StyleHEAT: One-Shot High-Resolution Editable Talking Face Generation via Pre-trained StyleGAN 译文
链接
https://feiiyin.github.io/StyleHEAT/
arxiv:https://arxiv.org/abs/2203.04036
摘要
图1。我们的统一框架支持高分辨率的通话人脸生成,通过驾驶视频或音频解除纠缠控制,以及灵活的人脸编辑。我们的方法首次将一次性会说话的人脸生成的分辨率提高到1024×1024。第一行显示了一个视频驱动的交叉身份再现的合成视频。第二行显示了一个由音频驱动的嘴唇运动生成的合成视频。第三行显示,在谈话视频生成过程中,我们可以通过GAN倒置在任何时间戳上一致地自由编辑面部属性。第四行显示,我们可以基于嵌入式3DMM执行直观的人脸编辑以及会说话的人脸生成。
一次性谈话人脸生成的目的是从一个由视频或音频片段驱动的任意肖像图像中合成一个高质量的谈话人脸视频。一个具有挑战性的质量因素是输出视频的分辨率:更高的分辨率传达了更多的细节。在这项工作中,我们研究了一个预先训练过的样式根的潜在特征空间,并发现了一些优秀的空间变换性质。通过观察,我们探索了使用预先训练过的StyleGAN来突破训练数据集的分辨率限制的可能性。我们提出了一种基于预先训练过的StyleGAN的新型统一框架,它能够实现一组强大的功能,即高分辨率的视频生成,通过驱动视频或音频来解除纠缠控制,以及灵活的人脸编辑。
我们的框架首次将合成的说话面的分辨率提高到1024×1024,尽管训练数据集的分辨率较低。我们设计了一个基于视频的运动生成模块和一个基于音频的模块,它可以单独或联合插入到框架中来驱动视频生成。预测的运动用于变换StyleGAN的潜在特征,用于视觉动画。为了补偿变换失真,我们提出了一个校准网络和一个域损失来细化特征。此外,我们的框架允许两种类型的面部编辑,即通过GAN倒置的全局编辑和基于3D可变形模型的直观编辑。综合实验表明,优越的视频质量,灵活的可控性,和可编辑性比最先进的方法。
图2所示。预训练StyleGAN的潜在特征空间研究。采用不同的几何变换来修改特征映射。
1. 介绍
一次性谈话人脸生成是指在驾驶视频或音频片段的引导下,从一个给定的肖像图像中合成一个高质量的谈话人脸视频的任务。所合成的人脸从人像图像中继承身份信息,而其姿态和表达式从驱动视频中传输或基于驱动音频生成。人脸生成具有数字人体动画、电影制作等重要应用。
在最近的文献中,有许多尝试用不同的角度的视频或音频驱动静态肖像。[15,38,65,72]利用三维变形模型(3dmm),这是一种分解表情、姿态和身份的参数模型,来传递面部运动。对于音频驱动的情况,音频特征总是投影到3DMM [65,67,70]的参数空间。此外,许多方法[34,46,69,75]使用面部地标作为中间表示。其他一些无模型方法[40,41,53,58,64]通过无监督关键点检测去除人脸。
在这些工作中,依赖于主题的方法往往会获得更高质量的结果,因为它们需要源主题的长视频片段来学习适合训练视频的特定于个人的模型。相比之下,主题不可知的方法旨在获得适用于任何源主题的通用模型,由于关于源的信息有限,以合成质量为代价。一次性说话的面孔生成是在主题不可知的设置下,鉴于最小的输入,这更具挑战性。
最近的一次性谈话人脸生成方法[38,58,72]在驱动表达和姿态方面取得了显著进展,但它们不能生成高分辨率的视频帧。常用方法的视频分辨率仍然保持在256×256。很少有方法如[58]和[72]通过利用新收集的高分辨率数据集,即说话头-1KH和HDTF来达到512×512的分辨率,但它们仍然受训练数据分辨率的限制。更重要的是,改进解决率需要正确设计的网络架构和培训策略。以一种直接的方式将上采样层添加到网络中通常并不好地工作。
我们提出了一个雄心勃勃的问题:即使现有数据集的分辨率较低,我们是否能进一步提高一次性谈话的分辨率到1024×1024?为了实现这一目标,我们求助于一个强大的预训练生成模型: StyleGAN [27]。StyleGAN在各种应用中都取得了令人印象深刻的效果,如面部属性编辑[10]、盲图像恢复[59]、肖像风格化[45]等。一套GAN反演技术[3,49,55,78]基于预训练的StyleGAN在人脸操作中取得了高质量的结果。这些方法利用StyleGAN学习到的图像优先级来促进下游任务,消除了从头开始训练大型模型的需要。图像分辨率被保留在1024×1024,视觉细节也被保留。尽管取得了这些成功,但据我们所知,目前还没有使用预先训练过的风格来生成一次性会说话的脸。
在这项工作中,我们首先研究了一个预先训练过的风格化者的潜在风格空间和特征空间。样式空间也被称为W空间,它是通过一个多层感知器(MLP)将一个正态分布映射到一个新的分布来构造的。样式代码用于通过AdaIN [21]修改主干网的特征图。采用GAN反演方法对人脸编辑的样式空间进行了广泛的研究。特征空间也称为F空间,它是由主干的每一层的卷积运算产生的。这在文献中并没有得到太多的关注:只有少数基于优化的反演方法[24,78]访问了更好的重构和属性编辑。在一个谈话头视频中,不同的面部表情是通过变形不同的面部区域来实现不同的面部表情。因此,由于样式码是不包含准确空间信息的潜在向量,因此样式空间并不是注入面脸运动信息的合适选择。然后,我们通过在StyleGAN的特征图上应用一组空间变换,系统地研究了特征空间,包括平移、旋转、放大、缩放、剪切、遮挡和扭曲。有趣的是,我们发现预先训练好的模型对这些操作具有鲁棒性,因为它可以稳定地相应地生成高质量的图像,这表明特征空间具有令人满意的空间特性。图2显示了一些合成结果。研究表明,将面部运动信息整合到特征空间中是高质量对话人脸生成的一个有希望的方向。
基于上述观察,我们提出了一种基于预训练StyleGAN的高质量一次性说话人脸生成的统一框架。我们的框架实现了一组强大的功能,包括高分辨率视频生成,通过驱动视频和音频进行解纠缠控制,以及灵活的面部编辑。由于预先训练的StyleGAN,我们的方法可以在不训练新数据集的情况下达到1024×1024的分辨率。对于说话脸的生成,我们利用了常用的流场作为运动描述符。我们设计了一个基于视频的运动生成模块来从视频中提取运动,一个基于音频的运动生成模块来从音频中提取运动。利用预测的流场对潜在特征映射进行空间扭曲。然而,翘曲操作总是在最终输出中引入明显的伪影,特别是在眼睛和牙齿周围。因此,我们提出了一个校正网络和一个域损失来改进扭曲的特征映射。这两个模块可以单独或联合插入到框架中。使用这两个模块时,姿态驱动信息来自视频,唇动驱动信息来自音频。此外,我们的框架允许两种类型的人脸编辑,即通过GAN反演的全局编辑和基于3DMM的直观编辑。具体来说,给定源肖像,我们执行GAN反演以获得可用于修改特征映射的样式代码。这使我们能够轻松地通过样式代码编辑全局面部属性时,生成一个说话的脸视频。在基于视频的运动生成模块中,我们利用3DMM参数来指导流场的生成,通过修改3DMM参数可以实现直观的编辑。几部相关作品的特征比较见表1。图1说明了提议的框架的功能。
我们的主要贡献如下:
- 我们提出了一个基于预训练StyleGAN的统一框架,用于一次性说话脸生成。它可以实现高分辨率的视频生成,通过驱动视频和音频来解除纠缠控制,以及灵活的面部编辑。
- 我们进行了全面的实验来说明我们的框架的各种功能,并将其与许多最先进的方法进行比较。
2. 相关工作
2.1 视频说话头生成
2.1.1 基于三维结构的方法
传统的3D人脸模型先验(如3DMM[8])通过参数调制为人像图像的渲染和编辑提供了强大的工具。例如,DVP[31]修改源和目标的参数,然后使用网络将阴影渲染到视频。NS-PVD[30]通过一种新的目标式保持递归GAN扩展了DVP。最近基于3D模型的方法[15,17,18,38]也可以很好地完成与受试者无关的人脸合成。HeadGAN[15]将三维糊状物作为网络的输入进行预处理。PIRenderer[38]预测特征扭曲的流场。尽管基于模型的方法取得了令人印象深刻的性能,但它们的能力受到限制。由于3d模型只编码面部区域,而真实的相关信息(例如,头发,牙齿等)很难合成。
2.1.2 基于2D的方法
为了代替控制模型参数,用神经网络模拟另一个个体的运动也是一个流行的方向。早期的作品[6,57,66]学习通过图像到图像的翻译将源视频映射到目标视频[22]。然而,这些方法只能在单个身份的单个模型上工作。后来,元学习框架在目标身份的微调模型中进行了探索[56,69]。这些方法使用少数目标身份样本,但在复杂的现实场景中失败。受试者不可知论方法[5,9,40 - 42,58],只需要目标人物的单一图像,是最受欢迎的类型。对于代表性的方法,Monkey-Net[41]提出了一种将变形从稀疏运动流转移到密集运动流的网络。FOMM[40]通过一阶局部仿射变换扩展了Monkey-Net。然后,Face-vid2vid[58]通过学习3D无监督关键点来改进formm,用于生成自由视点说话头。与以往的方法不同,[5]通过潜空间导航学习源图像的动画化。
2.1.3 音频驱动说话头生成
另一个值得注意的方向是音频驱动的方法。这些方法从音频流中生成令人信服的面部运动。早期的方法也学习针对特定说话人的模型,如Synthesizing Obama[47]、NVP[50]、AudioDVP[62]。受近期神经渲染技术发展的启发,基于NeRF[35]的talking-head生成也被提出[19]。对于主体不可知的方法,基于重构的方法可以合成准确的嘴唇,Speech2Vid[11]提出了端到端的神经网络。然后,[73]通过对抗性学习扩展了这种方法。接下来,Wav2Lip[37]将嘴巴与音频同步进行基于绘画的重建,PC-AVS[74]通过隐式调制学习姿势和嘴唇重建。[54]利用基于变压器的网络和预训练的FOMM方法[40]。最近的研究还将额外的结构信息用于与主题无关的方法,例如地标[46,75]、运动流场[72]和3d网格[33]。对于高质量的谈话头生成,[72]提出了一个数据集,由于该数据集相对较小,因此仍然受到唇伪影的影响。
然而,以往所有的说话头方法都不能生成高分辨率的视频。一方面,很难收集到大量高分辨率的语音数据集。另一方面,网络需要精心设计以学习高分辨率的说话面孔。与我们的相似,有几种方法[5,74]也利用了基于风格的编码器来生成说话头。然而,它们都侧重于风格卷积的隐式模块化能力,而不是预训练的GAN先验。在这项工作中,我们首先证明了预训练的StyleGAN网络可以用于说话头视频生成。
2.2 通过预训练的StyleGAN进行图像编辑
StyleGAN2[28]由于能够生成高质量的人脸图像,并且特征空间高度解纠缠,能够生成高质量的人脸图像,受到了业界的关注。因此,随着GAN的快速进化,通过GAN反演编辑StyleGAN[77]变得流行起来。GAN通过预训练模型的潜在空间对图像进行投影和编辑。一般可以大致分为基于优化的、基于编码器的和混合的三种方法[55]。基于优化的方法可以获得更高的重建质量,但需要对每个图像进行优化[1 - 3,27]。一种更直接的方法是通过附加的编码器来学习潜在嵌入。pSp[39]通过类似unet的pixel2style编码器学习潜在空间。[4,61]通过多阶段细化扩展了pSp。另一方面,混合方法[55,76]被提出作为基于优化和基于编码器的方法的组合。
此外,我们还可以根据使用的隐空间对GAN反演进行分类。广泛使用的反演空间为W/W+,该空间对人脸属性编辑具有高度的去纠缠性[1,2,4,39,52,61]。还有一些作品试图通过W/W+空间来控制面部姿势和表情。StyleRig[49]通过3DMM对固定的StyleGAN提供了类似钻机的控制,它可以将3D人脸网格上的语义编辑转换到StyleGAN的输入空间。然而,它无法创建一致的面部姿态编辑,网络无法生成新的姿态。 有几部作品也尝试编辑预先训练好的StyleGAN W空间进行无条件视频生成[16,44,51],很容易失去身份。
另一方面,空间特征空间F也是精确、局部编辑的一个有前景的方向。例如Barbershop[78]使用分割蒙版和F空间编辑来实现精确的图像合成。GFP-GAN[59]利用F空间进行盲人脸复原。StyleMapGAN[29]在空间维度上编辑潜在空间,用于局部编辑和语义操作。在这项工作中,我们给出了人脸编辑在F空间上的详细几何变换,并提出了一种使用预训练的StyleGAN生成谈话头视频的方法,该方法保留了GAN模型的质量和可编辑性,并通过条件信号产生时间一致性视频内容。
3. 研究样式的特征空间
为了使预训练的StyleGAN[28]能够生成高分辨率的谈话视频,一个可能的方向是基于StyleGAN的视频生成[16,51],他们通过在W+潜在空间中发现理想轨迹来学习生成视频。然而,运动是随机采样的,没有任何控制,当当前姿态与初始姿态不同时,内容就会被破坏。这是因为W+是一个高度语义浓缩的空间,缺乏明确的空间先验[55]。此外,在W+空间中编辑只允许改变高级面部属性,由于StyleGAN是在对齐的面部上训练的,因此无法生成不对齐的图像[24]。
因此,F特征空间中的图像编辑[24,55,59,78]引起了我们的密切关注。具体来说,F特征空间中的潜在代码表示生成器中的空间特征映射。对于StyleGAN[28],我们将定义为在一定尺度上经过一对上采样和卷积层后的特征映射。之前只有少数方法[24,55,59,78]编辑空间特征用于GAN反演[24,55]、图像合成[78]和盲人脸增强[59]。这些方法收获了空间特征空间编辑的潜力,并将空间调制(例如空间特征变换[60])应用于特征。然而,预训练StyleGAN的特征空间在经过各种几何变换后是否仍然可以用来生成逼真的图像,目前还没有得到充分的研究。

图3所示。实验在哪一层操作。
因此,我们进行了详细的实验来验证StyleGAN特征的空间特性,充分挖掘其潜在的能力。我们首先在W+空间中对样式潜在代码w进行随机采样,使用预训练的StyleGAN生成随机人脸图像。同时,各种空间特征 [ f 4 × 4 , f 8 × 8 , … , f 1024 × 1024 ] \left[f_{4 \times 4}, f_{8 \times 8}, \ldots, f_{1024 \times 1024}\right] [f4×4,f8×8,…,f1024×1024] 在F空间中可以得到。为了确定适合进行空间变换的层,我们对每一层的特征图分别进行翘曲。结果如图3所示。我们可以观察到,扭曲较低的图层不能准确地控制姿态和表情,而扭曲较高的图层会在合成图像上产生鬼影。因此,我们选择64×64层作为一个平衡的选择。然后,为了测试预训练的StyleGAN特征的空间属性,使用平移、旋转、缩放、剪切、薄板样条(Thin Plate Spline, TPS[63])等几种几何变换直接操作 f 64 × 64 f_{64 \times 64} f64×64 。最后,以编辑好的特征图为输入,通过前向传递生成变换后的图像。
实验结果如图2所示。首先,如a)到e)所示,我们用固定的对 f 64 × 64 f_{64 \times 64} f64×64 进行不同的仿射变换,并将编辑好的特征映射馈送到StyleGAN中。值是用0填充遮挡。我们可以观察到,生成的图像具有相同的身份和外观,只有微小的差异。这种现象表明,在预训练的生成器中学习到的卷积核以平移不变的方式执行。然后,我们将feature map的一些随机patch去除,如图2 f)所示,仍然可以生成图像。这意味着StyleGAN特征空间对于这种修改也是健壮的。最后,在对特征映射进行复杂变形(如TPS操作)时,对源图像进行插值以匹配随机采样的目标关键点。总的来说,无论是简单的仿射变换还是复杂的TPS变形,我们观察到生成的图像与在特征空间中应用的变形保持相同的几何变化。
我们将中间特征的强空间先验性总结如下。假设图像是由特征图和样式代码生成w,即 I = G ( f , w ) I=G(f, w) I=G(f,w),其中是预训练的生成器。
对于图像空间中的几何变换,我们有:
T ( I ) ≈ G ( T ′ ( f ) , w ) T(\boldsymbol{I}) \approx G\left(T^{\prime}(\boldsymbol{f}), \boldsymbol{w}\right) T(I)≈G(T′(f),w)
式中’为特征空间中的几何变换算子,对应。的比例尺根据到的相对比例尺进行调整。当被下采样到与’相同的尺度时,它们的值很接近。这种空间特性使预训练StyleGAN的特征空间编辑成为一个有前途的方向。
4. 方法
我们聚焦于可控制的说话头生成任务。设为源图像,{1,2,···,N}为会说话的头部视频,其中i为第i帧视频帧数,N为总帧数。一个理想的框架应该生成视频{12 , · · · , }具有一样的身份和一致的运动源自{1, 2 , · · · , }。
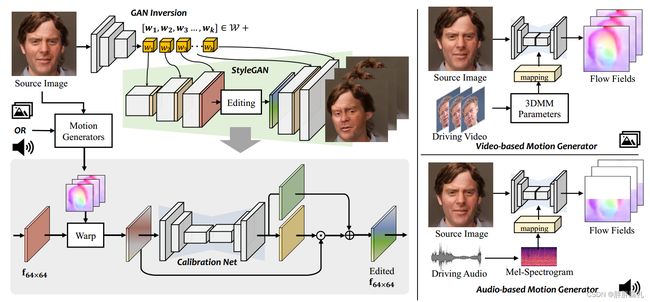
图4。我们统一框架的管道。该框架由四个部分组成,即预训练的StyleGAN,视频驱动的运动生成器,音频驱动的运动生成器和校准网络。给定源图像和驱动视频或音频,我们可以通过GAN反演编码器获得源图像的样式代码和特征映射。相应的运动生成器使用视频或音频连同源图像来预测运动场。选择的特征映射被运动场扭曲,然后校正网络对特征畸变进行校正。然后将改进的特征映射馈送到StyleGAN中进行最终的人脸生成。
受我们在第3节中观察到的启发,我们提出了一个基于预训练StyleGAN的F空间挖掘的统一框架。如图4所示,我们的方法包含实现这一目标的几个步骤。给定单源图像,我们首先使用GAN反演方法[55]获得源图像的潜在样式代码和特征映射。然后,为了注入精确的运动引导,我们直接从视频(4.1节)或音频(4.2节)中通过运动生成器预测密集流场。最后,由于翘曲操作可能会由于遮挡和错误映射而引入伪影,因此引入校准网络来更新编辑过的空间特征图(第4.3节)。下面,我们将详细讨论每个部分。
4.1 视频驱动运动生成器
视频驱动运动生成器的目标是以驱动视频和源图像为输入,生成密集的运动流。然后,这些流场将对预训练的StyleGAN的特征映射进行操作,用于生成说话脸。在这一部分中,我们首先演示了我们设置中的中间运动表示。然后,给出了密集运动场生成的网络结构和训练过程。
运动表示。为了实现准确、直观的运动控制,语义媒介在生成过程中起着重要作用。根据之前的工作[15,38],我们利用3DMM[7]参数进行运动建模。在3DMM中,人脸的三维形状可以解耦为:
S = S + α U i d + β U exp \boldsymbol{S}=\boldsymbol{S}+\boldsymbol{\alpha} \boldsymbol{U} i d+\boldsymbol{\beta} \boldsymbol{U} \exp S=S+αUid+βUexp
其中为平均形状, 和 p 为LSFM可变形模型恒等和表达的正交基[8]。系数∈r80和∈r64分别描述了人的身份和表情。为了保持姿态方差,系数∈(3)和∈r3表示头部旋转和头移。然后,我们可以用现有的3D人脸重建模型提取的参数集={,r,t}来建模驱动面的运动[14]。
由于同一视频中连续帧之间不可避免的存在预测误差,单个输入帧的参数会在最终生成的视频中造成抖动和不稳定。因此,为了获得更好的时间一致性,我们采用了一种窗口策略,其中相邻帧的参数也作为中心帧的描述符,以平滑运动轨迹。因此,定义-th驱动架运动系数为:
p i ≡ p i − k : i + k ≡ { β i − k , r i − k , t i − k , … , β i , r i , t i , … , β i + k , r i + k , t i + k } \boldsymbol{p}_i \equiv \boldsymbol{p}_{i-k: i+k} \equiv\left\{\boldsymbol{\beta}_{i-k}, \boldsymbol{r}_{i-k}, \boldsymbol{t}_{i-k}, \ldots, \boldsymbol{\beta}_i, \boldsymbol{r}_i, \boldsymbol{t}_i, \ldots, \boldsymbol{\beta}_{i+k}, \boldsymbol{r}_{i+k}, \boldsymbol{t}_{i+k}\right\} pi≡pi−k:i+k≡{βi−k,ri−k,ti−k,…,βi,ri,ti,…,βi+k,ri+k,ti+k}
其中为窗口半径。
网络结构。我们的网络建立在U-Net结构上,需要源图像和驾驶视频作为输入,输出是特征扭曲所需的流场。它包含一个5层卷积编码器和一个3层卷积解码器,用于多尺度特征提取。我们使用来自驱动框架的3DMM参数作为运动表示。具体来说,这些参数首先通过3层MLP映射到潜在向量,以聚合时间信息。然后,通过自适应实例归一化(AdaIN[21])将运动参数注入每个卷积层,定义为:
AdaIN ( x i , p ) = M s ( p ) i x i − μ ( x i ) σ ( x i ) + M b ( p ) i \operatorname{AdaIN}\left(\boldsymbol{x}_i, \boldsymbol{p}\right)=M_s(\boldsymbol{p})_i \frac{\boldsymbol{x}_i-\mu\left(\boldsymbol{x}_i\right)}{\sigma\left(x_i\right)}+M_b(\boldsymbol{p})_i AdaIN(xi,p)=Ms(p)iσ(xi)xi−μ(xi)+Mb(p)i
其中, μ \mu μ 为平均操作, σ \sigma σ为方差操作。利用 M s M_s Ms和 M b M_b Mb 根据目标运动估计自适应均值和偏置值。每个特征映射 在首先被归一化,然后使用相应的标量分量进行缩放和偏置。然后,以源图像 I I I 和运动条件 p t p_t pt 作为输入,对网络进行训练。最后,通过后向翘曲计算目标图像 d t d_t dt 与生成图像之间的损失函数,这将在后面讨论。
训练的策略。由于我们只需要一个低分辨率的流场来驱动StyleGAN的空间特征图,我们的运动生成器是在广泛使用的说话脸数据集(VoxCeleb[36])上进行预训练的,以生成可信的流场。具体来说,由于地面真实流场不可用,我们使用网络来预测流场 n n n,然后使用源帧 I ^ n = I ∘ n \hat{\boldsymbol{I}}_n=\boldsymbol{I} \circ \boldsymbol{n} I^n=I∘n 来计算扭曲帧。然后,给定目标帧 I t \boldsymbol{I}_t It ,我们使用感知损失[23]来计算预训练的VGG-19网络激活图之间的L1距离[43]。
L v = ∑ i ∥ ϕ i ( I ^ n ) − ϕ i ( I t ) ∥ 1 , \mathcal{L}^v=\sum_i\left\|\phi_i\left(\hat{I}_n\right)-\phi_i\left(\boldsymbol{I}_t\right)\right\|_1, Lv=i∑ ϕi(I^n)−ϕi(It) 1,
其中, ϕ i \phi_i ϕi 为VGG19网络第i层的激活图。与[40]类似,我们通过在 I t \boldsymbol{I}_t It 和 I ^ n \hat{I}_n I^n 上应用金字塔下采样来计算许多分辨率上的感知损失。训练完成后,生成的流场可用于编辑StyleGAN的特征图。
4.2 音频驱动运动发生器
音频驱动的运动传输类似于视频驱动的运动传输,但这项任务更复杂,因为它需要对音频和面部运动之间的关系进行建模。之前的一些作品尝试将音频特征转化为一种中间媒介,如3D顶点坐标[12]、人脸模型参数[48]、3DMM参数[38]等。然后将介质转换为面部动作,使整个面部动画化。然而,仅从音频信息中直接预测视觉语义参数是一项困难的任务,并且两阶段转换过程可能会积累更多的误差。因此,我们可以直接从音频特征中预测运动。接下来,我们首先介绍网络结构和我们设置中的运动表示。然后给出运动生成的预训练策略。
网络结构。所述音频驱动运动发生器的网络结构与所提出的视频驱动运动发生器相似。不同的是,驱动信号来自音频。因此,我们首先将原始音频转换为梅尔谱图。然后我们使用MLP来压缩时间维度。最后,通过AdaIN将这些特征注入到网络中。

图5所示。音频驱动运动发生器成对训练数据生成。由于嵌入了3dMM参数,我们使用预训练的基于视频的运动生成器来创建代理输入,该输入与源图像(a)具有相同的表达式,并且与目标图像©具有相同的头部姿势。然后,(b)和来自(a)的音频可用于在©的监督下生成流场。
训练的策略。对于音频驱动的运动生成,我们训练生成器来预测脸部下半部分的流场,因为音频与嘴唇运动密切相关。然而,一个主要的挑战是,从音频中生成视频缺乏配对数据集,因为具有相同姿势但不同唇形的视频很难获得。为了解决这个问题,我们利用第4.1节中预训练的视频驱动运动生成器在不同音频条件下构建具有相同姿势但不同表情的配对数据。具体来说,我们通过混合从源帧和驱动帧中提取的3DMM参数来生成代理输入,即代理输入与驱动帧具有相同的姿态,与源帧具有相同的表达式。我们在图5中说明了主要过程,其中代理输入的头部姿态与驱动框架高度对齐。通过对配对数据集的训练,我们的音频驱动运动生成器将专注于表达的流生成。
至于损失函数,与我们的视频驱动运动生成器类似,我们使用感知损失和L1损失计算驱动图像 I t I_t It和扭曲图像 I a u d i o I_{audio} Iaudio之间的损失。不同的是,我们使用口罩策略来增加口腔区域的权重。掩模是通过计算嘴巴周围关键点的边界盒得到的。损失定义为:
L t a = ∑ i ∥ M ⋅ ϕ i ( I t ) − M ⋅ ϕ i ( I ^ audio ) ∥ 1 + λ 1 a ⋅ ∥ M ⋅ I t − M ⋅ I ^ audio ) ∥ 1 , \begin{gathered} \mathcal{L}_t^a=\sum_i\left\|M \cdot \phi_i\left(\boldsymbol{I}_t\right)-M \cdot \phi_i\left(\hat{I}_{\text {audio }}\right)\right\|_1+ \left.\lambda_1^a \cdot \| M \cdot \boldsymbol{I}_t-M \cdot \hat{I}_{\text {audio }}\right) \|_1, \end{gathered} Lta=i∑ M⋅ϕi(It)−M⋅ϕi(I^audio ) 1+λ1a⋅∥M⋅It−M⋅I^audio )∥1,
其中, λ 1 a \lambda_1^a λ1a 是超参数。实际上,遮罩是软的形式。
此外,由于伪像总是发生在被屏蔽区域,我们设计了一个正则化损失,以确保代理输入 I ^ v i s u a l \hat{I}_{v i s u a l} I^visual 和扭曲图像 I ^ audio \hat{I}_{\text {audio }} I^audio 之间的非被屏蔽区域的一致性:
L reg a = ∑ i ∥ ( 1 − M ) ⋅ ϕ i ( I ^ visual ) − ( 1 − M ) ⋅ ϕ i ( I ^ audio ) ∥ 1 , \mathcal{L}_{\text {reg }}^a=\sum_i\left\|(1-M) \cdot \phi_i\left(\hat{I}_{\text {visual }}\right)-(1-M) \cdot \phi_i\left(\hat{I}_{\text {audio }}\right)\right\|_1, Lreg a=i∑ (1−M)⋅ϕi(I^visual )−(1−M)⋅ϕi(I^audio ) 1,
最后,为了使嘴唇运动与音频更加一致,我们使用了SyncNet为音频和视频之间的同步而训练的口型同步鉴别器 D sync D_{\text {sync }} Dsync [11]。同步目标可以定义为:
L sync a = − E [ ∑ t = i − 2 i + 2 log ( D ( I ^ audio , a ) ) ] , \mathcal{L}_{\text {sync }}^a=-\mathbb{E}\left[\sum_{t=i-2}^{i+2} \log \left(D\left(\hat{I}_{\text {audio }}, \boldsymbol{a}\right)\right)\right], Lsync a=−E[t=i−2∑i+2log(D(I^audio ,a))],
其中 D sync D_{\text {sync }} Dsync 需要5个连续帧作为输入。
整体损失可以写成:
L a = L t a + λ r a ⋅ L reg a + λ s a ⋅ L sync a , \mathcal{L}^a=\mathcal{L}_t^a+\lambda_r^a \cdot \mathcal{L}_{\text {reg }}^a+\lambda_s^a \cdot \mathcal{L}_{\text {sync }}^a, La=Lta+λra⋅Lreg a+λsa⋅Lsync a,
其中 λ r a \lambda_r^a λra 和 λ s a \lambda_s^a λsa 是相应的权重。
完全可控的运动场。单独训练视频驱动和音频驱动的运动生成器后,这两个生成器可以在一个统一的框架中联合使用,独立控制头部运动和嘴唇运动。
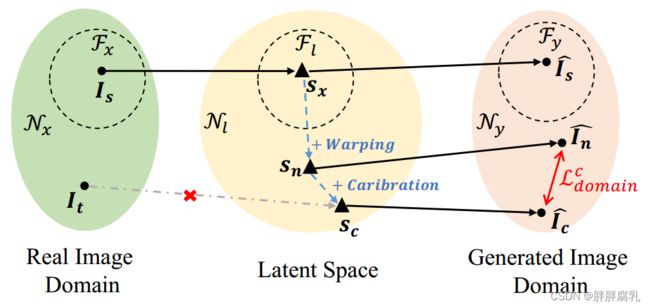
图6。域损失的图示。
4.3 特征校准与联合训练
视频驱动和音频驱动的运动生成器在不考虑预训练StyleGAN的任何信息的情况下进行预训练。虽然预测的运动场可以用来扭曲StyleGAN的特征图,但它不可避免地会引入伪影。例如,通过二维扭曲使封闭的口腔张开并不能填充口腔内正确的牙齿。为了减轻特征映射的失真,我们引入了校正网络来校正特征空间中的伪影。
校正网络。由于扭曲的特征仍然存在伪影,因此需要一个校准网络。如图4所示,我们采用U-Net架构提取多分辨率空间特征。它由一个4层编码器和一个4层解码器组成。我们将扭曲的特征图作为网络的输入。然后,利用多尺度常规层对扭曲特征进行细化。然而,由于中间特征的高度复杂性,我们的校准网络不是直接预测特征,而是对扭曲的特征进行空间特征变换(SFT[60]),定义为:
f ^ c = SFT ( f w ∣ α , β ) = α ⊙ f w + β \hat{f}_c=\operatorname{SFT}\left(f_{\boldsymbol{w}} \mid \boldsymbol{\alpha}, \boldsymbol{\beta}\right)=\boldsymbol{\alpha} \odot \boldsymbol{f}_{\boldsymbol{w}}+\boldsymbol{\beta} f^c=SFT(fw∣α,β)=α⊙fw+β
其中 ⊙ \odot ⊙ 表示逐元素乘法。 最终得到的高质量、高分辨率的结果为 I ^ = G ( f ^ c , w ) \hat{I}=G\left(\hat{f}_c, \boldsymbol{w}\right) I^=G(f^c,w)。
全面的端到端培训。直接应用引入的校准网络很容易遇到模糊结果(如图15所示),因为视频数据集中的帧质量远低于用于训练StyleGAN的高分辨率人脸数据集。此外,GAN反演方法不可避免地会带来身份、属性、纹理、背景等细节的丢失,这将扩大生成图像与真实图像之间的差距,进一步误导优化的方向。
因此,我们联合训练整个网络并设计损失函数来解决上述问题。我们首先设计了一个域损失来限制变形特征映射的重建图像与校准后的特征映射在生成的图像域中的差异。如图6所示,给定StyleGAN空间Fx对齐后的自然源图像 I s I_s Is,GAN反演方法可以分别在隐空间和生成图像域对图像进行反演和重构。不同的是,对于非对齐域的目标图像 I t I_t It,很难应用GAN反演。因此,该方法利用流场对隐空间中的图像进行编辑,以获得所需的隐空间 s c s_c sc。编辑后,扭曲的特征 s n s_n sn 可能不再位于对齐的StyleGAN潜在空间中,但它仍然可以通过转发传递生成高质量的图像 ,正如我们在第3节中讨论的那样。不幸的是,由于流场质量低,可能会产生翘曲伪影。因此,我们提出了校正网络来进一步编辑前面介绍的特征映射。然而,由于特征转移,结果 I c I_c Ic变得模糊。为了保留 I n I_n In和 I c I_c Ic 的优点,定义了域损失来衡量它们的差异。此外,我们采用掩蔽策略来增强不同区域的权重。校准蒙版由眼睛和嘴巴的边界框组成,因为伪影经常出现在它们周围。因此,域损失为:
L domain c = ∑ i ∥ ( 1 − M ) ⋅ ϕ i ( I ^ n ) − ( 1 − M ) ⋅ ϕ i ( I ^ c ) ∥ 1 \mathcal{L}_{\text {domain }}^c=\sum_i\left\|(1-M) \cdot \phi_i\left(\hat{I}_n\right)-(1-M) \cdot \phi_i\left(\hat{I}_c\right)\right\|_1 Ldomain c=i∑ (1−M)⋅ϕi(I^n)−(1−M)⋅ϕi(I^c) 1
此外,为了消除局部面部特征的伪影,驾驶图像 I t I_t It 提供了最准确的高频信息。因此,我们计算L1损失和感知损失与地面真值,这是在掩蔽区域加权:
L t c = ∑ i ∥ M ⋅ ϕ i ( I t ) − M ⋅ ϕ i ( I ^ c ) ∥ 1 + λ 1 c ⋅ ∥ M ⋅ I t − M ⋅ I ^ c ∥ 1 , \begin{aligned} \mathcal{L}_t^c= & \sum_i\left\|M \cdot \phi_i\left(\boldsymbol{I}_t\right)-M \cdot \phi_i\left(\hat{\boldsymbol{I}}_c\right)\right\|_1+ \\ & \lambda_1^c \cdot\left\|M \cdot \boldsymbol{I}_t-M \cdot \hat{\boldsymbol{I}}_c\right\|_1, \end{aligned} Ltc=i∑ M⋅ϕi(It)−M⋅ϕi(I^c) 1+λ1c⋅ M⋅It−M⋅I^c 1,
这里 λ 1 c \lambda_1^c λ1c 是 L 1 \mathcal{L}_1 L1 损失的权重。
最后,为了保持人脸生成的高保真度,我们还施加了对抗损失。注意,我们冻结了鉴别器的参数,因为低质量的视频帧可能会降低其性能。对抗性损失可定义为:
L a d v c = − E [ log ( D ( I ^ c ) ) ] \mathcal{L}_{a d v}^c=-\mathbb{E}\left[\log \left(D\left(\hat{I}_c\right)\right)\right] Ladvc=−E[log(D(I^c))]
这里 D D D 是 StyleGAN2训练好的判别器。
图7所示。高分辨率谈话脸生成。最上面一行:一张真实的脸是由一张真实的脸驱动的。下一排:一个合成的脸是由一个真实的脸驱动。真实人脸来自HDTF[72]。合成人脸从StyleGAN中采样。PIRenderer生成的图像分辨率为256×256,而我们生成的图像分辨率为1024×1024。

图8所示。与增强方法的比较。我们使用最近的面部恢复(FR)方法来提高这些竞争方法的视觉质量,即GFP-GAN[59]。
该框架以端到端方式进行训练,同时计算相应的运动生成器的损失。这里,我们计算运动生成器的中间结果与地面真实之间的感知损失,与Eq. 5相同。其他组件(StyleGAN生成器和反转编码器)的权重被冻结。
综上所述,总损失为以下加权总和:
L c = L t c + λ d c ⋅ L domain c + λ a d v c ⋅ L a d v c + β v ⋅ L v + β a ⋅ L a , \mathcal{L}^c=\mathcal{L}_t^c+\lambda_d^c \cdot \mathcal{L}_{\text {domain }}^c+\lambda_{a d v}^c \cdot \mathcal{L}_{a d v}^c+\beta^v \cdot \mathcal{L}^v+\beta^a \cdot \mathcal{L}^a, Lc=Ltc+λdc⋅Ldomain c+λadvc⋅Ladvc+βv⋅Lv+βa⋅La,
其中 λ d c , λ a d v c , β v \lambda_d^c, \lambda_{a d v}^c, \beta^v λdc,λadvc,βv 和 β a \beta^a βa 是对应的权重。
5. 实验
5.1 设置
数据集。我们在VoxCeleb数据集[36]上训练两个运动生成器,该数据集由1,251个主题的超过100K个视频组成。接下来[40],我们通过裁剪视频中的人脸来预处理数据,然后将其大小调整为256×256。面不对齐,可以在固定的边界框内自由移动。我们在HDTF数据集[72]上联合训练整个框架,该数据集由300多个主题的362个视频组成。原始视频分辨率为720 < <或者1080 < <,高于VoxCeleb。视频以与处理VoxCeleb相同的方式裁剪,然后调整大小为512×512。HDTF被分成不重叠的训练集和测试集。测试集包含20个视频,帧数约为10K。为了进行跨身份运动转移评估,我们还从CelebA-HQ数据集中选择了1000张高分辨率图像[25]。
实现细节。我们分两个阶段训练两个运动发生器和标定网络。在第一阶段,我们在VoxCeleb上对基于视频的运动生成器进行了20万次迭代的预训练。然后,我们使用预测的运动作为伪标签,为基于音频的运动生成器制定训练对。我们用合成的音频-运动对对基于音频的生成器进行了20万次迭代的预训练。权衡超参数设置为: λ 1 a = 10 \lambda_1^a=10 λ1a=10, λ r a = 0.1 \lambda_r^a=0.1 λra=0.1 and λ s a = 1 \lambda_s^a=1 λsa=1.。两个预训练过程的优化器都是ADAM[32],初始学习率为10−4。所有实验的批量大小设置为20。
由于来自预训练生成器的运动不能无缝地应用于StyleGAN的特征图,我们需要与校准网络一起对它们进行微调。因此,在第二阶段,我们首先在HDTF上以端到端方式共同优化校准网络和基于视频的运动生成器,进行20K迭代。超参数设置为: λ 1 c = 10 , λ d c = 0.01 , λ a d v c = 0.1 \lambda_1^c=10, \lambda_d^c=0.01, \lambda_{a d v}^c=0.1 λ1c=10,λdc=0.01,λadvc=0.1, β v = 0.01 \beta^v=0.01 βv=0.01, 和 β a = 0 \beta^a=0 βa=0。学习速率分别为10−4和2×10−5。然后,我们对基于视频的运动生成器进行了修复,并对基于音频的运动生成器和标定网络进行了20K次迭代优化。超参数设置为: λ 1 c = 10 , λ d c = 0.01 , λ a d v c = 0.1 , β v = 0 \lambda_1^c=10, \lambda_d^c=0.01, \lambda_{a d v}^c=0.1, \beta^v=0 λ1c=10,λdc=0.01,λadvc=0.1,βv=0, 和 β a = 0.01 \beta^a=0.01 βa=0.01.。学习率设置与上述优化相同。
在推理过程中,两个运动发生器可以单独使用,也可以联合使用。当两者同时使用时,基于视频的运动生成器控制头部姿势,而基于音频的运动生成器控制嘴唇运动。
在我们的框架中,使用GAN反演来获得空间特征映射。几乎所有现有的GAN反转技术都可以被利用。优化技术可以获得更精确的重建结果,但效率不高。虽然基于学习的技术更快,但它们遇到的重建质量较低。考虑到效率,我们在训练过程中采用了最先进的基于学习的反演方法[55]。在推理过程中,我们首先使用[55]获得风格代码和特征映射。对于运动传递任务,我们进一步利用基于优化的反演方法[78]来优化潜在特征映射,以获得更准确的重建。对于编辑任务,我们直接使用[55]中的样式代码和特征图。
评价指标。我们利用一组指标来评估图像质量和运动传输质量。对于图像质量,使用学习感知图像斑块相似度(LPIPS)[71]、峰值信噪比(PSNR)作为衡量重建质量的指标。使用结构相似度(SSIM)来度量输入图像patch之间的结构相似度。利用Frechet Inception Distance (FID)[20]来衡量合成结果的真实感。为了衡量身份保持,我们计算源图像和从ArcFace中提取的生成视频之间身份嵌入的余弦相似度(CSIM)[13]。在运动传递质量方面,本文[38]采用平均表达距离(Average Expression Distance, AED)和平均姿态距离(Average Pose Distance, APD)分别计算生成图像与目标图像在3DMM表达和姿态方面的差异
5.2 高分辨率说话脸生成
由于我们的框架是基于预训练的StyleGAN,它可以生成分辨率为1024 × 1024的高质量图像。目前已有两篇文献将分辨率提高到512×512,分别为[58]和[72]。它们都是在新收集的高分辨率数据集上训练的,即TalkingHead-1KH和HDTF。然而,他们既没有发布源代码,也没有发布预训练的模型,这给我们与他们比较视觉质量设置了障碍。有很多方法可以达到256 × 256的分辨率。其中,最近发表的PIRenderer[38]和HeadGAN[15]因其令人满意的视觉质量而脱颖而出。由于PIRenderer提供了源代码和检查点,这里我们将其与之进行比较以进行说明。
图7显示了PIRenderer和我们的一些可视化结果。我们用一张真实的脸来驱动一张合成的脸或一张真实的脸。合成图像从StyleGAN中随机采样。可以看出,这两种方法都可以很好地传递头部姿势和面部表情。然而,由于低分辨率,PIRenderer看起来模糊并且丢失了一些面部细节。虽然我们的高分辨率结果包含了更多的视觉细节,尤其是眼睛,嘴巴和头发周围。瞳孔,皱纹,斑点,甚至一根头发都可以被注意到。
人脸修复技术能否促进低分辨率方法的发展?我们将Bi-layer、formm和PIRenderer与最先进的盲脸恢复方法GFP-GAN[59]结合起来,以提高分辨率和图像质量。GFP-GAN利用StyleGAN先前的图像来恢复面部细节。将这些方法的分辨率提高到1024×1024。这些增强方法和我们的方法的结果如图8所示。我们可以观察到GFP-GAN大大提高了这些低分辨率方法的视觉质量。然而,它也带来了很多副作用。首先,面部过度平滑。皮肤上的细节被去除,小皱纹和胡须也不见了。头发和眉毛的质地变弱了。相反,在我们的结果中,一根头发或眉毛是可见的。第二,肤色从源头上变得不同。我们的方法使色调更好。第三,光照与源相比也发生了变化。此外,人脸恢复不能弥补产生的伪影。例如,由PIRenderer生成的嘴巴中的工件在修复后仍然存在。结果表明,我们的方法在图像质量方面优于竞争对手的方法,即使它们被人脸恢复方法增强。
5.3 视频驱动的人脸再现
为了评估视频驱动的动作传输的性能,我们进行了两个面部再现任务,即同一身份再现和跨身份再现。对于同一身份再现,源人像的身份与驾驶视频的身份相同。对于跨身份再现,源人像的身份与驾驶视频的身份不同。由于源身份和驱动身份之间的面部形状差距,后者比前者更具挑战性。
对于相同的情况,我们从HDTF数据集中选择20个测试视频进行实验。我们将第一帧作为源人像,接下来的500帧作为驾驶视频。因此,我们有10000个合成帧,每个合成帧都有一个相应的真值帧。
对于交叉身份案例,我们使用CelebAHQ数据集的1000张图像作为源肖像,使用HDTF的20个测试视频作为驾驶视频。我们使用每个驾驶视频的前100帧来驱动50个源图像。因此,我们可以获得100,000张合成图像。由于在这种情况下我们没有ground-truth图像,我们只能计算合成图像的FID,源图像和合成图像之间的CSIM,以及驱动图像和合成图像之间的AED和APD。
我们将我们的方法与几种最先进的方法进行了比较,包括X2Face[64]、Bi-layer[68]、FOMM[40]和PIRenderer[38]。所有这些方法都是开源的。我们使用官方发布的检查点进行评估。
图9所示。同身份再现任务的定性比较与最新方法。

表2。与最先进的说话面部运动传递方法的定量比较。
图10所示。跨身份再现任务的定性比较与最新的方法。
定性评估。同一恒等式和交叉恒等式的视觉结果分别如图9和图10所示。我们的方法可以获得比其他方法更好的图像分辨率和质量,这在第5.2节中已经详细说明。这里我们关注其他方面。在相同的情况下,除X2Face外,所有方法在转移姿势上都表现良好。当源图像的姿态与驱动图像相差很大时(见图9最后一行),X2Face会出现极端的失真。在表达方面,我们的方法在源图像与驱动图像的表达差异较大时表现优于其他方法,特别是当源图像的口关闭而驱动图像的口打开较大时。例如,在图9的第一和第三行中,其他方法在口腔内遇到扭曲。他们无法产生干净的牙齿,而我们的方法效果要好得多。
在交叉身份的情况下,其他方法出现的问题更多,而我们的方法可以稳定地工作。formm遭受头部扭曲。由于它纯粹基于二维扭曲,很难处理源图像和驱动图像之间的头部形状间隙。我们发现PIRenderer在处理眼睛注视方面并不完美。例如,在第一行中,PIRenderer合成了闭着眼睛的图像,与驾驶图像相比,这是意料之外的。同样的问题也出现在最后两行。PIRenderer将运动场应用于输入图像,然后在图像空间中使用网络进行细化。不同的是,利用预训练的StyleGAN框架,我们将预测运动应用于特征映射,并设计一个校准网络来纠正特征空间中的失真。预训练的参数将校准的特征映射转换为高质量的图像。我们将PIRenderer的性能提升归功于StyleGAN中强大的图像。
定量评价。两个重演任务的定量结果如表2所示。我们的FID在这些情况下是最好的,这表明我们合成的人脸比其他方法更真实。这是提高图像分辨率以覆盖更多视觉细节的好处。较好的LPIPS和PSNR意味着较好的重建性能。有趣的是,FOMM在同一身份再现中实现了最好的CSIM,而在跨身份再现中实现了较差的CSIM。其中一个原因是,当源图像和驱动图像之间没有面部形状间隙时,formm表现良好。但当形状差距较大时,头部变形较大,对人脸识别模型的身份相似度影响很大。由于我们的方法使用GAN反演方法来获取特征映射,在重构过程中不可避免地丢失了一些身份信息。这可能会导致相同身份情况下的较低CSIM。相反,我们在交叉身份情况下的最佳CSIM表明,我们的方法可以在这种更具挑战性的设置中稳定地工作,并且遭受较少的失真。我们的AED和APD在两个重现任务中与PIRenderer相当。
5.4 音频驱动的说话脸生成
图11所示。音频驱动的说话脸生成的定性结果。第1行:提供音频的视频。第1列:源图像。第2-4栏:音频驱动唇动生成。第5-7栏:视频和音频共同驱动的说话面孔生成。视频控制姿势,音频控制嘴唇动作。

图16所示。与wav2lip的比较[37]。音频用于驱动唇动的生成。第二行表示音频片段的真实帧。第三行显示了wav2lip生成的结果。底部显示了我们的结果。
在我们的框架中,基于音频的运动生成器可以单独工作,也可以与基于视频的运动生成器一起工作。两种情况的视觉结果如图11所示。第一行表示提供音频的视频。第一列表示要动画化的源肖像。从第二到第五列合成的面孔纯粹是由驱动音频生成的。而最后三列的合成人脸是根据驾驶视频和音频生成的。驾驶视频控制头部姿势,而音频控制嘴唇运动。
对于音频驱动的情况,可以观察到生成的唇部运动与不同源人像的真实视频一致。在音频和视频驱动的情况下,实验结果表明,姿态被视频精确控制,唇部运动与视频保持一致。视觉控制和声学控制都可以推广到不同的身份。
我们还比较了最先进的音频驱动的说话脸生成方法wav2lip[37]。可视化结果如图16所示。我们的结果比wav2lip有更好的视觉质量,因为wav2lip不能处理高分辨率输入。wav2lip的口部模糊,没有合成牙齿。
5.5 说话人脸视频编辑
我们的框架支持两种类型的人脸编辑,即全局人脸属性编辑和直观人脸编辑。
全局属性编辑。由于我们的模型是建立在预训练的StyleGAN上的,它继承了StyleGAN的一个强大的属性,即通过现有的GAN反演方法在潜在风格空间中编辑面部属性。该框架的一个显著优点是效率高,因为我们可以在对话视频生成过程中随时自由编辑面部属性,只需要执行一次GAN反转。属性编辑和特征编辑发生在StyleGAN的同一个前向过程中。相反,对于其他单镜头说话头方法,如果他们打算改变每一帧的属性,他们必须先进行GAN反演以获得编辑后的图像,然后对该图像进行运动转移。因此,他们必须对所有帧执行多次GAN反转,这相当耗时。
图12所示。通过GAN反转进行全局属性编辑。该属性在每个生成的谈话视频中逐渐被修改。从上到下,编辑的属性依次是:化妆、胡须、年龄递增、年龄递减。
图13所示。直观人脸编辑的定性结果。第1行:驱动3DMM参数。第1列:源图像。第2-4列:由PIRenderer合成的图像。第5-7列:我们的合成图像。
我们的框架便于全局编辑属性。我们应用GAN反演方法[55]来获得第一帧的潜在样式代码。然后,在视频生成过程中,我们可以自由地应用预定义的样式方向,以可控的程度改变样式代码。我们可以通过在任何时间戳的样式代码中添加样式方向的移位来有效地修改属性。图12给出了逐步编辑视频中化妆、胡须、年龄等几个属性的视觉效果。可以看出,属性编辑是稳定的,对运动传递没有副作用,即属性编辑和运动传递是互不干扰的。
直观的编辑。我们的基于视频的运动生成器使用驾驶图像的3DMM参数来指导源图像的运动生成。由于基于3DMM的说话脸生成方法[15,38]总是能够对姿态和表情进行直观的编辑,这也使得我们可以通过直接修改3DMM参数来控制运动的生成,从而对最终的合成进行直观的编辑。我们比较了最先进的基于3DMM的方法PIRenderer[38]。结果如图13所示。PIRenderer和我们的方法都可以准确地从3DMM参数中转移姿态和表情。但由于StyleGAN保留了面部先验,我们可以在分辨率,纹理和光照方面实现更好的视觉质量。例如第三排,在不同的姿势和表情下,源人像的噪声和检查上的光照被完美地保留下来。而PIRenderer合成图像的光照变得不那么明显。
5.6 消融实验
我们进行消融研究,以验证我们的框架中几个重要设计的有效性,这些设计可以提高图像质量。
校正网络。直接将流场应用于特征图将导致眼睛和嘴巴周围出现明显的伪影,例如,对于闭合的嘴巴,2D翘曲无法生成牙齿。因此,我们设计了校正网络来校正特征空间中由翘曲引起的伪影。我们比较了有和没有校准网络的性能。结果如图14所示。可以看出,不使用标定网络,模型不能正确生成牙齿和闭眼。该矫正网络极大地改善了眼口周围的形状和内容。
域损失。校正网络修改特征映射。为了防止编辑后的特征图偏离原始特征图,我们设计了域损失。我们比较了有和没有域损耗时的性能。结果如图15所示。我们可以观察到,减少损失会使合成图像模糊,并且失去面部细节,如皱纹和头发纹理。
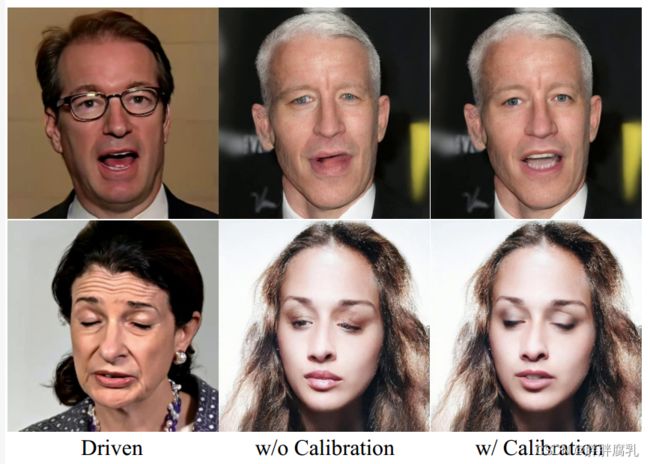
图14所示。校准网络的消融研究。

图15所示。域损失的烧蚀研究。
6. 局限性与讨论
我们提出的方法也有一些局限性。图17显示了两种失效情况。首先,现有的GAN反演方法并不完美:由于特征映射中的信息丢失,无法完全避免重构误差。如第一行所示,源人像的发带纹理严重失真。

图17。一些失败案例。合成图像不能很好地保留头带区域(上)和手遮挡区域(下)。
这种类型的故障可以通过使用未来开发的更好的GAN反转技术来缓解。其次,我们的框架目前无法处理面部咬合。如第二行所示,合成图像中被遮挡区域周围有明显的伪影。这是所有现有的说话脸生成方法的共同问题,需要在未来解决。
如文献[26]所述,StyleGAN2生成的图像存在纹理粘附伪影,这意味着合成视频中的头发和面部通常不会同步移动。 Alias-Free GAN[26]设计了一个特定的架构来克服这个问题。当研究高质量的GAN反演方法时,我们的框架可以迁移到新的生成器上。
7. 结论
我们提出了一种基于预训练StyleGAN的单镜头说话人脸生成新框架。强大的StyleGAN实现了一组强大的功能:高分辨率的谈话视频生成(1024×1024首次),通过驱动视频和音频来解开控制,以及灵活的面部编辑。该系统由基于视频的运动生成模块、基于音频的运动生成模块和校准网络组成,与预先训练好的StyleGAN协同生成高质量的说话人脸。该框架支持视频驱动的再现、音频驱动的再现以及视频和音频联合驱动的再现。此外,我们的框架允许两种类型的人脸编辑,即通过GAN反演的全局属性编辑和基于3DMM的直观编辑。我们进行全面的实验来说明我们统一框架的各种能力,包括消融研究和与许多最先进方法的比较。
参考文献
[1] Rameen Abdal, Yipeng Qin, and Peter Wonka. 2019. Image2stylegan: How to embed images into the stylegan latent space?. In CVPR.
[2] Rameen Abdal, Yipeng Qin, and Peter Wonka. 2020. Image2StyleGAN++: How to Edit the Embedded Images?. In CVPR.
[3] Rameen Abdal, Peihao Zhu, Niloy J Mitra, and Peter Wonka. 2021. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional continuous normalizing flows. TOG (2021).
[4] Yuval Alaluf, Or Patashnik, and Daniel Cohen-Or. 2021. Restyle: A residual-based stylegan encoder via iterative refinement. In ICCV.
[5] Anonymous. 2022. Latent Image Animator: Learning to animate image via latent space navigation. In ICLR.
[6] Aayush Bansal, Shugao Ma, Deva Ramanan, and Yaser Sheikh. 2018. Recycle-gan: Unsupervised video retargeting. In ECCV.
[7] Volker Blanz and Thomas Vetter. 1999. A morphable model for the synthesis of 3D faces. In SIGGRAPH.
[8] James Booth, Anastasios Roussos, Stefanos Zafeiriou, Allan Ponniah, and David Dunaway. 2016. A 3d morphable model learnt from 10,000 faces. In CVPR.
[9] Egor Burkov, Igor Pasechnik, Artur Grigorev, and Victor Lempitsky. 2020. Neural head reenactment with latent pose descriptors. In CVPR.
[10] Anpei Chen, Ruiyang Liu, Ling Xie, Zhang Chen, Hao Su, and Jingyi Yu. 2020. Sofgan: A portrait image generator with dynamic styling. arXiv preprint
arXiv:2007.03780 (2020).
[11] Joon Son Chung and Andrew Zisserman. 2016. Out of time: automated lip sync in the wild. In ACCV.
[12] Daniel Cudeiro, Timo Bolkart, Cassidy Laidlaw, Anurag Ranjan, and Michael J Black. 2019. Capture, learning, and synthesis of 3D speaking styles. In CVPR.
[13] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In CVPR.
[14] Yu Deng, Jiaolong Yang, Sicheng Xu, Dong Chen, Yunde Jia, and Xin Tong. 2019. Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set. In CVPR Workshops.
[15] Michail Christos Doukas, Stefanos Zafeiriou, and Viktoriia Sharmanska. 2021. HeadGAN: One-shot Neural Head Synthesis and Editing. In ICCV.
[16] Gereon Fox, Ayush Tewari, Mohamed Elgharib, and Christian Theobalt. 2021. Stylevideogan: A temporal generative model using a pretrained stylegan. arXiv
preprint arXiv:2107.07224 (2021).
[17] Ohad Fried, Ayush Tewari, Michael Zollhöfer, Adam Finkelstein, Eli Shechtman, Dan B Goldman, Kyle Genova, Zeyu Jin, Christian Theobalt, and Maneesh
Agrawala. 2019. Text-based editing of talking-head video. TOG (2019).
[18] Jiahao Geng, Tianjia Shao, Youyi Zheng, Yanlin Weng, and Kun Zhou. 2018. WarpGuided GANs for Single-Photo Facial Animation. TOG (2018).
[19] Yudong Guo, Keyu Chen, Sen Liang, Yongjin Liu, Hujun Bao, and Juyong Zhang. AD-NeRF: Audio Driven Neural Radiance Fields for Talking Head Synthesis. In ICCV.
[20] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. NIPS (2017).
[21] Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In ICCV.
[22] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. 2017. Image-toImage Translation with Conditional Adversarial Networks. CVPR (2017).
[23] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. 2016. Perceptual losses for realtime style transfer and super-resolution. In ECCV.
[24] Kyoungkook Kang, Seongtae Kim, and Sunghyun Cho. 2021. GAN Inversion for Out-of-Range Images with Geometric Transformations. In CVPR.
[25] Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. 2018. Progressive growing of gans for improved quality, stability, and variation. In ICLR.
[26] Tero Karras, Miika Aittala, Samuli Laine, Erik Härkönen, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2021. Alias-free generative adversarial networks. In NIPS.
[27] Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In CVPR.
[28] Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, and Timo Aila. 2020. Analyzing and improving the image quality of stylegan. In CVPR.
[29] Hyunsu Kim, Yunjey Choi, Junho Kim, Sungjoo Yoo, and Youngjung Uh. 2021. Exploiting Spatial Dimensions of Latent in GAN for Real-Time Image Editing. In CVPR.
[30] Hyeongwoo Kim, Mohamed Elgharib, Michael Zollhöfer, Hans-Peter Seidel, Thabo Beeler, Christian Richardt, and Christian Theobalt. 2019. Neural style-preserving visual dubbing. TOG (2019).
[31] Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Pérez, Christian Richardt, Michael Zollhöfer, and Christian Theobalt. 2018. Deep video portraits. TOG (2018).
[32] Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
[33] Avisek Lahiri, Vivek Kwatra, Christian Frueh, John Lewis, and Chris Bregler. 2021. LipSync3D: Data-Efficient Learning of Personalized 3D Talking Faces from Video using Pose and Lighting Normalization. In CVPR.
[34] Yuanxun Lu, Jinxiang Chai, and Xun Cao. 2021. Live Speech Portraits: Real-Time
Photorealistic Talking-Head Animation. TOG (2021).
[35] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2020. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV.
[36] Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. 2017. Voxceleb: a large-scale speaker identification dataset. In INTERSPEECH.
[37] KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In ACM Multimedia.
[38] Yurui Ren, Ge Li, Yuanqi Chen, Thomas H Li, and Shan Liu. 2021. PIRenderer: Controllable Portrait Image Generation via Semantic Neural Rendering. In ICCV.
[39] Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, and Daniel Cohen-Or. 2021. Encoding in style: a stylegan encoder for image-to-image translation. In CVPR.
[40] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019. First order motion model for image animation. NIPS (2019). [41] Aliaksandr Siarohin, Stéphane Lathuilière, Sergey Tulyakov, Elisa Ricci, and Nicu Sebe. 2019. Animating Arbitrary Objects via Deep Motion Transfer. In CVPR.
[42] Aliaksandr Siarohin, Oliver J Woodford, Jian Ren, Menglei Chai, and Sergey Tulyakov. 2021. Motion Representations for Articulated Animation. In CVPR.
[43] Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014).
[44] Ivan Skorokhodov, Sergey Tulyakov, and Mohamed Elhoseiny. 2021. StyleGANV: A Continuous Video Generator with the Price, Image Quality and Perks of StyleGAN2.
[45] Guoxian Song, Linjie Luo, Jing Liu, Wan-Chun Ma, Chunpong Lai, Chuanxia Zheng, and Tat-Jen Cham. 2021. AgileGAN: stylizing portraits by inversionconsistent transfer learning. TOG (2021).
[46] Linsen Song, Wayne Wu, Chaoyou Fu, Chen Qian, Chen Change Loy, and Ran He. 2021. Everything’s Talkin’: Pareidolia Face Reenactment. arXiv preprint arXiv:2104.03061 (2021).
[47] Supasorn Suwajanakorn, Steven M Seitz, and Ira Kemelmacher-Shlizerman. 2017. Synthesizing obama: learning lip sync from audio. TOG (2017).
[48] Sarah Taylor, Taehwan Kim, Yisong Yue, Moshe Mahler, James Krahe, Anastasio Garcia Rodriguez, Jessica Hodgins, and Iain Matthews. 2017. A deep learning approach for generalized speech animation. TOG (2017).
[49] Ayush Tewari, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick Pérez, Michael Zöllhofer, and Christian Theobalt. 2020. StyleRig: Rigging StyleGAN for 3D Control over Portrait Images, CVPR 2020. In CVPR. IEEE.
[50] Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, and Matthias Nießner. 2020. Neural voice puppetry: Audio-driven facial reenactment. In ECCV.
[51] Yu Tian, Jian Ren, Menglei Chai, Kyle Olszewski, Xi Peng, Dimitris N Metaxas, and Sergey Tulyakov. 2021. A good image generator is what you need for highresolution video synthesis. In ICLR.
[52] Rotem Tzaban, Ron Mokady, Rinon Gal, Amit H Bermano, and Daniel Cohen-Or. Stitch it in Time: GAN-Based Facial Editing of Real Videos. arXiv preprint arXiv:2201.08361 (2022).
[53] Suzhen Wang, Lincheng Li, Yu Ding, Changjie Fan, and Xin Yu. 2021. Audio2Head: Audio-driven One-shot Talking-head Generation with Natural Head Motion. IJCAI (2021).
[54] Suzhen Wang, Lincheng Li, Yu Ding, and Xin Yu. 2021. One-shot Talking Face Generation from Single-speaker Audio-Visual Correlation Learning. arXiv preprint arXiv:2112.02749 (2021).
[55] Tengfei Wang, Yong Zhang, Yanbo Fan, Jue Wang, and Qifeng Chen. 2021. Highfidelity gan inversion for image attribute editing. arXiv preprint arXiv:2109.06590 (2021).
[56] Ting-Chun Wang, Ming-Yu Liu, Andrew Tao, Guilin Liu, Jan Kautz, and Bryan Catanzaro. 2019. Few-shot video-to-video synthesis. arXiv preprint arXiv:1910.12713 (2019).
[57] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Guilin Liu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. 2018. Video-to-video synthesis. arXiv preprint arXiv:1808.06601 (2018).
[58] Ting-Chun Wang, Arun Mallya, and Ming-Yu Liu. 2021. One-shot free-view neural talking-head synthesis for video conferencing. In CVPR.
[59] Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. 2021. Towards Real-World Blind Face Restoration with Generative Facial Prior. In CVPR.
[60] Xintao Wang, Ke Yu, Chao Dong, and Chen Change Loy. 2018. Recovering realistic texture in image super-resolution by deep spatial feature transform. In CVPR.
[61] Tianyi Wei, Dongdong Chen, Wenbo Zhou, Jing Liao, Weiming Zhang, Lu Yuan, Gang Hua, and Nenghai Yu. 2021. A Simple Baseline for StyleGAN Inversion. arXiv preprint arXiv:2104.07661 (2021).
[62] Xin Wen, Miao Wang, Christian Richardt, Ze-Yin Chen, and Shi-Min Hu. 2020. Photorealistic Audio-driven Video Portraits. TVCG (2020).
[63] Wikipedia contributors. 2020. Thin plate spline — Wikipedia, The Free Encyclopedia. https://en.wikipedia.org/wiki/Thin_{}plate_{}spline[64] Olivia Wiles, A Koepke, and Andrew Zisserman. 2018. X2face: A network for controlling face generation using images, audio, and pose codes. In ECCV.
[65] Haozhe Wu, Jia Jia, Haoyu Wang, Yishun Dou, Chao Duan, and Qingshan Deng. Imitating Arbitrary Talking Style for Realistic Audio-Driven Talking Face Synthesis. In ACM Multimedia.
[66] Wayne Wu, Yunxuan Zhang, Cheng Li, Chen Qian, and Chen Change Loy. 2018. Reenactgan: Learning to reenact faces via boundary transfer. In ECCV.
[67] Ran Yi, Zipeng Ye, Juyong Zhang, Hujun Bao, and Yong-Jin Liu. 2020. Audiodriven talking face video generation with learning-based personalized head pose. arXiv preprint arXiv:2002.10137 (2020).
[68] Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, and Victor Lempitsky. Fast bi-layer neural synthesis of one-shot realistic head avatars. In ECCV.
[69] Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, and Victor Lempitsky. 2019. Few-shot adversarial learning of realistic neural talking head models. In ICCV.
[70] Chenxu Zhang, Yifan Zhao, Yifei Huang, Ming Zeng, Saifeng Ni, Madhukar Budagavi, and Xiaohu Guo. 2021. FACIAL: Synthesizing Dynamic Talking Face With Implicit Attribute Learning. In ICCV.
[71] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR.
[72] Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. 2021. Flow-Guided One-Shot Talking Face Generation With a High-Resolution Audio-Visual Dataset. In CVPR.
[73] Hang Zhou, Yu Liu, Ziwei Liu, Ping Luo, and Xiaogang Wang. 2019. Talking face generation by adversarially disentangled audio-visual representation. In AAAI.
[74] Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. 2021. Pose-controllable talking face generation by implicitly modularized audio-visual representation. In CVPR.
[75] Yang Zhou, Xintong Han, Eli Shechtman, Jose Echevarria, Evangelos Kalogerakis,
and Dingzeyu Li. 2020. MakeitTalk: speaker-aware talking-head animation. TOG (2020).
[76] Jiapeng Zhu, Yujun Shen, Deli Zhao, and Bolei Zhou. 2020. In-domain gan inversion for real image editing. In European conference on computer vision.
[77] Jun-Yan Zhu, Philipp Krähenbühl, Eli Shechtman, and Alexei A Efros. 2016. Generative visual manipulation on the natural image manifold. In ECCV.
[78] Peihao Zhu, Rameen Abdal, John Femiani, and Peter Wonka. 2021. Barbershop: GAN-based Image Compositing using Segmentation Masks. arXiv preprint arXiv:2106.01505 (2021).