一个优化的SQL:
SELECT order_date,
order_source,
SUM(commodity_num) num,
SUM(actual_charge) charge
FROM (
SELECT to_char(oc.create_date, 'yyyyMMdd') AS order_date,
(CASE
WHEN oo.event_type = 'ONLINE_COMMODITY_ORDER' THEN
'线上'
ELSE
'线下'
END) order_source,
oc.commodity_num,
oc.actual_charge actual_charge
FROM ord.ord_commodity_hb_2017 AS oc, ord.ord_order_hb_2017 AS oo
WHERE oc.order_id = oo.order_id
AND oc.op_type = 3 -- 3个值 ,3->5000 大概1/20的数据
AND oc.create_date BETWEEN '2017-02-05' AND '2017-12-07' -- 无用
AND oc.corp_org_id = 106 -- 无用
AND oo.trade_state = 11 -- 3个值 11 --> 71万行,一半数据
AND oo.event_type IN (values('ONLINE_COMMODITY_ORDER'),
('USER_CANCEL'),
('USER_COMMODITY_UPDATE')) -- 大概1/10 数据
ORDER BY oc.create_date -- 如果业务不强制,最好去掉排序,如果不能去掉,最好等过滤数据量到尽量小时再排序
) T
GROUP BY order_date, order_source;
下面默认以postgresql为例:
一、排序:
1. 尽量避免
2. 排序的数据量尽量少,并保证在内存里完成排序。
(至于具体什么数据量能在内存中完成排序,不同数据库有不同的配置:
oracle是sort_area_size;
postgresql是work_mem (integer),单位是KB,默认值是4MB。
mysql是sort_buffer_size 注意:该参数对应的分配内存是每连接独占!
)
二、索引:
1. 过滤的数据量比较少,一般来说<20%,应该走索引。20%-40% 可能走索引也可能不走索引。> 40% ,基本不走索引(会全表扫描)
2. 保证值的数据类型和字段数据类型要一直。
3. 对索引的字段进行计算时,必须在运算符右侧进行计算。也就是 to_char(oc.create_date, 'yyyyMMdd')是没用的
4. 表字段之间关联,尽量给相关字段上添加索引。
5. 复合索引,遵从最左前缀的原则,即最左优先。(单独右侧字段查询没有索引的)
三、连接查询方式:
1、hash join
放内存里进行关联。
适用于结果集比较大的情况。
比如都是200000数据
2、nest loop
从结果1 逐行取出,然后与结果集2进行匹配。
适用于两个结果集,其中一个数据量远大于另外一个时。
结果集一:1000
结果集二:1000000
四、多表联查时:
在多表联查时,需要考虑连接顺序问题。
1、当postgresql中进行查询时,如果多表是通过逗号,而不是join连接,那么连接顺序是多表的笛卡尔积中取最优的。如果有太多输入的表, PostgreSQL规划器将从穷举搜索切换为基因概率搜索,以减少可能性数目(样本空间)。基因搜索花的时间少, 但是并不一定能找到最好的规划。
2、对于JOIN,
LEFT JOIN / RIGHT JOIN 会一定程度上指定连接顺序,但是还是会在某种程度上重新排列:
FULL JOIN 完全强制连接顺序。
如果要强制规划器遵循准确的JOIN连接顺序,我们可以把运行时参数join_collapse_limit设置为 1
五、PostgreSQL提供了一些性能调优的功能:
优化思路:
0、为每个表执行 ANALYZE
。然后分析 EXPLAIN (ANALYZE,BUFFERS) sql。
1、对于多表查询,查看每张表数据,然后改进连接顺序。
2、先查找那部分是重点语句,比如上面SQL,外面的嵌套层对于优化来说没有意义,可以去掉。
3、查看语句中,where等条件子句,每个字段能过滤的效率。找出可优化处。
比如oc.order_id = oo.order_id是关联条件,需要加索引
oc.op_type = 3 能过滤出1/20的数据,
oo.event_type IN (...) 能过滤出1/10的数据,
这两个是优化的重点,也就是实现确保op_type与event_type已经加了索引,其次确保索引用到了。
优化方案:
a) 整体优化:
1、使用EXPLAIN
EXPLAIN命令可以查看执行计划,这个方法是我们最主要的调试工具。
2、及时更新执行计划中使用的统计信息
由于统计信息不是每次操作数据库都进行更新的,一般是在 VACUUM 、 ANALYZE 、 CREATE INDEX等DDL执行的时候会更新统计信息,
因此执行计划所用的统计信息很有可能比较旧。 这样执行计划的分析结果可能误差会变大。
以下是表tenk1的相关的一部分统计信息。
SELECT relname, relkind, reltuples, relpages
FROM pg_class
WHERE relname LIKE 'tenk1%';
relname | relkind | reltuples | relpages
----------------------+---------+-----------+----------
tenk1 | r | 10000 | 358
tenk1_hundred | i | 10000 | 30
tenk1_thous_tenthous | i | 10000 | 30
tenk1_unique1 | i | 10000 | 30
tenk1_unique2 | i | 10000 | 30
(5 rows)
其中 relkind是类型,r是自身表,i是索引index;reltuples是项目数;relpages是所占硬盘的块数。
估计成本通过 (磁盘页面读取【relpages】*seq_page_cost)+(行扫描【reltuples】*cpu_tuple_cost)计算。
默认情况下, seq_page_cost是1.0,cpu_tuple_cost是0.01。
名字
类型
描述
relpages
int4
以页(大小为BLCKSZ)的此表在磁盘上的形式的大小。 它只是规划器用的一个近似值,是由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。
reltuples
float4
表中行的数目。只是规划器使用的一个估计值,由VACUUM,ANALYZE 和几个 DDL 命令,比如CREATE INDEX更新。
3、使用临时表(with)
对于数据量大,且无法有效优化时,可以使用临时表来过滤数据,降低数据数量级。
4、对于会影响结果的分析,可以使用 begin;...rollback;来回滚。
b) 查询优化:
1、明确用join来关联表,确保连接顺序
一般写法:SELECT * FROM a, b, c WHERE a.id = b.id AND b.ref = c.id;
如果明确用join的话,执行时候执行计划相对容易控制一些。
例子:
SELECT * FROM a CROSS JOIN b CROSS JOIN c WHERE a.id = b.id AND b.ref = c.id;
SELECT * FROM a JOIN (b JOIN c ON (b.ref = c.id)) ON (a.id = b.id);
c) 插入更新优化
1、关闭自动提交(autocommit=false)
如果有多条数据库插入或更新等,最好关闭自动提交,这样能提高效率
2、多次插入数据用copy命令更高效
我们有的处理中要对同一张表执行很多次insert操作。这个时候我们用copy命令更有效率。因为insert一次,其相关的index都要做一次,比较花费时间。
3、临时删除index【具体可以查看Navicat表数据生成sql的语句,就是先删再建的】
有时候我们在备份和重新导入数据的时候,如果数据量很大的话,要好几个小时才能完成。这个时候可以先把index删除掉。导入后再建index。
4、外键关联的删除
如果表的有外键的话,每次操作都没去check外键整合性。因此比较慢。数据导入后再建立外键也是一种选择。
d) 修改参数:
选项
默认值
说明
是否优化
原因
max_connections
100
允许客户端连接的最大数目
否
因为在测试的过程中,100个连接已经足够
fsync
on
强制把数据同步更新到磁盘
是
因为系统的IO压力很大,为了更好的测试其他配置的影响,把改参数改为off
shared_buffers
24MB
决定有多少内存可以被PostgreSQL用于缓存数据(推荐内存的1/4)
是
在IO压力很大的情况下,提高该值可以减少IO
work_mem
1MB
使内部排序和一些复杂的查询都在这个buffer中完成
是
有助提高排序等操作的速度,并且减低IO
effective_cache_size
128MB
优化器假设一个查询可以用的最大内存,和shared_buffers无关(推荐内存的1/2)
是
设置稍大,优化器更倾向使用索引扫描而不是顺序扫描
maintenance_work_mem
16MB
这里定义的内存只是被VACUUM等耗费资源较多的命令调用时使用
是
把该值调大,能加快命令的执行
wal_buffer
768kB
日志缓存区的大小
是
可以降低IO,如果遇上比较多的并发短事务,应该和commit_delay一起用
checkpoint_segments
3
设置wal log的最大数量数(一个log的大小为16M)
是
默认的48M的缓存是一个严重的瓶颈,基本上都要设置为10以上
checkpoint_completion_target
0.5
表示checkpoint的完成时间要在两个checkpoint间隔时间的N%内完成
是
能降低平均写入的开销
commit_delay
0
事务提交后,日志写到wal log上到wal_buffer写入到磁盘的时间间隔。需要配合commit_sibling
是
能够一次写入多个事务,减少IO,提高性能
commit_siblings
5
设置触发commit_delay的并发事务数,根据并发事务多少来配置
是
减少IO,提高性能
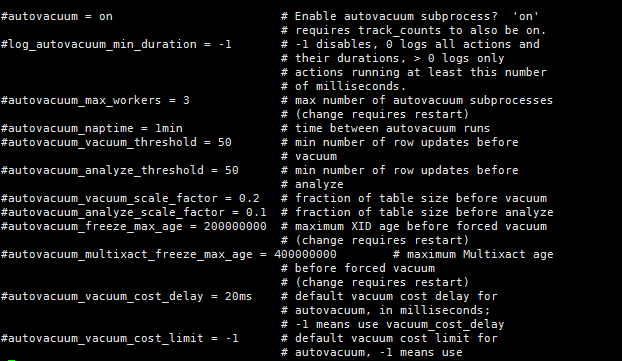
autovacuum_naptime
1min
下一次vacuum任务的时间
是
提高这个间隔时间,使他不是太频繁
autovacuum_analyze_threshold
50
与autovacuum_analyze_scale_factor配合使用,来决定是否analyze
是
使analyze的频率符合实际
autovacuum_analyze_scale_factor
0.1
当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。
是
使analyze的频率符合实际
1、增加maintenance_work_mem参数大小
增加这个参数可以提升CREATE INDEX和ALTER TABLE ADD FOREIGN KEY的执行效率。
2、增加checkpoint_segments参数的大小
增加这个参数可以提升大量数据导入时候的速度。
3、设置archive_mode无效
这个参数设置为无效的时候,能够提升以下的操作的速度
・CREATE TABLE AS SELECT
・CREATE INDEX
・ALTER TABLE SET TABLESPACE
・CLUSTER等。
4、autovacuum相关参数
autovacuum :默认为on,表示是否开起autovacuum。默认开起。特别的,当需要冻结xid时,尽管此值为off,PG也会进行vacuum。
autovacuum_naptime :下一次vacuum的时间,默认1min。 这个naptime会被vacuum launcher分配到每个DB上。autovacuum_naptime/num of db。
log_autovacuum_min_duration:记录autovacuum动作到日志文件,当vacuum动作超过此值时。 “-1”表示不记录。“0”表示每次都记录。
autovacuum_max_workers :最大同时运行的worker数量,不包含launcher本身。
autovacuum_work_mem :每个worker可使用的最大内存数。
autovacuum_vacuum_threshold :默认50。与autovacuum_vacuum_scale_factor配合使用, autovacuum_vacuum_scale_factor默认值为20%。当update,delete的tuples数量超过autovacuum_vacuum_scale_factor*table_size+autovacuum_vacuum_threshold时,进行vacuum。如果要使vacuum工作勤奋点,则将此值改小。
autovacuum_analyze_threshold :默认50。与autovacuum_analyze_scale_factor配合使用。
autovacuum_analyze_scale_factor : 默认10%。当update,insert,delete的tuples数量超过autovacuum_analyze_scale_factor*table_size+autovacuum_analyze_threshold时,进行analyze。
autovacuum_freeze_max_age :200 million。离下一次进行xid冻结的最大事务数。
autovacuum_multixact_freeze_max_age :400 million。离下一次进行xid冻结的最大事务数。
autovacuum_vacuum_cost_delay :如果为-1,取vacuum_cost_delay值。
autovacuum_vacuum_cost_limit :如果为-1,到vacuum_cost_limit的值,这个值是所有worker的累加值。
你可能感兴趣的:(PostgreSQL,postgresql)
Redis vs. 其他数据库:深度解析,如何选择最适合的数据库?
moton2017
数据库 redis 缓存
一、如何为项目选择合适的数据库?选择合适的数据库是一个复杂的过程,需要综合考虑多个因素。下面几个维度来详细阐述:1.数据模型关系型数据库(RDBMS):适用于高度结构化、关联性强的数据,如电商关系系统、金融系统。代表:MySQL、PostgreSQL。NoSQL数据库:文档型数据库(如MongoDB):适用于灵活的、类似文档的数据,如内容管理系统。键值对数据库(如Redis):适用于服务器、实时数
开源的数据库监控和管理工具—PMM
蚂蚁在飞-
数据库 人工智能 运维 后端
PMM(PerconaMonitoringandManagement)是一个开源的数据库监控和管理工具,主要用于监控MySQL、MariaDB、MongoDB和PostgreSQL等数据库的性能和健康状况。PMM提供了一套可视化的界面,帮助数据库管理员和开发人员对数据库进行深度监控、性能优化和故障排查。PMM由两个主要组件组成:1.PMMServerPMMServer是PMM的核心组件,负责收集和
PostgreSQL 数据备份与恢复:掌握 pg_dump 和 pg_restore 的最佳实践
title:PostgreSQL数据备份与恢复:掌握pg_dump和pg_restore的最佳实践date:2025/1/28updated:2025/1/28author:cmdragonexcerpt:在数据库管理中,备份与恢复是确保数据安全和业务连续性的关键措施。PostgreSQL提供了一系列工具,以便于数据库管理员对数据进行备份和恢复,其中pg_dump和pg_restore是最常用且功
【面试题】构建高并发、高可用服务架构:技术选型与设计
言之。
redis python 面试 架构
监控系统消息队列缓存层数据存储层应用层Web层负载均衡与流量分配GrafanaPrometheusAlertmanager消息队列Kafka/RabbitMQ集群/镜像队列缓存层Redis/Memcached数据库MySQL/PostgreSQL主从复制/主主复制应用服务器SpringBoot/Node.js应用服务器SpringBoot/Node.js应用服务器SpringBoot/Node.j
Windows 上安装 PostgreSQL
froginwe11
开发语言
Windows上安装PostgreSQLPostgreSQL是一款功能强大的开源对象-关系型数据库系统,它具有出色的扩展性和稳定性。本文将详细介绍在Windows操作系统上安装PostgreSQL的步骤和注意事项。1.准备工作在开始安装PostgreSQL之前,请确保您的计算机满足以下要求:操作系统:Windows10或更高版本处理器:64位内存:至少4GB(推荐8GB或更高)硬盘空间:至少2GB
PostgreSQL中级专家是什么意思?
leegong23111
postgresql oracle 数据库
数据库技术领域,PostgreSQL作为一种广泛使用的开源关系型数据库管理系统,吸引了众多技术人员深入学习和研究。“PostgreSQL中级专家”是对掌握该数据库特定技能层次的一种描述。知识储备中级专家深入理解PostgreSQL的体系结构,包括进程模型、内存管理机制等。他们清楚数据库是如何存储数据,以及各个组件如何协同工作来保证数据的一致性和完整性。精通SQL语言在PostgreSQL中的高级特
PostgreSQL 介绍
candy662
postgresql
PostgreSQL是一个免费的对象-关系数据库服务器(ORDBMS),在灵活的BSD许可证下发行。PostgreSQL开发者把它念作post-gress-Q-L。PostgreSQL的Slogan是"世界上最先进的开源关系型数据库"。参考内容:PostgreSQL10.1手册什么是数据库?数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。每个数据库都有一个或多个不同的API用
第21篇:python编程进阶:python数据库基础详解
猿享天开
python从入门到精通 python 数据库 开发语言
第21篇:数据库基础内容简介在现代应用开发中,数据库是存储和管理数据的核心组件。本篇文章将介绍关系型数据库与非关系型数据库的基本概念和区别,深入探讨SQL的基础知识,并展示如何使用Python连接和操作常见的数据库系统,如MySQL和PostgreSQL。通过理论与实践相结合的方式,您将全面掌握数据库的基本原理和实际应用技能,为构建高效、可靠的数据驱动型应用打下坚实的基础。目录数据库概述什么是数据
PostgreSQL TRUNCATE TABLE 操作详解
lsx202406
开发语言
PostgreSQLTRUNCATETABLE操作详解引言在数据库管理中,经常需要对表进行操作以保持数据的有效性和一致性。TRUNCATETABLE是PostgreSQL中一种高效删除表内所有记录的方法。本文将详细探讨PostgreSQL中TRUNCATETABLE的使用方法、性能优势以及注意事项。什么是TRUNCATETABLE?TRUNCATETABLE语句用于删除指定表中的所有记录,并重置该
PostgreSQL体系结构
eygle
原文:https://www.enmotech.com/web/detail/1/764/1.html导读:本文主要从日志文件、参数文件、控制文件、数据文件、redo日志(WAL)、后台进程这六个方面来讨论PostgreSQL的结构。一、引言PostgreSQL是最像Oracle的开源数据库,我们可以拿MySQL和Oracle来比较学习它的体系结构,比较容易理解。本文会讨论pg的如下结构:日志文件
【postgresql初级使用】在表的多个频繁使用列上创建一个索引,多条件查询优化,多场景案例揭示索引失效
韩楚风
postgresql 数据库 sql database
多列索引专栏内容:postgresql使用入门基础手写数据库toadb并发编程个人主页:我的主页管理社区:开源数据库座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.文章目录多列索引概述多列索引创建创建语法创建说明案例分析创建数据创建索引带首列查询不带首列查询总结结尾概述
Oracle、PostgreSQL该学哪一个?
leegong23111
oracle postgresql 数据库
从事数据库运维一线工作的老鸟,经常会有人来问我:“Oracle和PostgreSQL,我该学哪个?哪个更有职业发展前景?”今天就来和大家好好唠唠。先说说Oracle。它堪称数据库领域的“老牌贵族”,功能极其强大。在大型企业和金融机构中,Oracle有着深厚的根基。其具备高度的稳定性和可靠性,能支撑超大规模的数据处理和高并发业务。比如在银行的核心交易系统中,每天要处理海量的交易数据,Oracle就能
MySQL、PostgreSQL 和 Microsoft SQL Server:谁是王者?
cda2024
mysql postgresql microsoft
在当今数据驱动的时代,选择合适的数据库系统对于企业的成功至关重要。MySQL、PostgreSQL和MicrosoftSQLServer是目前市场上最受欢迎的三种关系型数据库管理系统(RDBMS)。每种数据库都有其独特的优势和适用场景,但究竟哪一种更适合你的业务需求呢?本文将从多个维度对这三种数据库进行对比,帮助你做出明智的选择。1.性能1.1MySQLMySQL是一款开源数据库,以其高性能和易用
“选择最佳数据库解决方案:MySQL、SQL Server 和 PostgreSQL 的比较与实际应用指南“
AMIOKATT
数据库 mysql postgresql
目录典型中高端数据库服务器硬件配置CPU内存存储网络操作系统不同数据库系统在上述硬件上的性能表现MySQLPostgreSQLSQLServer具体硬件配置示例示例配置1:中小型Web应用示例配置2:复杂查询和事务处理示例配置3:企业级数据仓库和分析其他优化建议典型中高端数据库服务器硬件配置CPU型号:IntelXeon或AMDEPYC系列核心数:8至32个物理核心(多线程,通常2倍的逻辑核心)主
【PostgreSQL实战1】基于openEuler部署PostgreSQL
云计算老王
postgresql 数据库
【PostgreSQL实战1】基于openEuler部署PostgreSQL目录【PostgreSQL实战1】基于openEuler部署PostgreSQL前言一、PostgreSQL是什么?二、环境准备2.1操作系统2.2内存2.3CPU2.4关闭selinux2.5关闭防火墙三、部署安装3.1创建用户名3.2创建目录3.3安装依赖3.4安装包下载3.5编译安装3.6配置环境变量3.7初始化3.
PostgreSql学习:体系结构
我爱夜来香A
数据库开发 数据库 postgresql 服务器
postgresql一、存储结构、逻辑存储结构、物理存储结构二、进程结构、守护进程与服务进程、辅助进程三、内存结构、本地内存、共享内存PostgreSql数据库是由一系列位于文件系统上的物理文件组成,在数据库运行过程中,通过整套高效严谨的逻辑管理这些物理文件。通常将这些物理文件称为数据库,将这些物理文件、管理这些物理文件的进程、进程管理的内存称为这个数据库的实例。在postgreSql的内部实现上
使用 pgvector 实现 PostgreSQL 语义搜索和 RAG:完整指南
m0_74825260
面试 学习路线 阿里巴巴 postgresql 数据库
使用pgvector实现PostgreSQL语义搜索和RAG:完整指南1.引言在当今的数据驱动世界中,能够高效地搜索和检索相关信息变得越来越重要。传统的关系型数据库虽然在结构化数据管理方面表现出色,但在处理非结构化数据和语义搜索时往往力不从心。本文将介绍如何使用pgvector扩展来增强PostgreSQL数据库,实现语义搜索和检索增强生成(RAG)功能,从而大大提升数据检索的效率和准确性。2.p
使用 pgvector 将 PostgreSQL 与语义搜索/RAG 集成的教程
azzxcvhj
postgresql 人工智能 数据库 python
技术背景介绍在大语言模型(LLMs)和语义搜索的兴起中,结合结构化的关系型数据库(如PostgreSQL)进行增强型查询变得越来越有价值。这种方法常用于RAG(Retrieval-AugmentedGeneration)场景,例如FAQ问答、文档检索、推荐系统等。pgvector是用于PostgreSQL的一个扩展,它支持稠密向量的存储和操作。通过pgvector,可以将嵌入向量直接存储在数据库中
创建和管理用户
远歌已逝
数据库 oracle 数据库
学习目标创建新的数据库用户修改和删除现有的数据库用户监控现有用户的信息获取用户信息以下是基于MySQL数据库管理系统的操作步骤和示例,这些概念也可以适用于其他数据库系统,如PostgreSQL、SQLServer、Oracle等。1.创建新的数据库用户在MySQL中创建新用户,可以使用以下SQL语句:CREATEUSER'username'@'hostname'IDENTIFIEDBY'passw
Postgres与MySQL对比
救救孩子把
mysql 数据库
AntonP的[基准测试]MySQL与PostgreSQL性能基准(延迟-吞吐量-饱和)我们每天与成千上万的开发人员合作管理他们的数据,我亲眼目睹了PostgreSQL和MySQL如何成为最受欢迎(也是最强大)的两个数据库。在本文中,我将比较两者—涵盖它们的优点、缺点和细微差别—以便您可以决定哪一个最适合您的需求。几十年来,关系数据库为无数应用程序提供支持,它们仍然是许多现代系统的支柱。当谈到生产
Databend 实现高效实时查询:深入解读 Dictionary 功能
数据库
作者:洪文丽开源之夏2024“支持ExternalDictionaries”项目参与者东北大学软件工程专业云计算方向大二在读,喜欢挑战自我,尝试新鲜事物背景介绍在大型系统中,数据通常存储在多个不同的数据源中,例如PostgreSQL、MySQL和Redis负责存储在线数据,而Databend和ClickHouse则用于存储分析数据。传统的分析查询方法往往需要同时使用到多种不同的数据,通常通过ETL
Azure学生订阅上手实操:在Ubuntu VPS上利用Docker快速部署PostgreSQL数据库
shelby_loo
数据库 azure ubuntu
引言本文将详细指导您如何在Azure100学生订阅中,利用Ubuntu虚拟机,通过Docker容器技术快速搭建PostgreSQL数据库。我们将从Docker和PostgreSQL的基础知识入手,逐步讲解部署过程中的每一个步骤,并提供完整的命令和配置文件示例。Docker和PostgreSQL简介Docker是一种开源的容器化平台,它可以让开发者打包他们的应用以及依赖项到一个可移植的容器中。这些容
PostgreSQL 向量扩展插件pgvector安装和使用
m0_74823524
面试 学习路线 阿里巴巴 postgresql 数据库
文章目录PostgreSQL向量扩展插件pgvector安装和使用安装postgresqlpgvector下载和安装安装错误调试错误调试1尝试解决AP1:启动postgresql错误调试2尝试解决AP2:使用apt-getinstallpostgresql-server错误调试3尝试解决AP3:卸载apt-get安装错误调试4设置环境变量PG_CONFIG编译成功使用pgvector测试例列出当前
使用python将数据导入postgresql数据中
强强0007
postgresql python 数据库
1插入一条数据连接postgresql数据库中的origindb数据库,用户为dn。创建表插入一条数据##导入psycopg2包importpsycopg2##连接到一个给定的数据库conn=psycopg2.connect(database="origindb",user="dn",password="000000",host="192.168.10.102",port="5432")##建立游
pg使用python编写存储过程_postgresql – 可以在Postgres Python存储过程中使用NLTK
耶律大石
您可以在PL/Python存储过程或触发器中使用几乎任何Python库.概念要理解的关键点是PL/Python是CPython(无论如何都在PostgreSQL中包括9.3);它使用与普通独立Python完全相同的解释器,它只是将它作为库加载到PostgreSQL支持的.有一些限制(如下所述),如果它适用于CPython,它可以与PL/Python一起使用.如果您的系统上安装了多个Python解释
python建立数据库_Python PostgreSQL-创建数据库
weixin_39727976
python建立数据库
您可以使用CREATEDATABASE语句在PostgreSQL中创建数据库。您可以通过在命令后指定要创建的数据库的名称,在PostgreSQLShell提示符下执行此语句。句法以下是CREATEDATABASE语句的语法。CREATEDATABASEdbname;例以下语句在PostgreSQL中创建一个名为testdb的数据库。postgres=#CREATEDATABASEtestdb;CR
pg使用python编写存储过程_postgresql存储过程代码编写
weixin_39562185
背景公司最近有个项目数据库里表需要使用到另外一个数据库里表的某两个字段,而且并不是直接查询就能插入到新表里旧表idsncustomer1xxxxTest新表idsncustomer_id1xxxx1idcustomer1Test我开始考虑的是使用python脚本去查数据库,然后逻辑判断,这种方式也是可以实现的。进行插入但表里的数据有几百万条记录,使用python脚本迁移,有网络的开销,执行的速度会
pg使用python编写存储过程_Python操作PostgreSql数据库的方法(基本的增删改查)
何明科
Python操作PostgreSql数据库(基本的增删改查)操作数据库最快的方式当然是直接用使用SQL语言直接对数据库进行操作,但是偶尔我们也会碰到在代码中操作数据库的情况,我们可能用ORM类的库对数控库进行操作,但是当需要操作大量的数据时,ORM的数据显的太慢了。在python中,遇到这样的情况,我推荐使用psycopg2操作postgresql数据库psycopg2官方文档传送门:http:/
PostgreSQL 初中级认证可以一起学吗?
leegong23111
数据库
在数据库领域,PostgreSQL以其强大的功能和稳定性备受青睐。对于想要在该领域提升自己专业能力的人来说,考取PostgreSQL认证就可以轻松考取国产数据库。那么,PostgreSQL初中级认证可以一起考吗?又该如何报名呢?首先,关于是否能一起考的问题。答案是可以的。PostgreSQL认证体系为考生提供了灵活的选择,允许考生根据自己的知识储备和能力水平,同时报考初级和中级认证考试。这对于那些
使用python将Excal表格数据批量导入PostgreSQL数据库
大橙子zz
python 数据库 postgresql
使用Python中的psycopg2库来操作PostgreSQL数据库是一个常见的任务。以下是一个完整的示例,包括安装必要的包、建立和关闭连接、执行增删改查操作以及处理可能的异常。1.环境准备安装必要的包:pandas:用于读取Excel文件并处理数据。openpyxl或者xlrd:pandas读取Excel文件所需的库。psycopg2:Python访问PostgreSQL数据库的适配器。pip
Java实现的简单双向Map,支持重复Value
superlxw1234
java 双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
PL/SQL触发器基础及例子
百合不是茶
oracle数据库 触发器 PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
[时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
easy ui datagrid上移下移一行
商人shang
js 上移下移 easyui datagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
springMVC 使用JSR-303 Validation验证
杨白白
spring mvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
使用ajax和history.pushState无刷新改变页面URL
agevs
jquery 框架 Ajax html5 chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
centos中文乱码
AILIKES
centos OS ssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
JS正则表达式的i m g
bijian1013
JavaScript 正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
HTML5模式和Hashbang模式
bijian1013
JavaScript AngularJS Hashbang模式 HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
[Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
巧用视错觉-UI更有趣
brotherlamp
UI ui视频 ui教程 ui自学 ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构 算法 线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
HTTP协议详解
chicony
http协议
引言
Scala设计模式
chenchao051
设计模式 scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
安装mysql
daizj
mysql 安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
C语言中,关键字static的作用
e200702084
C++ c C#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转 递归反转 二分交换反转 java字符串反转 栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
代码实现任意容量倒水问题
home198979
PHP 算法 倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
两种启动监听器ApplicationListener和ServletContextListener
spjich
java spring 框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
JavaScript Rounding Methods of the Math object
何不笑
JavaScript Math
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen