基于DolphinScheduler的调度流程梳理及落地实践

目 录
01 背景
02 主流调度引擎
03 DolphinScheduler核心概念及调度过程
04 开发实践
01
背景
随着数据中台概念及相关技术逐渐成熟、落地,不断有企业将其应用到自身业务中,将原本分散的各系统数据进行整合、分析,挖掘数据价值,为业务发展提供了更多可能。但伴随数据量不断累积,业务中操作大数据的场景越来越多,那么如何高效安全的处理大数据业务?
大数据业务一般包含对数据的Extract(提取)、Transform(转换)、Load(加载) 等步骤,(简称ETL),具体执行时,可分解为多个任务(Shell、Spark、Flink、Hive等)分别执行的,各个任务之间存在依赖关系,同一个任务可能被多条业务引用。最基本的处理方式是为每个任务充足执行时间,按照预留时间,定时执行下一条任务。但在企业应用场景中,每天定时执行的操作数据量大,这种处理方法存在因前置任务执行超时,导致整个业务执行失败的风险,严重时会给企业造成难以弥补的损失。因此,对企业而言,拥有一个安全高效的调度引擎系统至关重要。
02
主流调度引擎
目前主流调度引擎有Apache Oozie、Apache Airflow、Apache DophinScheduler,对比下三者的优缺点:
Apache Oozie只用于管理Hadoop中Hive、Sqoop、Spark、Shell、MR等任务的调度引擎,支持任务类型自定义,任务执行时支持暂停、停止、恢复等操作,支持RestfApi、JavaApi调用;配置调度任务复杂繁琐,不支持可视化任务流程定义,调度任务时可能会出现死锁。
Apache Airflow 使用Python语言编写,支持Python、Bash、HTTP、Mysql等任务及任务类型自定义,不支持可视化DAG任务作业流创建,不支持任务暂停、恢复、补数等操作,Scheduler单线程解析、调度任务,任务过载会卡死服务器,支持高可用但受限于Scheduler易发生单点故障。
Apache DolphinScheduler 旨在解决数据处理过程中复杂的依赖问题,支持Shell、MR、Spark、Hive、Flink等10余种任务类型,支持任务类型自定义,可实现在Web端可视化开发设计任务流程,支持跨语言、多租户、高可用,任务执行时支持暂停、停止、恢复、补数等操作,可查看任务执行信息,支持任务执行日志查看下载,Master、Worker服务支持动态上下线。
显而易见,Apache DolphinScheduler是一款优秀的调度引擎工具。普元数据治理运营平台(DWS)目前便接入了Apache DolphinScheduler 调度系统,远期会集成其他优秀的调度引擎系统。
03
DolphinScheduler
核心概念及调度过程
为更好的了解DolphinScheduler ,先介绍其核心概念:
Task(任务):调度执行的最小单元,包含Shell、Spark、Flink、Sql、MR等多种类型。可设置任务执行优先级、任务执行参数、超时告警、超时失败;
Process(作业流):由任务以有向无环图形式构成,执行时解析作业流为多个任务,可设置作业流优先级,作业执行全局参数、超时告警;
Command(待调度指令):作业流经手动调度或定时调度生成的数据,存储在数据库中;
Instance(实例):作业流、任务执行后,会生成相应的实例,记录执行时作业流、任务的状态及执行内容,任务实例可查看下载日志;
Master(调度服务):提供对作业流手动调度、定时调度、超时告警、任务容错、任务执行监控等功能;
Worker(运行服务):解析作业流,识别任务类型,调用对应任务类型的逻辑,生成作业流、任务实例;
Alert(告警服务):可通过Email、FTP、微信等多种方式,通知作业流、任务执行结果。
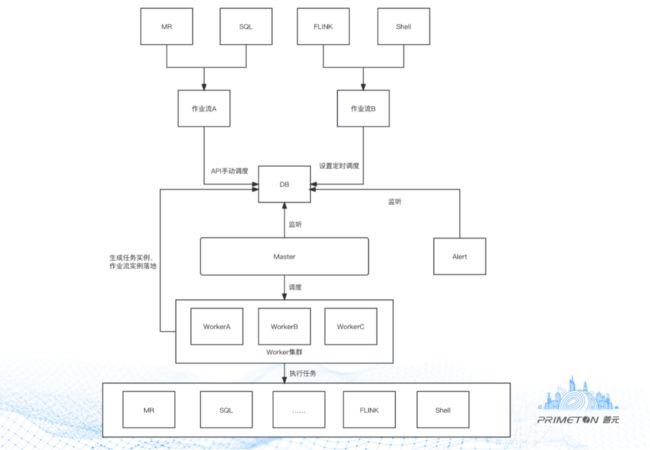
DolphinScheduler 通过DAG(有向无环图)创建任务、作业流,存在Master、Worker、Web、Alert等模块。先通过Web界面创建任务、以DAG形式组成作业流,落地到数据库,而后Web调度该作业流,生成Command数据。Master监听到数据库的Command表有新数据,解析后交由Worker选择对应的任务类型执行,执行完成后,由Alert通知任务执行结果。
下面具体展示下调度任务的创建、被调度执行的过程:
1. 根据具体业务需求,创建ETL Task,组合Task生成Process落库;
2. 手动调度或定时调度生成Command;
3. Master监听读取Command记录,动态分配至Worker;
4. Worker执行完成后,生成Task Instance、Process Instance落库;
5. 告警模块监听Instance,通过Email、FTP等发送任务执行结果。
04
数据开发实践
普元数据治理运营平台(DWS)将ETL作业流构建与调度引擎剥离,采用多引擎模式,区分开发、测试、生产环境。为实现此目标,对DolphinScheduler 调度平台做如下改造:
1. 定制开发了PDI-JOB、PDI-TRANS任务类型,用以支持从开源ETL工具Kettle迁移的JOB、Trans模型运行;
2. 将DolphinScheduler 表ID关联改造为CODE关联,保证切换调度引擎时,历史数据顺利迁移;
3. 适配Kingbase、DM、GBase等多款国产数据库,为信创事业增砖添瓦。
以上内容是本人在数据治理运营平台建设过程中对调度引擎的一些浅见,欢迎留言交流讨论。
 关于作者:曾亮,普元高级工程师,负责普元数据治理运营平台作业调度模块研发,元数据管理平台开发维护等。
关于作者:曾亮,普元高级工程师,负责普元数据治理运营平台作业调度模块研发,元数据管理平台开发维护等。