操作系统真象还原实验记录之实验七:加载内核
操作系统真象还原实验记录之实验七:加载内核
对应书P207
1.相关基础知识总结
1.1 elf格式
1.1.1 c程序如何转化成elf格式
写好main.c的源程序
//main.c
int main(void)
{
while(1);
return;
}
使用命令
gcc -c -o main.o main.c && ld main.o -Ttext 0xc0001500 -e main -o kernel.bin
gcc会自动将main.c转化成具有elf格式的kernel.bin,并且,指定0xc0001500这个虚拟地址作为main.c的入口函数地址,也就是main.c第一个被执行的函数的地址。
1.1.2 被转化成elf格式后kernel.bin的布局

上图的解释

windows下可执行文件格式是PE,Linux下可执行文件格式是elf。
elf文件格式是不同操作系统之间可移植二进制文件格式
gcc编译后的文件有两种状态,一种可重定位阶段,一种是可执行阶段,
程序资源包括节和段,段就是数据段、代码段等,许多节构成段。
处于链接阶段的可重定位文件,必须有的是elf文件头+节头表。
处于可执行阶段的文件,必须有的是elf文件头+程序头表(记录段,也就是链接文件后,会把许多节合并成一个段)。
将许多可重定位文件链接成可执行文件,会把许多节合并成段,有两种情况,一种是给出入口函数地址,这样生成的可执行文件每个标号的地址就固定了,可执行文件被加载到内存的位置也固定了;还有一种情况,就是不给入口地址,可执行文件被加载到内存的时候,根据共享目标文件.so,动态链接,共享目标文件成为可执行文件的一部分。
本次实验
elf头大小固定,记录了程序头表的信息。
程序头表的所有表项记录了c程序每个段的信息,所以大小不一。
根据此图所以本次实验kernel.bin的结构应该是:
elf头+程序头表+第一个段
其中第一个段首地址还不是我们的main函数
第一个段包括文件头+main函数
也就是说0xc0001500这个地址在第一个段内
编程思路
程序头表每个表项大小固定,elf头内有每个表项大小,表项个数,第一个表项起始地址,故可以遍历所有程序头表表项
每个程序头表表项中,拥有该表项对应段的大小,段首地址,以及段应该被搬运的目的地址p_vaddr(已本项目为例,命令指出入口函数地址0xc0001500,则main函数位于0xc0001500,main不是段首,前面还有该段的文件头,所以p_vaddr为0xc0001000)。因此通过p_vaddr可以知道main这个段应该被搬到0xc0001000处才能保证入口地址为0xc0001500。
1.2.3 elf头以及程序头表内的关键字段
新定义的数据类型

elf头

程序头表

其中本次实验代码要使用的字段及其功能如下
e_phentsize: 程序头表一个表项的大小,位于elf头首址+42字节处,用来遍历头表每一个表项。
e_phoff:程序头表在整个文件的偏移量,位于elf头首址+28字节处,用来获得程序头表首址,该值应该是0x34,因为elf头大小固定
e_phnum: 表示程序头表表项的个数,也就是c程序段的个数。用来遍历头表每一个表项,位于elf头首址+44字节处
有了上述elf头内的信息,也就可以访问程序头表每一个段了。
p_type:p_type=PT_NULL。则此段未使用,跳过,不加载进内存。位于程序头表第一个字段,也就是程序头表的首址
p_filesz: 该段的大小,单位字节,位于程序头表首址+16字节。显然对此段的拷贝前需要知道此段的大小。
p_offset:该段相对于elf头首址的偏移量。位于该程序头表项首址+4字节,拷贝段前当然要知道段的起始地址。
p_vaddr:段的目的地址,位于位于程序头表首址+8字节。这个字段有点难理解。这个字段记录了段被拷贝后的首地址
p_offset与p_vaddr的区别:
任何c程序被gcc编译链接成elf文件后,该文件会被增加elf头和程序头表,然后被加载到内存地址A处,在A处按照elf格式解析elf头和程序头表,获得各个段的信息,然后再将各个段拷贝到相应内存地址B,今后cpu要运行这个c程序,就会执行内存地址B的代码。内存地址A的elf格式文件在各个段成功拷贝后,将毫无用处,最后会被覆盖。
这个内存地址A就是p_offset+elf头首址
这个内存地址B就是p_vaddr
当然上述都是虚拟地址。因为加载内核的代码前已经开启了分页。
而且还要注意的一点是,内存地址B只是拷贝后的段的首址,0xc0001500是指定的入口函数main的地址,位于段中。
本次实验中p_vaddr的值为0xc0001000
而loader.s最后一句jmp指令进内核执行死循环的地址为0xc0001500,显然0xc0001000~0xc0001500为该段其他代码,0xc0001500以上才是死循环编译后的指令。

2.实验记录
2.1实验目的
使用命令
gcc -c -o main.o main.c && ld main.o -Ttext 0xc0001500 -e main -o kernel.bin
gcc会自动将main.c转化成具有elf格式的kernel.bin
将kernel.bin刻入磁盘第9扇区,修改loader.s将其从磁盘加载到内存0x70000,该地址就是elf头的首地址
在loader.s新编一个函数kernel_init,读取elf头内的信息,再读取程序头表,根据elf规范将kernel.c的所有段拷贝到内存中相应位置,我们这次的main.c只有一个段,段内是死循环。
loader.s最后一句代码是jmp到0xc0001500地址。该地址就是设计好的死循环函数的入口地址。
bochs模拟最后程序死循环,说明死循环段被成功加载到虚拟地址0xc0001500处。

2.2实验代码
loader.s
%include "boot.inc"
section loader vstart=LOADER_BASE_ADDR
;构建gdt及其内部的描述符
GDT_BASE: dd 0x00000000
dd 0x00000000
CODE_DESC: dd 0x0000FFFF
dd DESC_CODE_HIGH4
DATA_STACK_DESC: dd 0x0000FFFF
dd DESC_DATA_HIGH4
VIDEO_DESC: dd 0x80000007 ; limit=(0xbffff-0xb8000)/4k=0x7
dd DESC_VIDEO_HIGH4 ; 此时dpl为0
GDT_SIZE equ $ - GDT_BASE
GDT_LIMIT equ GDT_SIZE - 1
times 60 dq 0 ; 此处预留60个描述符的空位(slot)
SELECTOR_CODE equ (0x0001<<3) + TI_GDT + RPL0 ; 相当于(CODE_DESC - GDT_BASE)/8 + TI_GDT + RPL0
SELECTOR_DATA equ (0x0002<<3) + TI_GDT + RPL0 ; 同上
SELECTOR_VIDEO equ (0x0003<<3) + TI_GDT + RPL0 ; 同上
; total_mem_bytes用于保存内存容量,以字节为单位,此位置比较好记。
; 当前偏移loader.bin文件头0x200字节,loader.bin的加载地址是0x900,
; 故total_mem_bytes内存中的地址是0xb00.将来在内核中咱们会引用此地址
total_mem_bytes dd 0
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
;以下是定义gdt的指针,前2字节是gdt界限,后4字节是gdt起始地址
gdt_ptr dw GDT_LIMIT
dd GDT_BASE
;人工对齐:total_mem_bytes4字节+gdt_ptr6字节+ards_buf244字节+ards_nr2,共256字节
ards_buf times 244 db 0
ards_nr dw 0 ;用于记录ards结构体数量
loader_start:
;------- int 15h eax = 0000E820h ,edx = 534D4150h ('SMAP') 获取内存布局 -------
xor ebx, ebx ;第一次调用时,ebx值要为0
mov edx, 0x534d4150 ;edx只赋值一次,循环体中不会改变
mov di, ards_buf ;ards结构缓冲区
.e820_mem_get_loop: ;循环获取每个ARDS内存范围描述结构
mov eax, 0x0000e820 ;执行int 0x15后,eax值变为0x534d4150,所以每次执行int前都要更新为子功能号。
mov ecx, 20 ;ARDS地址范围描述符结构大小是20字节
int 0x15
jc .e820_failed_so_try_e801 ;若cf位为1则有错误发生,尝试0xe801子功能
add di, cx ;使di增加20字节指向缓冲区中新的ARDS结构位置
inc word [ards_nr] ;记录ARDS数量
cmp ebx, 0 ;若ebx为0且cf不为1,这说明ards全部返回,当前已是最后一个
jnz .e820_mem_get_loop
;在所有ards结构中,找出(base_add_low + length_low)的最大值,即内存的容量。
mov cx, [ards_nr] ;遍历每一个ARDS结构体,循环次数是ARDS的数量
mov ebx, ards_buf
xor edx, edx ;edx为最大的内存容量,在此先清0
.find_max_mem_area: ;无须判断type是否为1,最大的内存块一定是可被使用
mov eax, [ebx] ;base_add_low
add eax, [ebx+8] ;length_low
add ebx, 20 ;指向缓冲区中下一个ARDS结构
cmp edx, eax ;冒泡排序,找出最大,edx寄存器始终是最大的内存容量
jge .next_ards
mov edx, eax ;edx为总内存大小
.next_ards:
loop .find_max_mem_area
jmp .mem_get_ok
;------ int 15h ax = E801h 获取内存大小,最大支持4G ------
; 返回后, ax cx 值一样,以KB为单位,bx dx值一样,以64KB为单位
; 在ax和cx寄存器中为低16M,在bx和dx寄存器中为16MB到4G。
.e820_failed_so_try_e801:
mov ax,0xe801
int 0x15
jc .e801_failed_so_try88 ;若当前e801方法失败,就尝试0x88方法
;1 先算出低15M的内存,ax和cx中是以KB为单位的内存数量,将其转换为以byte为单位
mov cx,0x400 ;cx和ax值一样,cx用做乘数
mul cx
shl edx,16
and eax,0x0000FFFF
or edx,eax
add edx, 0x100000 ;ax只是15MB,故要加1MB
mov esi,edx ;先把低15MB的内存容量存入esi寄存器备份
;2 再将16MB以上的内存转换为byte为单位,寄存器bx和dx中是以64KB为单位的内存数量
xor eax,eax
mov ax,bx
mov ecx, 0x10000 ;0x10000十进制为64KB
mul ecx ;32位乘法,默认的被乘数是eax,积为64位,高32位存入edx,低32位存入eax.
add esi,eax ;由于此方法只能测出4G以内的内存,故32位eax足够了,edx肯定为0,只加eax便可
mov edx,esi ;edx为总内存大小
jmp .mem_get_ok
;----------------- int 15h ah = 0x88 获取内存大小,只能获取64M之内 ----------
.e801_failed_so_try88:
;int 15后,ax存入的是以kb为单位的内存容量
mov ah, 0x88
int 0x15
jc .error_hlt
and eax,0x0000FFFF
;16位乘法,被乘数是ax,积为32位.积的高16位在dx中,积的低16位在ax中
mov cx, 0x400 ;0x400等于1024,将ax中的内存容量换为以byte为单位
mul cx
shl edx, 16 ;把dx移到高16位
or edx, eax ;把积的低16位组合到edx,为32位的积
add edx,0x100000 ;0x88子功能只会返回1MB以上的内存,故实际内存大小要加上1MB
.mem_get_ok:
mov [total_mem_bytes], edx ;将内存换为byte单位后存入total_mem_bytes处。
;----------------- 准备进入保护模式 -------------------
;1 打开A20
;2 加载gdt
;3 将cr0的pe位置1
;----------------- 打开A20 ----------------
in al,0x92
or al,0000_0010B
out 0x92,al
;----------------- 加载GDT ----------------
lgdt [gdt_ptr]
;----------------- cr0第0位置1 ----------------
mov eax, cr0
or eax, 0x00000001
mov cr0, eax
jmp dword SELECTOR_CODE:p_mode_start ; 刷新流水线,避免分支预测的影响,这种cpu优化策略,最怕jmp跳转,
; 这将导致之前做的预测失效,从而起到了刷新的作用。
.error_hlt: ;出错则挂起
hlt
[bits 32]
p_mode_start:
mov ax, SELECTOR_DATA
mov ds, ax
mov es, ax
mov ss, ax
mov esp,LOADER_STACK_TOP
mov ax, SELECTOR_VIDEO
mov gs, ax
; ------------------------- 加载kernel ----------------------
mov eax, KERNEL_START_SECTOR ; kernel.bin所在的扇区号
mov ebx, KERNEL_BIN_BASE_ADDR ; 从磁盘读出后,写入到ebx指定的地址
mov ecx, 200 ; 读入的扇区数
call rd_disk_m_32
; 创建页目录及页表并初始化页内存位图
call setup_page
;要将描述符表地址及偏移量写入内存gdt_ptr,一会用新地址重新加载
sgdt [gdt_ptr] ; 存储到原来gdt所有的位置
;将gdt描述符中视频段描述符中的段基址+0xc0000000
mov ebx, [gdt_ptr + 2]
or dword [ebx + 0x18 + 4], 0xc0000000 ;视频段是第3个段描述符,每个描述符是8字节,故0x18。
;段描述符的高4字节的最高位是段基址的31~24位
;将gdt的基址加上0xc0000000使其成为内核所在的高地址
add dword [gdt_ptr + 2], 0xc0000000
add esp, 0xc0000000 ; 将栈指针同样映射到内核地址
; 把页目录地址赋给cr3
mov eax, PAGE_DIR_TABLE_POS
mov cr3, eax
; 打开cr0的pg位(第31位)
mov eax, cr0
or eax, 0x80000000
mov cr0, eax
;在开启分页后,用gdt新的地址重新加载
lgdt [gdt_ptr] ; 重新加载
;;;;;;;;;;;;;;;;;;;;;;;;;;;; 此时不刷新流水线也没问题 ;;;;;;;;;;;;;;;;;;;;;;;;
;由于一直处在32位下,原则上不需要强制刷新,经过实际测试没有以下这两句也没问题.
;但以防万一,还是加上啦,免得将来出来莫句奇妙的问题.
jmp SELECTOR_CODE:enter_kernel ;强制刷新流水线,更新gdt
enter_kernel:
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
call kernel_init
mov esp, 0xc009f000
jmp KERNEL_ENTRY_POINT ; 用地址0x1500访问测试,结果ok
;----------------- 将kernel.bin中的segment拷贝到编译的地址 -----------
kernel_init:
xor eax, eax
xor ebx, ebx ;ebx记录程序头表地址
xor ecx, ecx ;cx记录程序头表中的program header数量
xor edx, edx ;dx 记录program header尺寸,即e_phentsize
mov dx, [KERNEL_BIN_BASE_ADDR + 42] ; 偏移文件42字节处的属性是e_phentsize,表示program header大小
mov ebx, [KERNEL_BIN_BASE_ADDR + 28] ; 偏移文件开始部分28字节的地方是e_phoff,表示第1 个program header在文件中的偏移量
; 其实该值是0x34,不过还是谨慎一点,这里来读取实际值
add ebx, KERNEL_BIN_BASE_ADDR
mov cx, [KERNEL_BIN_BASE_ADDR + 44] ; 偏移文件开始部分44字节的地方是e_phnum,表示有几个program header
.each_segment:
cmp byte [ebx + 0], PT_NULL ; 若p_type等于 PT_NULL,说明此program header未使用。
je .PTNULL
;为函数memcpy压入参数,参数是从右往左依然压入.函数原型类似于 memcpy(dst,src,size)
push dword [ebx + 16] ; program header中偏移16字节的地方是p_filesz,压入函数memcpy的第三个参数:size
mov eax, [ebx + 4] ; 距程序头偏移量为4字节的位置是p_offset
add eax, KERNEL_BIN_BASE_ADDR ; 加上kernel.bin被加载到的物理地址,eax为该段的物理地址
push eax ; 压入函数memcpy的第二个参数:源地址
push dword [ebx + 8] ; 压入函数memcpy的第一个参数:目的地址,偏移程序头8字节的位置是p_vaddr,这就是目的地址
call mem_cpy ; 调用mem_cpy完成段复制
add esp,12 ; 清理栈中压入的三个参数
.PTNULL:
add ebx, edx ; edx为program header大小,即e_phentsize,在此ebx指向下一个program header
loop .each_segment
ret
;---------- 逐字节拷贝 mem_cpy(dst,src,size) ------------
;输入:栈中三个参数(dst,src,size)
;输出:无
;---------------------------------------------------------
mem_cpy:
cld
push ebp
mov ebp, esp
push ecx ; rep指令用到了ecx,但ecx对于外层段的循环还有用,故先入栈备份
mov edi, [ebp + 8] ; dst
mov esi, [ebp + 12] ; src
mov ecx, [ebp + 16] ; size
rep movsb ; 逐字节拷贝
;恢复环境
pop ecx
pop ebp
ret
;------------- 创建页目录及页表 ---------------
setup_page:
;先把页目录占用的空间逐字节清0
mov ecx, 4096
mov esi, 0
.clear_page_dir:
mov byte [PAGE_DIR_TABLE_POS + esi], 0
inc esi
loop .clear_page_dir
;开始创建页目录项(PDE)
.create_pde: ; 创建Page Directory Entry
mov eax, PAGE_DIR_TABLE_POS
add eax, 0x1000 ; 此时eax为第一个页表的位置及属性
mov ebx, eax ; 此处为ebx赋值,是为.create_pte做准备,ebx为基址。
; 下面将页目录项0和0xc00都存为第一个页表的地址,
; 一个页表可表示4MB内存,这样0xc03fffff以下的地址和0x003fffff以下的地址都指向相同的页表,
; 这是为将地址映射为内核地址做准备
or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性RW和P位为1,US为1,表示用户属性,所有特权级别都可以访问.
mov [PAGE_DIR_TABLE_POS + 0x0], eax ; 第1个目录项,在页目录表中的第1个目录项写入第一个页表的位置(0x101000)及属性(3)
mov [PAGE_DIR_TABLE_POS + 0xc00], eax ; 一个页表项占用4字节,0xc00表示第768个页表占用的目录项,0xc00以上的目录项用于内核空间,
; 也就是页表的0xc0000000~0xffffffff共计1G属于内核,0x0~0xbfffffff共计3G属于用户进程.
sub eax, 0x1000
mov [PAGE_DIR_TABLE_POS + 4092], eax ; 使最后一个目录项指向页目录表自己的地址
;下面创建页表项(PTE)
mov ecx, 256 ; 1M低端内存 / 每页大小4k = 256
mov esi, 0
mov edx, PG_US_U | PG_RW_W | PG_P ; 属性为7,US=1,RW=1,P=1
.create_pte: ; 创建Page Table Entry
mov [ebx+esi*4],edx ; 此时的ebx已经在上面通过eax赋值为0x101000,也就是第一个页表的地址
add edx,4096
inc esi
loop .create_pte
;创建内核其它页表的PDE
mov eax, PAGE_DIR_TABLE_POS
add eax, 0x2000 ; 此时eax为第二个页表的位置
or eax, PG_US_U | PG_RW_W | PG_P ; 页目录项的属性RW和P位为1,US为0
mov ebx, PAGE_DIR_TABLE_POS
mov ecx, 254 ; 范围为第769~1022的所有目录项数量
mov esi, 769
.create_kernel_pde:
mov [ebx+esi*4], eax
inc esi
add eax, 0x1000
loop .create_kernel_pde
ret
;-------------------------------------------------------------------------------
;功能:读取硬盘n个扇区
rd_disk_m_32:
;-------------------------------------------------------------------------------
; eax=LBA扇区号
; ebx=将数据写入的内存地址
; ecx=读入的扇区数
mov esi,eax ; 备份eax
mov di,cx ; 备份扇区数到di
;读写硬盘:
;第1步:设置要读取的扇区数
mov dx,0x1f2
mov al,cl
out dx,al ;读取的扇区数
mov eax,esi ;恢复ax
;第2步:将LBA地址存入0x1f3 ~ 0x1f6
;LBA地址7~0位写入端口0x1f3
mov dx,0x1f3
out dx,al
;LBA地址15~8位写入端口0x1f4
mov cl,8
shr eax,cl
mov dx,0x1f4
out dx,al
;LBA地址23~16位写入端口0x1f5
shr eax,cl
mov dx,0x1f5
out dx,al
shr eax,cl
and al,0x0f ;lba第24~27位
or al,0xe0 ; 设置7~4位为1110,表示lba模式
mov dx,0x1f6
out dx,al
;第3步:向0x1f7端口写入读命令,0x20
mov dx,0x1f7
mov al,0x20
out dx,al
;;;;;;; 至此,硬盘控制器便从指定的lba地址(eax)处,读出连续的cx个扇区,下面检查硬盘状态,不忙就能把这cx个扇区的数据读出来
;第4步:检测硬盘状态
.not_ready: ;测试0x1f7端口(status寄存器)的的BSY位
;同一端口,写时表示写入命令字,读时表示读入硬盘状态
nop
in al,dx
and al,0x88 ;第4位为1表示硬盘控制器已准备好数据传输,第7位为1表示硬盘忙
cmp al,0x08
jnz .not_ready ;若未准备好,继续等。
;第5步:从0x1f0端口读数据
mov ax, di ;以下从硬盘端口读数据用insw指令更快捷,不过尽可能多的演示命令使用,
;在此先用这种方法,在后面内容会用到insw和outsw等
mov dx, 256 ;di为要读取的扇区数,一个扇区有512字节,每次读入一个字,共需di*512/2次,所以di*256
mul dx
mov cx, ax
mov dx, 0x1f0
.go_on_read:
in ax,dx
mov [ebx], ax
add ebx, 2
; 由于在实模式下偏移地址为16位,所以用bx只会访问到0~FFFFh的偏移。
; loader的栈指针为0x900,bx为指向的数据输出缓冲区,且为16位,
; 超过0xffff后,bx部分会从0开始,所以当要读取的扇区数过大,待写入的地址超过bx的范围时,
; 从硬盘上读出的数据会把0x0000~0xffff的覆盖,
; 造成栈被破坏,所以ret返回时,返回地址被破坏了,已经不是之前正确的地址,
; 故程序出会错,不知道会跑到哪里去。
; 所以改为ebx代替bx指向缓冲区,这样生成的机器码前面会有0x66和0x67来反转。
; 0X66用于反转默认的操作数大小! 0X67用于反转默认的寻址方式.
; cpu处于16位模式时,会理所当然的认为操作数和寻址都是16位,处于32位模式时,
; 也会认为要执行的指令是32位.
; 当我们在其中任意模式下用了另外模式的寻址方式或操作数大小(姑且认为16位模式用16位字节操作数,
; 32位模式下用32字节的操作数)时,编译器会在指令前帮我们加上0x66或0x67,
; 临时改变当前cpu模式到另外的模式下.
; 假设当前运行在16位模式,遇到0X66时,操作数大小变为32位.
; 假设当前运行在32位模式,遇到0X66时,操作数大小变为16位.
; 假设当前运行在16位模式,遇到0X67时,寻址方式变为32位寻址
; 假设当前运行在32位模式,遇到0X67时,寻址方式变为16位寻址.
loop .go_on_read
ret
代码新增了几个函数
rd_disk_m_32:,用于把gcc编译链接后的kernel.bin从磁盘读到内存
kernel_init:用于按照elf规范解析kernel.bin,遍历每一个段,调用mem_cpy来将其拷贝到0xc0001000,
虚拟地址0xc0001500是入口函数的地址.
mem_cpy拷贝段
此次loader.s这将是最终版,以后均不修改了。
注意,进入保护模式前。sp被置为0x900,进入保护模式后,ss使用数据段,分页后ss得到的数据段的段基址0x00000000,所以为了让esp处于3GB以上内核空间,esp加了0xc0000000.

2.main.c
//main.c
int main(void)
{
while(1);
return;
}
3.boot.inc新增
KERNEL_BIN_BASE_ADDR equ 0x70000
KERNEL_START_SECTOR equ 0x9
KERNEL_ENTRY_POINT equ 0xc0001500
;------------- program type 定义 --------------
PT_NULL equ 0
2.3实验记录
1.编译loader.s
nasm -o loader.bin loader.s
2.编译mbr.s
nasm -o mbr.bin mbr.s
3.将mbr.bin刻入第0扇区
dd if=/home/Seven/bochs2.68/bin/mbr.bin of=/home/Seven/bochs2.68/bin/Seven.img bs=512 count=1 seek=0 conv=notrunc
4.将loader.bin刻入第2扇区
dd if=/home/Seven/bochs2.68/bin/loader.bin of=/home/Seven/bochs2.68/bin/Seven.img bs=512 count=3 seek=2 conv=notrunc
5.main.c的编译链接刻入硬盘第9扇区
gcc -m32 -c -o main.o main.c && ld -m elf_i386 -Ttext 0xc0001500 -e main -o kernel.bin main.o && dd if=kernel.bin of=/home/Seven/bochs2.68/bin/Seven.img bs=512 count=200 seek=9 conv=notrunc
这里有个要注意的地方,使用的是Ubuntu64位系统,所以要使用以上的编译方法才能生成32位文件格式的ELF文件,否则在初始化内核时会出现问题。
使用书上的命令编译链接出来的文件会有6.1KB
使用此命令只会编译1.7KB,符合书上描述的不到4块扇区。
6.模拟bochs
./bochs -f bochsrc.disk 按c继续
2.4实验结果


死循环才对
3.特权级、TSS、I/O位图
TSS、I/O位图都和特权级有部分的关系
3.1 CPL RPL DPL
假设程序处于某个代码段,执行的代码即将要访问某个数据段。
CPL:当程序处于某个代码段,CS:IP指向该代码段的某条指令,这个时候,CS低两位即CS.RPL=此代码段的DPL=CPL。
RPL:此代码段的代码是要访问某个数据段的数据,为此将此数据段选择子赋值给了DS,然后,使用DS:bx访问数据段,那么这个时候的DS.RPL=RPL,也就是程序要使用的选择子的低两位为RPL。
DPL:选择子高13位所指向的数据段段描述符内的DPL即=DPL。DPL即要访问的段的DPL。
数值越低,特权级越高,特权级有0,1,2,3。
3.2访问各种段特权级检查规则
1 数据段
当用户进程CPL=1,赋值给ds要访问数据段的选择子RPL为0时,不使用门服务(即中断处理程序),
若要访问的段为数据段,只能访问DPL为1,2,3的数据段。
即数值上CPL<=DPL且RPL<=DPL,如此看来,即使伪造特权级很高的RPL,CPL是硬伤,无法访问0特权级。
2 代码段
当用户进程CPL=1,赋值给cs要跳转的代码段的选择子RPL为1时,不使用门服务(即中断处理程序),
若要跳转到某个非一致性代码段,只能跳转DPL为1的代码段,即平级转移,
即CPL=RPL=DPL
因为任何程序不能访问权限比自己高的段,也不需要自降权限获得某个服务。
若要跳转到某个一致性代码段,可以跳转DPL为1,0的代码段,即直接向高级转移,
即CPL=>DPL 且RPL=>DPL
一致性代码段的特点是,支持程序从低特权级向高特权级跳转,但是,跳转后CPL并不会变成此段的DPL,也就是说本质上特权级并没有改变,只是cpu可以执行更高级的代码了而已。
3 栈段
若要访问的是栈段,CPL=SS.RPL=用作栈的数据段的DPL
因为除了特权级3以外,不同特权级都有自己的栈,CPL即CS.RPL每次改变,对应的SS也会跟着变,SS指向的栈段的DPL始终都等于CPL。SS是不需要人为去维护的。ss段寄存器是当 CPL发生变化的时候系统自动维护,汇编没有给程序员自己改变ss的指令,所以一旦访问栈段,那么CPL都会=RPL=DPL。
3.3 触发特权级检查时机
受访者为数据时,
特权级检查发生在段寄存器加载选择子的时候,包括DS,FS,ES,GS
举个例子:mov ds, ax;
这句代码会触发特权级检查,ax.RPL即RPL<=ax所指段的DPL 且 CPL<=DPL.
受访者为代码段,显然,远转移CS:IP被赋值前就应该检查,检查通过就更新,从而程序跳转。检查发生在访问前的一瞬间。
3.4 门结构
跳转到一致性代码段,本质是不会升高特权级的,CPL不变。
要想实现程序跳转到高特权级代码段且CPL同时变低,就必须要使用门结构。



除了任务门,其他三个门都对应一段例程。
它的选择子对应的代码段的DPL叫DPL_CODE
调用门使用call jmp,位于GDT,LDT
中断门int指令
陷阱门int3指令,用于调试程序。
任务门用于TSS的任务切换,位于GDT,LDT,IDT
自制的OS也只用到了中断门,中断门陷阱门仅位于IDT。
现代操作系统很少使用调用门、任务门。
3.5 调用门的使用及特权级检查
门描述符自己有个DPL叫DPL_GATE
门描述符有个选择子,这个选择子指向的代码段的DPL叫做DPL_CODE
以调用门为例:
首先,调用门是个描述符,需要一个选择子,
格式是call/jmp 某个调用门选择子:偏移量;这个偏移量会被cpu忽视。
这个call是改变cs的指令,cs加载调用门选择子时,会触发特权级检查
call指令下
数值上
RPL<=DPL_GATE 且 DPL_CODE <= CPL<=DPL_GATE
调用门选择子RPL只是与DPL_GATE比较而已。
显然,使用调用门这个过程cs会加载两次选择子,
第一次触发的特权级检查为CPL<=DPL_GATE且RPL<=DPL_GATE
成功后,第二次cs要加载调用门内的选择子了,触发的特权级检查为
DPL_CODE <= CPL
调用门结束,只有通过retf或iret才能从高特权级返回到低特权级
jmp指令只支持平级
DPL_CODE <= CPL=DPL_GATE 且 RPL<=DPL_GATE
特权级触发时机原理同上
因为除了retf和iret这种必须被动从高向低返回,程序无法主动向更低特权级跳转的机会,jmp一旦可以向更高特权级跳转,那么意味着低特权级的资源永远无法使用,故jmp只能平级转移
然后调用前有些调用门是需要用户进程提供选择子作为参数的,但是这个选择子的RPL可以由用户指定。也就是说,如果此选择子的RPL=0,然后选择子指向的段DPL=0是内核段,再程序跳转到调用门指向的内核例程,CPL=0,用户就可以借助调用门访问内核段,这显然是不行的,所以
用户进程提供的作为参数的选择子的RPL会数值上变成自己的CPL,保留了进入门前的CPL特权级。这样即使这个选择子指向内核段,由于RPL权限低,也无法访问。
3.6 TSS以及使用调用门栈的转换

TSS中不需要记录特权级3的栈,因为没有程序会向特权级3的栈跳转,除了retf和iret从高向低返回。
call指令调用门完整过程
(1) 首先用户进程3,为调用门提供两个参数,使用的是特权级3的栈,在此栈压入两个参数,然后call 调用门选择子:偏移量(由于是调用门,偏移量会被忽略)

(2)根据调用门选择子,cpu找到调用门描述符,通过里面的S为0判断出为系统段,再根据TYPE判断出是调用门,从而特权级检查成为了
RPL<=DPL_GATE 且 DPL_CODE <= CPL<=DPL_GATE。
(3)特权级检查通过后,根据该调用门对应的函数例程的DPL,判断要用什么样的新特权级栈,然后找个地方临时保存SS_old和ESP_old,同时更新SS:ESP为SS_new:ESP_new,然后再将临时保存的SS_old,ESP_old入新栈。
(4)然后再将旧栈的两个参数复制到新栈
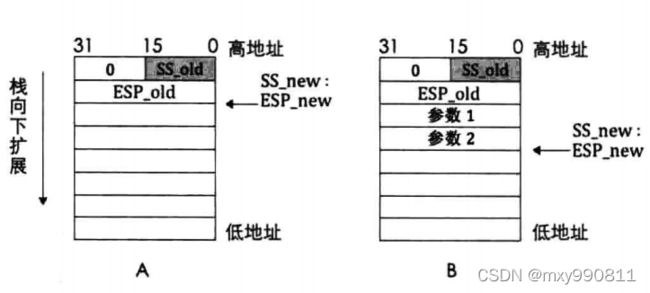
(5)新旧栈切换好了,再改变特权级即CPL,先将CS_old:EIP_old入新栈,再将调用门描述符中函数例程选择子和偏移量即CS_new:EIP_new赋值给CS:EIP。从而完成程序从低向高的跳转。

调用结束时,使用retf + 参数个数(此例为2)*参数大小(此例为32) 从调用门远返回:
(1)先检查CS_old的RPL,retf是允许程序从高特权级向低特权级转移,故特权级检查规则是,CS_old.RPL>=CPL,则通过。
(2)通过后,将EIP_old,CS_old弹到CS:EIP中,其中保护模式下段寄存器仍只有16位,所以CS_old只取低16位。
(3)然后,根据retf后面的参数,ESP_new要跳过参数1、2,指向ESP_old。
(4)根据第(1)步特权级检查,得知特权级改变,故要重新使用旧栈,所以弹出ESP_old和SS_old到ESP,SS。ESP_new和SS_new从而废弃丢失。
注意:如果在返回时需要改变特权级,还会检查数据段寄存器DS、ES、FS、GS,如果其中某个指向的段的DPL比返回后的CPL权限要高,则置为0,GDT第0个段描述符是哑描述符,访问会处理器异常。
如果不置0,那么返回到用户进程CPL=3,但是它的数据段指向的可以是内核段,特权级检查只发生在段寄存器加载选择子的时候,所以用户进程就可以访问内核段了。
门结构的作用本质以及越权可能的总结
门结构的作用就是把程序的CPL权限变高,这样就可以给数据段寄存器赋值DPL更高的的选择子了,选择子的RPL程序员想给多高就给多高,能不能加载上去的关键是CPL。
因此这样就会有两个可能越权的问题
第一:你在门里面,即在CPL=0的地方给ds赋值了DPL=0的段,那你从门里出来依然可以访问这个段,所以ds要清0
第二:我可以找一个需要选择子作为参数的门结构,提供一个RPL,DPL都=0的选择子,利用门代码的功能,跑到门里CPL=0后再加载这个选择子,这样也就是变相完成了CPL=3的时候加载了DPL,RPL=0的选择子,只不过加载后必须走门结构对应的代码,会受到束缚,但依然越权,所有就有了进入门后选择子参数的RPL变成进入前的CPL,保留了进入前的权限,这样在门里,RPL成了短板,依然无法完成加载。
3.7 I/O位图、eflag中的IOPL(12、13位)
当CPL<=IOPL时,I/O接口中的所有I/O端口(intel处理器最大支持65536个)均可访问;
当CPL>IOPL时,I/O位图才有作用,
若I/O位图存在,I/O位图所有为0的对应的端口可以访问;
若不存在,所有端口都禁用
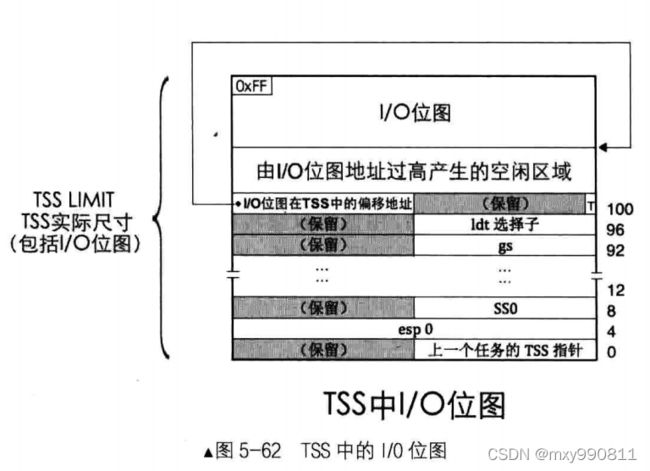

如何判断I/O位图是否存在
I/O位图位于TSS,范围是I/O位图偏移地址+8192+1字节 “1”(0xFF)
也就是104到TSS段界限limit之间。超过这个范围,I/O位图不存在。
为什么最高位字节是0xFF
I/O端口按字节编址

如果0x234号端口映射在位图最后一个字节最后一个比特,那么0x235号端口就要跨I/O位图的字节了,可能会超过I/O位图范围。也就是说一条in/out指令可能会跨I/O位图字节访存TSS。
所以最后一个字节一律0xFF,
如果实际端口数超过I/O位图的比特数,那么0XFF一i定会映射8个端口,表示禁用这8个端口,这无所谓。
如果实际端口数少于I/O位图的比特数,那么0XFF表示边界标记,不映射端口,防止访问TSS外的内存。
4.真实的Linux如何加载操作系统的内核(个人猜测)
调用lsblk会发现,系统盘有两个分区,上面均已经创建了文件系统,一个是挂载在/boot的文件系统,一个是挂载在/的文件系统。
/boot以文件形式保存编译好的内核源码,每次Loader.s程序会以文件的形式把os读到内存,然后解析elf,jmp到main函数执行。
所以真实的加载Linux的系统盘的loader.s相比我们的loader.s会多一些处理文件绝对路径,获取内核源码文件所在扇区号、根据扇区号读磁盘扇区这样的函数,但是读一个扇区到内存函数依然很简陋,因为在加载os阶段,访问硬盘不同考虑多线程互斥读同一个磁盘问题,也不用考虑中断问题,也没有一个内存管理系统以位图的形式管理内存。所以读一个扇区只需要给硬盘下命令然后循环查询寄存器status等待即可。
当成功以文件形式把os读到内存,解析完毕elf并jmp到内核的main函数后,内核源码实际上实现了包含中断、多进程、锁、内存管理系统的读扇区函数,以及适配各种类型文件系统的文件绝对路径解析函数,从而封装出sys_read和sys_write等这样的系统调用接口方便访问文件系统。这样的系统调用其实被用于各种高级编程语言,比如python的read,c的sys_read。同时在他们的基础上实现了shell命令更加方便依靠绝对路径访问文件,以及在shell基础上又实现了vim这样的文件编辑器。