基于python數據分析的疫情数据可视化系统
文章目录
- 前言
- 1 课题背景
- 2 实现效果
-
- 2.1 整体界面展示
- 2.2 收集數據
- 3 實現過程
-
- 3.1 爬取疫情數據:
-
- 3.1.1 導包
- 3.1.2 實例化csv
- 3.1.3 防反爬
- 3.1.4 爬取html
- 3.1.5 re解析
- 3.1.6 解析數據
- 3.1.7 保存數據
- 完整代碼
- 3.2 可視化
-
- 3.2.1 導包
- 3.2.2 渲染生成html
- 完整代碼
- 4 相关理论及技术
-
- 4.1 爬虫
- 4.2 Echarts
-
- 4.2.1 安装
- 4.2.2 简单使用
- 4.3 各种属性方法
- 总结
前言
基于python 爬虫的疫情数据可视化系统
选题指导, 项目分享:
https://gitee.com/fbozhang/python/tree/master/spider/%E7%96%AB%E6%83%85%E6%95%B8%E6%93%9A%E5%8F%AF%E8%A6%96%E5%8C%96
1 课题背景
自2019年12月12日武汉确诊新型冠状病毒患者开始,历时三年之久的新冠疫情仍未结束。新型冠状病毒肺炎(COVID-19)存在人畜跨界传播、传染性强、影响因素多样、传播途径复杂等特点,导致肺炎疫情发病急、发展快、溯源分析难、社会危害大等问题。随着新型冠状病毒毒株的不断变异,现出现了传播性极强、免疫逃逸能力极高的变异病毒。
为更直观、更专业地了解疫情的变化,本文设计了基于爬虫、Pyecharts的疫情信息可视化系统。该系统主要包括疫情模型预测、疫情信息可视化以及防疫措施指南三大功能,能够实时动态展示疫情发展趋势,并根据预测模型进行疫情预测以及提供有效的防疫措施。
2 实现效果
2.1 整体界面展示
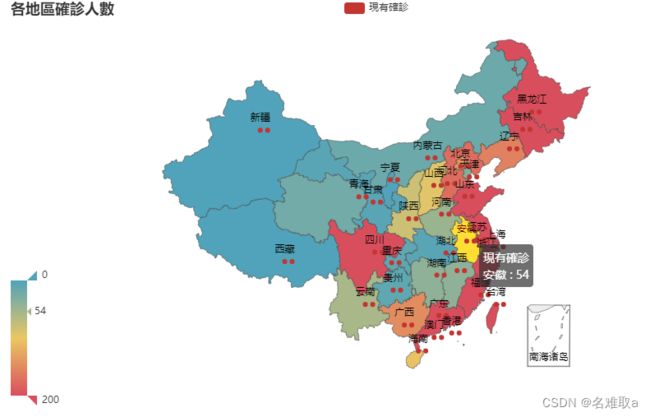
2.2 收集數據
利用爬虫从百度等网站收集了全国31个省份多个城市的确诊病例数量,保存为CSV文件如下图:

3 實現過程
3.1 爬取疫情數據:
3.1.1 導包
csv庫用來將數據寫入保存到 .csv文件;requests庫是用來爬蟲的操作;json庫用來序列化json數據;re庫用來分析html文件,也可以用 BeautifulSoup 或 xpath庫來解析,本次使用re

3.1.2 實例化csv
初始化csv並寫入列頭,即數據標題

3.1.3 防反爬
不加上ua就會把你是個爬蟲的信息發給瀏覽器,就可能報:我是一個茶壺

3.1.4 爬取html
response.close():關閉

3.1.5 re解析
把html傳給re進行解析得到數據存放位置中的數據,並進行json.loads()轉爲python字典類型方便後面使用

3.1.6 解析數據
解析出需要的各個字段數據並接收他們
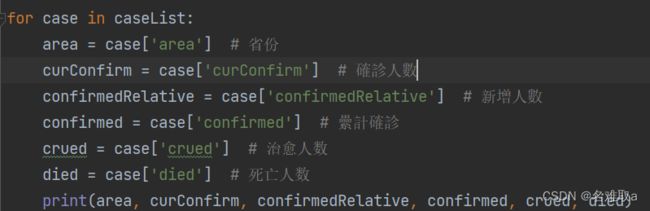
3.1.7 保存數據
將數據寫入到csv文件中

完整代碼
with open('data.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['area', 'curConfirm', 'confirmedRelative', 'confirmed', 'crued', 'died'])
url = "https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_aladin_banner"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
data_html = response.text
response.close()
json_str = re.findall('"component":\[(.*)\}]', data_html)[0] + '}'
# print(json_str) # 得到一個json,打印去json.cn轉譯
json_dict = json.loads(json_str) # 把json字符串轉爲字典
caseList = json_dict['caseList']
for case in caseList:
area = case['area'] # 省份
curConfirm = case['curConfirm'] # 確診人數
confirmedRelative = case['confirmedRelative'] # 新增人數
confirmed = case['confirmed'] # 纍計確診
crued = case['crued'] # 治愈人数
died = case['died'] # 死亡人数
print(area, curConfirm, confirmedRelative, confirmed, crued, died)
with open('data.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([area, curConfirm, confirmedRelative, confirmed, crued, died])
3.2 可視化
3.2.1 導包
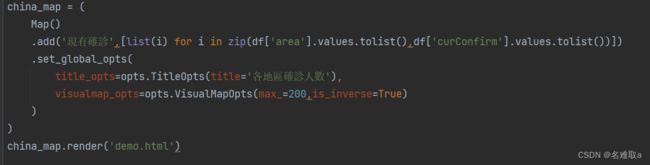
3.2.2 渲染生成html
完整代碼
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
df = pd.read_csv('data.csv',encoding='utf-8')
# print(df)
china_map = (
Map()
.add('現有確診',[list(i) for i in zip(df['area'].values.tolist(),df['curConfirm'].values.tolist())])
.set_global_opts(
title_opts=opts.TitleOpts(title='各地區確診人數'),
visualmap_opts=opts.VisualMapOpts(max_=200,is_inverse=True)
)
)
china_map.render('demo.html')
4 相关理论及技术
4.1 爬虫
简介
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。爬虫对某一站点访问,如果可以访问就下载其中的网页内容,并且通过爬虫解析模块解析得到的网页链接,把这些链接作为之后的抓取目标,并且在整个过程中完全不依赖用户,自动运行。若不能访问则根据爬虫预先设定的策略进行下一个 URL的访问。在整个过程中爬虫会自动进行异步处理数据请求,返回网页的抓取数据。在整个的爬虫运行之前,用户都可以自定义的添加代理,伪 装 请求头以便更好地获取网页数据。爬虫流程图如下

4.2 Echarts
ECharts(Enterprise Charts)是百度开源的数据可视化工具,底层依赖轻量级Canvas库ZRender。兼容了几乎全部常用浏览器的特点,使它可广泛用于PC客户端和手机客户端。ECharts能辅助开发者整合用户数据,创新性的完成个性化设置可视化图表。支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)等,通过导入 js 库在 Java Web 项目上运行。
4.2.1 安装
pip install pyecharts
4.2.2 简单使用
from pyecharts.charts import Bar,Line
from pyecharts import options as opts
from pyecharts.globals import ThemeType
line = (
Line(init_opts=opts.InitOpts(theme=ThemeType.LIGHT, width='1000px',height='300px' ))
.add_xaxis(["衬衫", "羊毛衫", "雪纺衫", "裤子", "高跟鞋", "袜子"])
.add_yaxis("商家A", [5, 20, 36, 10, 75, 90])
.add_yaxis("商家B", [15, 6, 45, 20, 35, 66])
.set_global_opts(title_opts=opts.TitleOpts(title="主标题", subtitle="副标题"),
datazoom_opts=opts.DataZoomOpts(is_show=True))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True))
)
line.render('test.html')
line.render_notebook()
具體查看官方文檔,有詳細的中文解釋
4.3 各种属性方法
add() 主要方法,用于添加图表的数据和设置各种配置项
render() 默认将会在根目录下生成一个 render.html 的文件,文件用浏览器打开
图表配置:图形初始化,通用配置项
- xyAxis:平面直角坐标系中的 x、y 轴。(Line、Bar、Scatter、EffectScatter、Kline)
- dataZoom:dataZoom 组件 用于区域缩放,从而能自由关注细节的数据信息,或者概览数据整体,或者去除离群点的影响。(Line、Bar、Scatter、EffectScatter、Kline、Boxplot)
- legend:图例组件。图例组件展现了不同系列的标记(symbol),颜色和名字。可以通过点击图例控制哪些系列不显示。
- label:图形上的文本标签,可用于说明图形的一些数据信息,比如值,名称等。
- lineStyle:带线图形的线的风格选项(Line、Polar、Radar、Graph、Parallel)
- grid3D:3D笛卡尔坐标系组配置项,适用于 3D 图形。(Bar3D, Line3D, Scatter3D)
- axis3D:3D 笛卡尔坐标系 X,Y,Z 轴配置项,适用于 3D 图形。(Bar3D, Line3D, Scatter3D)
- visualMap:是视觉映射组件,用于进行『视觉编码』,也就是将数据映射到视觉元素(视觉通道)
- markLine&markPoint:图形标记组件,用于标记指定的特殊数据,有标记线和标记点两种。(Bar、Line、Kline)
- tooltip:提示框组件,用于移动或点击鼠标时弹出数据内容
总结
以上就是今天要讲的内容,本文仅仅简单介绍了request 和echarts的使用,而echarts提供了大量能使我们快速便捷地处理数据的函数和方法可以參考官方文檔使用畫出各種不同的圖