Web网站性能压测实践 | 数据平台
一、 为什么要做压测?
首先解释下为什么要做性能压测:根据 Amazon 统计,每慢 100 毫秒,交易额下降 1%。这个统计数据为大家敲响了警钟,也客观说明了性能压测对于企业应用的重要性。从具体的OKR上讲,我们希望能将单机 QPS 提升至 600 ,使得目前线上机器并发能力提升 1 倍。
那么问题来了: 什么是QPS?目前服务器单机QPS是多少?如何才能将单机的QPS提升到600?如何找出系统的瓶颈?
要解决上述问题,就要利用我们本文要讲的压测,如果你还不了解压测,不妨仔细阅读本文
二、 什么是压力测试?
1. 基本概念
一般来说「性能测试」包括压力测试、负载测试、容量测试三种主要测试类型

这里我们主要聚焦压力测试,压力测试是通过不断向被测系统施加压力,测试系统在压力情况下的性能表现。主要考察当前软硬件环境下系统所能承受的最大负荷并帮助开发人员找出系统瓶颈所在。我们可以模拟巨大的流量请求以查看应用程序在峰值使用情况以及服务器状况。
2. 核心指标
核心指标:TPS、QPS、RT、系统CPU利用率、系统内存等

3. 压测工具
工欲善其事,必先利其器。压测工具有很多,大家可以自行去了解,这里就主要说说我们本次压测使用的工具:wrk。
wrk是一款针对Http协议的基准测试工具,它能够在单机多核 CPU的条件下,使用系统自带的高性能 I/O机制,如 Epoll,Kqueue等,通过多线程和事件模式,对目标机器产生大量的负载。
安装wrk

使用./wrk命令启动
![]()
参数说明:
-c:HTTP连接数,每一个线程处理N = 连接数/线程数
-d:持续时间,3s,3m,3h
-t:总的线程数
-s:脚本,可以是Lua 脚本
-H:增加HTTP header,例如:User-Agent: iphone
-latency:输出时间统计的细节
-timeout:超时时间
三、压测实践
初次接触压测时,探索基线耗费了我们不少时间,这里着重介绍一下我们探索系统基线测试的过程,下图是探索基线的压测流程:
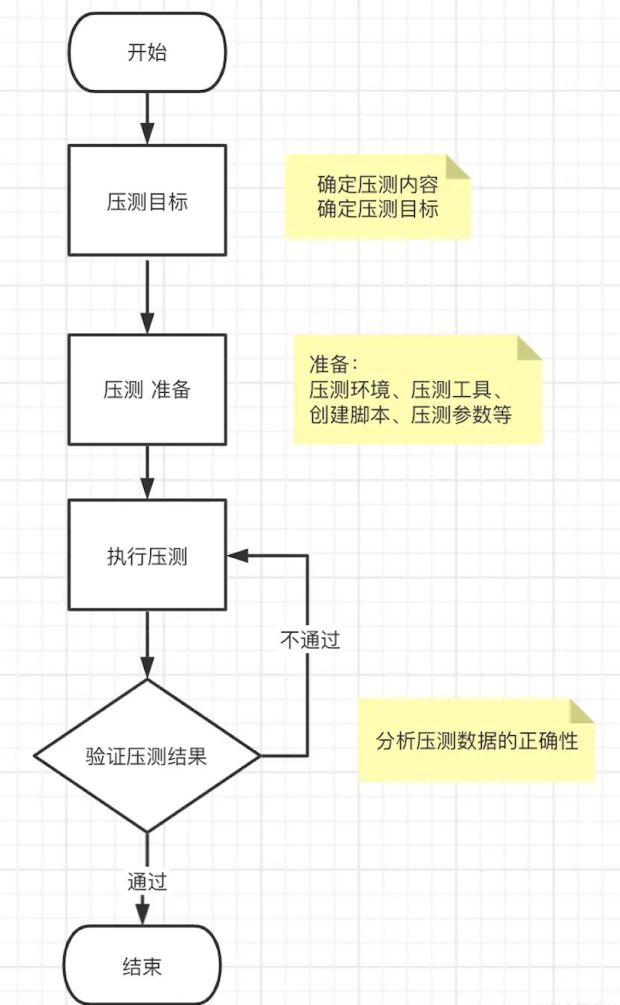
1. 压测目标
这一步骤,主要任务是要明确压测目标、压测内容,以下是我们的压测目标。
现状:线上压测数据单机QPS 300,机器 4C8G,机器硬件由 4C8G 升级为 8C16G
优化目标:单机QPS 300提升至 600 ,机器数量不变,并发能力提升 1 倍
压测目标:进行基准测试,通过压测确定系统基线,为后续分析优化提供参考
2、压测准备
一般线上压测要尽可能避开流量高峰期,大多是在凌晨进行线上压测,且压测的过程很有可能将服务压挂,我们不可能直接在线上进行压测,因此需要搭建一套供压测使用的仿真环境
为了保障正确定位系统基线,准确定位线上系统瓶颈,对仿真环境提出了很高的要求,有条件的要保证仿真和线上配置一致。次之也要和线上成比例,方便后续分析评估计算。
以我们本次压测项目为例(Nuxt+Vue+SSR搭建的web网站),在这一步骤我要做以下准备:
准备一套压测环境:搭建压测环境你可能需要申请域名、申请Jenkins构建权限、申请堡垒机权限等
调研并选择压测工具
确定压测参数、准备压测脚本
3、 执行压测--基线测试
基线测试是对整个压测流程的探索阶段,系统性能问题,其排查思路更为复杂一些,耗费了我们不少时间,也踩了一些坑,下面详细梳理了基线测试历程:
(1) 使用内部的压测工具压测第一组数据, 压测参数:4T400C,压测3分钟,压测过程中监控压测数据、CPU、内存、负载等,检测到cpu达到120%左右 ,master分支单机QPS均值611,超过目标QPS值 600(优化目标QPS值达到600),难道master分支已经达到了优化目标?
说明一下,这里我们使用3台机器同时施压, 压测的一个主要目的就是将CPU压到极限,观察cpu极限的情况下QPS值,因此我们使用多台机器同时压测
(2) 分析代码发现压测页面有重定向(重定向到其他网站),部分压力转移到其他网站,压测数据不准确。排除重定向影响,保持参数不变,再次压测,压测结果显示:master分支单机QPS值607,依然超过目标值600
(3) 压测过程中了解到公司内部的压测工具 默认单线程,施压能能力有限,后续采用wrk 压测工具进行压测
(4) 依然对数据的准备性保持怀疑,再次排查发现:仿真环境服务器(24核)与线上服务器(4核)相差较大 ,导致仿真环境与线上环境 压测数据相差较大,不利于评估计算
下图仿真环境服务器(24核)情况截图:

(5) 为了更加真实的模拟线上环境,搭建一套仿真环境(服务器4核),仿真环境服务器截图如下:

(6) 我们发现,压测过程中CPU使用率在120左右,也会造成QPS值偏大,更加合理的压测,应该是控制CPU使用率在100%左右
(7) 为了更加准备找到基线,我们保持压测参数同线上一致(服务器:4C8G,压测参数:16T1000C,压测3分钟),使用wrk压测工具分别在服务器端、本机进行压测,服务器端压测结果:QPS :337

两人同时本机使用wrk压测:QPS:(89163+112449)/180 =1120 对比发现两组QPS:服务端337,本地:1120,数据相差太大
怀疑可能由于本机施压不够,导致本机压测QPS值过大,放弃本机压测,开始在服务器进行压测,保持压测参数不变(服务器:4C8G,压测参数:16T1000C,压测3分钟 ),压测结果如下,你会发现几乎90%的请求都超时了,超时严重,这个时候要逐步降低施压,直到基本不会超时

(8) 经过以上步骤,最后确定:压测服务器:4C8G,压测参数:4T200C,
分别压测nuxt空项目(对照组)、master分支(现状)、优化分支(优化组),分析三组数据得出基线
假设你得到一下数据:

分析数据,得到以下三个重要指标:
nuxt 空项目 :QPS 1000 ,这是优化极限目标
master分支 :QPS 300,是优化的基线
优化分支与master分支的QPS差值是100,优化的预计收益就是100 QPS
总结一些压测过程中注意观察的点:
服务器资源监控cpu、内存、 I/O
响应是否变慢
是否有报错
请求超时问题
是否正常返回200状态码
服务器是否正常响应
四、 分析瓶颈&性能优化
将分析系统瓶颈,并针对瓶颈进行优化的过程抽象为四个主要步骤:
简要流程如下图所示:
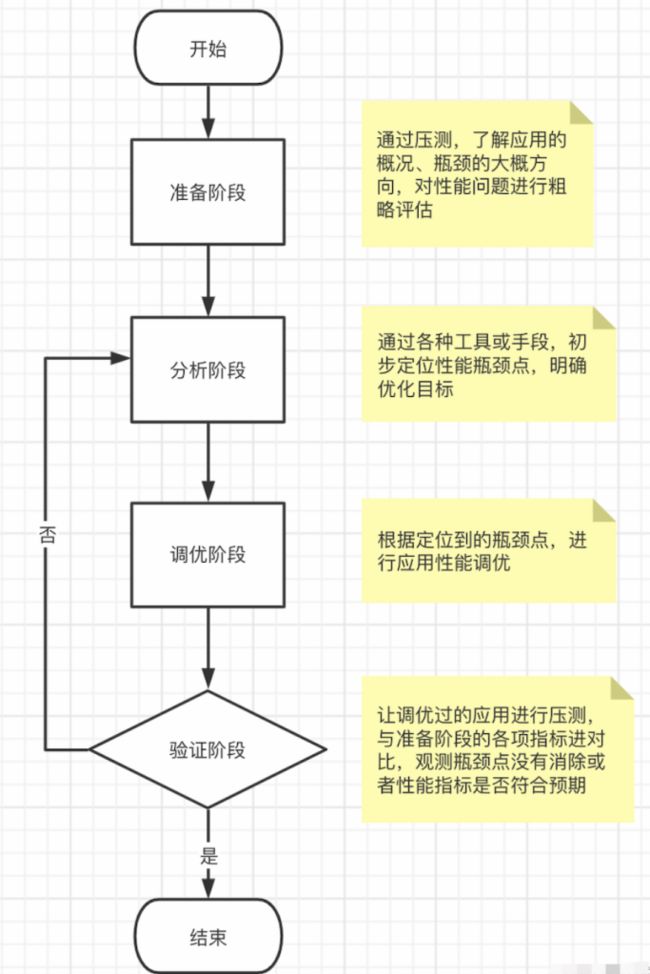
结合本次压测实战,来说说这4个步骤我们要做了些什么
1. 准备阶段:
在这一阶段主要任务是了解瓶颈的大概方向,对性能问题进行粗略评估。我们采用注释代码的方法法探测系统瓶颈,主要方法是,逐步注释影响系统性能的模块,记录注释后的压测结果,对比压测数据,分析影响QPS关键因素,这一步,我们粗略估算Vue-Router是提升QPS的瓶颈
2. 分析阶段:
主要任务是通过各种工具或手段,初步定位性能瓶颈点,明确优化目标,我们使用了Node性能分析工具node-clinic ,分析Node 方向,node-clinic火焰图如下:白色部分表示CPU密集计算,直接影响 QPS,判定这里是瓶颈

3. 调优阶段:
主要任务是根据定位到的瓶颈点,进行应用性能调优,分析明确vue-router瓶颈之后,针对瓶颈,我们将系统使用nuxt自动生成路由,优化为自定义路由配置,同时我们对QPS有提升的其他优化点做了优化
自定义路由配置
首屏页面 使用服务端渲染(ssr)
全局组件、样式、方法 的拆分
nuxt.config.js 移除 serverMiddleware 配置
4. 验证阶段:
让调优过的应用进行压测,与准备阶段的各项指标进行对比,观测其是否符合预期,如果瓶颈点没有消除或者性能指标不符合预期,则重复步骤2和3。
五、 迭代上线 &后续优化计划
当压力测试的结果符合了预期的调优目标,或者与基线数据相比,有很大的改善,则我们进行迭代开发上线。
性能优化是一个渐进、迭代的过程,上线后,需要对调优后的系统进行测试验证,保持环境一致,通过压测,对比优化上线前后性能的变化,是否符合预期结果
一个阶段的优化工作完成以后,最好是总结反思一下:
本次优化是否达到了目标?
系统的整体性能是否得到了改善?
用户体验是否得到了提升?
优化遗留问题如何解决?
以及如何在接下来的开发工作中做的更好?
六、 反思总结:
选择合适的性能优化工具,可以使得性能优化取得事半功倍的效果;
压测过程中注意控制单一变量,每次改变一个变量,引入多个变量会给我们的观测、优化过程造成干扰
压测结束之后,会将压测过程中的系统表现、监控数据等整理,进行压测复盘,分析当前系统瓶颈、后续改进修复计划及下一轮压测时间等,
性能优化是一个渐进、迭代的过程,需要逐步、动态地持续进行