OneFlow源码解析:基础计算接口Primitive

作者|郑建华
此前,OneFlow 版本更新博客中的第 5 节对框架的“多设备适配”作了说明,原文摘录如下:
OneFlow 提供简洁高效易扩展的硬件抽象层 EP(Execution Provider),以应对适配不同硬件的复杂性。引入硬件抽象层之后,用户无需关注底层硬件和框架的具体实现细节,框架的各个模块无需改动便可以适配新的硬件设备,同时,用户只需按照硬件抽象接口的约定和硬件设备的实际情况,实现一系列接口,便可以完成硬件的适配工作。
EP 还定义了一组基础计算接口 Primitive,基于 Primitive 接口重新实现了 Kernel。相比 EP 提供的运行时接口,Primitive 提供的接口更加灵活,不同接口之间相互独立,每一个接口表示了某种硬件设备可以提供的特定的计算能力。
ep 模块主要包括两部分。一部分是之前讨论的设备管理,根据用户提供的信息能获取设备实例,将设备抽象出 Stream、Event、内存管理等接口。
另一部分就是基础计算接口 Primitive。这里只简要介绍一下 Primitive 的概念,包含哪些内容。不会涉及具体计算的设计和实现。
1
Primitive 是什么?
粗略地说,基础计算接口是指 Primitive 目录下定义的二十来个基础计算接口类。它们都是 Primitive 的子类。这些接口类型通常只声明一个 Launch 方法,实际支持哪些计算是由针对具体设备的实现决定的。
各基础计算接口如下表所示:
Primitive 接口类型 |
设备实现 |
支持的操作 |
补充说明 |
Add |
CPU, CUDA, OneDnn |
DataType |
|
BatchMatmul |
BatchMatmulImpl |
是否转置 |
转发给 BroadcastMatmul |
BroadcastElementwiseBinary |
CPU, CUDA, OneDnn |
BinaryOp |
支持 BinaryOp 操作 |
BroadcastElementwiseUnary |
CPU, CUDA |
UnaryOp |
支持 UnaryOp 操作 |
BroadcastMatmul |
BroadcastMatmulImpl |
是否转置 |
CPU 和 CUDA 实现都是基于模版类 BroadcastMatmulImpl |
Cast |
CPU, CUDA |
DataType |
|
ConstantPad |
CPU, CUDA |
DataType |
|
CopyNd |
CPU, CUDA |
DimSize |
|
ElementwiseUnary |
CPU, CUDA |
UnaryOp |
支持 UnaryOp 操作 |
Fill |
CPU, CUDA |
DataType |
|
LogSoftmax |
CPU, CUDA, OneDnn |
DataType |
与 SoftmaxBackward 复用实现 |
LogSoftmax |
CPU, CUDA, OneDnn |
DataType |
与Softmax 复用实现。 SoftmaxImpl 的基类 SoftmaxBase 可以是 Softmax 或 LogSoftmax。 |
Matmul |
MatmulImpl |
是否转置 |
转发给 BatchMatmul |
Memcpy |
CPU, CUDA |
设备拷贝方向 |
Host2Device、Device2Host …… |
Memset |
CPU, CUDA |
||
Permute |
CPU, CUDA, OneDnn |
DimSize |
|
SoftmaxBackward |
CPU, CUDA, OneDnn |
与 LogSoftmaxBackward 复用实现 |
|
Softmax |
CPU, CUDA, OneDnn |
与 LogSoftmax 复用实现。 |
|
TensorFill |
CPU, CUDA |
DataType |
2
部分计算接口的说明
2.1 ElementwiseUnary
2.1.1 relu kernel 的执行过程
relu kernel 就是通过 ElementwiseUnary 执行计算的。注册 relu kernel 的 SetCreateFn 函数执行类似如下代码的操作。UnaryPrimitiveKernel 构造时会保存 primitive_factory_func_。
auto primitive_factory_func_ = [](user_op::KernelComputeContext* ctx) {
const user_op::TensorDesc* src = ctx->TensorDesc4ArgNameAndIndex("x", 0);
const user_op::TensorDesc* dst = ctx->TensorDesc4ArgNameAndIndex("y", 0);
return ep::primitive::NewPrimitive(
ctx->device_type(), ep::primitive::UnaryOp::kRelu, src->data_type(),
dst->data_type());
};
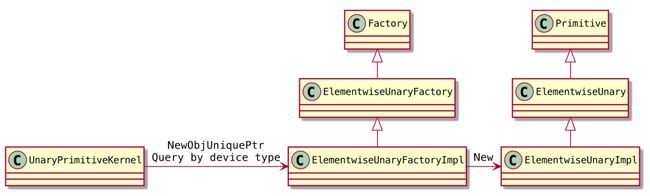
OpKernel* ptr = new UnaryPrimitiveKernel("y", "x", primitive_factory_func_); 在调用 UnaryPrimitiveKernel::Compute 执行 kernel 计算时,执行如下操作:
调用 primitive_factory_func_ 获取一个 primitive 实例。
NewPrimitive
调用 NewObjUniquePtr 获取 ElementwiseUnaryFactoryImpl 实例(CPU,CUDA)。
调用 ElementwiseUnaryFactoryImpl::New 返回 ElementwiseUnaryImpl 实例(CPU, CUDA)。
调用 primitive->Launch 执行计算。
上述类之间的关系如下:
2.1.2 ElementwiseUnary 支持哪些操作?
ElementwiseUnaryFactoryImpl::New 中的宏展开后,代码如下。根据 UnaryOp 的操作类别、数据类型查到 New 函数,传递对应的模版参数给 New 函数并创建 ElementwiseUnaryImpl 实例。
ElementwiseUnary 在 CPU 环境支持的<操作, 数据类型>组合都在这个 map 中注册。这个就是“常规”意义上的“Primitive 接口”的一部分(支持哪些操作、数据类型等),操作的输入参数由 Launch 函数的接口决定。
static const std::map<
std::tuple,
std::function(Scalar, Scalar)>>
new_elementwise_unary_handle {
{std::make_tuple((UnaryOp::kRelu), DataType::kFloat, DataType::kFloat), NewElementwiseUnary<(UnaryOp::kRelu), float, float>},
{std::make_tuple((UnaryOp::kRelu), DataType::kDouble, DataType::kDouble), NewElementwiseUnary<(UnaryOp::kRelu), double, double>},
{std::make_tuple((UnaryOp::kElu), DataType::kFloat, DataType::kFloat), NewElementwiseUnary<(UnaryOp::kElu), float, float>},
{std::make_tuple((UnaryOp::kLogicalNot), DataType::kDouble, DataType::kBool), NewElementwiseUnary<(UnaryOp::kLogicalNot), double, bool>},
// ......
};
const auto it =
new_elementwise_unary_handle.find(std::make_tuple(unary_op, src_type, dst_dtype));
if (it != new_elementwise_unary_handle.end()) {
return it->second(attr0, attr1);
} else {
return nullptr;
} 2.1.3 ElementwiseUnaryImpl::Launch 的实现
Primitive 不同子类的 Launch 方法,其实现方式和输入参数各不一样。ElementwiseUnaryImpl::Launch 通过 primitive::UnaryFunctor 实现计算逻辑(CPU,CUDA)。
primitive::UnaryFunctor 是一个模版类,其特化版本分布在如下文件:
各设备通用的 UnaryFunctor 实现。其中包括 relu 的实现。
CPU 的 UnaryFunctor 实现。通过 cpu_stream->ParallelFor 并行加速。
CUDA 的 UnaryFunctor 实现。后续通过 cuda::elementwise::Unary 调用设备计算。
2.2 BroadcastElementwiseBinary
BroadcastElementwiseBinary 也定义了 CUDA 的工厂实现。New 函数的 map 中定义了 CUDA 下支持的所有操作组合,每个都是一个 NewBroadcastElementwiseBinary 模版函数的特化实例的引用。这些模版函数的特化定义在下面几个文件中:
broadcast_elementwise_binary_activation_grad.cu
broadcast_elementwise_binary_comparision.cu
broadcast_elementwise_binary_logical.cu
broadcast_elementwise_binary_math.cu
这些文件中的宏可以用如下命令展开,必须指定 WITH_CUDA 才能正常展开宏。
nvcc -DWITH_CUDA \
-E -std=c++17 \
-I. -Ibuild \
-Ibuild/oneflow/ir/llvm_monorepo-src/llvm/include \
-Ibuild/oneflow/ir/llvm_monorepo-build/include \
-Ibuild/half/src/half/include \
-Ibuild/_deps/glog-src/src -Ibuild/_deps/glog-build \
-Ibuild/protobuf/src/protobuf/src \
oneflow/core/ep/cuda/primitive/broadcast_elementwise_binary_math.cu > math.cpp3
UserOp、Kernel 与 Primitive 的关系
3.1 UserOp 与 Kernel 是一对多的关系
之前看过的代码,UserOp 通常只有一个 Kernel,Kernel 不区分设备、通过 Primitive 适配不同的设备计算。但也有例外。
通过 conv kernel 可以看到,CPU 和 CUDA 注册了同名的 kernel。仔细看 UserOpRegistryMgr::op_kernel_reg_result_ 的 value 类型是 vector。所以 UserOp 与 Kernel 是一对多的关系。通过 OpKernelRegistryResult::is_matched_hob 筛选出匹配的 kernel。
以 max_pool_2d 为例,其 Kernel 注册代码如下:
REGISTER_USER_KERNEL("max_pool_2d")
.SetCreateFn>()
.SetIsMatchedHob((user_op::HobDeviceType() == device)
&& (user_op::HobDataType("x", 0) == GetDataType::value)); Kernel 计算的准备阶段,在 StatefulOpKernel::ChooseOpKernel 中相关调用如下:
kernel_reg_val = UserOpRegistryMgr::Get().GetOpKernelRegistryResult(...)
通过 reg_val.is_matched_hob->get(ctx) 判断 Kernel 是否匹配
如果没有匹配会报错。如果多于一个匹配会报警
kernel = kernel_reg_val->create_fn()
3.2 IsMatchedHob 到底是啥?
is_matched_hob 的类型是 IsMatchedHob:
using IsMatchedHob = std::shared_ptr>; (user_op::HobDeviceType() == device) && (user_op::HobDataType("x", 0) == GetDataType
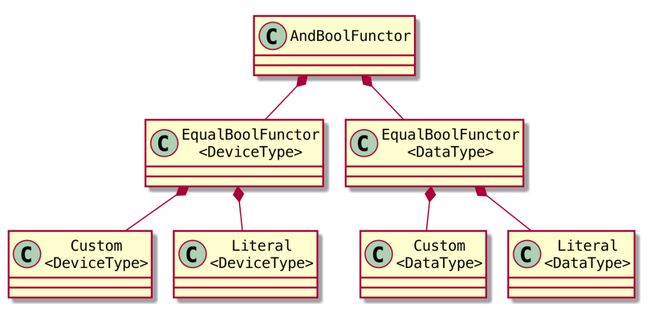
HobDeviceType()返回的类型是 Custom,它是 Expr 的子类,其 ValueT 是 DeviceType。DEFINE_BINARY_FUNCTOR 宏定义了一个重载 Expr 的 == 运算符的函数,第一个参数类型是 Expr(也就是 Custom),第二个参数类型是 Custom::ValueT,也就是 DeviceType,返回的 BoolFunctor 继承自 BoolExpr ,也是 Expr 的子类。类似的,也通过宏定义了 And 运算符的重载。这样就构成了如上图所示的高阶 bool 表达式。BoolFunctor::get 函数在运行时根据 context 动态计算表达式的值。比如 normalization 用来区分是训练还是推理。
各类型关系如下:

3.2.1 布尔表达式的析构函数
BaseExpr 是上述这些 bool 表达式对象的基类。其析构函数不是 virtual 的。SetIsMatchedHob 的代码如下。调用时 T 的具体类型是确定的,make_shared 知道如何合理释放,所以这个场景不会造成内存泄漏。
template
OpKernelRegistry& SetIsMatchedHob(const T& hob) {
result_.is_matched_hob = std::make_shared(hob);
return *this;
} 参考资料
OneFlow v0.9.0
其他人都在看
Transformer模型的基础演算
向量嵌入:AutoGPT的幻觉解法
John Schulman:通往TruthGPT之路
复杂推理:大型语言模型的"北极星"能力
为什么ChatGPT用强化学习而非监督学习
OneEmbedding:单卡训练TB级推荐模型不是梦
GLM训练加速:性能最高提升3倍,显存节省1/3
试用OneFlow: github.com/Oneflow-Inc/oneflow/
