【Quartz】分布式定时任务
初识Quartz
Quartz 是一个功能丰富的开源作业调度库,几乎可以集成到任何 Java 应用程序中。
GitHub友情连接
核心
-
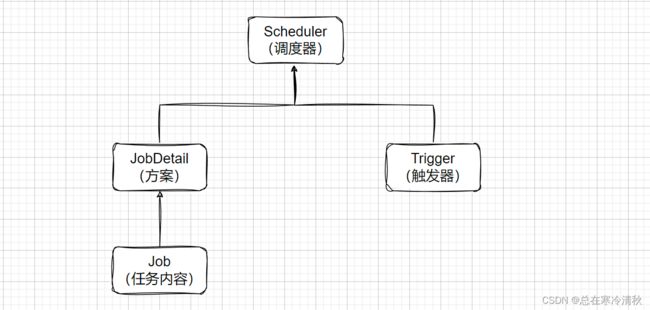
任务 Job
定义定时任务的具体执行内容。 -
JobDetail
表示一个具体的可执行的调度程序,Job 是这个可执行程调度程序所要执行的内容,另外 JobDetail 还包含了这个任务调度的方案和策略。 -
触发器 Trigger
Trigger 作为执行任务的调度器。定义触发逻辑,如间隔多久触发、按照 Cron 表达式触发、一共可以触发多少次等等。 -
调度器 Scheduler
Scheduler 为任务的调度器,它会将任务 JobDetail 及触发器 Trigger 整合起来,负责基于 Trigger 设定的时间来执行 Job。并且一个调度器中可以注册多个 JobDetail 和 Trigger。
Quartz 应用
应用入门
- 导入相关依赖
<dependency> <groupId>org.quartz-schedulergroupId> <artifactId>quartzartifactId> <version>2.3.2version> dependency> - 自定义任务
public class TestJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("Quartz 任务执行中"); } } - 创建任务调度
public class TestJobDetail { public static void main(String[] args) throws SchedulerException { // 创建任务调度器 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); // 创建JobDetail,绑定TestJob JobDetail jobDetail = JobBuilder.newJob(TestJob.class) .withIdentity("jobDetail", "jobDetailGroup") .build(); // 创建触发器 Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger", "triggerGroup") // 频率规则 五秒一次,共三次 .withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(3, 5)) // 启动后立即执行 .startNow() .build(); // 调度器绑定触发器和jobDetail scheduler.scheduleJob(jobDetail, trigger); // 任务开始 scheduler.start(); } } - 结果呈现
Quartz 任务执行中 Quartz 任务执行中 Quartz 任务执行中
我们来整理下这段简单中展现的Quartz的核心,和重要参数。
Job
工作任务调度的接口,任务类需要实现该接口,重写execute 方法。
每次调度器执行 Job 时,在调用 execute 方法之前都会创建一个新的 Job 实例,当调用完成后,关联的 Job 对象示例会被释放,释放的实例会被垃圾回收机制回收。
JobDetail
为 Job 实例提供了许多设置属性,以及 JobDetailMap 成员变量属性,它用来存储特定 Job 实例的状态信息,调度器需要借助 JobDetail 对象来添加 Job 实例。
PS:JobDetail 定义的是任务数据,而真正的执行逻辑是是在 Job 中。这是因为任务有可能并发执行,直接使用 Job会存在对同一个 Job 实例并发访问的问题。而 采用JobDetail & Job 方式,Scheduler 每次执行,都会根据 JobDetail 创建一个新的 Job 实例,这样就可以规避并发访问问题。
JobExecutionContext
当 Scheduler 调用一个 Job ,就会将 JobExecutionContext 传递给 Job 的 execute() 方法。这样在Job 中就能通过 JobExecutionContext 对象来访问到 Quartz 运行时候的环境以及 Job 本身的明细数据。
JobDataMap
用来存储任何可序列化的数据对象,当 Job 实例对象被执行时这些参数对象会传递给它。
-
任务调度类:
JobDetail jobDetail = JobBuilder.newJob(TestJob.class) // JobDataMap 存储数据 .usingJobData("jobDetail", "jobDetail数据存放") // 可以使用这种方式为TestJob实例中的testMsg属性赋值 .usingJobData("testMsg", "job中testMsg属性存储值") .withIdentity("jobDetail", "jobDetailGroup") .build(); Trigger trigger = TriggerBuilder.newTrigger() // trigger存储 key 和jobDetail中一致,会覆盖前者 .usingJobData("trigger", "trigger储存数据") .withIdentity("trigger", "triggerGroup") .withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(1, 5)) .startNow() .build(); -
Job任务
public class TestJob implements Job { private String testMsg; public void setTestMsg(String testMsg) { this.testMsg = testMsg; } @Override public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("jobDetail ------> " + context.getJobDetail().getJobDataMap().get("jobDetail")); System.out.println("testMsg属性值 ------ > " + testMsg); System.out.println("trigger ------> " + context.getTrigger().getJobDataMap().get("trigger")); } } -
结果输出
jobDetail ------> jobDetail数据存放 testMsg属性值 ------ > job中testMsg属性存储值 trigger ------> trigger储存数据
我们可以看出,除了通过 getJobDataMap( ) 方法来获取 JobDataMap 中的值之外,还可以Job实现类中添加对应key的setter方法,那么Quartz框架默认的JobFactory实现类在初始化 Job 实例对象时回自动地调用这些 setter 方法。
任务的状态
前面有提到过:在调用 execute 方法之前都会创建一个新的 Job 实例,那么如果我们想持有一些信息,要怎么做呢?
如果我们想利用JobDataMap知道这个Job的调用次数,大概会如此修改上述的例子。
-
修改任务调度
public class TestJobDetail { public static void main(String[] args) throws SchedulerException { Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); JobDetail jobDetail = JobBuilder.newJob(TestJob.class) .usingJobData("trigger", "jobDetail数据存放") // 计数count初始为 0 .usingJobData("count", 0) .withIdentity("jobDetail", "jobDetailGroup") .build(); Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger", "triggerGroup") .withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(3, 1)) .startNow() .build(); // 略 ... } } -
修改Job任务
public class TestJob implements Job { private Integer count; public void setCount(Integer count) { this.count = count; } @Override public void execute(JobExecutionContext context) throws JobExecutionException { // 计数自增1并放回JobDataMap System.out.println(++count); context.getJobDetail().getJobDataMap().put("count", count); } } -
结果展示
1 1 1
结果并没有按照我们预计的发展,逻辑写的也没什么问题。
其实上面已经提到过:在调用 execute 方法之前都会创建一个新的 Job 实例
这就牵引出了 Job 状态的概念
-
无状态的 Job
每次调用时都会创建一个新的 JobDataMap -
有状态的 Job
多次 Job 调用可以持有一些状态信息,这些状态信息存储在 JobDataMap 中
如果让 Job 变成有状态?这个时候我们可以借助一个注解:@PersistJobDataAfterExecution ,再Job实现类加上这个注解后,我们再来试下:

可以看到已经实现我们想要的效果。
Trigger
至此我们已经知道了 Quartz 的组成,我们定义了任务之后,需要用触发器 Trigger 去指定 Job 的执行时间,执行间隔,运行次数等,我们中间还需要 Scheduler 去调度。
那么Trigger只能按照上述的例子一样只能简单定义任务的时间间隔吗,不,我们可以搜一下实现代码。

大致有四个实现类,但是我们平时用的最多的还是 CronTriggerImpl 和 SimpleTriggerImpl。
SimpleTriggerImpl
SimpleTrigger 对于设置和使用是最为简单的一种 QuartzTrigger,它是为那种需要在特定的日期/时间启动,且以一个可能的间隔时间重复执行 n 次的 Job任务 所设计的。
也可以设定任务的开始时间和结束时间
Trigger trigger = TriggerBuilder.newTrigger()
.usingJobData("trigger", "trigger储存数据")
.withIdentity("trigger", "triggerGroup")
.withSchedule(SimpleScheduleBuilder.repeatSecondlyForTotalCount(3, 1))
// 时间为日期类型,这里省略了
.startAt('开始时间')
.endAt('结束时间')
.build();
SimpleTrigger具备的属性有:开始时间、结束时间、重复次数和重复的时间间隔
- 重复次数 的值可以为 0、正整数
- 重复的时间间隔属性值必须大于 0 或长整型的正整数
- 结束时间和重复次数同时存在时,以结束时间优先,即使任务没有达到足够次数
CronTriggerImpl
跟 SimpleTrigger 执行间隔时间触发的相比,CronTrigger 更加灵活,它是基于日历的作业调度器。
Cron表达式的相关知识这里就略过了,也不用记什么,需要的时候去网上找就可以了。
CronTriggerImpl 触发器
Trigger trigger = TriggerBuilder.newTrigger()
.withIdentity("trigger", "triggerGroup")
// 每月的第三个星期五上午10:15触发
.withSchedule(CronScheduleBuilder.cronSchedule("0 15 10 ? * 6#3"))
// 时间为日期类型,这里省略了
.startAt('开始时间')
.endAt('结束时间')
.build();
Scheduler
Quartz 是以模块的方式构建的,Job 和 Trigger 之间的结合需要靠 Scheduler。
上述例子是通过 Quartz 默认的 SchedulerFactory来得到Scheduler 实例
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();
我们也可以使用自定义参数(Properties)来创建和初始化 Quartz 调度器。
public class QuartzProperties {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, "org.quartz.simpl.SimpleThreadPool"); // 线程池定义
props.put("org.quartz.threadPool.threadCount", "5"); // 默认Scheduler的线程数
StdSchedulerFactory factory = new StdSchedulerFactory(props);
Scheduler scheduler = factory.getScheduler();
}
}
但是并不推荐使用这种硬编码,假如需要修改例子中线程数量,将不得不修改代码,然后重新编译。
可以将配置参数存储在 quartz.properties文件中,程序去读取,比较灵活。
配置文件参考


Quartz 监听器
监听器是一种特殊的类,可以注册到Quartz调度器中,以便在作业和触发器事件发生时接收通知并执行相应的逻辑。监听器可以帮助开发人员监视和控制任务的执行,以及在需要时采取适当的行动。
JobListener
用于监听作业的生命周期事件,如作业执行前、执行后、被否决等。以实现JobListener接口来创建自定义的作业监听器。
-
JobListener接口
getName( ): 获取JobListener 的名称jobToBeExecuted( ): 将要被执行时调用的方法jobExecutionVetoed( ):即将被执行,但又被TriggerListener否决时会调用该方法jobWasExecuted( ):被执行之后调用这个方法
-
定义自定义Job监听器
public class MyJobListener implements JobListener { @Override public String getName() { return getClass().getSimpleName(); } @Override public void jobToBeExecuted(JobExecutionContext context) { String jobName = context.getJobDetail().getKey().toString(); System.out.println("Job " + jobName + " 将要被执行时"); } @Override public void jobExecutionVetoed(JobExecutionContext context) { String jobName = context.getJobDetail().getKey().toString(); System.out.println("Job " + jobName + " 即将被执行,但又被TriggerListener否决时会调用该方法"); } @Override public void jobWasExecuted(JobExecutionContext context, JobExecutionException e) { String jobName = context.getJobDetail().getKey().toString(); System.out.println("Job " + jobName + " 被执行之后调用这个方法"); if (e != null) { System.out.println("Exception occurred during execution: " + e.getMessage()); } } } -
在调度器中注册该作业监听器
JobListener jobListener = new MyJobListener(); scheduler.getListenerManager().addJobListener(jobListener, EverythingMatcher.allTriggers()); -
控制台运行结果
Job myJob.group1 将要被执行时 Job myJob.group1 被执行之后调用这个方法
TriggerListener
用于监听触发器的生命周期事件,如触发器触发前、触发后、被否决等。实现TriggerListener接口来创建自定义的触发器监听器。
-
TriggerListener接口
getName( ): 获取TriggerListener的名称triggerFired( ):被触发时执行vetoJobExecution( ):在 Trigger 触发后,将要调用。TriggerListener 给了一个选择去否post决 Job 的执行。假如这个方法返回 true,这个 Job 将不会执行triggerMisfired( ):错过触发执行,更该关注此方法中持续时间长的逻辑,避免错过触发导致的骨牌效应triggerComplete( ): 被触发并且完成了 Job 的执行时调用
-
定义自定义TriggerListener
public class TestTriggerListener implements TriggerListener { @Override public String getName() { return getClass().getSimpleName(); } @Override public void triggerFired(Trigger trigger, JobExecutionContext jobExecutionContext) { System.out.println(trigger.getKey().getName() + "被触发"); } @Override public boolean vetoJobExecution(Trigger trigger, JobExecutionContext jobExecutionContext) { System.out.println(trigger.getKey().getName() + "进行表决,是否允许执行job"); // true 标识 不允许 return false; } @Override public void triggerMisfired(Trigger trigger) { System.out.println(trigger.getKey().getName() + "错过触发"); } @Override public void triggerComplete(Trigger trigger, JobExecutionContext jobExecutionContext, Trigger.CompletedExecutionInstruction completedExecutionInstruction) { System.out.println(trigger.getKey().getName() + "完成之后触发"); } } -
在调度器中注册该作业监听器
// 全局监听 scheduler.getListenerManager() .addTriggerListener(new TestTriggerListener(), EverythingMatcher.allTriggers()); -
控制台运行结果
trigger被触发 trigger进行表决,是否允许执行job Job myJob.group1 将要被执行时 Job myJob.group1 被执行之后调用这个方法 trigger完成之后触发
SchedulerListener
用于监听调度器的生命周期事件,如调度器启动前、启动后、关闭前、关闭后等。实现SchedulerListener接口来创建自定义的调度器监听器。
-
SchedulerListener接口
jobScheduled( ):用于部署JobDetail时调用jobUnscheduled( ):用于卸载JobDetail时调用triggerFinalized( ):当一个 Trigger 来到了再也不会触发的状态时调用这个方法。除非这个 Job 已设置成了持久性,否则它就会从 Scheduler 中移除。triggersPaused( ):Scheduler 调用这个方法是发生在一个 Trigger 或 Trigger 组被暂停时。假如是 Trigger 组的话,triggerName 参数将为 null。triggersResumed( ):Scheduler 调用这个方法是发生成一个 Trigger 或 Trigger 组从暂停中恢复时。假如是 Trigger 组的话,假如是 Trigger 组的话,triggerName 参数将为 null。参数将为 null。jobsPaused( ):当一个或一组 JobDetail 暂停时调用这个方法。jobsResumed( ):当一个或一组 Job 从暂停上恢复时调用这个方法。假如是一个 Job 组,jobName 参数将为 null。schedulerError( ):在 Scheduler 的正常运行期间产生一个严重错误时调用这个方法。schedulerStarted( ):当Scheduler 开启时,调用该方法schedulerInStandbyMode( ): 当Scheduler处于StandBy模式时,调用该方法schedulerShutdown( ):当Scheduler停止时,调用该方法schedulingDataCleared( ):当Scheduler中的数据被清除时,调用该方法。
-
自定义调度监听器
public class TestSchedulerListener implements SchedulerListener { @Override public void jobScheduled(Trigger trigger) { System.out.println(trigger.getJobKey().getName() + " 完成部署"); } @Override public void jobUnscheduled(TriggerKey triggerKey) { System.out.println(triggerKey + " 完成卸载"); } @Override public void triggerFinalized(Trigger trigger) { System.out.println("触发器被移除 " + trigger.getJobKey().getName()); } @Override public void triggerPaused(TriggerKey triggerKey) { System.out.println(triggerKey + " 正在被暂停"); } @Override public void triggersPaused(String triggerGroup) { System.out.println("触发器组 " + triggerGroup + " 正在被暂停"); } @Override public void triggerResumed(TriggerKey triggerKey) { System.out.println(triggerKey + " 正在从暂停中恢复"); } @Override public void triggersResumed(String triggerGroup) { System.out.println("触发器组 " + triggerGroup + " 正在从暂停中恢复"); } @Override public void jobAdded(JobDetail jobDetail) { System.out.println(jobDetail.getKey() + " 添加工作任务"); } @Override public void jobDeleted(JobKey jobKey) { System.out.println(jobKey + " 删除工作任务"); } @Override public void jobPaused(JobKey jobKey) { System.out.println(jobKey + " 工作任务正在被暂停"); } @Override public void jobsPaused(String jobGroup) { System.out.println("工作任务组 " + jobGroup + " 正在被暂停"); } @Override public void jobResumed(JobKey jobKey) { System.out.println(jobKey + " 正在从暂停中恢复"); } @Override public void jobsResumed(String jobGroup) { System.out.println("工作任务组 " + jobGroup + " 正在从暂停中恢复"); } @Override public void schedulerError(String msg, SchedulerException cause) { System.out.println("产生严重错误时调用: " + msg + " " + cause.getUnderlyingException()); } @Override public void schedulerInStandbyMode() { System.out.println("调度器在挂起模式下调用"); } @Override public void schedulerStarted() { System.out.println("调度器 开启时调用"); } @Override public void schedulerStarting() { System.out.println("调度器 正在开启时调用"); } @Override public void schedulerShutdown() { System.out.println("调度器 已经被关闭 时调用"); } @Override public void schedulerShuttingdown() { System.out.println("调度器 正在被关闭 时调用"); } @Override public void schedulingDataCleared() { System.out.println("调度器的数据被清除时调用"); } } -
注册调度监听器
scheduler.getListenerManager() .addSchedulerListener(new TestSchedulerListener()); -
控制台结果
jobDetailGroup.jobDetail 添加工作任务 jobDetail 完成部署 调度器 正在开启时调用 调度器 开启时调用 trigger被触发 trigger进行表决,是否允许执行job Job myJob.group1 将要被执行时 Job myJob.group1 被执行之后调用这个方法 jobDetail -- Scheduler在JobDetail被执行之后调用这个方法 trigger完成之后触发
SrpingBoot 集成
相关依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-quartzartifactId>
<version>2.7.5version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
<version>8.0.26version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
持久化
各个数据库的脚本可以去 Quarz GitHub获取(GitHub友情链接),本文使用Mysql。
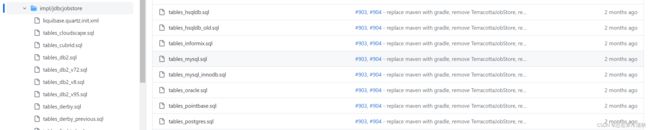

下面是 Quartz 提供的 11 张数据库表及其说明:
| 表名 | 说明 |
|---|---|
| QRTZ_BLOB_TRIGGERS | 存储 BLOB 类型的触发器相关信息 |
| QRTZ_CALENDARS | 存储日历信息 |
| QRTZ_CRON_TRIGGERS | 存储 Cron 类型的触发器相关信息 |
| QRTZ_FIRED_TRIGGERS | 存储已触发的触发器的执行状态信息 |
| QRTZ_JOB_DETAILS | 存储任务详情信息 |
| QRTZ_LOCKS | 存储程序的锁定状态信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储被暂停的触发器组的信息 |
| QRTZ_SCHEDULER_STATE | 存储调度程序的状态信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储 Simple 类型的触发器相关信息 |
| QRTZ_SIMPROP_TRIGGERS | 存储用于在给定时间间隔触发的触发器的额外信息 |
| QRTZ_TRIGGERS | 存储触发器的通用信息 |
这些表格用于存储 Quartz 调度器的相关信息,包括触发器、任务详情、日历、执行状态
关键代码
- JavaBean方式初始化SchedulerFactoryBean,也可以直接使用默认的,需求为主。使用的
quartz.properties见文章末尾提供的项目demo资源链接。@Configuration public class QuartzConfig { @Bean public Scheduler scheduler() { return schedulerFactoryBean().getScheduler(); } // 自定义SchedulerFactoryBean @Bean public SchedulerFactoryBean schedulerFactoryBean() { SchedulerFactoryBean factoryBean = new SchedulerFactoryBean(); factoryBean.setSchedulerName("cluster-s"); factoryBean.setApplicationContextSchedulerContextKey("总在寒冷清秋"); // 配置文件 factoryBean.setConfigLocation(new ClassPathResource("quartz.properties")); //数据源自定义 factoryBean.setDataSource(quartzDataSource()); // 延迟执行 // factoryBean.setStartupDelay(10); factoryBean.setWaitForJobsToCompleteOnShutdown(true); // 启动时更新己存在的Job,这样就不用每次修改targetObject后删除qrtz_job_details表对应记录了 factoryBean.setOverwriteExistingJobs(true); return factoryBean; } @Bean @QuartzDataSource public DataSource quartzDataSource() { DataSourceBuilder dataSourceBuilder = DataSourceBuilder.create(); dataSourceBuilder.driverClassName("com.mysql.cj.jdbc.Driver"); dataSourceBuilder.url("jdbc:mysql://192.168.1.110:3306/quartz"); dataSourceBuilder.username("root"); dataSourceBuilder.password("jsepc01!"); return dataSourceBuilder.build(); } } - SpringBoot集成Quartz,Job任务继承
QuartzJobBean类public class SampleJob extends QuartzJobBean { @Override protected void executeInternal(JobExecutionContext context) { System.out.println("Hello, Quartz!"); } } - 监听程序上下文(所有的 bean 已经被加载和初始化完成)
@Component public class MyApplicationListener implements ApplicationListener<ContextRefreshedEvent> { @Autowired private Scheduler scheduler; @Override public void onApplicationEvent(ContextRefreshedEvent contextRefreshedEvent) { TriggerKey triggerKey = new TriggerKey("trigger", "trigger"); try { Trigger trigger = scheduler.getTrigger(triggerKey); if (Objects.isNull(trigger)) { Trigger trigger1 = TriggerBuilder.newTrigger() .withIdentity(triggerKey) .withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?")) .build(); JobDetail jobDetail = JobBuilder.newJob(SampleJob.class).withIdentity("job1", "job1").build(); scheduler.scheduleJob(jobDetail, trigger1); scheduler.start(); } } catch (Exception e) { throw new RuntimeException(e); } } } - 启动测试
- 数据库数据



- 数据库数据
集群表现
-
服务集群如下

-
数据库展现调度器正常

-
观察相关日志可以看到,只有quartz01这个服务在执行任务

-
停止quartz01,quartz02执行相关调度
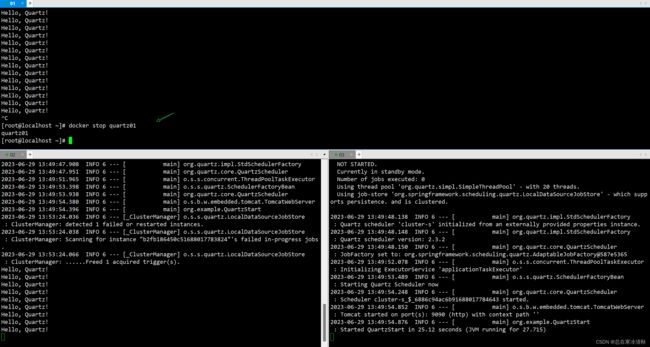
-
重启quzrtz01,调度并不会转为01执行
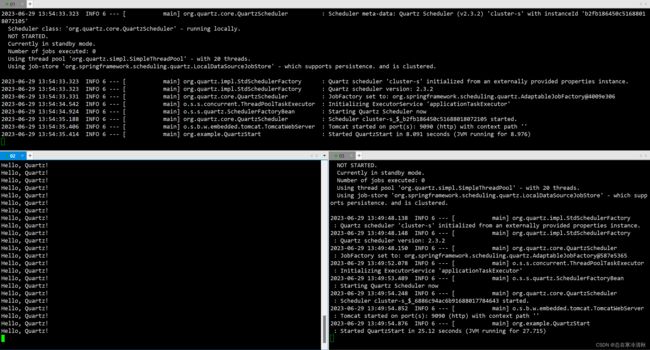
-
将quartz01、quart02都停止,任务调度转为quartz03执行

我们将 Quartz 的任务信息存储在共享的数据库中,而不是内存中。这样,无论任务在哪个节点上执行,它们的状态和执行记录都可以共享和同步。Quartz 节点会通过数据库表或其他共享存储机制相互通信,协调任务的调度和执行。
排他性锁补充
为了进一步保证任务的不重复执行,可以进一步使用QRTZ_LOCKS表来实现排他性锁,在执行任务时进行锁的判定操作。
public class MyJob implements Job {
private static final String LOCK_NAME = "myJobLock";
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
JobStoreTX jobStore = (JobStoreTX) context.getScheduler().getContext().get("quartzJobStore");
boolean lockAcquired = false;
try {
lockAcquired = jobStore.getLockManager().obtainLock(context, LOCK_NAME);
if (lockAcquired) {
// 执行任务逻辑
// ...
} else {
// 任务已被其他节点锁定,无需执行
// ...
}
} finally {
if (lockAcquired) {
jobStore.getLockManager().releaseLock(context, LOCK_NAME);
}
}
}
}
使用 Quartz 的 JobStoreTX 实例和 LockManager 接口来获取和释放锁。通过调用 obtainLock 方法来获取锁,返回值表示是否成功获取锁。在任务逻辑执行完成后,通过调用 releaseLock 方法释放锁。
注意:在任务的 JobExecutionContext 中获取 Quartz 的 JobStoreTX 实例和 LockManager 接口,可以通过调用 getScheduler().getContext().get(“quartzJobStore”) 获取。
通过上述步骤,在 Quartz 集群中使用排他性锁可以确保任务在同一时刻只有一个节点获得执行权限,从而避免任务的重复执行