MySQL 查询执行流程
MySQL 架构与SQL查询语句执行流程
一:一条查询语句的执行流程
**注意, mysql8.0没有查询缓存了
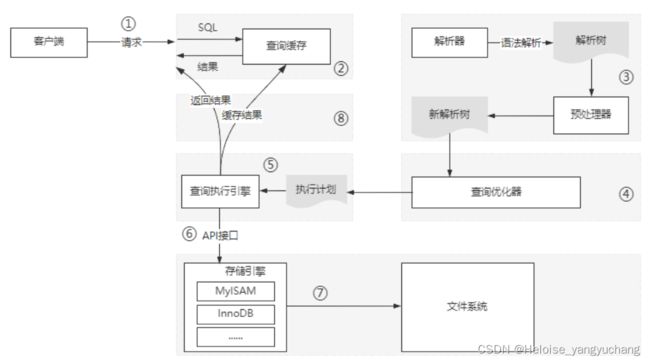
1.1、连接
跟数据库建立连接,MySQL服务监听的端口默认是3306,客户端连接服务端的方式有很多。可以是同步的也可以是异步的,可以是长连接也可以是短连接,可以是TCP也可以
查看MySQL当前有多少个连接
show global status like 'Thread%';
- Threads cached 缓存中的线程连接数。.
- Threads connected 当前打开的连接数。
- Threads created 为处理连接创建的线程数。
- Threads running 非睡眠状态的连接数,通常指并发连接数:
客户端每产生一个连接或者一个会话,在服务端就会创建一个线程来处理。反过来, 如果要杀死会话,就是Kill线程
既然是分配线程的话,保持连接肯定会消耗服务端的资源。MySQL会把那些长时间 不活动的(SLEEP)连接自动断开
show global variables like 'wait timeout';—非交互式超时时间,如 JDBC 程序
show global variables like 'interactive timeout';"交互式超时时间,如数据库工具
这两个参数默认都是28800秒,8小时。
既然连接消耗资源,MySQL服务允许的最大连接数(也就是并发数)在5.7版本中默认是151个,最大可以设置成100000
可以通过:show variables like 'max connections';
参数级别说明
MySQL中的参数(变量)分为session和global级别,分别是在当前会话中生效和 全局生效。但是并不是每个参数都有两个级别,比如max_connections就只有全局级别。
当没有带参数的时候,默认是session级别,包括查询和修改,比如修改了一个参数以后,在本窗口査询已经生效,但是其他窗口不生效
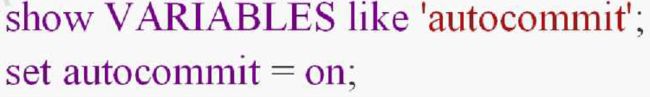
所以,如果只是临时修改,建议修改session级别。 如果需要在其他会话中生效,必须显式地加上global参数。
1.2、查询缓存
MySQL内部自带了一个缓存模块, MySQL的缓存默认是关闭的。
show variables like 'query_cache%';
默认关闭的意思就是不推荐使用,为什么MySQL不推荐使用它自带的缓存呢? 主要是因为MySQL自带的缓存的应用场景有限:
- 第一个是它要求SQL语句必须一 模一样,中间多一个空格,字母大小写不同都被认为是不同的的SQL。
- 第二个是表里面任何一条数据发生变化的时候,这张表所有缓存都会失效,所以对 于有大量数据更新的应用,也不适合。
所以缓存这一块,我们还是交给0RM框架(比如MyBatis默认开启了一级缓存), 或者独立的缓存服务,比如Redis来处理更合适。MySQL 8.0中,查询缓存已经被移除了。
1.3 、解析器和预处理器
为什么一条SQL语句能够被识别呢?假如随便执行一个字符串hello 服务器报错。
这个就是MySQL的Parser解析器和Preprocessor预处理模块。
这一步主要做的事情是对语句基于SQL语法进行词法和语法分析和语义的解析。
1.3.1.词法解析
第一步词法分析就是把一个完整的SQL语句打碎成一个个的单词。
比如一个简单的SQL语句:
select name from user where id = 1
它会打碎成8个符号,每个符号是什么类型,从哪里开始到哪里结束。
1.3.1.语法解析
第二步就是语法分析,语法分析会对SQL做一些语法检查,比如单引号有没有闭合, 然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构。这个数据结构我 们把它叫做解析树(select lex)。
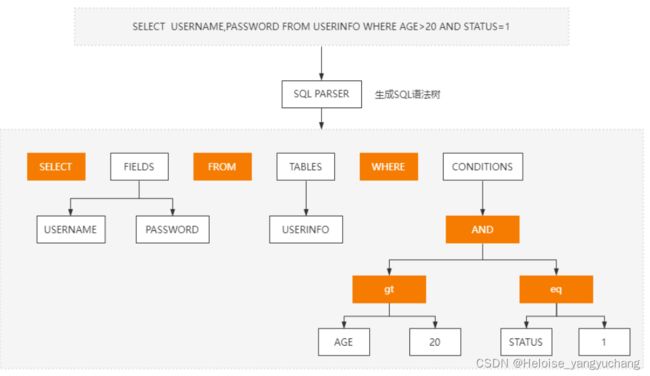
如果写了一个语法完全正确的树,但是表或者字段不存在,还是在解析的时候报错,因为解析器处理之后,还有一个预处理器,它用来判断解析树的语义是否正确,也就是表名和字段名是否存在,预处理后生成一个新的解析树。
select * from hello;//表不存在
实际上还是在解析的时候报错,解析SQL的环节里面有个预处理器。
它会检査生成的解析树,解决解析器无法解析的语义。比如,它会检査表和列名是否存在,检査名字和别名,保证没有歧乂。预处理之后得到一个新的解析树
1. 4、查询优化(Query Optimizer)与查询执行计划
得到解析树之后,是不是执行SQL语句了呢?这里还有一个问题,一条SQL语句是不是只有一种执行方式?或者说数据库最终 执行的SQL是不是就是我们发送的SQL?
这个答案是否定的。一条SQL语句是可以有很多种执行方式的,最终返回相同的结果,他们是等价的。但是如果有这么多种执行方式,这些执行方式怎么得到的?最终选 择哪一种去执行?根据什么判断标准去选择?
这个就是MySQL的査询优化器的模块(Optimizer)。
査询优化器的目的就是根据解析树生成不同的执行计划(Execution Plan),然后选 择一种最优的执行计划,MySQL里面使用的是基于开销(cost)的优化器,最终采用开销最小的作为最终执行的方案。
优化器最终会把解析树变成一个查询执行计划,查询执行计划一个数据结构。这个执行计划不一定是最优的结果,因为 mysql 也有可能覆盖不到所有的执行计划。
优化器包括两项工作分别是逻辑优化、物理优化,运行流程如下。
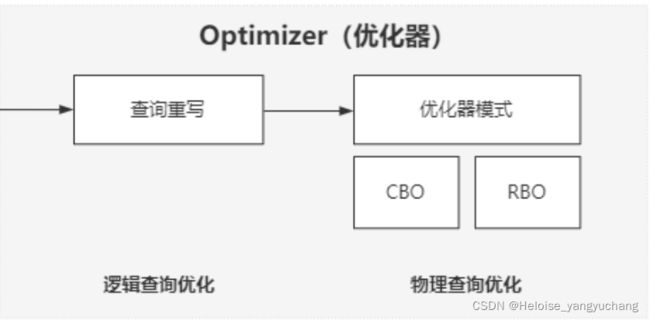
1. 4.1、逻辑优化
这个阶段主要是使用关系代数对SQL语句做一些等价,使得SQL执行效率最高。
对条件表达式进行等价谓词重写、条件简化,对视图进行重写,对子查询进行优化,对连接语义进行了外连接消除、嵌套连接消除等
案例:
-
子查询优化:子查询是SQL语句中出现频率很高的类型,而且也是较为耗时的操作。而子查询可能会出现在SQL中的目标列、from子句、where子句、JOIN/ON子句、GROUPBY子句、Having子句等
子查询合并:在某些条件下,多个子查询能合并成一个子查询,这样就可以把多次表扫
描,多次连接操作减少为单次表扫描和单次连接。
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=1)
OR EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND t2.b2=2) );
优化成:
SELECT * FROM t1 WHERE a1<10 AND ( EXISTS(SELECT a2 FROM t2 WHERE t2.a2<5 AND
(t2.b2=1 OR t2.b2=2) );
- 等价谓词重写:数据库执行引擎中,对一些谓词的处理效率要高于其他谓词,因此,把一些
逻辑表达式重写成等价的并且更高效的形式,能够提升查询效率
- like 规则
SELECT * FROM USERINFO WHERE name LIKE 'Abc%'
优化成:
SELECT * FROM USERINFO WHERE name >='Abc' AND name <'Abd'
前者针对LIKE这个谓词只能进行全表扫描,而在后者改造中如果name列有索引,转化后就变成索引范围内扫描
- IN转化OR规则:IN 转化 OR规则就是IN为此的OR等价重写,即改写IN谓词为等价的OR 谓词,从而更好的利用索引进行优化
select * from t1 where age in (10,14,18)
优化成:
select * from t1 where age =10 or age=14 or age=18
IN转化OR规则后,执行效率是否能够提高,需要看数据库中对IN谓词是否只支持全表扫描,如果数据库对IN谓词
只支持全表扫描并且OR谓词中的表的age列上存在索引,那么转化后查询效率会得到提高
- 条件简化:WHERE、HAVING、ON条件可能是由很多的表达式组成的,而这些表达式在某些情况下存在一定的联系, 数据库可以利用等式和不等式的性质,把WHERE、HAVING、ON条件简化
- 把HAVING条件并入到WHERE条件, 方便统一、集中化解子条件,节约多次化解的时间
- 去除表达式中的冗余括号,减少语法分析时产生的AND和OR 树的层次,比如((a AND b) AND (c AND d))简化为a AND b AND c AND d
- 常量传递,比如col_1=col_2 AND col_2=3 可以简化成col_1=3 ANDcol_2=3
- 表达式计算, 对可以求解的表达式进行计算,比如WHERE col_1=1+2 转化为 WHERE col_1=3
1. 4.2、物理优化
在生成逻辑查询计划后,查询优化器会进一步对查询树进行物理查询优化,
物理优化主要解决几个问题:
- 在单表扫描方式中,选择什么样的单表扫描方式是最优的
- 对于存在两个表连接时,那种连接方式最优
- 对于多个表连接,连接顺序有多种组合,那种连接顺序是最优的
物理查询优化一般分为两种:
- 基于规则的优化(RBO,Rule-Based Optimizer),这种方式主要是基于一些预置的规则对查询进行优化。
- 基于代价的优化(CBO,Cost-Based Optimizer),这种方式会根据模型计算出各个可能的执行计划的代价,然后选择代价最少的那个。它会利用数据库里面的统计信息来做判断,因此是动态的
- 基于代价估算是基于CPU代价和IO代价这两个纬度来实现的。
单表扫描代价
单表扫描代价,单表扫描需要从表上获取元组,直接关联到物理IO的读取,因此不同的单表扫描方式,会有不同的代价,通常有两种:
- 全表扫描表数据,获取全部的元组,读取表对应的全部数据页
- 局部扫描表数据,获取表的部分元组,读取指定位置对应的数据页
而单表扫描涉及到的算法有很多,比如
- 顺序扫描,从物理存储上按照存储顺序直接读取表的数据
- 索引扫描,根据索引键获取索引找到物理元组的位置,再根据该位置从
存储中读取数据页面 - 并行表扫描, 对同一个表,并行地通过索引的方式获取表的数据,然后 将结果合并在一起
对于局部扫描,通常会采用索引实现少量数据的读取优化,这是一种随机读取数据的方式。虽然顺序扫描可能比读取许多行的索引扫描花费的时间少,但是如果顺序扫描被执行多次(比如嵌套循环连接的表)它的整体代价更大,而索引扫描访问的数据页比较少,而且这些也可能会被保存在数据缓冲区中,所以访问速度会更快。
至于最终采用哪种扫描方式,查询优化器会采用代价估算比较代价大小后再决定。
总的来说,对于单表扫描的代价,由于单表扫描需要把数据从存储系统中加载到内存,所以单表扫描的代价需要考虑IO的开销。

1. 4.3、查询优化器整体结构
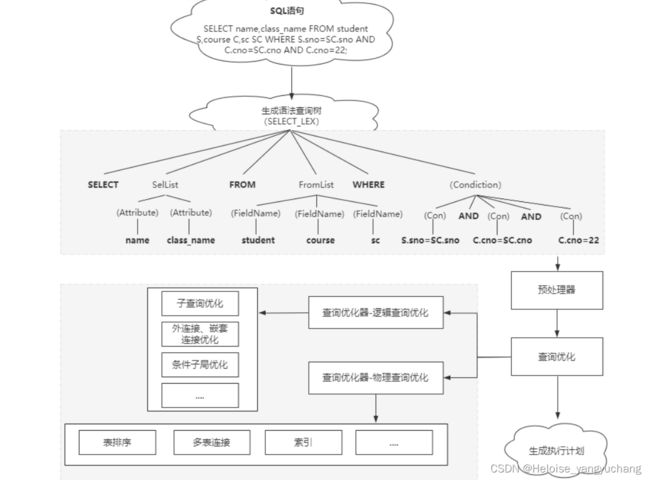
1. 5、执行计划:
当一条SQL语句经过Optimizer优化器优化之后,会针对这条SQL产生一个执行计划,从这个执行计划中可以得知Mysql会如何执行这条SQL。
在Mysql中,提供了EXPLAIN关键字来查看指定SQL的执行计划,通过该计划,可以得到以下信息。
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查
1. 6、Storage Engines
一条SQL语句经过解析和优化之后,最终还是需要从某一个地方获取数据,
那么:
- 从逻辑的角度来说,我们的数据是放在哪里的,或者说放在一个什么结 构里面?
- 执行计划在哪里执行?是谁去执行?
这里就涉及到存储引擎(Storage Engines)的概念了
存储引擎是Mysql中才有的概念,它表示数据如何存储、如何提取、如何更新等具体的实现,不同存储引擎的底层实现方式不同,因此 不同的存储引擎提供的特性都 不一样,它们有不同的存储机制、索引方式、锁定水平等功能。
我们在不同的业务场景中对数据操作的要求不同,就可以选择不同的存储引擎来满 足我们的需求
1. 6.1、InnoDB(2个文件)
mysql 5.7中的默认存储引擎。InnoDB是一个事务安全(与ACID兼容)的MySQL 存储引擎,它具有提交、回滚和崩溃恢复功能来保护用户数据。InnoDB行级锁(不升级 为更粗粒度的锁) ,适合经常更新的表,存在并发读写或者有事务处理的业务系统。只有在需要它不支持的特性时,才考虑使用其它存储引擎。
实现了四个标准的隔离级别,默认级别是可重复读(REPEATABLE READ)。在可重复读隔离级别下,通过多版本并发控制(MVCC)+ 间隙锁(Next-Key Locking)防止幻读。
主索引是聚簇索引,在索引中保存了数据,从而避免直接读取磁盘,以减少基于主键的常见查询的I/O,因此对查询性能有很大的提升。 为了保持数据完整性, InnoDB还支持外键引用完整性约束。
内部做了很多优化,包括从磁盘读取数据时采用的可预测性读、能够加快读操作并且自动创建的自适应哈希索引、能够加速插入操作的插入缓冲区等。
支持真正的在线热备份。其它存储引擎不支持在线热备份,要获取一致性视图需要停止对所有表的写入,而在读写混合场景中,停止写入可能也意味着停止读取
1. 6.2、MylSAM (3个文件)
应用范围比较小。表级锁定限制了读/写的性能,因此在Web和数据仓库配置中,
它通常用于只读或以读为主的数据分析项目 或者表比较小、可以容忍修复操作,则依然可以使用它。
特点:
- 支持表级别的锁(插入和更新会锁表)。不支持事务。读取时会对需要读到的所有表加共享锁,写入时则对表加排它锁。但在表有读取操作的同时,也可以往表中插入新的记录,这被称为并发插入(CONCURRENTINSERT)
- 提供了大量的特性,包括压缩表、空间数据索引等。
- 如果指定了 DELAY_KEY_WRITE选项,在每次修改执行完成时,不会立即将修改的索引数据写入磁盘,而是会写到内存中的键缓冲区,只有在清理键缓冲区或者关闭表的时候才会将对应的索引块写入磁盘。这种方式可以极大的提升写入性能,但是在数据库或者主机崩溃时会造成索引损坏,需要执行修复操作。
- 拥有较高的插入(insert)和查询(select)速度。存储了表的行数(count速度更快)。
怎么快速向数据库插入100万条数据?
我们有一种先用MylSAM插入数据,然后修改存储引擎为InnoDB的操作。
1. 6.3、Memory (1个文件)
将所有数据存储在RAM中,以便在需要快速查找非关键数据的环境中快速访问。这 个引擎以前被称为堆引擎。其使用案例正在减少;InnoDB及其缓冲池内存区域提供了一 种通用、持久的方法来将大部分或所有数据保存在内存中,而ndb custer为大型分布式数据集群提供了快速的键值查找。
特点:将表中的数据存储到内存中,读写的速度很快,但是数据库重启或者崩溃,数据会全部消失。只适合做临时表。
1. 6.4、CSV (3个文件)
它的表实际上是带有逗号分隔值的文本文件。csv表允许以CSV格式导入或转储数据, 以便与读写相同格式的脚本和应用程序交换数据。因为CSV表没有索引,所以通常在正 常操作期间将数据保存在innodb表中,并且只在导入或导出阶段使用csv表。
特点:不允许空行,不支持索引。格式通用,可以直接编辑,适合在不同数据库之 间导入导出
1. 6.5、Archive (2 个文件)
这些紧凑的未索引的表用于存储和检索大量很少引用的历史、存档或安全审计信息
特点:不支持索引,不支持update delete
1. 6.6、如何选择存储引擎?
- 如果对数据一致性要求比较高,并发大更新多,需要事务支持,可以选择InnoDB。
- 如果数据查询多更新少,对查询性能要求比较高,可以选择My ISAM。
- 如果需要一个用于查询的临时表,可以选择Memory。
MyISAM 和InnoDB 区别
- 事务: InnoDB 是事务型的,可以使用 Commit 和 Rollback 语句;MyISAM 不支持事务
- 并发: MyISAM 只支持表级锁,而 InnoDB 还支持行级锁以及外键约束,可以支持并发写。
- 聚集索引:MyISAM 非聚集索引,辅助索引和主索引基本一致;InnoDB 聚集索引,辅助索引存储主键值
- 备份: InnoDB 支持在线热备份。
- 崩溃恢复: MyISAM 崩溃后发生损坏的概率比 InnoDB 高很多,而且恢复的速度也更慢。
- 外键: InnoDB 支持外键。
- 其它特性: MyISAM 支持压缩表和空间数据索引。
1.7.执行引擎(Query Execution Engine)
OK,存储引擎分析完了,它是我们存储数据的形式,第二个问题,是谁使用执 行计划去操作存储引擎呢?
这就是我们的执行引擎,它利用存储引擎提供的相应的API来完成操作。为什么我们修改了表的存储引擎,操作方式不需要做任何改变,因为不同功能的存储引擎实现的API是相同的。最后把数据返回给客户端。