YOLOv5算法改进(7)— 添加SimAM注意力机制

前言:Hello大家好,我是小哥谈。SimAM(Similarity-based Attention Mechanism)是一种基于相似度的注意力机制,它的原理是通过计算查询向量与每个键向量之间的相似度,从而确定每个键向量对于查询向量的重要性,然后根据这些重要性给每个值向量分配一个权重,最终得到加权的值向量表示。SimAM相比于其他注意力机制的优点在于,它不需要额外的参数进行学习,而是通过计算相似度得分来确定每个键向量的重要性,从而实现了轻量化和高效的注意力机制。
 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
YOLOv5算法改进(4)— 添加CA注意力机制
YOLOv5算法改进(5)— 添加ECA注意力机制
YOLOv5算法改进(6)— 添加SOCA注意力机制
目录
1.论文
2.SimAM注意力机制方法及优缺点
3.在Backbone末端添加SimAM注意力机制方法
步骤1:在common.py中添加SimAM模块
步骤2:在yolo.py文件中加入类名
步骤3:创建自定义yaml文件
步骤4:修改yolov5s_SimAM.yaml文件
步骤5:验证是否加入成功
步骤6:修改train.py中的'--cfg'默认参数
4.在C3后面添加SimAM注意力机制的方法
步骤1:修改yaml文件
步骤2:验证是否加入成功

1.论文
本文是中山大学在注意力机制方面的尝试,从神经科学理论出发,构建了一种能量函数挖掘神经元重要性,并对此推导出了解析解以加速计算。SimAM(Similarity-based Attention Mechanism)是一种基于相似度的注意力机制,它的原理是通过计算查询向量与每个键向量之间的相似度,从而确定每个键向量对于查询向量的重要性,然后根据这些重要性给每个值向量分配一个权重,最终得到加权的值向量表示。SimAM相比于其他注意力机制的优点在于,它不需要额外的参数进行学习,而是通过计算相似度得分来确定每个键向量的重要性,从而实现了轻量化和高效的注意力机制。值得一提的是,SimAM是一种无参数注意力模块。

本文主要贡献包含以下几点:
-
受启发于人脑注意力机制,本文提出一种3D注意力模块并设计了一种能量函数用于计算注意力权值;
-
本文推导出了能量函数的解析解加速了注意力权值的计算并得到了一种轻量型注意力模块;
-
将所提注意力嵌入到现有ConvNet中在不同任务上进行了灵活性与有效性的验证。
论文题目:《SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks》
论文地址: SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks
代码实现: https://github.com/ZjjConan/SimAM
2.SimAM注意力机制方法及优缺点
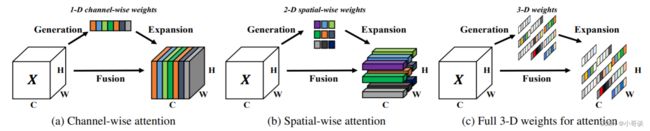
之前的方法:
现有的注意力模块通常被继承到每个块中,以改进来自先前层的输出。这种细化步骤通常沿着通道维度(a)或空间维度(b)操作,这些方法生成一维或二维权重,并平等对待每个通道或空间位置中的神经元。
- 通道注意力:1D注意力,它对不同通道区别对待,对所有位置同等对待;
- 空域注意力:2D注意力,它对不同位置区别对待,对所有通道同等对待。
这可能会限制他们学习更多辨别线索的能力。因此三维权重(c)优于传统的一维和二维权重注意力。✅
本文的方法:
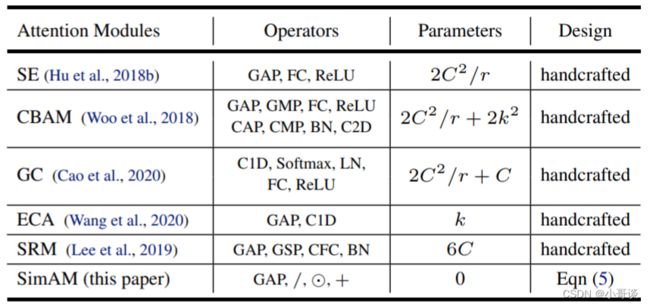
权值生成方法。现有注意力往往采用额外的子网络生成注意力权值,比如SE的GAP+FC+ReLU+FC+Sigmoid。更多注意力模块的操作、参数量可参考下表。总而言之,现有注意力的结构设计需要大量的工程性实验。我们认为:注意力机制的实现应当通过神经科学中的某些统一原则引导设计。
SimAM注意力机制优缺点
注意力机制是深度学习中常用的一种机制,它允许模型在处理序列数据时,能够对不同位置的信息进行加权处理。下面是注意力机制的优缺点:
优点:
(1)提升模型性能:注意力机制可以帮助模型更好地准确捕捉输入序列中重要的信息,提升模型的表现能力。
(2)可解释性强:注意力机制能够计算每个位置的权重,使得模型具有可解释性,可以知道模型在决策时关注了哪些重要的位置或特征。
(3)处理长序列能力强:对于较长的输入序列,注意力机制可以有效地处理,避免信息丢失或冗余。
缺点:
(1)计算复杂度高:注意力机制需要计算每个位置的权重,因此在处理较长的输入序列时,计算量较大,会增加模型的计算复杂度。
(2)学习难度较大:注意力机制需要学习如何计算每个位置的权重,对于一些复杂的任务或数据集,学习过程可能会比较困难。
(3)对齐问题:注意力机制假设输入序列和输出序列之间有对应的对齐关系,但在某些情况下,这种对齐关系可能并不明确或存在困难。
总的来说,注意力机制在深度学习中具有重要的作用,能够提升模型性能和可解释性,但也存在计算复杂度高和学习难度大的问题。在使用注意力机制时需要根据具体任务和数据集的特点进行权衡和选择。
3.在Backbone末端添加SimAM注意力机制方法
步骤1:在common.py中添加SimAM模块
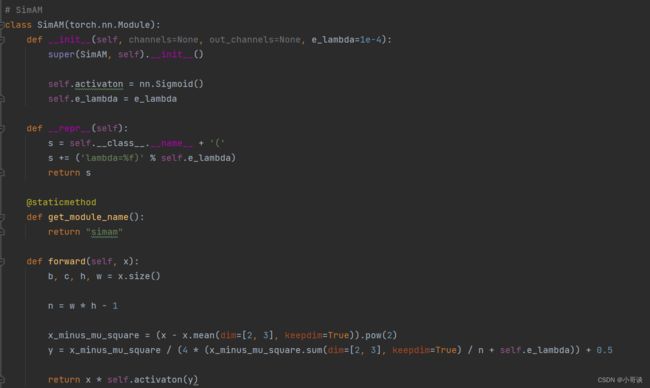
将下面的SimAM模块的代码复制粘贴到common.py文件的末尾。
#SimAM
class SimAM(torch.nn.Module):
def __init__(self, channels=None, out_channels=None, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)具体如下图所示:
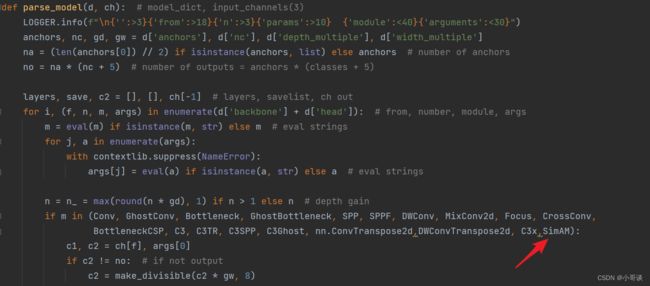
步骤2:在yolo.py文件中加入类名
首先在yolo.py文件中找到parse_model函数,然后将SimAM添加到这个注册表里。
步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_SimAM.yaml。
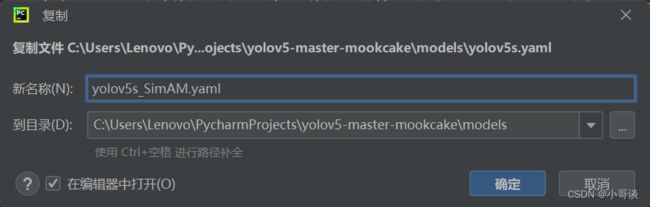
步骤4:修改yolov5s_SimAM.yaml文件
本步骤是修改yolov5s_SimAM.yaml,将SimAM模块添加到我们想添加的位置。
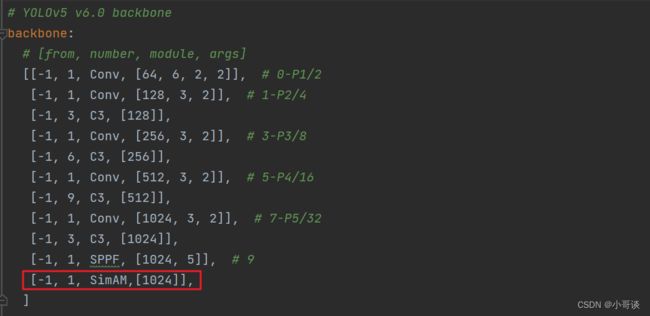
这里我先介绍第一种,第一种是将SimAM模块放在Backbone部分的最末端,这样可以使注意力机制看到整个Backbone部分的特征图,将具有全局视野,类似一个小transformer结构。
在这里,我将[-1,1,SimAM,[1024]]添加到SPPF的下一层,即下图中所示位置。
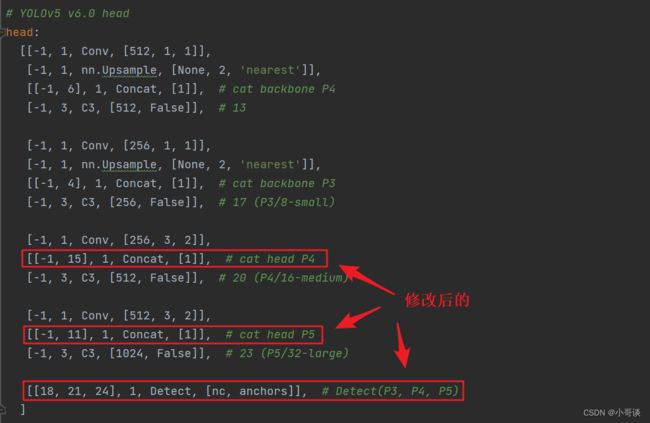
同样的,下面的head也要修改。原本Detect指定的是[17,20,23]层,所以,我们在添加了SimAM模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24]。同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。
具体如下图所示:
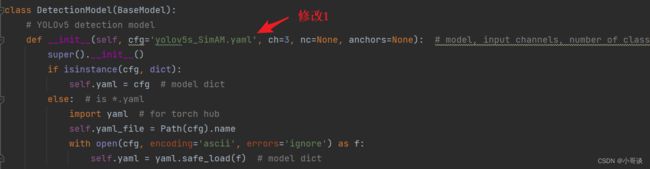
步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_SimAM.yaml。
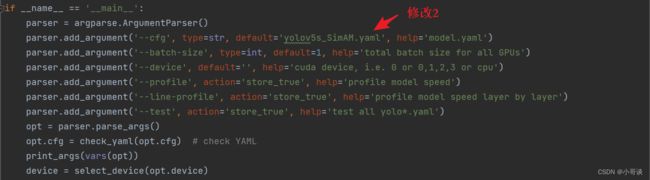
然后运行yolo.py,得到结果。
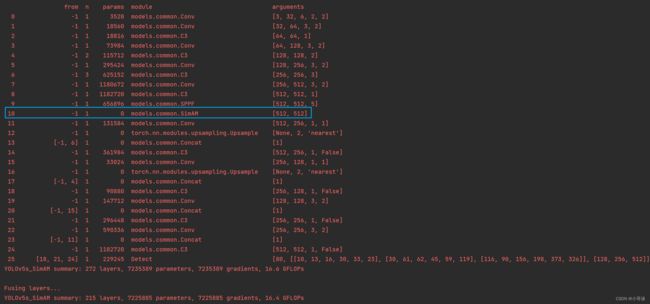
找到了SimAM模块,说明我们添加成功了。
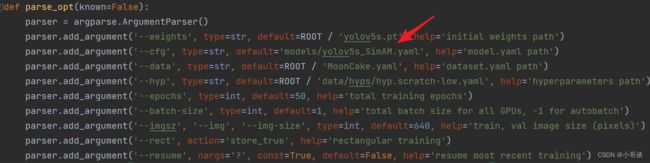
步骤6:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_SimAM.yaml',然后就可以开始进行训练了。
4.在C3后面添加SimAM注意力机制的方法
第二种是将SimAM放在Backbone部分每个C3模块的后面,这样可以使注意力机制看到局部的特征,每层进行一次注意力,可以分担学习压力。
步骤和方法1相同,区别在于yaml文件不同,所以只需修改yaml文件即可。
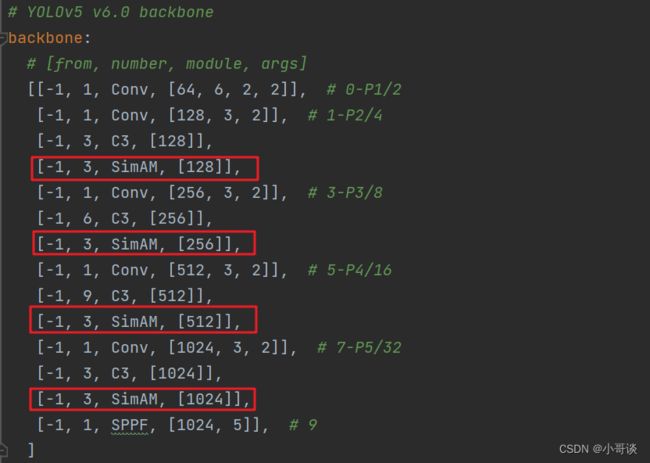
步骤1:修改yaml文件
将SimAM模块放在每个C3模块的后面,要注意通道的变化。
具体如下图所示:
同样的,下面的head也要做同样的修改。

步骤2:验证是否加入成功
运行yolo.py,具体结果如下所示:
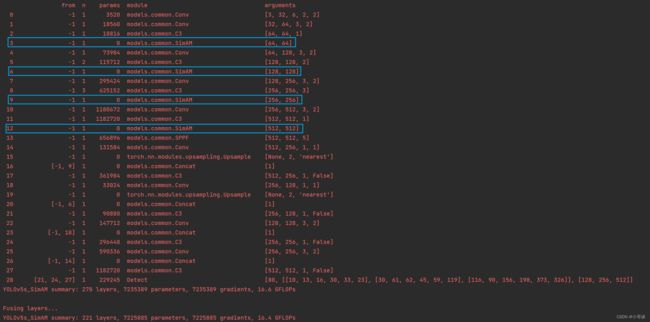
由上图可知,我们添加成功了!