App卡帧与BlockCanary
作者:图个喜庆
一,前言
app卡帧一直是性能优化的一个重要方面,虽然现在手机硬件性能越来越高,明显的卡帧现象越来越少,但是了解卡帧相关的知识还是非常有必要的。
本文分两部分从app卡帧的原理出发,讨论屏幕刷新机制,handler消息机制,为什么在主线程执行耗时任务会造成卡帧。另一部分讨论BlockCanary的原理,它是如何检测方法耗时的。
二,屏幕刷新机制
(1)卡帧的定义
大家小时候应该都玩过一个玩具,5毛一本的连环画小书,每一页绘制一幅画,用手指快速翻动会产生一个动画效果。
假设这本小书用50页构成一个完整的动画,丢了一页两页,可能看不出来,由于某些原因丢了10页,20页就完全没法看了。
app卡帧就是因为某些原因影响了屏幕绘制,电影每秒24帧,一般的手机是每秒60帧,高刷手机是每秒90帧 ,120帧。
如果发生了卡帧原本一秒内应该出现60张画面,实际只出现了30张画面,用户就会感觉界面不流畅。
用歌词举例卡帧 :
正常歌词【梦美的太短暂,孟克桥上呐喊,这世上的热闹,出自孤单】
卡帧歌词【梦xxx暂,xx桥xx喊,这世xx热闹,xxx单】
(2)屏幕刷新基础概念
在京东随便找几个手机,查看它们的屏幕刷新率参数: 144Hz ,90Hz,60Hz。
代表一秒内屏幕刷新的次数,常见的16.6ms刷新一次的概念来自 60Hz的普通手机 1000 / 60 ≈ 16ms。
60Hz的手机,每秒刷新60次,每次间隔16.6ms
90Hz的手机,每秒刷新90次,每次间隔11.1ms
144Hz的手机,每秒刷新144次,每次间隔6.9ms
手机的展示内容不是固定的,没办法预知提前绘制,所以手机硬件必须以极快的速度计算并绘制好下个瞬间要展示的图像。
60Hz的手机每个16ms就会出一帧图像。为了绘制这帧画有三个硬件参与其中:CPU,GPU,屏幕(display)
CPU负责计算数据,屏幕是由一个个像素点组成的,CPU根据编写的程序,计算这块像素展示什么颜色,形状之类的。
GPU负责把CPU计算好的数据进行渲染,放到缓存中
屏幕把缓存中的数据呈现到屏幕上
手机刷新频率是硬件决定的不会发生改变,CPU和GPU的工作必须在固定时间完成,如果没有按时完成就会产生掉帧。
(3)VSync ,Choreographer,view绘制
以固定频率刷新屏幕这种机制叫做VSync机制。Android系统每隔16ms发出VSYNC信号,触发UI渲染,Vsync机制并不是Android独创的,是一种在PC上很早就广泛使用的技术,Android在4.1版本引入Vsync机制。
这就引发了一个问题,屏幕刷新频率是非常快的,程序中关于view绘制的代码写在onMeasure()``onDraw()``onLayout() 三个方法中,而它们是不会随意调用的,并不与Vsync信号的频率保持一致,只有当主动调用invalidate() 或 requestLayout() 方法才会进行view重绘。
以requestLayout() 为例,看看为什么view的刷新与底层发送Vsync信号的频率不一致。
requestLayout() 方法在view中实现,
(a)调用自身mParent 的requestLayout() 方法,因为每个view都mParent 对象,会不断向上查找,找到根view,DecorView。
(b) DecorView的parent是ViewRootImpl,两者在activity启动时绑定。
(c)在ViewRootImpl 的requestLayout() 方法中 调用 scheduleTraversals();
(d)scheduleTraversals(); 的核心代码向主线程消息队列设置同步屏障 和 调用 Choreographer.postCallback() 需要注意 mTraversalRunnable 对象,当接收到底层传递的Vsync信号后会被执行。内部调用performTraversals(); 方法,接近100行,巨复杂,会按顺序调用performMeasure() performLayout() performDraw() 执行view绘制流程
//View
public void requestLayout() {
//代码省略
if (mParent != null && !mParent.isLayoutRequested()) {
mParent.requestLayout();
}
}
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();
}
}
void scheduleTraversals() {
if (!mTraversalScheduled) {
mTraversalScheduled = true;
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
final class TraversalRunnable implements Runnable {
@Override
public void run() {
doTraversal();
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
if (mProfile) {
Debug.startMethodTracing("ViewAncestor");
}
performTraversals();
if (mProfile) {
Debug.stopMethodTracing();
mProfile = false;
}
}
}
Choreographer
译名编舞者,跳舞的时候要跟着节拍,底层发出的Vsync信号,就好像舞蹈的节奏一样有条不紊的进行。Choreographer处于view与底层之间连接两者,承上启下,负责UI刷新。
(a)ViewRootImpl调用Choreographer.postCallback(int callbackType, Runnable action, Object token) 方法,重要的一个步骤是把 ViewRootImpl 传递的参数,以callbackType 作为数组的下标 Runnable 作为value, 保存到 类型为CallbackQueue[] 的数组中,
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token) ,收到Vsync信号后从数组中取出执行Runnable 任务
(b)Choreographer.postCallback()最终会调用到 FrameDisplayEventReceiver 的nativeScheduleVsync() 方法(定义在父类中),是一个native方法,作用是向底层注册监听,告诉底层当前应用有UI有更新需要重绘
(c)注册监听之后, FrameDisplayEventReceiver.onVsync() 会收到底层的Vsync信号,主要逻辑发送一条异步消息,FrameDisplayEventReceiver 自身实现Runnable 接口,handle发送异步消息,执行的就是自身run()方法中的逻辑 ,核心代码是doCallbacks()
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable{
@Override
public void onVsync(long timestampNanos, long physicalDisplayId, int frame,
VsyncEventData vsyncEventData) {
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame, mLastVsyncEventData);
}
}
void doFrame(long frameTimeNanos, int frame,
DisplayEventReceiver.VsyncEventData vsyncEventData) {
//省略代码
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos, frameIntervalNanos);
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos, frameIntervalNanos);
doCallbacks(Choreographer.CALLBACK_INSETS_ANIMATION, frameTimeNanos,
frameIntervalNanos);
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos, frameIntervalNanos);
doCallbacks(Choreographer.CALLBACK_COMMIT, frameTimeNanos, frameIntervalNanos);
}
(d) Choreographer.doCallbacks() 要和 Choreographer.postCallback() 结合起来看才合理
postCallback() 添加UI更新任务到数组中,任务大致分为三种:输入事件,动画,UI绘制。根据常量类型就是数组下标。,当Choreographer 接收到底层传递的Vsync信号后,调用doCallbacks() 根据下标从数组取出任务执行。
public static final int CALLBACK_INPUT = 0; //输入事件处理
public static final int CALLBACK_ANIMATION = 1;//处理动画
//处理插入更新的动画 没看到ViewRootImpl中有使用它 不太清楚和 CALLBACK_ANIMATION的区别
public static final int CALLBACK_INSETS_ANIMATION = 2;
public static final int CALLBACK_TRAVERSAL = 3;//UI绘制,measure,layout,draw
public static final int CALLBACK_COMMIT = 4;//不太清楚它的作用
//初始化CallbackQueue数组使用
private static final int CALLBACK_LAST = CALLBACK_COMMIT;
private final CallbackQueue[] mCallbackQueues;
private Choreographer(Looper looper, int vsyncSource) {
mCallbackQueues = new CallbackQueue[CALLBACK_LAST + 1];
for (int i = 0; i <= CALLBACK_LAST; i++) {
mCallbackQueues[i] = new CallbackQueue();
}
}
void doCallbacks(int callbackType, long frameTimeNanos, long frameIntervalNanos) {
CallbackRecord callbacks;
synchronized (mLock) {
//省略代码
callbacks = mCallbackQueues[callbackType].extractDueCallbacksLocked(
now / TimeUtils.NANOS_PER_MS);
}
}
public void postCallback(int callbackType, Runnable action, Object token) {
//省略代码 与 方法调用
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
}
(4)Choreographer流程总结
(a)底层根据屏幕刷新率按时发送Vsync信号
(b)应用通过调用requestLayout() ,invalidate() 或 动画等表明自己当前需要更新
(c)ViewRootImpl 内定义更新逻辑,如TraversalRunnable 定义UI绘制逻辑。当代码执行requestLayout() ,invalidate() 时把任务投递到Choreographer 内部的任务数组中
(d)Choreographer 可以接收:输入事件,动画,UI绘制三种任务,但不是立即执行,先将它们保存到数组中。同时Choreographer 调用native方法向底层注册Vsync信号监听
(e)Choreographer 收到Vsync信号回调,按照数组顺序依次执行任务,输入事件优先级最高,其次是动画,最后是UI绘制。 在UI绘制阶段通过view树层层调用measure,layout,draw
(f)整个流程说白了就是定义任务,监听事件,执行任务
偷一张代码流程图
屏幕刷新机制还有很多细节没有讲,屏幕的双缓存,Choreographer代码细节等可以看参考中的文章学习
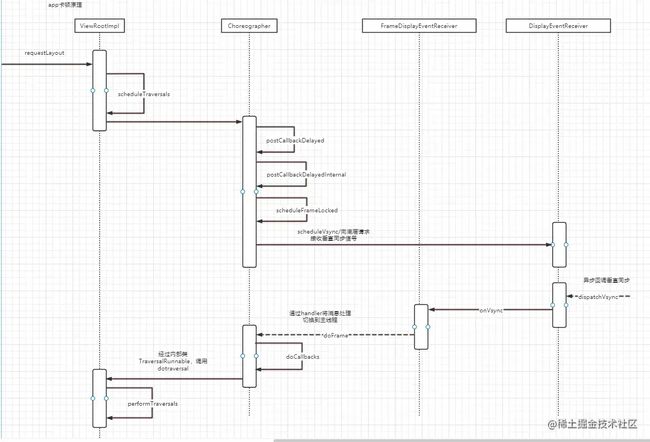
(5)Handler同步屏障和异步消息
在Handler消息队列每条消息按顺序逐个执行,假设此时接收到了Vsync信号,向主线程中投递了几个绘制相关的消息。但是消息队列中已经有10个消息了,如果仍然按照正常逻辑逐个执行等前面所有的消息执行完毕才会轮到绘制相关的消息执行,肯定是不合理的。
不能确定前面的消息何时执行完毕,没准任务非常复杂耗时很久。就算不耗时,轻微的等待对于绘制影响也是巨大的。绘制一旦响应的慢了,在用户看来就是系统交互太慢了,差评!
所以为了即使处理绘制这种重要消息,设计出了同步屏障 和 异步消息机制。
异步消息设置方式如下,单独使用异步消息没啥用,必须结合同步屏障一起使用
val handler = Handler(Looper.getMainLooper())
val msg = handler.obtainMessage()
msg.isAsynchronous= true
同步屏障通过MessageQueue.postSyncBarrier() 开启,向队列头部添加一个没有target的(target==null)的message。
很遗憾MessageQueue.postSyncBarrier() 方法是私有方法,不能允许开发者调用。想想也合理,开发层面有什么紧急的任务非要和应用重绘这种系统任务抢地盘?
public int postSyncBarrier() {
return postSyncBarrier(SystemClock.uptimeMillis());
}
private int postSyncBarrier(long when) {
// Enqueue a new sync barrier token.
// We don't need to wake the queue because the purpose of a barrier is to stall it.
synchronized (this) {
final int token = mNextBarrierToken++;
final Message msg = Message.obtain();
msg.markInUse();
msg.when = when;
msg.arg1 = token;
Message prev = null;
Message p = mMessages;
if (when != 0) {
while (p != null && p.when <= when) {
prev = p;
p = p.next;
}
}
if (prev != null) { // invariant: p == prev.next
msg.next = p;
prev.next = msg;
} else {
msg.next = p;
mMessages = msg;
}
return token;
}
}
在MessageQueue的next()方法关于消息的处理逻辑
if (msg != null && msg.target == null) 判断是否开启同步屏障
循环条件判断 while (msg != null && !msg.isAsynchronous())
Message next() {
//省略代码
Message msg = mMessages;
if (msg != null && msg.target == null) {
// Stalled by a barrier. Find the next asynchronous message in the queue.
do {
prevMsg = msg;
msg = msg.next;
} while (msg != null && !msg.isAsynchronous());
}
if (msg != null) {
if (now < msg.when) {
// Next message is not ready. Set a timeout to wake up when it is ready.
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// Got a message.
mBlocked = false;
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
if (DEBUG) Log.v(TAG, "Returning message: " + msg);
msg.markInUse();
return msg;
}
} else {
// No more messages.
nextPollTimeoutMillis = -1;
}
}
在ViewRootImpl 中,开始绘制任务之前开启同步屏障,借此保证Choreographer.FrameHandler 发出的消息能够快速响应执行任务。
当任务结束或取消移除同步屏障,保证其他消息顺利进行。
// ViewRootImpl
void scheduleTraversals() {
if (!mTraversalScheduled) {
//开启同步屏障
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
void unscheduleTraversals() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
mChoreographer.removeCallbacks(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
}
}
void doTraversal() {
if (mTraversalScheduled) {
mTraversalScheduled = false;
//移除同步屏障
mHandler.getLooper().getQueue().removeSyncBarrier(mTraversalBarrier);
}
}
//Choreographer
private final class FrameHandler extends Handler {
public FrameHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case MSG_DO_FRAME:
doFrame(System.nanoTime(), 0, new DisplayEventReceiver.VsyncEventData());
break;
case MSG_DO_SCHEDULE_VSYNC:
doScheduleVsync();
break;
case MSG_DO_SCHEDULE_CALLBACK:
doScheduleCallback(msg.arg1);
break;
}
}
}
(6)卡帧原理
为什么布局复杂会卡帧?主线程执行耗时操作会卡帧?
布局复杂,层级过多相应的计算view树数据的时间也会增加,view的绘制是在主线程进行的。如果不能在16.6ms内完成就会影响一下次绘制消息的处理。
虽然有同步屏障机制,但是如果主线程执行耗时操作超过16.6ms一致被占用,即便有同步屏障机制,但是也要当前消息执行完毕才会生效,也会出现掉帧的情况
主线程一次只能做一件事,处理耗时任务导致没有处理屏幕刷新的绘制任务,屏幕数据无法更新,产生掉帧现象
三,BlockCanary
经过上述卡帧原理分析可以得知,核心的绘制消息都是在主线程消息队列中处理的,当屏幕有重绘需求的时候,按照手机屏幕刷新率60Hz,每16.6ms刷新一帧画面有条不紊的进行。
在主线程进行耗时操作,影响了屏幕刷新的节奏,并不能准时执行每16.6ms一次的界面重绘,就会产生掉帧现象。
在优化性能时,检测寻找问题点比解决问题要麻烦的多。想靠人工在一行一行的代码中寻找耗时点是不可能的。
BlockCanary是Android平台的性能监控框架,能够找出主线程的耗时操作避免卡帧,核心原理并不复杂,非常巧妙。
BlockCanary分为两部分,检测耗时 和 耗时方法信息输出
(1)检测耗时
利用Handler消息机制实现,Looper线程唯一,无论有多少个Handler向主线程中发送消息都会走到同一个Looper中。
在Looper的loop() 方法中,msg.target.dispatchMessage() 是分发处理消息的位置,如果两次dispatchMessage() 调用时间间隔过长,就表明有耗时操作,出现掉帧情况需要优化。
那么如何判断dispatchMessage() 方法的执行时长呢?而且要监听到所有在主线程执行的消息。
在Looper源码中,dispatchMessage() 方法调用前后,Printer.println() 调用进行日志输出,默认情况下Printer 对象为null,可以通过setMessageLogging()方法设置
//自定义Printer
handler.looper.setMessageLogging(object :Printer{
override fun println(x: String?) {
}
})
//Looper源码
private Printer mLogging;
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
public void setMessageLogging(@Nullable Printer printer) {
mLogging = printer;
}
在blockcanary中 定义LooperMonitor 类 实现Printer 接口,监听dispatchMessage() 方法调用耗时,核心代码如下
(a)通过变量mPrintingStarted 判断是在dispatchMessage() 方法前调用还是在方法后调用
(b)保存第一次调用时间mStartTimestamp
(c)通过判断开始时间与结束时间的差值,是否超过预定义的卡帧阈值,判断是否产生耗时操作
代码真的非常简单,知道原理的同学分分可以自定义一个。
@Override
public void println(String x) {
if (mStopWhenDebugging && Debug.isDebuggerConnected()) {
return;
}
if (!mPrintingStarted) {
mStartTimestamp = System.currentTimeMillis();
mStartThreadTimestamp = SystemClock.currentThreadTimeMillis();
mPrintingStarted = true;
startDump();
} else {
final long endTime = System.currentTimeMillis();
mPrintingStarted = false;
if (isBlock(endTime)) {
notifyBlockEvent(endTime);
}
stopDump();
}
}
private boolean isBlock(long endTime) {
return endTime - mStartTimestamp > mBlockThresholdMillis;
}
(2)耗时方法信息输出
定位到那个方法有耗时操作后,BlockCanary利用线程API获取主线程堆栈,打印后可以到方法调用信息
val startTrace = Thread.currentThread().stackTrace
val sbInfo = StringBuilder()
for (item:StackTraceElement in startTrace) {
sbInfo.append(item.toString())
sbInfo.append("\n")
}
Log.d(TAG,sbInfo.toString())
//输出日志如下 方法在 RegisterActivity.onCreate() 方法中调用
D/aaa: dalvik.system.VMStack.getThreadStackTrace(Native Method)
java.lang.Thread.getStackTrace(Thread.java:1538)
com.example.module.user.register.RegisterActivity.onCreate(RegisterActivity.kt:35)
android.app.Activity.performCreate(Activity.java:7232)
android.app.Activity.performCreate(Activity.java:7221)
android.app.Instrumentation.callActivityOnCreate(Instrumentation.java:1272)
android.app.ActivityThread.performLaunchActivity(ActivityThread.java:2965)
android.app.ActivityThread.handleLaunchActivity(ActivityThread.java:3120)
android.app.servertransaction.LaunchActivityItem.execute(LaunchActivityItem.java:78)
android.app.servertransaction.TransactionExecutor.executeCallbacks(TransactionExecutor.java:108)
android.app.servertransaction.TransactionExecutor.execute(TransactionExecutor.java:68)
android.app.ActivityThread$H.handleMessage(ActivityThread.java:1840)
android.os.Handler.dispatchMessage(Handler.java:106)
android.os.Looper.loop(Looper.java:207)
android.app.ActivityThread.main(ActivityThread.java:6878)
java.lang.reflect.Method.invoke(Native Method)
com.android.internal.os.RuntimeInit$MethodAndArgsCaller.run(RuntimeInit.java:547)
com.android.internal.os.ZygoteInit.main(ZygoteInit.java:876)
为了帮助到大家更好的全面清晰的掌握好性能优化,准备了相关的核心笔记(还该底层逻辑):https://qr18.cn/FVlo89
性能优化核心笔记:https://qr18.cn/FVlo89
启动优化

内存优化

UI优化
网络优化

Bitmap优化与图片压缩优化:https://qr18.cn/FVlo89

多线程并发优化与数据传输效率优化
体积包优化
《Android 性能监控框架》:https://qr18.cn/FVlo89

《Android Framework学习手册》:https://qr18.cn/AQpN4J
- 开机Init 进程
- 开机启动 Zygote 进程
- 开机启动 SystemServer 进程
- Binder 驱动
- AMS 的启动过程
- PMS 的启动过程
- Launcher 的启动过程
- Android 四大组件
- Android 系统服务 - Input 事件的分发过程
- Android 底层渲染 - 屏幕刷新机制源码分析
- Android 源码分析实战
