k8s等运维(三)
万字长文,带你搞懂 Kubernetes 网络模型
1、K8s执行定时任务
1) 服务docker话—找到基础镜像—在里面搞定服务运行环境—Dockerfile 构建镜像
docker pull xxx
docker tag xxx
docker push 到Harbor #写dockerfile时要用到这个,因为快速
docker 制作好后,也要docker push上去
2) 并入k8s–确定服务发现的策略—编写k8s配置文件
定时任务关键字段
spec:
schedule: "*/1 * * * *" #一分钟后开始调度
kubectl apply -f xxx.yaml
Pod
容器是单进程模型,只能运行一个服务
1、pod是共享网络,共享volume,
1)关于network
kind: Pod
里面定义了两个容器
#创建pod
kubectl create -f pod-network.yaml
pod中的网络相通,进入其中一个容器,可以通过localhost相互通信,可以看到pod其他服务的端口
容器中的ip和网络设备都是一模一样的
2)关于volume
yaml里的volumes: 所有容器共用
实例:共用volume的容器,一般一个是主力,一个是辅助,日志采集和业务容器可以共享目录,业务容器负责写,
日志采集后发给Kafka等保存起来
kubectl create -f pod-volume.yaml
pod里的哪个容器都能访问修改共享目录
3)host文件
容器的host文件和主机的不同,是pod自己管理的,
所以不能在pod里的容器修改host
在yaml里设置
spec:
hostAliases:
- ip: "10.155.20.120"
hostnames:
- "web.mooc.com"
kubectl delete -f pod-volume.yaml
kubectl create -f pod-volume.yaml
docker ps|grep volume
docker exec -it 容器id cat /etc/hosts
- namespace
spec表示pod级别
spec:
hostNetwork: true #是不是使用宿主机的网络
hostPID: true #是不是使用宿主机的pid namespace
进入容器,ps -ef,发现使用了宿主机的进程空间
netstat -ntlp 使用了宿主机的network namespace
5)上面四个都是pod级别的,下面是容器级别的
生命周期的管理
containers:
lifecycle:
postStart: #容器启动之后可以执行一个命令,它跟entrypoint是并行的,
#所以不要将容器启动之后才能运行的放在这
exec:
command: ["/bin/sh","-c","echo web starting ... >> /var/log/messages"]
preStop: #停止之前要做的事,它是串行的,在容器停止之前,会执行下面的,
#执行完才给容器发送停止信号,它也不会一直等待,如果超时,会自动跳过
exec:
command: ["/bin/sh","-c","echo web stopping ... >> /var/log/messages && sleep 3"]
6) Pod的 lifecycle
Pendding
#找到合适的调度机器后
containerCreating
Running
Succeeded # 成功退出
Failed # 失败退出
Ready # 通过健康检查
CrashLoopBackOff # 没通过
Unknown # pod与apiServer通信有问题
7)ProjectedVolume 投射数据卷
由apiServer投射到volume里面的
aipServer知道pod启动的时候需要什么文件,在启动的时候就给你扔过来了
Secret: 用于跟service交互的,用于授权的
kubectl get secret
kubectl get secret 上面命令查出来的name -o yaml
# k8s会自动地将service account加入到每一个pod里面
get pods 后,-o yaml
volumes: 下定义token,使用的正是service secret account
#挂载到
volumeMounts:
- mountPath:
自己创建secret
vi secret.yaml
metadata:
name: dbpass # 数据库的密码
data:
username: base64后的
passwd: base64后的
#生成base64的命令
echo -n username|base64
# 创建secret
kubectl create -f secret.yaml
# 创建完要拿给pod来用
vi pod-secret.yaml
volumes:
- name: db-secret
-secret:
name:dbpass
containers:
volumeMounts:
-name:db-secret # 这里容器就用到了
#创建pod
kubectl create -f pod-secret.yaml
ConfigMap 用来存储不加密的数据,比如一些系统参数的配置啊
现有一个配置文件game.properties 里面含有大量的key val,想把它放进k8s,这时就用ConfigMap
kubectl create configmap web-game --from-file game.properties
# cm是configMap的缩写
kubectl get cm web-game -o yaml
# 怎么用configMap
vi pod-game.yaml
volumes:
-name:game
configMap:
name: web-game
volumeMounts:
-name: game
mountPath:/etc/config/game
kubectl create -f pod-game.yaml
# 进入后,就能在你mount的目录找到配置文件
#修改
kubectl edit cm web-game
----------------
另一种用法 环境变量
vi configmap.yaml
data:
JAVA_OPTS: -Xms1024 # 定义了最大的内存
LOG_LEVEL: DEBUG # 定义了log的级别
kubectl create -f configmap.yaml
# 创建完可以通过环境变量的方式使用
vi pod-env.yaml
spec:
containers:
env:
- name: LOG_LEVEL_CONFIG
valueFrom:
configMapKeyRef:
name: configs
key: LOG_LEVEL
kubectl create -f pod-env.yaml
# 进入容器 通过环境变量访问到变量的值
env|grep LOG
----------------------
还可以通过参数传进去
vi pod-cmd.yaml

进入容器 ps -ef 就可以看到参数已经传进去了
DownloadAPI 程序可以取到pod本身的一些相关信息
vi pod-downwardapi.yaml
volumes下定义downwardAPI
也是通过name挂载到volumeMounts:一个路径下
kubectl create -f pod-downwardapi.yaml
# 进入容器中挂载目录
ls -l
cat -n labels就能得到那些key value
这样认为太麻烦,用CICD解决
1、if no cicd
git提交代码仓库—maven构建—发布到指定的服务器上 — 调用脚本(停止老的服务,启动新服务)
problem:
服务间断,一段时间服务不可用。
一台机器多人用,环境版本问题
多次构建 dev test release发布环境 pre准生产 product
2、git — maven — build image — push image — k8s deploy — HealthCheck
好处:
环境隔离
服务不间断,因为滚动部署
一次构建,多环境运行,测的都是一个镜像
需要 install jenkins,现在是在其中一个node节点上的,一个job就是从拉代码到服务发布
Jenkins服务网页上填上名字,选择pipeline,写script,save, 点立即构建,点configure 继续编辑script
健康检查
kubectl get deploy k8s-web-demo -o yaml
用 go-template 找status,状态都相等时,即为健康
annotations 下面的revision 可以用它做更靠谱的健康检查
HealthCheck
1、没有健康检查的话,k8s只有在入口程序挂掉后,才会重启pod
健康检查是针对容器的,在yaml中是 livenessProbe:(检查应用是不是活着的探针)
1)cmd方式检查
exec: command: ps -ef|grep java 如果正常就返回0,非零则没通过健康检查,就pod重启
initialDelaySeconds: 10 等容器启动10秒后在执行健康检查命令
periodSeconds: 10 健康检查间隔
failureThreshold: 2 失败几次后才重启
successThreshold: 1 一次成功即为认定成功
timeoutSeconds: 5 执行command等待的时间
echo $? #上一条命令的返回值
返回值成功 打印出0
2)第二种基于http的
livenessProbe:
httpGet:
path: /
port: 8080 #容器开放的端口
scheme: HTTP
3)tcp方式 检查端口是否在监听状态
livenessProbe负责发现程序有问题了,重启,
用tcp检查端口是否存活
tcpSocket:
port: 8080
readinessProbe:(这个告诉k8s程序已经准备就绪了,可以挂到负载均衡上了,可以供用户使用了)
用http检查它是否可以访问
httpGet
kubectl get deploy -n dev 如果AVAILABLE是1,就说明readiness
Namespace
1、资源对象的隔离:Service, Deployment, Pod
资源配额的隔离:Cpu, Memory
2、创建命名空间:kubectl create -f namespace-dev.yaml
在其他应用yaml里面指定namespace
kubectl exec -it pod名 bash 进入pod
不同namespace serviceIP,podIP是可以互相访问的,namespace隔离的是dns名字,物理ip隔离不了
Resources CPU 内存
核心设计:Requests Limits
配置下yaml文件的resources
cpu: 100 表示100个cpu; cpu:100m 一核心的cpu等于1000m
kubectl describe node 节点名— 可以查看节点还有多少资源
requests改的太大的话,pod起不来,limit没影响
docker inspect 容器id,查看容器设置
docker status 容器id,查看资源占用情况
cpu是可压缩资源,你占用多了,就给你少分点,不会杀死进程
limitRange 在一个命名空间下设置资源限制, 如果不限制,在资源抢占的时候会处于劣势, 超了系统会kill 进程的。
pod优先级 request=limit 【完全可靠】> request 小于 limit【基本可靠】 >没有设置【不可靠】
kubectl create -f limits-test.yaml -n test,
kubectl get pods -n test -o yaml 可以看到资源限制
ResourceQuota 给namespace 分配资源
使用 kubectl delete -f xx.yaml 就能解除 kubectl apply
kubectl get quota -n test
kubectl describe quota object-counts -n test
Pod驱逐 - Eviction
kubelet时刻监控
用户可以自己决定驱逐哪个pod来释放资源
磁盘紧缺
删除死掉的pod、容器,没用的镜像,按优先级、资源占用情况驱逐pod(同级别中占用最多的进行驱逐)
内存紧缺
驱逐不可靠的pod, 驱逐基本可靠的pod, 驱逐可靠的pod
Label
1、key:value形式 可以贴到各种Resources-- Pod Deployment Service Node
相同的标签可以贴到多个资源上,一个资源上可以贴多个标签
根据节点的优点打标签,根据服务是前后端,可以打标签
在yaml的
spec: selector:matchLabels: key:value 和 template: metadata:labels value 这俩label必须相同,否则报错
label还可以通过deploy下的 matchExpressions设定范围
kubectl get pods -l group=dev,app=web-demo -n dev 根据标签筛选pod
kubectl get pods -l ‘group in (dev,test)’ -n dev
kubectl get pods -l ‘group notin (dev)’ -n dev
kubectl get nodes --show-labels
pod的调度策略
1、优先级队列,有一堆等待调度的pod, scheduler可以从队列中拿到pod信息
2、pod刚创建,调度之前是不知道在那个node上的
3、informer发现了等待调度的pod
4、每次都找ApiServer影响性能,所以引入Cache,缓存ApiServer上的信息,比如节点列表,节点信息,pod信息。
5、调度过程,
1)预选策略:筛掉不符合条件的节点。比如资源够吗?端口有在占用嘛?挂载的volume类型必须匹配,nodeSelector的规则必须匹配。亲和性和污点啊,必须满足
2) 优选策略:选出来进行评分,选择最高分的pod作为我们最后要调度的节点
最后ApiServer让kubelet把pod调度起来
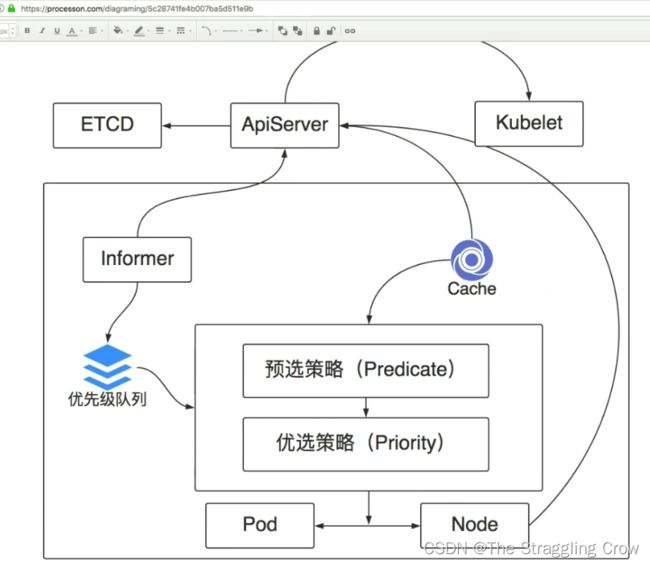
6、这些通过yaml文件里的参数控制
affinity 亲和性
1)节点的亲和性
require…Execution: 必须满足下面的条件
每个matchExpressions是并且的关系,nodeSelectorTerms是或的关系
preferr…的意思是最好是
2)pod的亲和性
一定范围内,pod和pod之间的亲和性
topologyKey: 节点的label名字
podAntiAffinity: 反亲和性调度
3)污点
node拒绝pod的运行,除非pod明显声明可以容忍这些污点
如果有些node有特殊的硬件,不想给其他pod用,比如有ssd,就可以打上污点
kubectl taint nodes nodename gpu=true:NoSchedule #冒号前面是污点名,后面是策略,
# 此处是调度器不会把pod调度在这上,preferNoSchedule--最好不要;NoExcute,除了不调度,
# 如果已经在这节点上,也把它驱逐,如果没有设置容忍时间,会把你立刻驱逐
污点容忍
tolerations:
- key:"gpu"
operator: "Equal"
value:"true"
effect:"NoSchedule"
部署策略实践
就是更新现有的服务都有哪些策略
1、Rolling update修改deployment 配置文件,然后kubectl apply -f 更新服务
spec:
strategy:
rollingUpdate:
maxSurge: 25% #我有四个实例,每次最多只能多启动一个实例
maxUnavailable: 25% #我有四个实例,最少要有三个保证可用状态
type: RollingUpdate
方式kubectl apply -f, 然后修改下yaml,比如加个标签,然后kubectl apply -f,就完事了
结果:新服务创建好后,老服务关闭,中间有一段两种服务交替存在
kubectl rollout pause deploy deploy的名字(metadata: name) -n namespace # 让滚动更新暂停
# 让其继续
kubectl rollout resume deploy deployname -n namespaceName
# 回滚原来版本
kubectl rollout undo deploy deployname -n namespaceName
2、Recreate 间断,重新创建
spec:
strategy:
type: Recreate
方式kubectl apply -f, 然后修改下yaml,比如加个标签,然后kubectl apply -f,就完事了
结果就是把旧的停掉,把新的创建
3、蓝绿部署 用service selector选择不同版本的服务,没有交替,瞬间切换版本
保持原有的部署方式(不论rolling update 还是 Recreate),我们新建一个deployment
比如原有的是绿色的,我们 newly build 一个蓝色的 ,等蓝色全部启动后,测试下蓝色的,没问题的话,
修改service的 selector ,让它把流量切到我新部署的deploy上来
template:
metadata:
labels:
app: web-bluegreen
vesion: v1.0
方式kubectl apply -f web-bluegreen,
kubectl apply -f web-bluegreen-service
spec:
selector:
app:web-bluegreen
version: v1.0
vi web-bluegreen.yaml 将镜像改掉,把version改成 v2.0 然后apply,等都跑起来
vi bluegreen-service.yaml 把version改成 v2.0 然后apply -f,瞬间就变成新版本的了
4、金丝雀 用ingress 轮询的访问不同的服务,刷新一下是一个服务,刷新一下变成另外一个服务
在蓝绿部署的基础上,简单修改下selector就变成金丝雀部署
vi bluegreen-service.yaml 将 version:v2.0删除 然后apply -f ,结果就是不断交替,一会新版本,一会旧版本
比如我只起一个新的,9个旧的,这样就可以不影响90%的用户,测试下新版本效果怎么样?就是所说的ab测试
DaemonSet 控制器能够确保 k8s 集群所有的节点都运行一个相同的 pod 副本,当向 k8s 集群中增加 node 节点时,这个 node 节点也会自动创建一个 pod 副本,当 node 节点从集群移除,这些 pod 也会自动删除;删除 Daemonset 也会删除它们创建的 pod
Daemonset 典型的应用场景
在集群的每个节点上运行存储,比如:glusterd 或 ceph。
在每个节点上运行日志收集组件,比如:flunentd 、 logstash、filebeat 等。
在每个节点上运行监控组件,比如:Prometheus、 Node Exporter 、collectd 等。
DaemonSet 与 Deployment 的区别
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。
DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
Ingress-Nginx
用ds 管理niginx controller,不要用deployment管理
1、删除deployment
kubectl delete deploy -n ingress-nginx 部署名
2、用ds(daemonSet的简称)部署
3、想在另一台机器上也跑ingress,只需要在那台机器上打个标签
kubectl label node xxx label=name
服务没起来可能因为有人在占用他想要的端口
用此命令查看
netstat -ntlp|grep 80
4、删除标签
kubectl get nodes
kubectl label node nodeName app-
查看结果
kubectl get pods -n ingress-nginx -o wide
四层代理—面对提供tcp服务,而不是http服务的时候
tcp如何用ingress-nginx去做服务发现
kubectl get cm -n ingress-nginx #cm是configmap的缩写
kubectl get cm -n ingress-nginx tcp-services -o yaml # tcp-services是创建ingress-nginx建立的
里面没有什么实质内容,都是元数据
自己写的文件 tcp-config.yaml
data:
“30000” : dev/web-demo:80 前面数字代表要暴露出去的端口,dev命名空间下的,web-demo服务80端口暴露在ingress-niginx上,服务是30000
kubectl apply -f tcp-config.yaml
就可以通过nodeIP:30000访问服务
定制自己的ingress,调整nginx的配置,用yaml文件弄
比如超时,buff size等等
涉及https的服务,怎么用证书呢
将生成的证书配置到ingress-nginx里面
用openssl生成一个key,一个crt证书,接下来创建tls类型的secret
kubectl get secret mc-tls -o yaml
在nginx-ingress-controller.yaml 里添加指定证书命令,然后apply -f 这个yaml
最后就可以通过https访问了,自己创建的证书,浏览器肯定是提示不安全的
访问控制
1)web服务有可能需要session 保持,同一个会话里面,最好访问的是同一个后端
带着cookie就保证他一直访问的是同一个后端,除非把浏览器关掉,再重开,就有可能访问到另外一个服务
修改的是yaml里面的
metadata:
annotations:
affinity: cookie
session-cookie-hash: sha1
session-cookie-name: route
2)新上线一个服务,先切10%的流量过来,看看是不是有问题,没问题,逐步增加
canary 金丝雀
#创建命名空间
kubectl create ns canary
apply -f canary a 和 canary b 和 ingress-nginx,然后网页便可访问网址
再apply -f 一个 yaml,关键在这个yaml中的 canary-weight: “10”,这样就实现了偶尔就能出现canary-b
测试用 while sleep 0.2; do curl http://网址 && echo “”; done (echo ”“ 是回车)
3)不让用户访问,只让测试人员,测试过了之后再上线
用cookie的方式做定向的流量控制,关键再yaml文件里的 canary-by-cookie: “cookie名字”
浏览器一直刷新还是老版本,那怎么才能访问新版本呢?就是加一个cookie,名字就是上面定义的,并指定值always,那么接下来就全部是访问到canary-b
还可以通过header实现 canary-by-header: “headerName”
用命令行测试: curl -H ‘headerName: always’ 域名
三种可以组合在yaml中,header, cookie, weight,,优先级顺序就是这个,header优先级最高,有header,其他不考虑,没有,看cookie有没有