,通过少数参数的调整,获得明显的效果增益。通过这种机制,ECANet能够在不增加过多参数和计算成本的情况下,有效地增强网络的表征能力。
ECANet的结构主要分为两个部分:通道注意力模块和嵌入式通道注意力模块。

(1)通道注意力模块
通道注意力模块是ECANet的核心组成部分,它的目标是根据通道之间的关系,自适应地调整通道特征的权重。该模块的输入是一个特征图(Feature Map),通过全局平均池化得到每个通道的全局平均值,然后通过一组全连接层来生成通道注意力权重。这些权重被应用于输入特征图的每个通道,从而实现特征图中不同通道的加权组合。最后,通过一个缩放因子对调整后的特征进行归一化,以保持特征的范围。
(2)嵌入式通道注意力模块
嵌入式通道注意力模块是ECANet的扩展部分,它将通道注意力机制嵌入到卷积层中,从而在卷积操作中引入通道关系。这种嵌入式设计能够在卷积操作的同时,进行通道注意力的计算,减少了计算成本。具体而言,在卷积操作中,将输入特征图划分为多个子特征图,然后分别对每个子特征图进行卷积操作,并在卷积操作的过程中引入通道注意力。最后,将这些卷积得到的子特征图进行合并,得到最终的输出特征图。
ECANet的设计在以下几个方面具有优势:
- 高效性:ECANet通过嵌入式通道注意力模块,在保持高效性的同时,引入了通道注意力机制。这使得网络能够在不增加过多计算成本的情况下,提升特征表示的能力。
- 提升特征表示:通道注意力机制能够自适应地调整通道特征的权重,使得网络能够更好地关注重要的特征。这种机制有助于提升特征的判别能力,从而提升了网络的性能。
- 减少过拟合:通道注意力机制有助于抑制不重要的特征,从而减少了过拟合的风险。网络更加关注重要的特征,有助于提高泛化能力。
总结:♨️♨️♨️
ECANet是一种高效的神经网络架构,通过引入通道注意力机制,能够有效地捕捉图像中的通道关系,提升特征表示的能力。它的结构包括通道注意力模块和嵌入式通道注意力模块,具有高效性、提升特征表示和减少过拟合等优势。通过这种设计,ECANet在图像处理任务中取得了优越的性能。
3.添加ECA注意力机制的方法
步骤1:在common.py中添加ECA模块
将下面的ECA模块的代码复制粘贴到common.py文件的末尾。
class ECA(nn.Module):
"""Constructs a ECA module.
Args:
channel: Number of channels of the input feature map
k_size: Adaptive selection of kernel size
"""
def __init__(self, c1,c2, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# feature descriptor on the global spatial information
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Multi-scale information fusion
y = self.sigmoid(y)
return x * y.expand_as(x)具体如下图所示:

步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数,然后将 ECA 添加到这个注册表里。
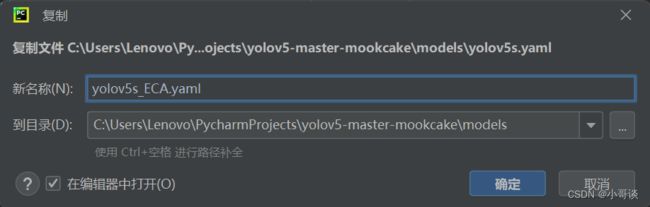
步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_ECA.yaml。
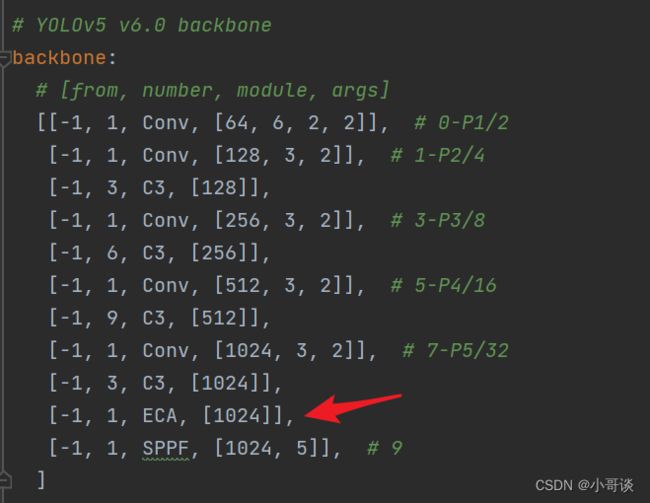
步骤4:修改yolov5s_ECA.yaml文件
本步骤是修改yolov5s_ECA.yaml,将ECA模块添加到我们想添加的位置。在这里,我将[-1,1,ECA,[1024]]添加到SPPF的上一层,即下图中所示位置。
说明:♨️♨️♨️
注意力机制可以加在Backbone、Neck、Head等部分,常见的有两种:一种是在主干的SPPF前面添加一层;二是将Backbone中的C3全部替换。
不同的位置效果可能不同,需要我们去反复测试。
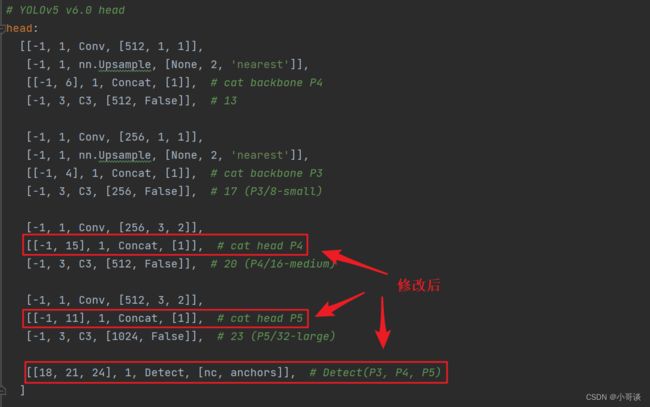
这里需要注意一个问题,当在网络中添加新的层之后,那么该层网络后面的层的编号会发生变化。原本Detect指定的是[17,20,23]层,所以,我们在添加了ECA模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24]。同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,我们刚才把ECA模块加到了第9层,所以第9层之后的编号都需要加1,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。
具体如下图所示:
步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_ECA.yaml。
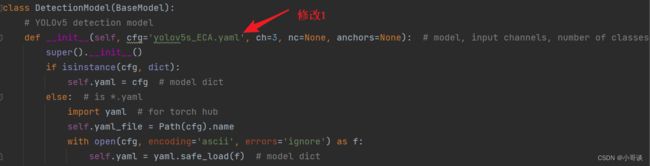

然后运行yolo.py,得到结果。

找到了ECA模块,说明我们添加成功了。
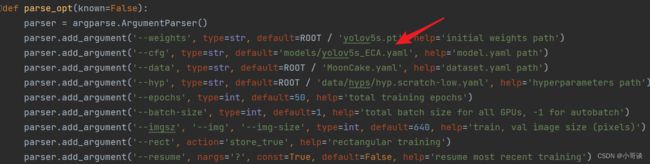
步骤6:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_ECA.yaml',然后就可以开始进行训练了。
4.添加C3_ECA注意力机制的方法(在C3模块中添加)
上面是单独添加注意力层,接下来的方法是在C3模块中加入注意力层。这个策略是将ECA注意力机制添加到Bottleneck,替换Backbone中所有的C3模块。
步骤1:在common.py中添加ECABottleneck和C3_ECA模块
将下面的代码复制粘贴到common.py文件的末尾。
class ECABottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=16, k_size=3): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
# self.eca=ECA(c1,c2)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
x1 = self.cv2(self.cv1(x))
# out=self.eca(x1)*x1
y = self.avg_pool(x1)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
out = x1 * y.expand_as(x1)
return x + out if self.add else out
class C3_ECA(C3):
# C3 module with ECABottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
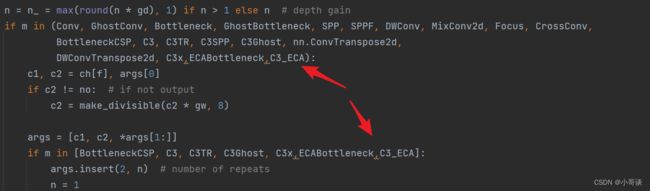
self.m = nn.Sequential(*(ECABottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))步骤2:在yolo.py文件里parse_model函数中加入类名
在yolo.py文件的parse_model函数中,加入ECABottleneck、C3_ECA这两个模块。
步骤3:创建自定义yaml文件
按照上面的步骤创建yolov5s_C3_ECA.yaml文件,替换4个C3模块。


步骤4:验证是否加入成功
在yolo.py文件里配置刚才我们自定义的yolov5s_C3_ECA.yaml,然后运行。
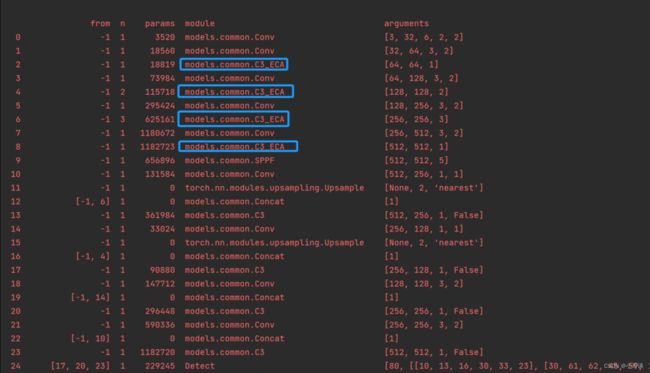
步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_C3_ECA.yaml',然后就可以开始进行训练了。