使用python通过接口爬取图书网站数据2.0
目录
一、前言
二、代码分析
三、效果展示
四、总结
五、彩蛋分享
一、前言
温馨提示:刚开始学习爬虫的小白可以看看我发的前三部教程,循序渐进的来,不至于看得有些懵
在观看Scrape Center网站中找到spa3,上一篇文章有法
spa3练习简介:电影数据网站,无反爬,数据通过 Ajax 加载,无页码翻页,下拉至底部刷新,适合 Ajax 分析和动态页面渲染爬取。
OK,let's go,上代码
import json
import requests
import pandas as pd
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
# 创建四个空列表,用来存放所需数据
title,type,score,cover, = [],[],[],[]
for i in range(10):
url = 'https://spa3.scrape.center/api/movie/?limit=10&offset='+str(i*10)
index = requests.get(url,headers=headers)
# print(index) # 200
dict_data = json.loads(index.text)
# print(dict_data)
# print(dict_data['results'][0])
for x in range(10):
title.append(dict_data['results'][x]['name']+" "+dict_data['results'][x]['alias'])
type.append(dict_data['results'][x]['categories'])
score.append(dict_data['results'][x]['score'])
cover.append(dict_data['results'][x]['cover'])
# print(type)
data = {
'电影名':title,
'类型':type,
'评分':score,
'图片':cover
}
# print(data)
# 将data数据通过自动生成一个表格
work = pd.DataFrame(data)
print(work)
# 文件保存路径
file_path = pd.ExcelWriter("work.xlsx")
work.to_excel(file_path,encoding='utf-8')
file_path.save()
二、代码分析
1.看了前面的教程,找接口已经很熟悉了,F12找到响应数据类型(Type)为xhr的数据,查看Request URL接口。
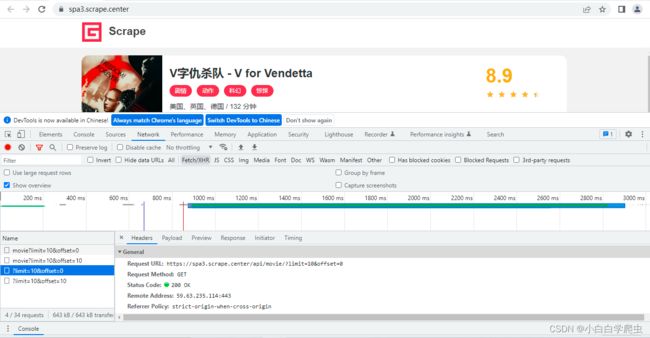
2.分析接口,limit控制个数,offset控制从第几个开始,当页面下滑刷新时,limit不变,offset+10,与上一篇接口解释类似
接口分析结束,看代码实现讲解
①请求头中的信息不能少,创建了四个列表,用来存放所需的数据
import json
import requests
import pandas as pd
# 请求头中的UA
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
# 创建四个空列表,用来存放所需数据
title,type,score,cover = [],[],[],[]②Preview中预览的count为101,则当前网页有数据101条

③因为下拉会刷新且新增数据,且下拉数据由offset控制,所以将offset数据设为变量,又因为count=101条,所以,将url遍历10此,符合当前接口规则
for i in range(10):
url = 'https://spa3.scrape.center/api/movie/?limit=10&offset='+str(i*10)
#以get方式发送url
index = requests.get(url,headers=headers)
# print(index) # 200
# 将json字符串转为json字典
dict_data = json.loads(index.text)
# print(dict_data)
# print(dict_data['results'][0])index.text为获取当前请求的json数据,可以自己打印看看。
④在上一个for循环中再嵌套一个for循环(也是遍历10次,因为每个里面0-9,十条数据)

目的:如果直接不筛选全部输出,数据太多,我们只需要跳出我们需要的,正对应前面新建的四个列表
有人看到这里可能会晕,为什么需要dict_data['results'][x]['name'],解释一下,
1、dict_data数据为{'count': 101, 'results': [{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine'.....},{'id': 2, 'name': '这个杀手不太冷', 'alias': 'Léon', 'cover':...}]
2、因为是容器为字典类型,先按照K找到V,dict_data['results'],找到后为一个列表,
[{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine'.....},{'id': 2, 'name': '这个杀手不太冷', 'alias': 'Léon', 'cover':...}]
3、[x]就是获取第x个列表,dict_data['results'][0]
{'id': 1, 'name': '霸王别姬', 'alias': 'Farewell My Concubine'.....}
4、在列表中找到所需的属性['name'] ,dict_data['results'][x]['name']
'霸王别姬'
遍历时将所需的数据全部追加到前面已经定义好的列表中
for x in range(10):
title.append(dict_data['results'][x]['name']+" "+dict_data['results'][x]['alias'])
type.append(dict_data['results'][x]['categories'])
score.append(dict_data['results'][x]['score'])
cover.append(dict_data['results'][x]['cover'])⑤将定义的四个集合,转为一个data字典,方便DataFrame制表
data = {
'电影名':title,
'类型':type,
'评分':score,
'图片':cover
}⑥将data容器制表,生成Excel并保存。
work = pd.DataFrame(data)
print(work)
# 文件保存路径
file_path = pd.ExcelWriter("work.xlsx")
work.to_excel(file_path,encoding='utf-8')
file_path.save()三、效果展示

四、总结
相比上一篇,直接获取全部数据不进行筛选,增加了些难度,思路还是一样,不影响操作,自己再看JavaScript逆向,后续会持续更新...敬请期待
五、彩蛋分享
《python3网络爬虫开发实战第二版 pdf》
学爬虫小白必看书籍之一了,课本的话太贵,这是博主买的电子版,分享给大家,大家有空可以看看,里面讲的挺细的,最近博主也在看。
JXU5NEZFJXU2M0E1JTNBaHR0cHMlM0EvL3Bhbi5iYWlkdS5jb20vcy8xS3RNNmJiRldzYTRlVGtXbFNVYjl3dyVBMCUwQSV1NjNEMCV1NTNENiV1NzgwMSUzQTg1aDg=