yo!这里是Linux基础开发工具介绍
目录
前言
基础开发工具
yum
vim
1.基本介绍
2.基本操作
3.正常模式常用命令
4.底行模式常用命令
gcc/g++
gdb
1.基本介绍
2.常用操作
make/Makefile
1.背景
2.介绍
3.使用
git
1.介绍
2.操作
进度条程序简单实现
后记
前言
在学完初步的基础指令及权限控制之后,在Linux环境下写一个c/c++程序才是重中之重,这里就要介绍到Linux的基础开发工具了,包括软件包管理器yum、编辑器vim、编译器gcc/g++、调试器gdb等等,在Linux前期的学习过程中,这些开发工具的使用还是比较频繁的,或者是面试官们会问到地方,虽然用起来很不方便,所以后面进一步的实际开发中会被平替掉,但还是要了解一下,知识点简单粗暴,并不复杂,在文章的最后,也会通过一个列子将这些开发工具综合练习一下。
基础开发工具
-
yum
Yum(Yellowdog Updater, Modified)是一个开源包管理系统,可以自动在您的系统中下载和安装软件包,并管理依赖关系。与其他包管理系统相比,Yum的优势在于它可以自动处理依赖关系的安装。这意味着它可以自动下载并安装所需的库和其他软件包,以满足您需要安装的软件包的所有依赖关系。Yum还可以自动升级已安装的软件包,以确保您的系统始终是最新的。
①yum list installed :列出已安装的软件包
②yum list | grep "关键字":列出存在"关键字"的软件包
③yum install package :安装软件包
④yum update package :更新软件包
⑤yum remove package :卸载软件包
eg:

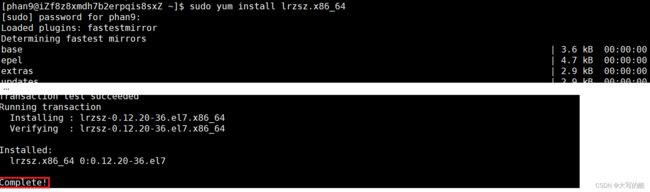
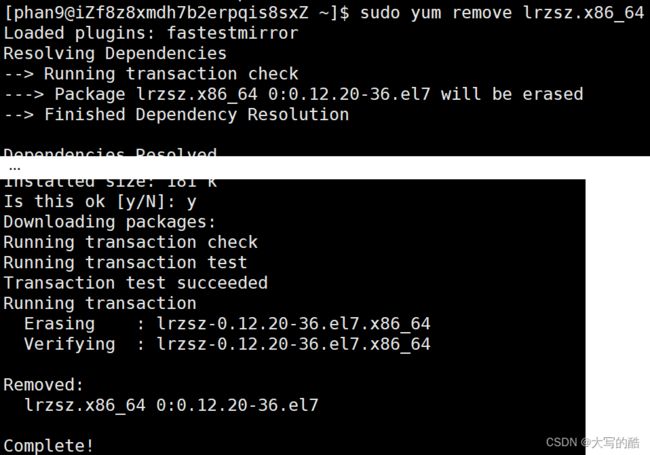
注意:从上述例子可以看出,安装软件和删除软件需要向系统目录中写入内容,所以需要root身份或者sudo指令 。
-
vim
1.基本介绍
Vim是一款基于Vi编辑器的文本编辑器,是Linux和Unix系统上最受欢迎的文本编辑器之一。它具有强大的功能和丰富的插件生态系统,也非常适合程序员和系统管理员使用。
Vim具有很多特点,其中最重要的是其模式。Vim有三种模式:命令模式(也叫正常/普通模式)、插入模式和底行(末行)模式。在命令模式下,用户可以执行各种命令,如控制光标的移动来跳转文本,删除文本,查找和替换,在插入模式下,用户可以像在常规文本编辑器中一样输入文本。在底行模式下,用户可以保存、退出文件,也可以查找关键字、列出行号等操作。
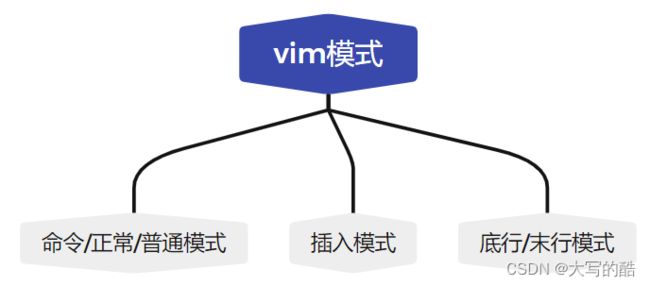
2.基本操作
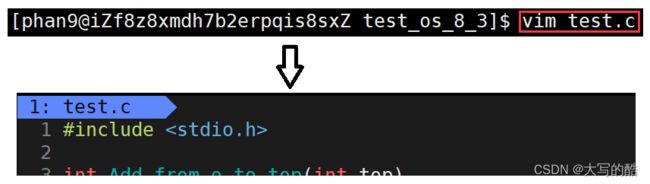
1)进入vim:vim 文件名
注意:一开始进入vim默认是命令模式
eg:
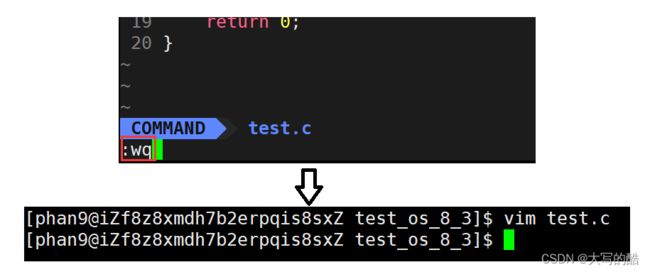
2)退出vim:底行模式下输入
【:w】保存当前文件
【:wq】保存并退出文件
【:q!】不保存强制退出
eg:
3)模式切换
a:append 在光标后面追加内容;
i:insert 在光标前面插入内容;
o:other 另起一行输入。
3.正常模式常用命令
1)移动光标
vim可以直接用键盘上的光标来上下左右移动,但正规的vim是用小写英文字母「h」、「j」、「k」、 「l」,分别控制光标左、下、上、右移一格,
「 $ 」:移动到光标所在行的“行尾”
「^」:移动到光标所在行的“行首”
「w」:光标跳到下个字的开头,即以单词为单位右移
「e」:光标跳到下个字的字尾
「b」:光标回到上个字的开头,即以单词为单位左移
「#l」:光标移到该行的第#个位置,如:5l,56l
[gg]:进入到文本开始
[G]:进入文本末端,eg:50G是移动到第50行
「ctrl」+「b」:屏幕往“后”移动一页
「ctrl」+「f」:屏幕往“前”移动一页
「ctrl」+「u」:屏幕往“后”移动半页
「ctrl」+「d」:屏幕往“前”移动半页
注意:加粗部分为本人认为常用的命令,下同
2)删除文字
「x」:每按一次,删除光标所在位置的一个字符
「#x」:例如,「6x」表示删除光标所在位置的“后面(包含自己在内)”6个字符
「X」:大写的X,每按一次,删除光标所在位置的“前面”一个字符
「#X」:例如,「20X」表示删除光标所在位置的“前面”20个字符
「dd」:删除光标所在行,相当于剪切,可粘贴
「#dd」:从光标所在行开始删除#行
3)复制
「yw」:将光标所在之处到字尾的字符复制到缓冲区中。
「#yw」:复制#个字到缓冲区
「yy」:复制光标所在行到缓冲区。
「#yy」:例如,「6yy」表示拷贝从光标所在的该行“往下数”6行文字。
「p」:将缓冲区内的字符贴到光标所在位置,相当于粘贴
注意:所有与“y”有关的复制命令都必须与“p”配合才能完成复制与粘贴功能。
4)替换
「r」:替换光标所在处的字符
「R」:替换光标所到之处的字符,直到按下「ESC」键为止。
「~」:大小写切换
5)撤销
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。按多次“u”可以执行多次回 复。
「ctrl + r」: 撤销的恢复
6)更改
「cw」:更改光标所在处的字到字尾处
「c#w」:例如,「c3w」表示更改3个字
7)跳至指定行
「ctrl」+「g」列出光标所在行的行号。
「#G」:例如,「15G」,表示移动光标至文章的第15行行首。
4.底行模式常用命令
「set nu」: 输入「set nu」后,会在文件中的每一行前面列出行号。
「set nonu」:取消行号
「/关键字」: 先按「/」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直按 「n」会往后寻找到您要的关键字为止。
「?关键字」:先按「?」键,再输入您想寻找的字符,如果第一次找的关键字不是您想要的,可以一直 按「n」会往前寻找到您要的关键字为止。
注意:两者区别在于“/”是从上向下找,“?”是从下向上找。
「vs 文件名」:分屏,使用「ctrl+w+w」切屏
「wq」:退出分屏
「!指令」:不退出vim情况下执行指令
-
gcc/g++
gcc/g++是GNU编译器集合的一部分,gcc针对与C语言,g++针对于c++语言,编译器集合提供了一个完整的工具套件,可以将源代码转换为机器语言,让程序可以在计算机上运行。它包含了一些工具,例如预处理器、编译器、汇编器、链接器等,可以根据需要将这些工具组合使用,进行一系列的编译操作,得到可执行文件或共享库等目标文件。(后仅讲解gcc,g++情况一致)
格式:gcc [选项] 要编译的文件 [选项] [目标文件] 或
gcc [选项] [目标文件] [选项] 要编译的文件
gcc可一步将.c文件直接生成可执行文件,见下方列子,也可以使用相关选项在四个步骤中停止,生成对应文件。
eg:
gcc hello.c -o hello
//或者
gcc -o hello hello.c1)预处理
功能:宏替换、文件包含展开、条件编译、去注释等
选项:
“-E”:该选项的作用是让 gcc 在预处理结束后停止编译过程。
“-o”:是指目标文件,
注意:
“.i”文件为已经过预处理的C原始程序。
eg:
gcc –E hello.c –o hello.i2)编译
功能:首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
选项:
“-S”:只进行编译而不进行汇编,在编译完停止,生成汇编。
eg:
gcc –S hello.i –o hello.s3)汇编
功能:把编译阶段生成的“.s”文件转成目标文件
选项:
“-c”:汇编完停止,生成“.o”的二进制目标代码
eg:
gcc –c hello.s –o hello.o4)链接
功能:生成可执行文件
eg:
gcc hello.o –o hello-
gdb
1.基本介绍
gdb是调试器,用于C、C++、其他一些编程语言的调试工具。它是一个功能强大的调试工具,可以帮助程序员分析和调试程序,以便更快地发现和解决软件缺陷。gdb可以与多种编程语言和操作系统配合使用,并提供广泛的调试功能。
2.常用操作
在Linux环境下gcc/g++出来的二进制程序默认是release模式,是发布模式,故无法调试,如图一,只有debug模式下才可以调试,所以要在gcc命令下加上-g选项,如图二。
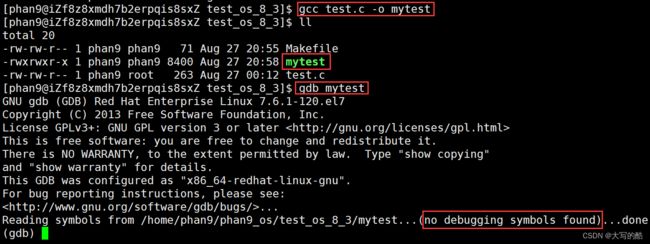
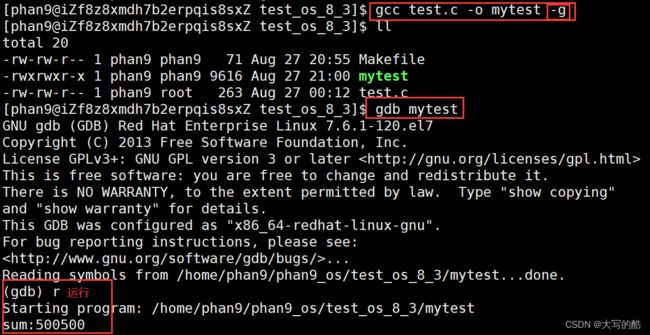
1)进入gdb:gdb 文件名
2)退出:ctrl+d 或 quit
3)调试命令(括号内为简写)
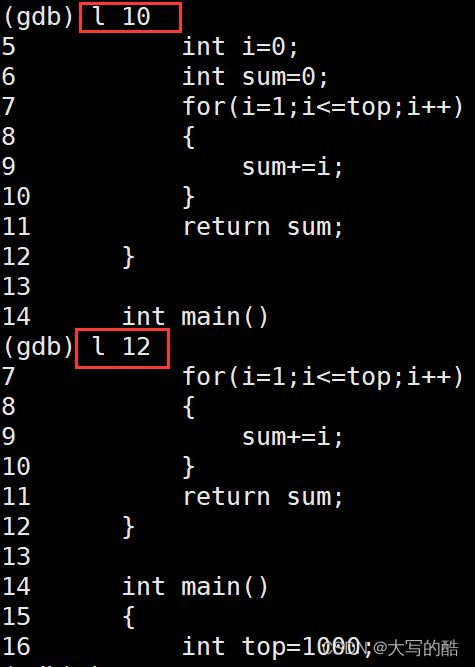
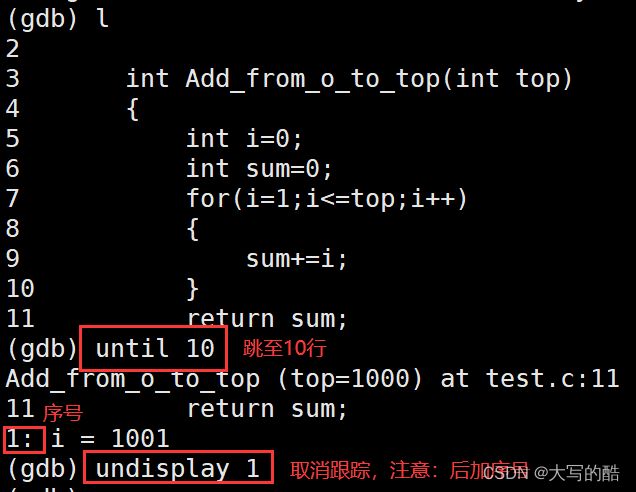
list(l) 行号:显示binFile源代码,接着上次的位置往下列,每次列10行。
注:l 0:从头显示
list(l) 函数名:列出某个函数的源代码。
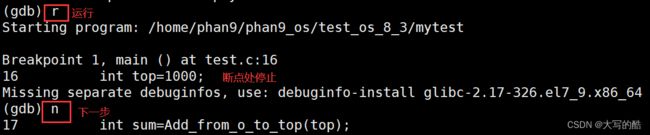
run(r):运行程序。
注:若有断点,就断点处停止
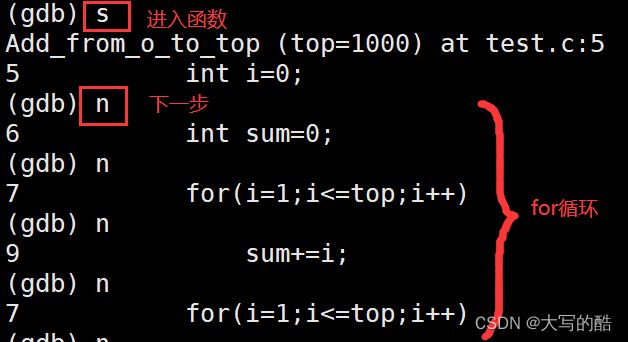
next(n):单条执行。
step(s):进入函数调用
break(b) 行号:在某一行设置断点
break 函数名:在某个函数开头设置断点
info break :查看断点信息。
finish:执行到当前函数返回,然后挺下来等待命令
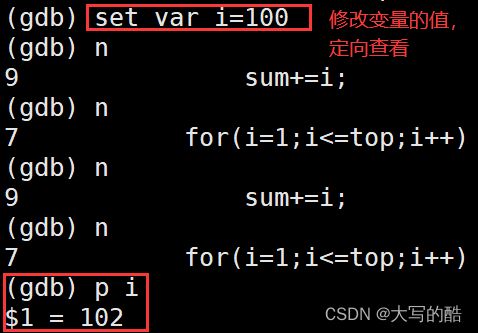
print(p):打印表达式的值,通过表达式可以修改变量的值或者调用函数
p 变量:打印变量值。
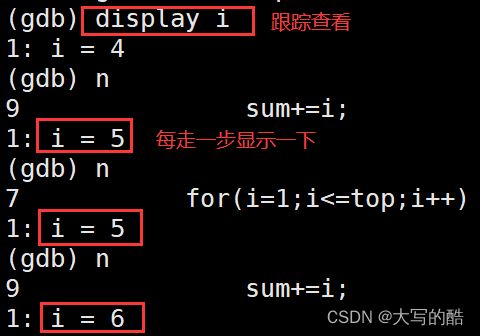
set var:修改变量的值
注:在跟踪查看某变量时,可修改变量值定向查看
continue(c):从当前位置开始连续而非单步执行程序
注:跳至下一个断点处,若后无断电则跳至结束
delete breakpoints:删除所有断点
delete breakpoints n:删除序号为n的断点
disable breakpoints n:禁用序号为n的断点
enable breakpoints n:启用序号为n的断点
info(i) breakpoints:参看当前设置了哪些断点
display 变量名:跟踪查看一个变量,每次停下来都显示它的值
undisplay n:取消对先前设置的序号为n的变量的跟踪
until X行号:跳至X行
breaktrace(或bt):查看各级函数调用及参数
info(i) locals:查看当前栈帧局部变量的值
eg:

-
make/Makefile
1.背景
Makefile是项目自动化构建工具,从侧面说明了一个人是否具备完成大型工程的能力,Makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂的功能操作,一旦写好,只需要一个make命令,整个工程完全自动编译,极大的提高了软件开发的效率。
make是一个命令工具,是一个解释Makefile中指令的命令工具,make是一条命令,Makefile是一个文件,两个搭配使用,完成项目自动化构建。
Makefile还可以帮助进行增量编译和自动化测试。如果一个文件已经被编译过了,而且没有被修改,那么Makefile就可以跳过这个文件的编译过程,从而节省大量的时间,它的灵活性和可扩展性使得它成为了软件开发过程中不可或缺的一部分。
2.介绍
太多的概念比不过一个例子更好理解,下面用一个例子来说明使用方法,比如:
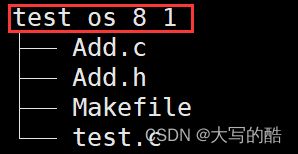
有某工程test_os_8_1,如图:
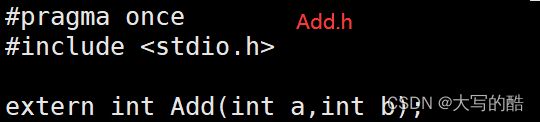
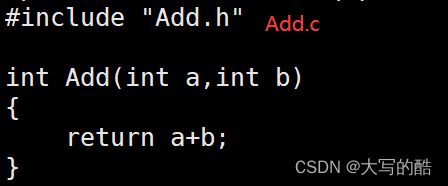
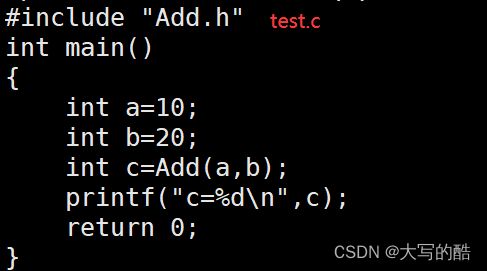
里面是我们写的c文件test.c、头文件Add.h以及Add.c文件,如下图:
针对于Makefile文件,如图:
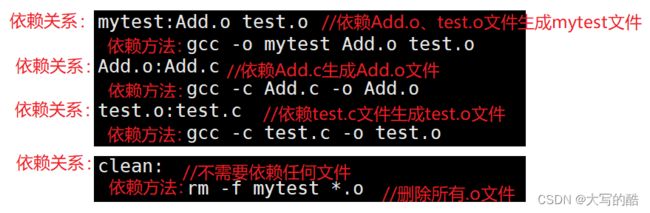
依赖关系:
指的是两个或多个事物之间的互相依存或相互影响的关系。在计算机科学中,依赖关系通常用于描述程序中各个模块之间的相互依赖。一个模块可能依赖于其他模块或库文件中的函数或类,这些依赖关系可以用来确定编译或执行程序的顺序,以确保程序能够正确地工作。
依赖方法:
指一个方法依赖于另一个方法的结果。在编程中,我们经常会使用依赖方法的思想来构建复杂的程序逻辑。
.PHONY:
是一种关键字,表明clean是伪目标,意思是总是被执行的,因为没有被第一个目标文件直接或间接关联,所以它后面所定义的命令将不会被自动执行,不过,我们可以使用指令“make clean”显式执行,以此来清除所有的目标文件,以便重编译。 一般像这种clean的目标文件,我们.PHONY 修饰,表示总是被执行。
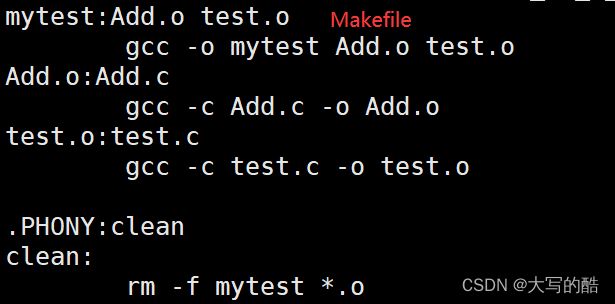
3.使用
1)make指令
原理:
①首先找到文件中的第一个目标文件,如mytest文件,并把这个文件作为最终的目标文件,就会执行后面所定义的命令来生成mytest这个文件。
②如果mytest所依赖的test.o文件、Add.o文件在当前目录中不存在,那么make会在当前文件中找目标为test.o文件的依赖关系,根据依赖方法生成test.o文件和Add.o文件。
③以此类推,一层又一层地去找文件的依赖关系,直到最终编译出第一个目标文件。
注意:
在找寻的过程中,如果出现错误,比如最后被依赖的文件找不到,那么make就会直接退出,并报错, 而对于所定义的命令的错误,或是编译不成功,make根本不管,只管文件的依赖性,即如果在make找了依赖关系之后,冒号后面的文件还是不在,那么直接退出。
2)make clean (清理工作)



-
git
1.介绍
Git是一个为了管理Linux内核开发而创建的分布式版本控制系统。它可以帮助开发者在不同的开发环境中协同工作,协助版本控制、代码合并等功能,支持非线性开发、分支处理等强大特性。
Git的主要优点:
1. 分布式版本控制系统,仓库拷贝自由。
2. 速度快,耗费资源少。
3. 全局版本号,标记版本历史。
4. 强大的分支管理,支持多分支开发。
5. 数据一致性高,内容的完整性和可追溯性强。
2.操作
目前,在学习开发的过程中,不太需要将git所有功能全部了解,只需要学会将自己的代码练习git到第三方平台上(如gitee、github),将平时的学习过程记录在上面即可,步骤如下。
准备一:Linux下安装git软件包
yum install git准备二:克隆远程仓库链接
git clone 链接注意:本平台上的gitee或github托管代码教学很多很详细,搜一下,下面针对Linux环境下如何提交代码。
1)git add [文件名]
eg:
2)git commit -m "提交日志"
eg:
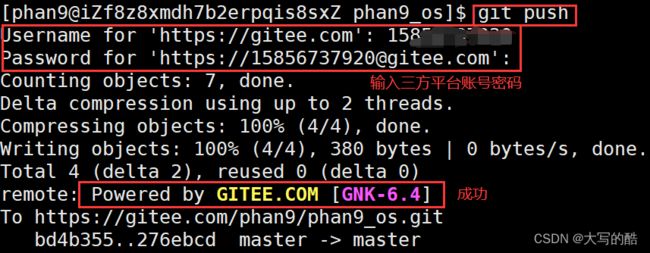
3)git push
eg:

补充:
①git log:查看提交记录
②git pull:同步仓库,在提交过程中出现报错,无脑git pull
③.gitignore文件:相当于黑名单,里面记录的文件后缀的文件在上传过程中会被忽略。
④git rm 文件 + 上面的三部曲:删除远程仓库的文件
进度条程序简单实现
在Linux环境下实现一个简单进度条程序,先写好Makefile文件,再使用vim编辑器打开c文件进行编写程序,然后使用gcc编译器、gdb调试器调试编译,程序运行正确之后将此工程git到自己的第三方平台上,使用基本的开发工具开发出一个小型工程,这就是过程。
代码:
int main()
{
int i=0;
char arr[NUM];
memset(arr,0,sizeof(arr));
while(i运行:
后记
以上就是Linux前期学习过程中所使用到的开发工具介绍,本身很好理解,但是细节很多,特别是编辑器vim、调试器gdb,需要记住的指令很多,但本文没有面面俱到,只列举了大部分常用的部分,先熟悉这些,其他的慢慢拓展,加油,拜拜!