中文分词和tfidf特征应用
文章目录
- 引言
- 1. NLP 的基础任务 --分词
- 2. 中文分词
-
- 2.1 中文分词-难点
- 2.2 中文分词-正向最大匹配
-
- 2.2.1 实现方式一
- 2.2.2 实现方式二 利用前缀字典
- 2.3 中文分词-反向最大匹配
- 2.4 中文分词-双向最大匹配
- 2.5 中文分词-jieba分词
-
- 2.5.1 基本用法
- 2.5.2 分词模式
- 2.5.3 其他功能
- 2.6 三种方式的缺点
- 2.7 中文分词-基于机器学习
- 3. 关于分词
- 4. 总结经验
- 5. 新词发现
- 6. TF-IDF
-
- 6.1 TF-IDF计算
- 6.2 TFIDF其他版本
- 6.3 算法特点
- 6.4 TFIDF应用-搜索引擎
- 6.5 TFIDF应用-文本摘要
- 6.6 TFIDF应用-文本相似度计算
- 6.7 TFIDF的优势
- 6.8 TFIDF劣势
- 7. TFIDF的计算和使用
引言
中文分词和TF-IDF(Term Frequency-Inverse Document Frequency)是自然语言处理(NLP)中的两个基础技术。
中文分词
因为中文文本没有明显的单词分隔符,所以需要进行分词。常用的分词算法有:
- 基于词典的分词:最长匹配算法、正向最大匹配、逆向最大匹配等。
- 基于统计的分词:隐马尔可夫模型(HMM)、条件随机场(CRF)等。
Python中有现成的分词库,如jieba。
import jieba
sentence = "我爱自然语言处理"
words = jieba.cut(sentence)
print(list(words))
TF-IDF
TF-IDF用于衡量一个词在文档集中的重要性。
- TF(Term Frequency): 词频,一个词在某个文档中出现的次数。
- IDF(Inverse Document Frequency): 逆文档频率,衡量一个词是多么罕见。
TF-IDF值 = TF值 × IDF值
常用于文本挖掘、信息检索等。
应用示例
假设你有一组中文文档,你想找出每个文档中的关键词。
- 首先对每个文档进行中文分词。
- 然后用TF-IDF算法找出每个文档中TF-IDF值高的词。
Python中的Scikit-learn库有现成的TF-IDF实现。
from sklearn.feature_extraction.text import TfidfVectorizer
# 假设已经分词并用空格连接
docs = ["我 爱 自然 语言 处理", "自然 语言 处理 很 有趣", "我 喜欢 学习"]
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(docs)
# 打印特征名和TF-IDF矩阵
print(vectorizer.get_feature_names_out())
print(tfidf.toarray())
通过中文分词和TF-IDF,你可以有效地将文本数据转换为机器可理解的数值型数据,进而用于各种NLP任务,如文本分类、聚类等。
1. NLP 的基础任务 --分词
分词任务
为什么讲分词?
- 分词是一个被长期研究的任务,通过了解分词算法的发展,可以看到NLP的研究历程
- 分词是NLP中一类问题的代表
- 分词很常用,很多NLP任务建立在分词之上
2. 中文分词
2.1 中文分词-难点
中文分词(Chinese Word Segmentation)相比于像英文这样的空格分隔的语言,有一些特有的难点:
- 没有明确分隔符:中文文本没有像英文那样的空格来明确分隔单词,这使得词的界定比较模糊。
- 词汇歧义:一个字可能出现在多个词中,具有不同的含义。例如,“海参”和“参与”中的“参”字。
- 新词识别:时事、网络等经常产生新词,这些词可能不在词典中,很难通过基于词典的方法进行准确分词。
- 复合词和短语:中文中有大量的复合词和成语,如“心有余悸”,这些词组内的单字如果单独拆开,意义会发生改变。
- 多粒度分词:中文分词可按不同的粒度进行,例如“北京大学”可以分为“北京 大学”或“北 京 大 学”,不同的应用场景需要不同粒度的分词。
- 方言和地域性用语:不同地区和群体可能有特定的用语和表达方式,这增加了分词的复杂性。
- 词性多样性:在中文中,同一个词可能作为不同词性出现,在句子中的不同位置可能需要不同的分词方式。
- 噪音和错误:文本中可能存在拼写错误、错别字或非标准用语,这些都可能影响分词的准确性。
由于以上因素,中文分词通常采用基于机器学习或统计的复杂算法,如条件随机场(CRF)、隐马尔可夫模型(HMM)等,以提高分词的准确性。
2.2 中文分词-正向最大匹配
正向最大匹配(Forward Maximum Matching,简称 FMM)是一种基于词典的中文分词算法。这种方法从文本的第一个字符开始,试图找到最长的词语,然后将其作为一个词来进行分词。具体流程如下:
- 准备词典:首先需要一个预先准备好的词典,其中包含可能出现的所有词。
- 设置窗口大小:窗口大小通常设置为词典中最长词的长度。
- 扫描文本:
- 将窗口放到文本的最左端。
- 从窗口中取出字符,并与词典中的词进行匹配,尝试找出最长的匹配词。
- 如果找到匹配,则将这个词作为一个分词结果,并将窗口向右移动相应的字符数。
- 如果没有找到匹配,则将窗口中的第一个字符作为一个分词结果,并只将窗口向右移动一个字符。
- 重复步骤3,直到整个文本都被扫描完成。
这种方法的优点是实现简单,运行速度快。但缺点也很明显:不能很好地处理词典外的新词,以及由于缺乏上下文信息,可能会导致一些歧义词的错误切分。
2.2.1 实现方式一
- 找出词表中最大词长度
- 从字符串开头开始选取最大词长度的窗口,检查窗口内的词是否在词表中
- 如果在词表中,在词边界处进行切分,之后移动到词边界处,重复步骤2
- 如果不在词表中,窗口右边界回退一个字符,之后检查窗口词是否在词表中
切分过程:
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
北 京 大 学 生 前 来 报 到
#分词方法:最大正向切分的第一种实现方式
import re
import time
#加载词典
def load_word_dict(path):
max_word_length = 0
word_dict = {} #用set也是可以的。用list会很慢
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
word_dict[word] = 0
max_word_length = max(max_word_length, len(word))
return word_dict, max_word_length
#先确定最大词长度
#从长向短查找是否有匹配的词
#找到后移动窗口
def cut_method1(string, word_dict, max_len):
words = []
while string != '':
lens = min(max_len, len(string))
word = string[:lens]
while word not in word_dict:
if len(word) == 1:
break
word = word[:len(word) - 1]
words.append(word)
string = string[len(word):]
return words
#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):
word_dict, max_word_length = load_word_dict("dict.txt")
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict, max_word_length)
writer.write(" / ".join(words) + "\n")
writer.close()
print("耗时:", time.time() - start_time)
return
string = "测试字符串"
word_dict, max_len = load_word_dict("dict.txt")
# print(cut_method1(string, word_dict, max_len))
main(cut_method1, "corpus.txt", "cut_method1_output.txt")
2.2.2 实现方式二 利用前缀字典
- 从前向后进行查找
- 如果窗口内的词是一个词前缀则继续扩大窗口
- 如果窗口内的词不是一个词前缀,则记录已发现的词,并将窗口移动到词边界

切分过程:

#分词方法最大正向切分的第二种实现方式
import re
import time
import json
#加载词前缀词典
#用0和1来区分是前缀还是真词
#需要注意有的词的前缀也是真词,在记录时不要互相覆盖
def load_prefix_word_dict(path):
prefix_dict = {}
with open(path, encoding="utf8") as f:
for line in f:
word = line.split()[0]
for i in range(1, len(word)):
if word[:i] not in prefix_dict: #不能用前缀覆盖词
prefix_dict[word[:i]] = 0 #前缀
prefix_dict[word] = 1 #词
return prefix_dict
#输入字符串和字典,返回词的列表
def cut_method2(string, prefix_dict):
if string == "":
return []
words = [] # 准备用于放入切好的词
start_index, end_index = 0, 1 #记录窗口的起始位置
window = string[start_index:end_index] #从第一个字开始
find_word = window # 将第一个字先当做默认词
while start_index < len(string):
#窗口没有在词典里出现
if window not in prefix_dict or end_index > len(string):
words.append(find_word) #记录找到的词
start_index += len(find_word) #更新起点的位置
end_index = start_index + 1
window = string[start_index:end_index] #从新的位置开始一个字一个字向后找
find_word = window
#窗口是一个词
elif prefix_dict[window] == 1:
find_word = window #查找到了一个词,还要在看有没有比他更长的词
end_index += 1
window = string[start_index:end_index]
#窗口是一个前缀
elif prefix_dict[window] == 0:
end_index += 1
window = string[start_index:end_index]
#最后找到的window如果不在词典里,把单独的字加入切词结果
if prefix_dict.get(window) != 1:
words += list(window)
else:
words.append(window)
return words
#cut_method是切割函数
#output_path是输出路径
def main(cut_method, input_path, output_path):
word_dict = load_prefix_word_dict("dict.txt")
writer = open(output_path, "w", encoding="utf8")
start_time = time.time()
with open(input_path, encoding="utf8") as f:
for line in f:
words = cut_method(line.strip(), word_dict)
writer.write(" / ".join(words) + "\n")
writer.close()
print("耗时:", time.time() - start_time)
return
string = "王羲之草书《平安帖》共有九行"
# string = "你到很多有钱人家里去看"
# string = "金鹏期货北京海鹰路营业部总经理陈旭指出"
# string = "伴随着优雅的西洋乐"
# string = "非常的幸运"
prefix_dict = load_prefix_word_dict("dict.txt")
# print(cut_method2(string, prefix_dict))
# print(json.dumps(prefix_dict, ensure_ascii=False, indent=2))
main(cut_method2, "corpus.txt", "cut_method2_output.txt")
2.3 中文分词-反向最大匹配
反向最大匹配(Reverse Maximum Matching,简称 RMM)是正向最大匹配(FMM)的一个变种,主要区别在于搜索方向。在RMM中,分词的过程是从文本的最后一个字符开始,向前进行扫描。具体流程如下:
- 准备词典:需要一个预先准备好的词典,里面包括可能会用到的所有词。
- 设置窗口大小:窗口大小通常设置为词典中最长词的长度。
- 扫描文本:
- 将窗口放到文本的最右端。
- 从窗口中取出字符,并与词典中的词进行匹配,尝试找出最长的匹配词。
- 如果找到匹配,则将这个词作为一个分词结果,并将窗口向左移动相应的字符数。
- 如果没有找到匹配,则将窗口中的最后一个字符作为一个分词结果,并将窗口向左移动一个字符。
- 重复步骤3,直到整个文本都被扫描完成。
与正向最大匹配类似,反向最大匹配的优点包括简单易于实现和运行速度快。但同样也存在缺点,例如不能很好地处理词典外的新词,以及可能因缺乏上下文信息而导致某些歧义词的错误切分。有时候,人们会将正向最大匹配和反向最大匹配的结果进行对比,以进一步提高分词的准确性。

2.4 中文分词-双向最大匹配
双向最大匹配(Bidirectional Maximum Matching,简称 BMM)是正向最大匹配(FMM)和反向最大匹配(RMM)的结合。该方法分别用两种策略进行分词,并比较两者的结果。具体步骤如下:
- 准备词典:首先需要一个预先准备好的词典,包括可能用到的所有词。
- 使用正向最大匹配进行分词:从文本的第一个字符开始,应用正向最大匹配算法进行分词。
- 使用反向最大匹配进行分词:从文本的最后一个字符开始,应用反向最大匹配算法进行分词。
- 比较两种方法的结果:
- 如果两种方法得到的分词结果相同,那么这个结果很可能是正确的。
- 如果两种方法得到的分词结果不同,则通常会选择分出的词数更少的那个结果,因为在实际应用中,通常认为分词结果越少,准确性越高。
双向最大匹配的优点是结合了两种分词方法,理论上能获得更准确的分词结果。然而,这种方法的运算成本也相对较高,因为需要运行两种分词算法并进行结果比较。
另外,这种方法同样无法很好地处理词典之外的新词或由多个词构成的固定搭配,也不能解决由上下文引起的分词歧义问题。但总体来说,双向最大匹配算法在准确性方面通常优于单一方向的最大匹配算法。

2.5 中文分词-jieba分词
jieba 是一个流行的中文分词库,主要用于Python语言。它使用了基于前缀词典的最大概率路径分词算法和基于有向无环图(DAG)的动态规划方法。jieba 支持多种分词模式,包括精确模式、全模式和搜索引擎模式。此外,它还支持词性标注和关键词提取。
2.5.1 基本用法
- 安装
通过 pip 进行安装:
pip install jieba
- 导入库和基本分词
import jieba
sentence = "我来到北京清华大学"
seg_list = jieba.cut(sentence)
print(list(seg_list))
2.5.2 分词模式
- 精确模式:尽可能地将句子分成精确的短词。
seg_list = jieba.cut("我来到北京清华大学", cut_all=False)
print(list(seg_list))
- 全模式:将句子中所有可能的词都扫描出来。
seg_list = jieba.cut("我来到北京清华大学", cut_all=True)
print(list(seg_list))
- 搜索引擎模式:在精确模式基础上,对长词再次进行切分。
seg_list = jieba.cut_for_search("我来到北京清华大学")
print(list(seg_list))
2.5.3 其他功能
- 添加自定义词典:
jieba.load_userdict("userdict.txt")
- 词性标注:
import jieba.posseg as pseg
words = pseg.cut("我来到北京清华大学")
for word, flag in words:
print(f"{word} {flag}")
- 关键词提取:
from jieba import analyse
tags = analyse.extract_tags(sentence, topK=5)
print(tags)
示例

2.6 三种方式的缺点
正向最大切分,负向最大切分,双向最大切分共同的缺点:
- 对词表极为依赖,如果没有词表,则无法进行;如果词表中缺少需要的词,结果也不会正确
- 切分过程中不会关注整个句子表达的意思,只会将句子看成一个个片段
- 如果文本中出现一定的错别字,会造成一连串影响
- 对于人名等的无法枚举实体词无法有效的处理
2.7 中文分词-基于机器学习
重新思考,如果想要对一句话进行分词,我们需要什么知道什么?
- 上 海 自 来 水 来 自 海 上
- 对于每一个字,我们想知道它是不是一个词的边界

问题转化为:对于句子中的每一个字,进行二分类判断,正类表示这句话中,它是词边界,负类表示它不是词边界
标注数据、训练模型,使模型可以完成上述判断,那么这个模型,可以称为一个分词模型
代码实现
#coding:utf8
import torch
import torch.nn as nn
import jieba
import numpy as np
import random
import json
from torch.utils.data import DataLoader
"""
基于pytorch的网络编写一个分词模型
我们使用jieba分词的结果作为训练数据
看看是否可以得到一个效果接近的神经网络模型
"""
class TorchModel(nn.Module):
def __init__(self, input_dim, hidden_size, num_rnn_layers, vocab):
super(TorchModel, self).__init__()
self.embedding = nn.Embedding(len(vocab) + 1, input_dim) #shape=(vocab_size, dim)
self.rnn_layer = nn.RNN(input_size=input_dim,
hidden_size=hidden_size,
batch_first=True,
num_layers=num_rnn_layers,
)
self.classify = nn.Linear(hidden_size, 2)
self.loss_func = nn.CrossEntropyLoss(ignore_index=-100)
#当输入真实标签,返回loss值;无真实标签,返回预测值
def forward(self, x, y=None):
x = self.embedding(x) #input shape: (batch_size, sen_len), output shape:(batch_size, sen_len, input_dim)
x, _ = self.rnn_layer(x) #output shape:(batch_size, sen_len, hidden_size)
y_pred = self.classify(x) #output shape:(batch_size, sen_len, 2)
if y is not None:
# view(-1,2): (batch_size, sen_len, 2) -> (batch_size * sen_len, 2)
return self.loss_func(y_pred.view(-1, 2), y.view(-1))
else:
return y_pred
class Dataset:
def __init__(self, corpus_path, vocab, max_length):
self.vocab = vocab
self.corpus_path = corpus_path
self.max_length = max_length
self.load()
def load(self):
self.data = []
with open(self.corpus_path, encoding="utf8") as f:
for line in f:
sequence = sentence_to_sequence(line, self.vocab)
label = sequence_to_label(line)
sequence, label = self.padding(sequence, label)
sequence = torch.LongTensor(sequence)
label = torch.LongTensor(label)
self.data.append([sequence, label])
#使用部分数据做展示,使用全部数据训练时间会相应变长
if len(self.data) > 10000:
break
#将文本截断或补齐到固定长度
def padding(self, sequence, label):
sequence = sequence[:self.max_length]
sequence += [0] * (self.max_length - len(sequence))
label = label[:self.max_length]
label += [-100] * (self.max_length - len(label))
return sequence, label
def __len__(self):
return len(self.data)
def __getitem__(self, item):
return self.data[item]
#文本转化为数字序列,为embedding做准备
def sentence_to_sequence(sentence, vocab):
sequence = [vocab.get(char, vocab['unk']) for char in sentence]
return sequence
#基于结巴生成分级结果的标注
def sequence_to_label(sentence):
words = jieba.lcut(sentence)
label = [0] * len(sentence)
pointer = 0
for word in words:
pointer += len(word)
label[pointer - 1] = 1
return label
#加载字表
def build_vocab(vocab_path):
vocab = {}
with open(vocab_path, "r", encoding="utf8") as f:
for index, line in enumerate(f):
char = line.strip()
vocab[char] = index + 1 #每个字对应一个序号
vocab['unk'] = len(vocab) + 1
return vocab
#建立数据集
def build_dataset(corpus_path, vocab, max_length, batch_size):
dataset = Dataset(corpus_path, vocab, max_length) #diy __len__ __getitem__
data_loader = DataLoader(dataset, shuffle=True, batch_size=batch_size) #torch
return data_loader
def main():
epoch_num = 10 #训练轮数
batch_size = 20 #每次训练样本个数
char_dim = 50 #每个字的维度
hidden_size = 100 #隐含层维度
num_rnn_layers = 3 #rnn层数
max_length = 20 #样本最大长度
learning_rate = 1e-3 #学习率
vocab_path = "chars.txt" #字表文件路径
corpus_path = "../corpus.txt" #语料文件路径
vocab = build_vocab(vocab_path) #建立字表
data_loader = build_dataset(corpus_path, vocab, max_length, batch_size) #建立数据集
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
optim = torch.optim.Adam(model.parameters(), lr=learning_rate) #建立优化器
#训练开始
for epoch in range(epoch_num):
model.train()
watch_loss = []
for x, y in data_loader:
optim.zero_grad() #梯度归零
loss = model(x, y) #计算loss
loss.backward() #计算梯度
optim.step() #更新权重
watch_loss.append(loss.item())
print("=========\n第%d轮平均loss:%f" % (epoch + 1, np.mean(watch_loss)))
#保存模型
torch.save(model.state_dict(), "model.pth")
return
#最终预测
def predict(model_path, vocab_path, input_strings):
#配置保持和训练时一致
char_dim = 50 # 每个字的维度
hidden_size = 100 # 隐含层维度
num_rnn_layers = 3 # rnn层数
vocab = build_vocab(vocab_path) #建立字表
model = TorchModel(char_dim, hidden_size, num_rnn_layers, vocab) #建立模型
model.load_state_dict(torch.load(model_path)) #加载训练好的模型权重
model.eval()
for input_string in input_strings:
#逐条预测
x = sentence_to_sequence(input_string, vocab)
with torch.no_grad():
result = model.forward(torch.LongTensor([x]))[0]
result = torch.argmax(result, dim=-1) #预测出的01序列
#在预测为1的地方切分,将切分后文本打印出来
for index, p in enumerate(result):
if p == 1:
print(input_string[index], end=" ")
else:
print(input_string[index], end="")
print()
if __name__ == "__main__":
# main()
input_strings = ["同时国内有望出台新汽车刺激方案",
"沪胶后市有望延续强势",
"经过两个交易日的强势调整后",
"昨日上海天然橡胶期货价格再度大幅上扬"]
predict("model.pth", "chars.txt", input_strings)
3. 关于分词
目前,对于中文分词的研究在逐渐减少,有以下几方面原因:
- 目前的分词在由大部分情况下,效果已经比较理想,优化空间不大
- 分词即使发生错误,下游任务不是一定发生错误,所以不值得花大量精力优化分词
- 随着神经网络和预训练模型的兴起,中文任务逐渐不再需要分词,甚至不做分词,效果更好
- 解决不了的问题,是真的不好解决了
4. 总结经验
- 相同的任务有不同的算法可以完成
- 不同实现方式可能有相同的结果,但效率不同
- 不同的算法可能有不同的结果,但各有优劣
- 空间换时间,是一种常用的提升性能思路
- 多种算法组合使用,可能会获得更好的结果
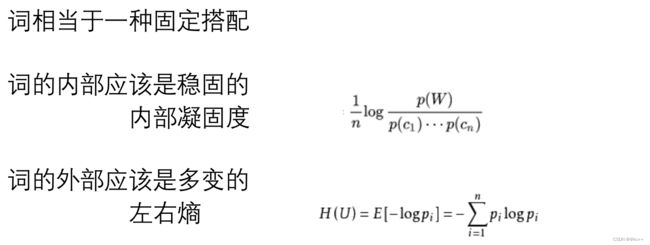
5. 新词发现
新词发现是自然语言处理(NLP)中的一个重要任务,特别是对于动态变化的语料或专业领域文本。传统的分词工具通常依赖于预先构建的词典,这样在处理未登录词(不在词典中的词)时就会有局限性。新词发现算法旨在自动从大量文本中识别出这种新词。
- 假设没有词表,如何从文本中发现新词?
- 随着时间推移,新词会不断出现,固有词表会过时
- 补充词表有利于下游任务
代码示例
import math
from collections import defaultdict
class NewWordDetect:
def __init__(self, corpus_path):
self.max_word_length = 5
self.word_count = defaultdict(int)
self.left_neighbor = defaultdict(dict)
self.right_neighbor = defaultdict(dict)
self.load_corpus(corpus_path)
self.calc_pmi()
self.calc_entropy()
self.calc_word_values()
#加载语料数据,并进行统计
def load_corpus(self, path):
with open(path, encoding="utf8") as f:
for line in f:
sentence = line.strip()
for word_length in range(1, self.max_word_length):
self.ngram_count(sentence, word_length)
return
#按照窗口长度取词,并记录左邻右邻
def ngram_count(self, sentence, word_length):
for i in range(len(sentence) - word_length + 1):
word = sentence[i:i + word_length]
self.word_count[word] += 1
if i - 1 >= 0:
char = sentence[i - 1]
self.left_neighbor[word][char] = self.left_neighbor[word].get(char, 0) + 1
if i + word_length < len(sentence):
char = sentence[i +word_length]
self.right_neighbor[word][char] = self.right_neighbor[word].get(char, 0) + 1
return
#计算熵
def calc_entropy_by_word_count_dict(self, word_count_dict):
total = sum(word_count_dict.values())
entropy = sum([-(c / total) * math.log((c / total), 10) for c in word_count_dict.values()])
return entropy
#计算左右熵
def calc_entropy(self):
self.word_left_entropy = {}
self.word_right_entropy = {}
for word, count_dict in self.left_neighbor.items():
self.word_left_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)
for word, count_dict in self.right_neighbor.items():
self.word_right_entropy[word] = self.calc_entropy_by_word_count_dict(count_dict)
#统计每种词长下的词总数
def calc_total_count_by_length(self):
self.word_count_by_length = defaultdict(int)
for word, count in self.word_count.items():
self.word_count_by_length[len(word)] += count
return
#计算互信息(pointwise mutual information)
def calc_pmi(self):
self.calc_total_count_by_length()
self.pmi = {}
for word, count in self.word_count.items():
p_word = count / self.word_count_by_length[len(word)]
p_chars = 1
for char in word:
p_chars *= self.word_count[char] / self.word_count_by_length[1]
self.pmi[word] = math.log(p_word / p_chars, 10) / len(word)
return
def calc_word_values(self):
self.word_values = {}
for word in self.pmi:
if len(word) < 2 or "," in word:
continue
pmi = self.pmi.get(word, 1e-3)
le = self.word_left_entropy.get(word, 1e-3)
re = self.word_right_entropy.get(word, 1e-3)
self.word_values[word] = pmi ** 2 * min(le, re)
if __name__ == "__main__":
nwd = NewWordDetect("sample_corpus.txt")
# print(nwd.word_count)
# print(nwd.left_neighbor)
# print(nwd.right_neighbor)
# print(nwd.pmi)
# print(nwd.word_left_entropy)
# print(nwd.word_right_entropy)
value_sort = sorted([(word, count) for word, count in nwd.word_values.items()], key=lambda x:x[1], reverse=True)
print([x for x, c in value_sort if len(x) == 2][:10])
print([x for x, c in value_sort if len(x) == 3][:10])
print([x for x, c in value_sort if len(x) == 4][:10])
从词到理解
- 有了分词能力后,需要利用词来完成对文本的理解
- 首先可以想到的,就是从文章中挑选重要词
何为重要词
- 假如一个词在某类文本(假设为A类)中出现次数很多,而在其他类别文本(非A类)出现很少,那么这个词是A类文本的重要词(高权重词)。

- 反之,如果一个词在出现在很多领域,则其对于任意类别的重要性都很差。

如何从数学角度刻画

6. TF-IDF
6.1 TF-IDF计算
- TF·IDF = TF * IDF
- 假设有四篇文档,文档中的词用字母代替
- A:a b c d a b c d
- B: b c b c b c
- C: b d b d
- D: d d d d d d d
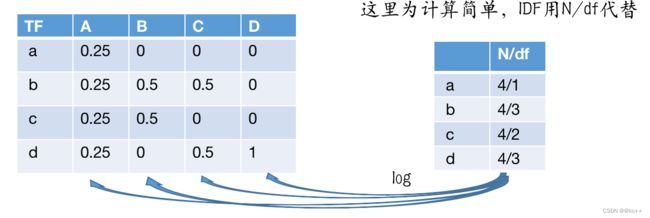
- 每个词对于每个类别都会得到一个TF·IDF值
- TF·IDF高 -> 该词对于该领域重要程度高
- 低则相反

6.2 TFIDF其他版本


6.3 算法特点
- tf-idf的计算非常依赖分词结果,如果分词出错,统计值的意义会大打折扣
- 每个词,对于每篇文档,有不同的tf-idf值,所以不能脱离数据讨论tfidf
- 假如只有一篇文本,不能计算tf-idf
- 类别数据均衡很重要
- 容易受各种特殊符号影响,最好做一些预处理
6.4 TFIDF应用-搜索引擎
- 对于已有的所有网页(文本),计算每个网页中,词的TFIDF值
- 对于一个输入query进行分词
- 对于文档D,计算query中的词在文档D中的TFIDF值总和,作为query和文档的相关性得分
代码示例
import jieba
import math
import os
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk
"""
基于tfidf实现简单搜索引擎
"""
jieba.initialize()
#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
def load_data(file_path):
corpus = []
with open(file_path, encoding="utf8") as f:
documents = json.loads(f.read())
for document in documents:
corpus.append(document["title"] + "\n" + document["content"])
tf_idf_dict = calculate_tfidf(corpus)
return tf_idf_dict, corpus
def search_engine(query, tf_idf_dict, corpus, top=3):
query_words = jieba.lcut(query)
res = []
for doc_id, tf_idf in tf_idf_dict.items():
score = 0
for word in query_words:
score += tf_idf.get(word, 0)
res.append([doc_id, score])
res = sorted(res, reverse=True, key=lambda x:x[1])
for i in range(top):
doc_id = res[i][0]
print(corpus[doc_id])
print("--------------")
return res
if __name__ == "__main__":
path = "news.json"
tf_idf_dict, corpus = load_data(path)
while True:
query = input("请输入您要搜索的内容:")
search_engine(query, tf_idf_dict, corpus)
6.5 TFIDF应用-文本摘要
- 通过计算TFIDF值得到每个文本的关键词。
- 将包含关键词多的句子,认为是关键句。
- 挑选若干关键句,作为文本的摘要。
代码示例
import jieba
import math
import os
import random
import re
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk
"""
基于tfidf实现简单文本摘要
"""
jieba.initialize()
#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
def load_data(file_path):
corpus = []
with open(file_path, encoding="utf8") as f:
documents = json.loads(f.read())
for document in documents:
assert "\n" not in document["title"]
assert "\n" not in document["content"]
corpus.append(document["title"] + "\n" + document["content"])
tf_idf_dict = calculate_tfidf(corpus)
return tf_idf_dict, corpus
#计算每一篇文章的摘要
#输入该文章的tf_idf词典,和文章内容
#top为人为定义的选取的句子数量
#过滤掉一些正文太短的文章,因为正文太短在做摘要意义不大
def generate_document_abstract(document_tf_idf, document, top=3):
sentences = re.split("?|!|。", document)
#过滤掉正文在五句以内的文章
if len(sentences) <= 5:
return None
result = []
for index, sentence in enumerate(sentences):
sentence_score = 0
words = jieba.lcut(sentence)
for word in words:
sentence_score += document_tf_idf.get(word, 0)
sentence_score /= (len(words) + 1)
result.append([sentence_score, index])
result = sorted(result, key=lambda x:x[0], reverse=True)
#权重最高的可能依次是第10,第6,第3句,将他们调整为出现顺序比较合理,即3,6,10
important_sentence_indexs = sorted([x[1] for x in result[:top]])
return "。".join([sentences[index] for index in important_sentence_indexs])
#生成所有文章的摘要
def generate_abstract(tf_idf_dict, corpus):
res = []
for index, document_tf_idf in tf_idf_dict.items():
title, content = corpus[index].split("\n")
abstract = generate_document_abstract(document_tf_idf, content)
if abstract is None:
continue
corpus[index] += "\n" + abstract
res.append({"标题":title, "正文":content, "摘要":abstract})
return res
if __name__ == "__main__":
path = "news.json"
tf_idf_dict, corpus = load_data(path)
res = generate_abstract(tf_idf_dict, corpus)
writer = open("abstract.json", "w", encoding="utf8")
writer.write(json.dumps(res, ensure_ascii=False, indent=2))
writer.close()
6.6 TFIDF应用-文本相似度计算
- 对所有文本计算tfidf后,从每个文本选取tfidf较高的前n个词,得到一个词的集合S。
- 对于每篇文本D,计算S中的每个词的词频,将其作为文本的向量。
- 通过计算向量夹角余弦值,得到向量相似度,作为文本的相似度
- 向量夹角余弦值计算:
代码示例
#coding:utf8
import jieba
import math
import os
import json
from collections import defaultdict
from calculate_tfidf import calculate_tfidf, tf_idf_topk
"""
基于tfidf实现文本相似度计算
"""
jieba.initialize()
#加载文档数据(可以想象成网页数据),计算每个网页的tfidf字典
#之后统计每篇文档重要在前10的词,统计出重要词词表
#重要词词表用于后续文本向量化
def load_data(file_path):
corpus = []
with open(file_path, encoding="utf8") as f:
documents = json.loads(f.read())
for document in documents:
corpus.append(document["title"] + "\n" + document["content"])
tf_idf_dict = calculate_tfidf(corpus)
topk_words = tf_idf_topk(tf_idf_dict, top=5, print_word=False)
vocab = set()
for words in topk_words.values():
for word, score in words:
vocab.add(word)
print("词表大小:", len(vocab))
return tf_idf_dict, list(vocab), corpus
#passage是文本字符串
#vocab是词列表
#向量化的方式:计算每个重要词在文档中的出现频率
def doc_to_vec(passage, vocab):
vector = [0] * len(vocab)
passage_words = jieba.lcut(passage)
for index, word in enumerate(vocab):
vector[index] = passage_words.count(word) / len(passage_words)
return vector
#先计算所有文档的向量
def calculate_corpus_vectors(corpus, vocab):
corpus_vectors = [doc_to_vec(c, vocab) for c in corpus]
return corpus_vectors
#计算向量余弦相似度
def cosine_similarity(vector1, vector2):
x_dot_y = sum([x*y for x, y in zip(vector1, vector2)])
sqrt_x = math.sqrt(sum([x ** 2 for x in vector1]))
sqrt_y = math.sqrt(sum([x ** 2 for x in vector2]))
if sqrt_y == 0 or sqrt_y == 0:
return 0
return x_dot_y / (sqrt_x * sqrt_y + 1e-7)
#输入一篇文本,寻找最相似文本
def search_most_similar_document(passage, corpus_vectors, vocab):
input_vec = doc_to_vec(passage, vocab)
result = []
for index, vector in enumerate(corpus_vectors):
score = cosine_similarity(input_vec, vector)
result.append([index, score])
result = sorted(result, reverse=True, key=lambda x:x[1])
return result[:4]
if __name__ == "__main__":
path = "news.json"
tf_idf_dict, vocab, corpus = load_data(path)
corpus_vectors = calculate_corpus_vectors(corpus, vocab)
passage = "魔兽争霸"
for corpus_index, score in search_most_similar_document(passage, corpus_vectors, vocab):
print("相似文章:\n", corpus[corpus_index].strip())
print("得分:", score)
print("--------------")
6.7 TFIDF的优势
- 可解释性好,可以清晰地看到关键词,即使预测结果出错,也很容易找到原因
- 计算速度快,分词本身占耗时最多,其余为简单统计计算
- 对标注数据依赖小,可以使用无标注语料完成一部分工作
- 可以与很多算法组合使用,可以看做是词权重
6.8 TFIDF劣势
- 受分词效果影响大
- 词与词之间没有语义相似度
- 没有语序信息(词袋模型)
- 能力范围有限,无法完成复杂任务,如机器翻译和实体挖掘等
- 样本不均衡会对结果有很大影响
- 类内样本间分布不被考虑
7. TFIDF的计算和使用
代码示例
import jieba
import math
import os
import json
from collections import defaultdict
"""
tfidf的计算和使用
"""
#统计tf和idf值
def build_tf_idf_dict(corpus):
tf_dict = defaultdict(dict) #key:文档序号,value:dict,文档中每个词出现的频率
idf_dict = defaultdict(set) #key:词, value:set,文档序号,最终用于计算每个词在多少篇文档中出现过
for text_index, text_words in enumerate(corpus):
for word in text_words:
if word not in tf_dict[text_index]:
tf_dict[text_index][word] = 0
tf_dict[text_index][word] += 1
idf_dict[word].add(text_index)
idf_dict = dict([(key, len(value)) for key, value in idf_dict.items()])
return tf_dict, idf_dict
#根据tf值和idf值计算tfidf
def calculate_tf_idf(tf_dict, idf_dict):
tf_idf_dict = defaultdict(dict)
for text_index, word_tf_count_dict in tf_dict.items():
for word, tf_count in word_tf_count_dict.items():
tf = tf_count / sum(word_tf_count_dict.values())
#tf-idf = tf * log(D/(idf + 1))
tf_idf_dict[text_index][word] = tf * math.log(len(tf_dict)/(idf_dict[word]+1))
return tf_idf_dict
#输入语料 list of string
#["xxxxxxxxx", "xxxxxxxxxxxxxxxx", "xxxxxxxx"]
def calculate_tfidf(corpus):
#先进行分词
corpus = [jieba.lcut(text) for text in corpus]
tf_dict, idf_dict = build_tf_idf_dict(corpus)
tf_idf_dict = calculate_tf_idf(tf_dict, idf_dict)
return tf_idf_dict
#根据tfidf字典,显示每个领域topK的关键词
def tf_idf_topk(tfidf_dict, paths=[], top=10, print_word=True):
topk_dict = {}
for text_index, text_tfidf_dict in tfidf_dict.items():
word_list = sorted(text_tfidf_dict.items(), key=lambda x:x[1], reverse=True)
topk_dict[text_index] = word_list[:top]
if print_word:
print(text_index, paths[text_index])
for i in range(top):
print(word_list[i])
print("----------")
return topk_dict
def main():
dir_path = r"category_corpus/"
corpus = []
paths = []
for path in os.listdir(dir_path):
path = os.path.join(dir_path, path)
if path.endswith("txt"):
corpus.append(open(path, encoding="utf8").read())
paths.append(os.path.basename(path))
tf_idf_dict = calculate_tfidf(corpus)
tf_idf_topk(tf_idf_dict, paths)
if __name__ == "__main__":
main()