Sentinel实现熔断与限流
文章目录
-
- 一、Sentinel是什么
-
- 1、简介
- 2、对比
- 3、Linux安装
- 二、初始化演示工程
-
- 1、新建module:cloudalibaba-sentinel-service8401
- 2、pom文件
- 3、application.yml
- 4、启动类
- 5、流控业务类
- 6、测试
- 三、监控
-
- 1、实时监控
- 2、簇点链路
- 四、流控规则
-
- 1、QPS限流
- 2、线程数限流
- 3、关联限流
- 4、链路限流
- 5、流控效果
-
- (1)WarmUp
- (2)匀速排队
- 五、熔断规则
-
- 1、慢调用比例
- 2、异常比例
- 3、异常数
- 六、异常处理
-
- 1、fallback方法
- 2、blockHolder方法
- 3、fallback和blockHolder方法的区别
- 4、优化代码实现解耦
- 5、通用降级处理方法
一、Sentinel是什么
1、简介
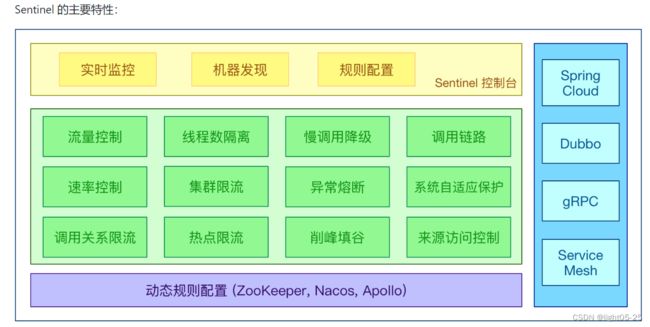
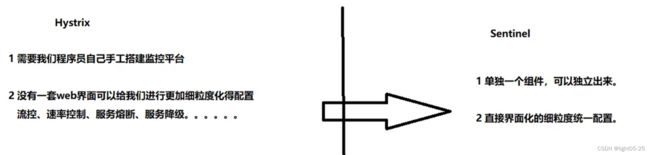
随着微服务的流行,服务和服务之间的稳定性变得越来越重要。Sentinel 以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应过载保护、热点流量防护等多个维度保护服务的稳定性。其实说白了就是SpringCloud Hystrix的升级版。
关于Hystrix可以查看我的另外一篇文章:SpringCloud之Hystrix断路器
Sentinel官网:Sentinel官网
GitHub地址:https://github.com/alibaba/Sentinel
中文文档:Sentinel中文文档
2、对比
3、Linux安装
先到GitHub进行下载jar并上传Linux:下载版本
注意:启动 Sentinel 控制台需要 JDK 版本为 1.8 及以上版本。
使用如下命令启动控制台:
#直接启动:
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar
#后台启动:
nohup java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar > sentinelLog.txt 2>&1 &
其中 -Dserver.port=8080 用于指定 Sentinel 控制台端口为 8080。
从 Sentinel 1.6.0 起,Sentinel 控制台引入基本的登录功能,默认用户名和密码都是 sentinel。
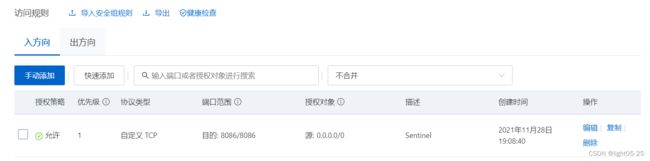
阿里云服务器需要在《网络与安全》—《安全组》中开放Sentinel的端口(我这里的端口为8086)
注意!!!!!!!!!!!!
云服务器上的sentinel可以监测到你的服务,但是做不到熔断和降级等操作,你必须得保证你的项目和sentinel能够双向访问才行,内网穿透也没用,别问我怎么知道的 (╥﹏╥)(╥﹏╥)(╥﹏╥)
解决方案:
1、将微服务和sentinel部署在相同的服务器上
2、将微服务部署到另一个服务器上,然后将该服务器加入到sentinel服务器中,微服务的那个服务器开放8719端口
浏览器直接访问:http://localhost:8080/,默认用户名和密码都是 sentinel。

登陆后的页面:

二、初始化演示工程
1、新建module:cloudalibaba-sentinel-service8401
2、pom文件
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discoveryartifactId>
<exclusions>
<exclusion>
<groupId>org.yamlgroupId>
<artifactId>snakeyamlartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
<version>2.7.1version>
<exclusions>
<exclusion>
<groupId>org.yamlgroupId>
<artifactId>snakeyamlartifactId>
exclusion>
exclusions>
dependency>
<dependency>
<groupId>org.yamlgroupId>
<artifactId>snakeyamlartifactId>
<version>1.30version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
<version>2.7.1version>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.24version>
<scope>providedscope>
dependency>
dependencies>
3、application.yml
我这里sentinel的端口修改成了8086,后续不再强调
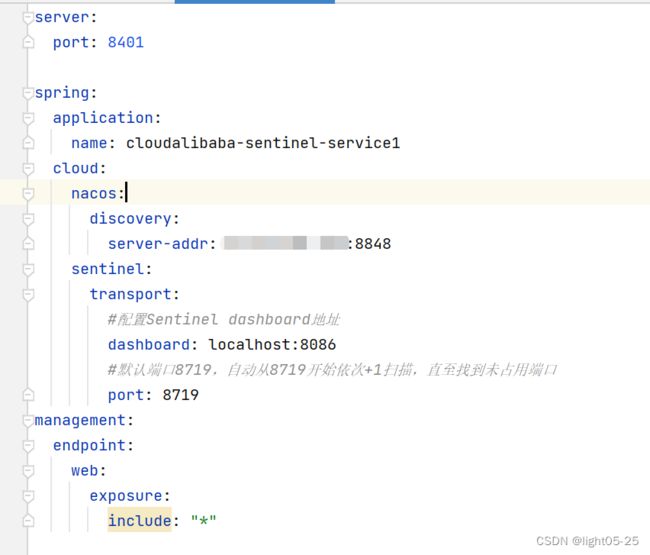
spring.cloud.sentinel.transport.port:指定应用与Sentinel控制台交互的端口,应用本地会起一个该端口占用的HttpServer
spring.cloud.sentinel.transport.port 端口配置会在应用对应的机器上启动一个 Http Server,该Server 会与 Sentinel 控制台做交互。比如 Sentinel 控制台添加了1个限流规则,会把规则数据 push 给这个Http Server 接收,Http Server 再将规则注册到 Sentinel 中。
4、启动类
@SpringBootApplication
@EnableDiscoveryClient
public class SentinelApplication8401 {
public static void main(String[] args) {
SpringApplication.run(SentinelApplication8401.class,args);
}
}
5、流控业务类
@RestController
@Slf4j
public class FlowLimitController {
@GetMapping("/testA")
public String testA() {
return "------testA";
}
@GetMapping("/testB")
public String testB() {
return "------testB";
}
}
6、测试
-
启动nacos(可省略)
-
启动Sentinel
-
启动服务8401
-
查看Sentinel后发现没有我们的服务

-
访问http://localhost:8401/testB
-
再次刷新Sentinel网址进行查看:
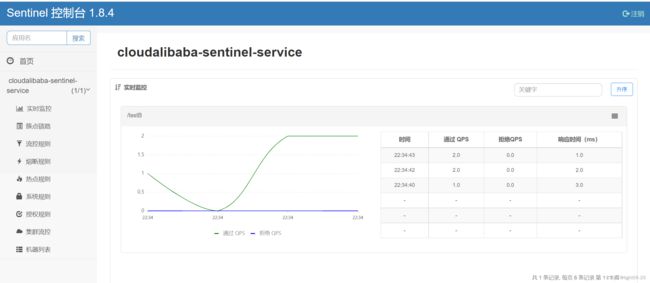
三、监控
1、实时监控
"实时监控"汇总资源信息(集群聚合),同时,同一个服务下的所有机器的簇点信息会被汇总,并且秒级地展示在"实时监控"下。
注意:
1、实时监控仅存储 5 分钟以内的数据,如果需要持久化,需要通过调用实时监控接口来定制。
2、请确保 Sentinel 控制台所在的机器时间与自己应用的机器时间保持一致,否则会导致拉不到实时的监控数据。
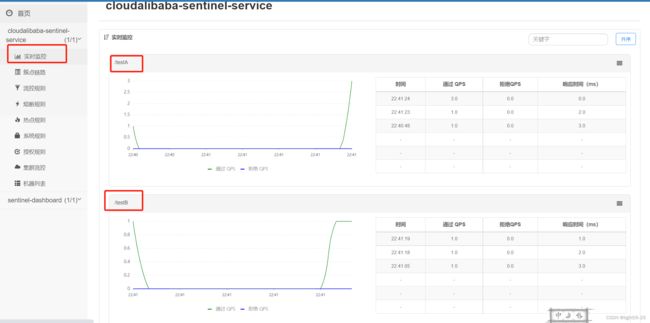
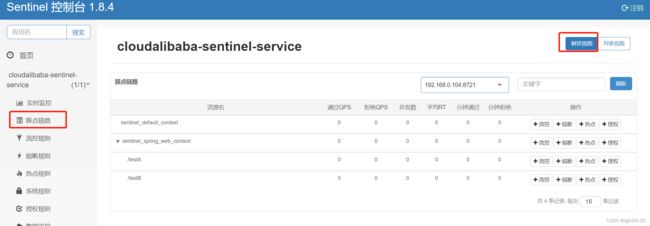
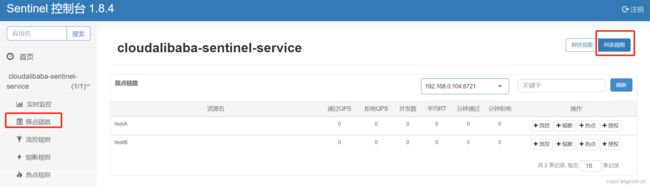
2、簇点链路
簇点链路(单机调用链路)页面实时的去拉取指定客户端资源的运行情况。它一共提供两种展示模式:一种用树状结构展示资源的调用链路,另外一种则不区分调用链路展示资源的运行情况。
注意: 簇点监控是内存态的信息,它仅展示启动后调用过的资源。
四、流控规则
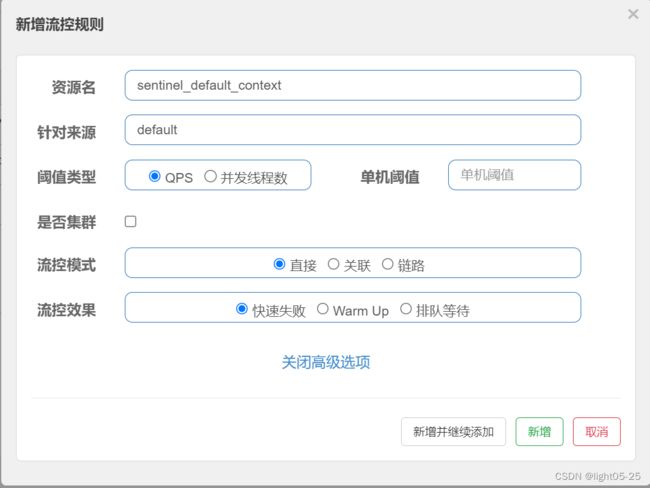
1、QPS限流
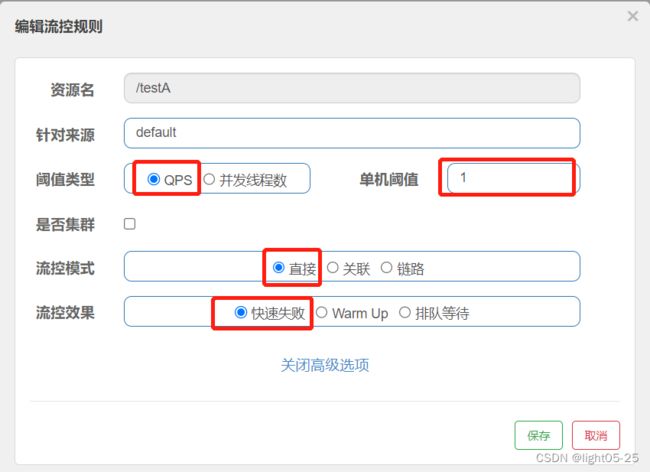
1)配置内容
- 资源名称:表示我们针对哪个接口资源进行流控规则配置,如:“/testA”
- 针对来源:表示针对哪一个服务访问当前接口资源的时候进行限流,default表示不区分访问来源。如填写服务名称:aservice-xxxx,表示aservice-xxxx访问前接口资源的时候进行限流,其他服务访问该接口资源的时候不限流。(但是这个可能有坑,而且不建议针对来源的配置存在多个,这样会增大匹配的数量,从而影响性能)
- 阈值类型/单机阈值:QPS,每秒钟请求数量。上图配置表示每秒钟超过1次请求的时候进行限流。
- 流控模式:直接,当达到限流标准时就直接限流
- 流控效果:快速失败。很简单的说就是达到限流标准后,请求就被拦截,直接失败。(HTTP状态码:429 too many request)
- 是否集群:默认情况下我们的限流策略都是针对单个服务的,sentinel提供了集群限流的功能。笔者个人意见是:除非你的微服务规模特别大,一般不要使用集群模式。集群模式需要各节点与token server交互才可以,会增加网络交互次数,一定程度上会拖慢你的服务响应时间。
上面的限流规则用一句话说:对于任何来源的请求,当超过每秒1次的标准之后就直接限流,访问失败抛出异常(BlockException)!
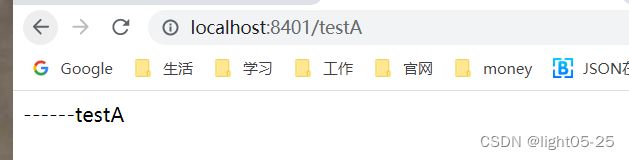
2)测试
一秒钟请求一次,响应正常:
一秒钟请求多次,响应失败数据:
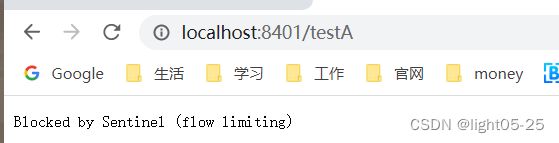
证明QPS限流规则生效,被限制的请求直接返回失败数据!
2、线程数限流
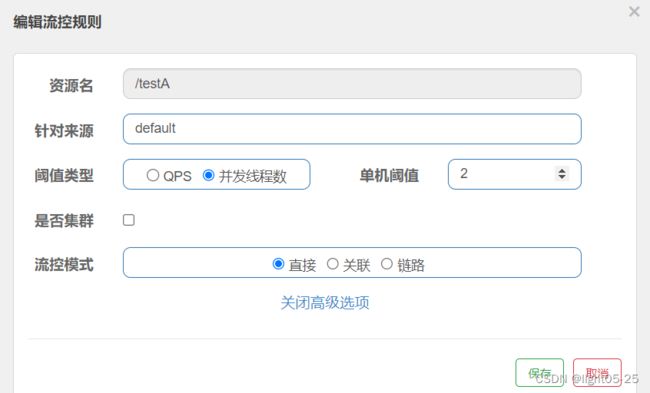
1)配置
- 资源名称:表示我们针对哪个接口资源进行流控规则配置,如:“/testA”
- 针对来源:表示针对哪一个服务访问当前接口资源的时候进行限流,default表示不区分访问来源。如填写服务名称:aservice-xxxx,表示aservice-xxxx访问前接口资源的时候进行限流,其他服务访问该接口资源的时候不限流。
- 阈值类型/单机阈值:线程数。表示开启n个线程处理资源请求。
- 流控模式:直接,当所有线程都被占用时,新进来的请求就直接限流
- 流控效果:快速失败。很简单的说就是达到限流标准后,请求就被拦截,直接失败。(HTTP状态码:429 too many request)
上面的限流规则用一句话说:对于任何来源的请求,服务端“/testA”资源接口的2个线程都被占用的时候,其他访问失败!
2)测试
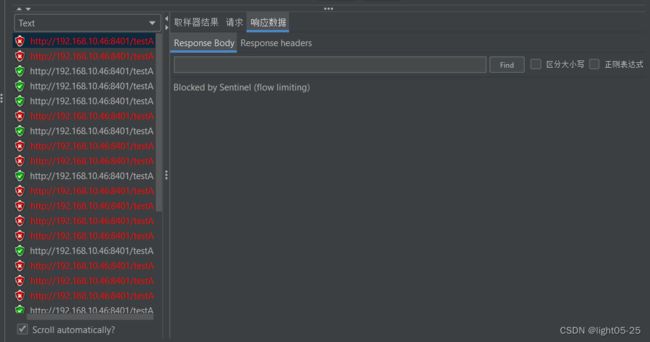
3、关联限流
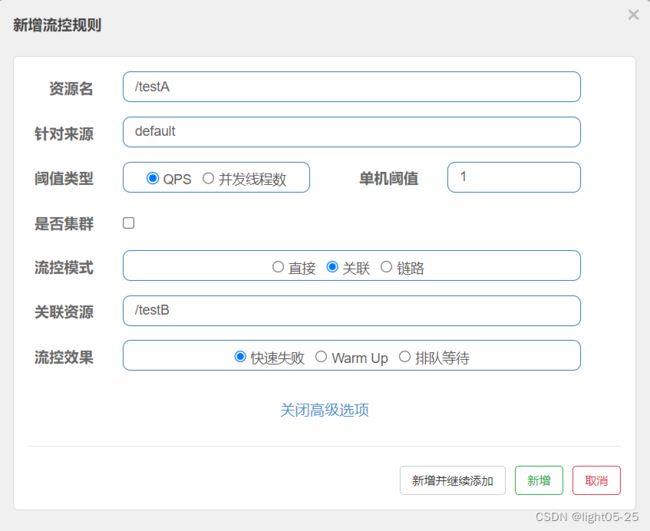
1)配置
- 对关联资源接口“/testB”使用QPS的限流规则,每秒钟只处理一个请求。(这个规则只是一个统计标准,并不会对“/testB”真的限流)
- 当大量的并发请求达到“/testB”关联资源接口的限流标准的时候,“/testA”资源将被限流。流控效果是快速失败。
需要注意的是:
- 在关联限流配置中,虽然我们对关联资源“/testB”进行了限流规则配置,但该配置对“/testB”并不生效。
- sentinel会统计请求流量,根据流量是否触发关联资源“/testB”的限流标准,去限制“/testA”资源。
大家注意不要把限流关系弄反了!限流规则是为了限制“资源”,而不是“关联资源”!
2)测试
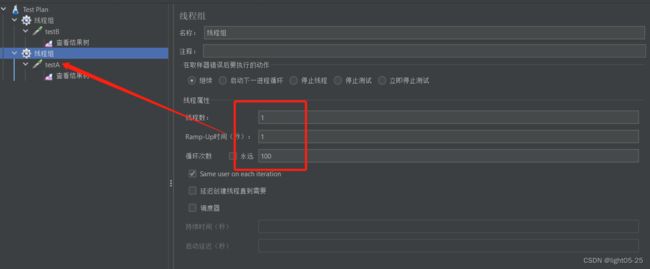
- testB在1秒钟请求2000次(次数根据电脑性能定)
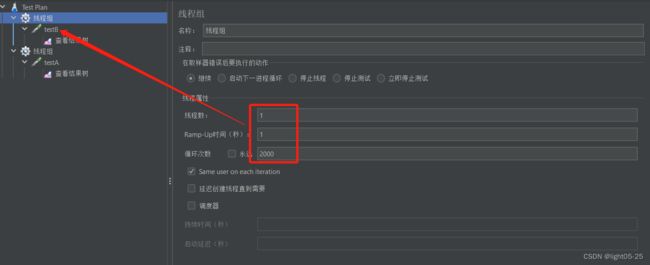
- testA在一秒钟请求100次,确保能抓到testB对testA的影响数据
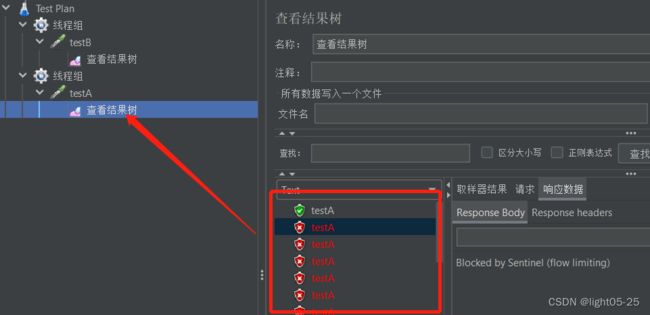
- 两个线程组同时启动,测试结果如下:
第一次显示正常是因为此时testB请求还没达到阈值,所以显示正常
4、链路限流
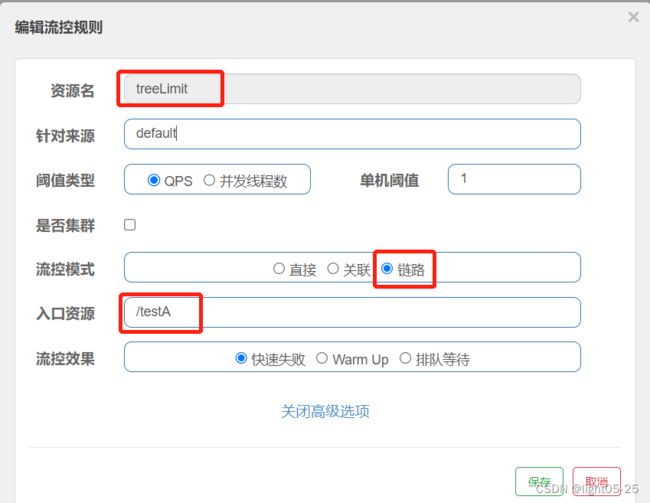
1)配置
- 我们针对treeLimit资源进行流控规则配置,入口为:"/testA”。
- 期望实现的效果是从"/testA”访问treeLimit资源被限流,从“/testB”入口访问treeLimit资源不被限流。
2)编码
service中添加@SentinelResource,当服务被限流后调用blockHandler中的方法

controller调用service中的方法
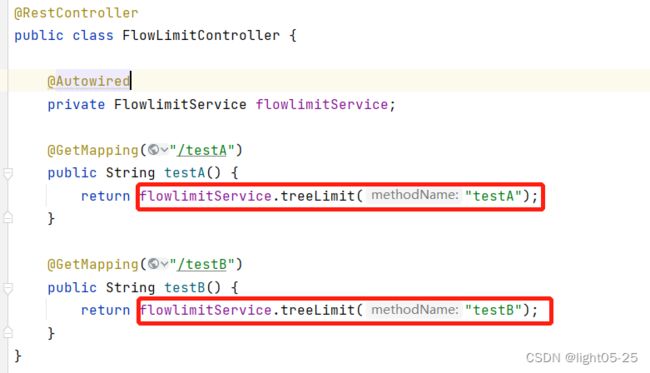
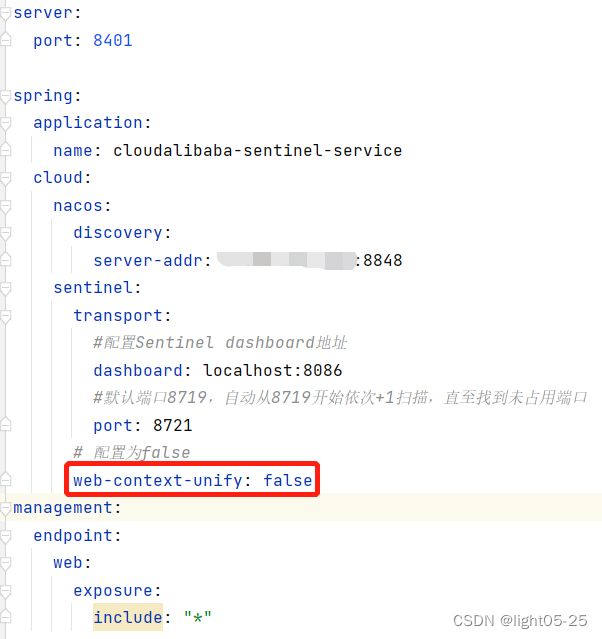
注意添加application.yml中的配置,不然链路流控会失效!!!!
3)测试
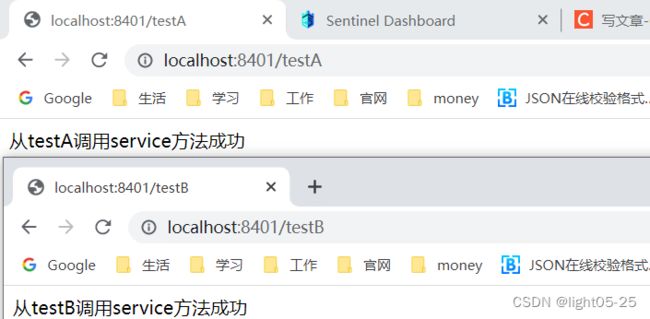
- 一秒一次请求testA和testB都响应正常:
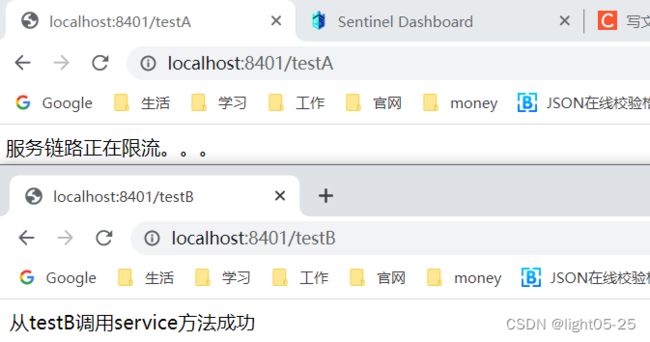
- 频繁一秒内多次请求testA和testB,testA响应流控效果,testB响应正常:
5、流控效果
之前的章节主要为大家介绍流控规则的配置,其中流控规则中的流控效果配置有三种(目前版本1.8.4只有当阈值类型为QPS时才可以选择流控效果):
- 快速失败:就是流量达到阀值或线程量占满,直接返回错误报异常
- Warm Up:在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间(本节为大家介绍)
- 匀速排队:让请求以均匀的速度通过,下一节为大家介绍
(1)WarmUp
1)简介
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统流量长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
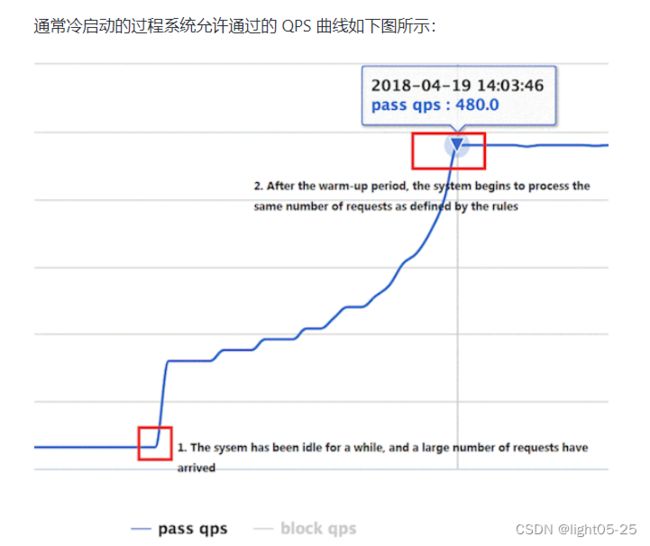
官网案例: 流量控制 - Warm Up 文档
为什么冷系统容易被压垮?
一般在我们系统内部会有线程池,比如:数据库连接线程池。在系统较为空闲的时候,数据库连接线城池内只有少量的连接。假设突然大量的请求并发而至,数据库连接池会去创建新的连接,用来支撑高并发请求。但是这个连接创建的过程需要时间,有可能这边连接池内新连接还没创建完成,这些少量的连接支撑不住就会被压垮。
所以在类似这种场景下,Warm Up让流量缓慢爬升,从而给数据库连接池创建连接一个缓冲的时间,就显得非常有必要了!
2)配置
Warm Up配置有三个要素:
- 冷启动因子coldFactoer,默认等于3
- 预热时长(配置项)
- QPS单机阈值(配置项)
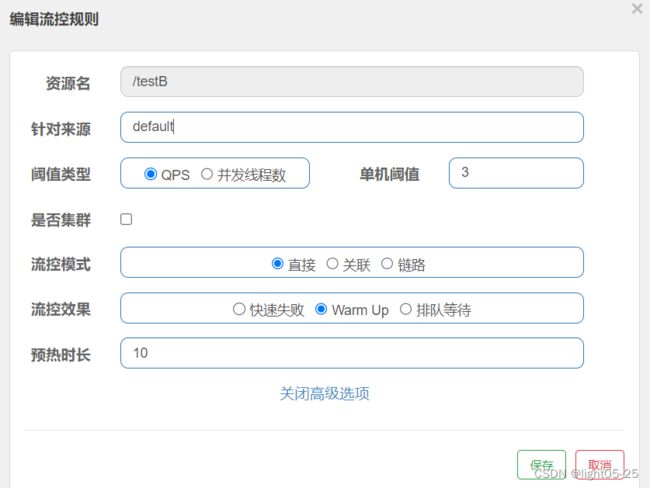
举例:当预热时长=10,QPS单机阈值=3
当并发请求到达的时候,实际的单机阈值是:QPS单机阈值配置/coldFactoer=3/3=1,也就是每秒钟只能一个请求访问成功。
预热时长为10秒,实际的单机阈值在10秒钟内逐步由1 -> 2 -> 3,最终等于QPS单机阈值配置。
3)测试
为了更明显的触发流控规则:配置20秒钟发送60个请求
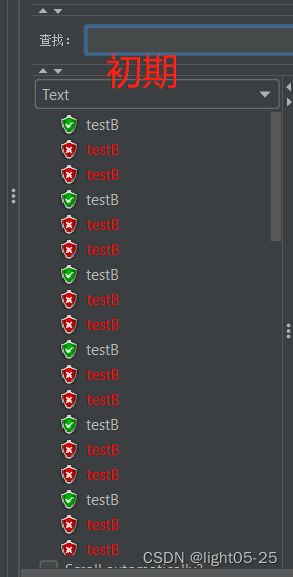
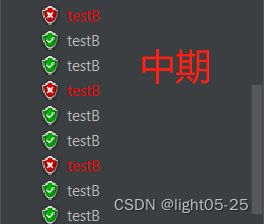
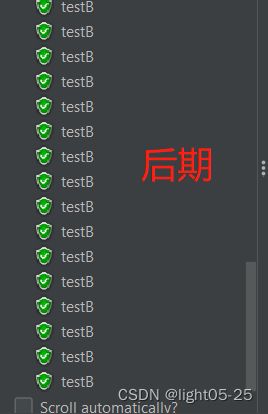
结果:
- 冷启动初期,三个请求能成功一个(单机阈值=1)
- 中期,三个请求能成功2个(单机阈值=2)
- 后期WarmUp限流配置到达阈值3的时候,所有的请求都能被成功处理(单机阈值=3)
但是我在测试中发现一个问题,当请求流量慢慢减少后,阈值好像又会逐步恢复成QPS单机阈值配置/coldFactoer=1,但是我不太确定这个是我自己本身的请求问题,还是确实存在这个问题。
(2)匀速排队
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
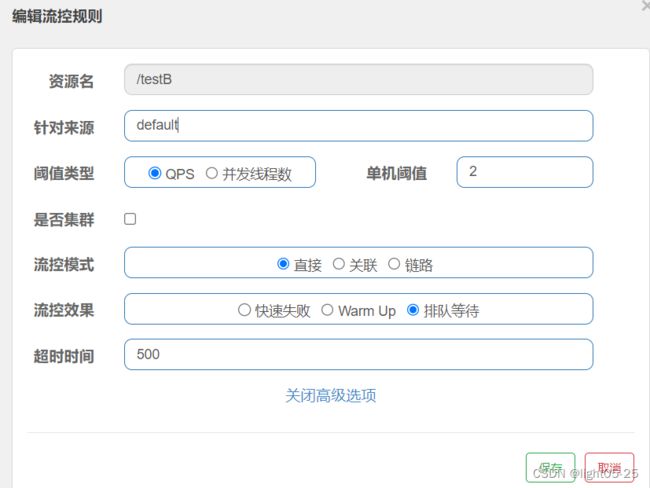
1)配置
上图的配置表示的是:“/testB”资源服务接口,每秒钟匀速通过2个请求。当每秒请求大于2的时候,多余的请求排队等待,等待的时间是500ms。如果500ms以内请求得不到处理,就被限流访问失败!
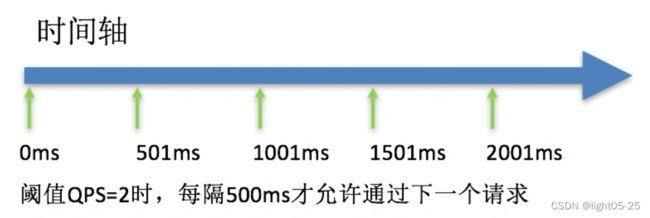
2)配置20秒钟发送60个请求进行测试
当设置请求超时0.5秒时:
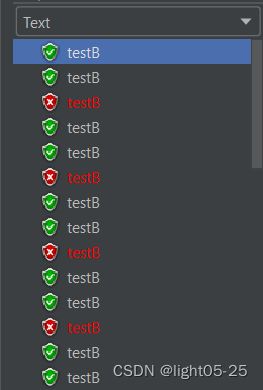
从上图的请求结果可以看出:60个请求20秒发完,平均一秒3个请求,我们配置的匀速通过阈值是2。所以每秒处理2个请求,另外一个请求等待之后超过超时时间0.5秒(500ms),访问失败!
将超时时间调大为5秒:
请求刚开始发送的时候,我们配置的匀速通过阈值是2,所以每秒处理2个请求。先发送的请求先进入排队队列,在5秒之内发送的请求几乎都被成功处理了,后来队列里面的请求积压的越来越多,导致后面不断有请求超时(超过5秒)。
五、熔断规则
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的某一环不稳定,就可能会层层级联,最终导致整个链路都不可用。因此我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。
注意:本文档针对 Sentinel 1.8.0 及以上版本。1.8.0
版本对熔断降级特性进行了全新的改进升级,请使用最新版本以更好地利用熔断降级的能力。
官网文档:Sentinel熔断降级

1、慢调用比例
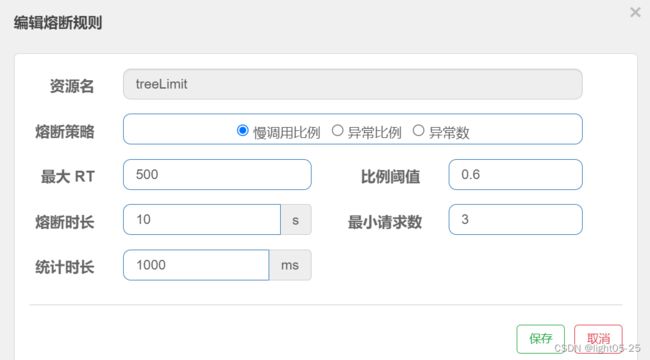
1)配置说明
选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。
当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。
经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
2)测试
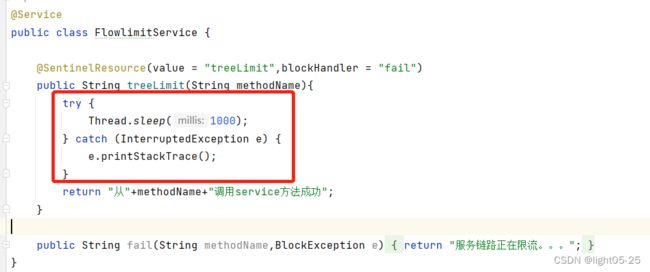
- 先修改service方法,让这个方法的响应时间超过1秒:
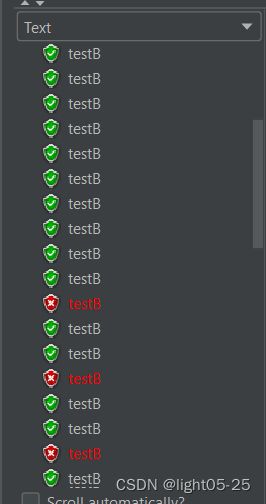
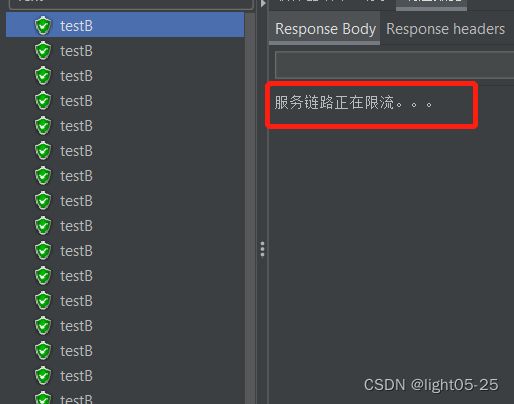
- 在3秒钟内启动20个请求,平均一秒钟6个请求,超过最小请求数3,并且慢调用比例大于0.6,可以看到结果:
3. 等过了设置的熔断时长10s后,再次请求testB,可以看到熔断结束,响应正常:
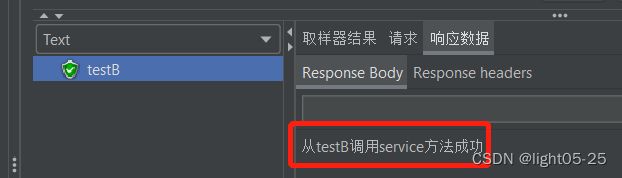
2、异常比例
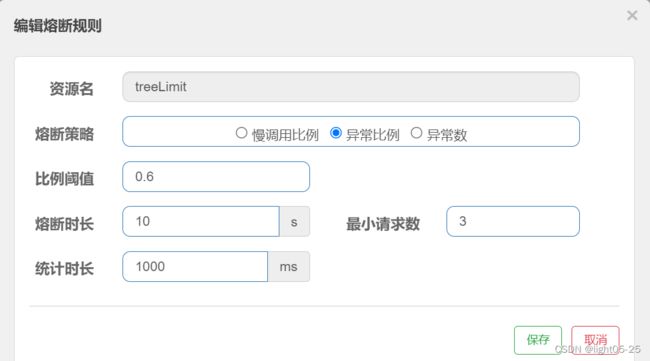
1)配置说明
当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
2)测试
- 还是3秒钟20个请求
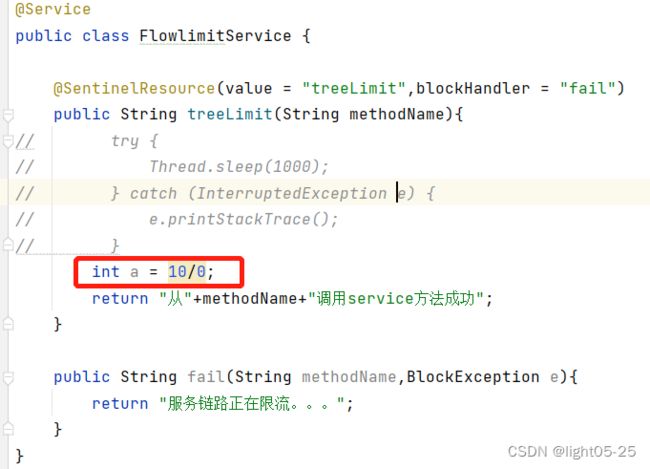
- 修改service方法,模拟出现异常情况:
- 测试结果
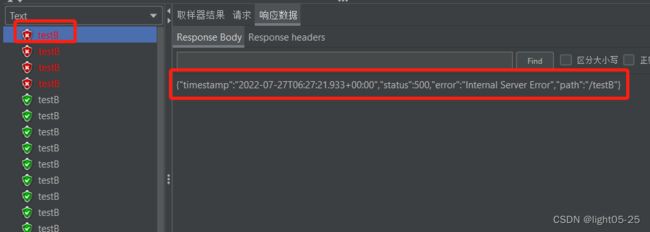
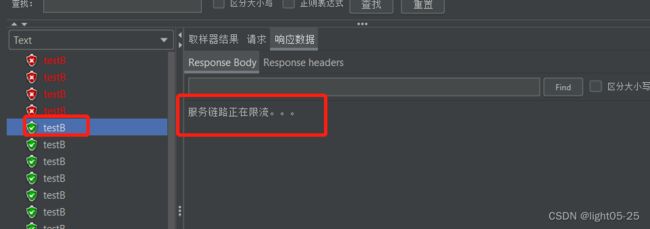
我们可以看到最开始的时候页面响应报错,但是当在一秒钟内请求3次以上且异常比例是0.6以上,Sentinel开启熔断,返回我们自定义友好提示。
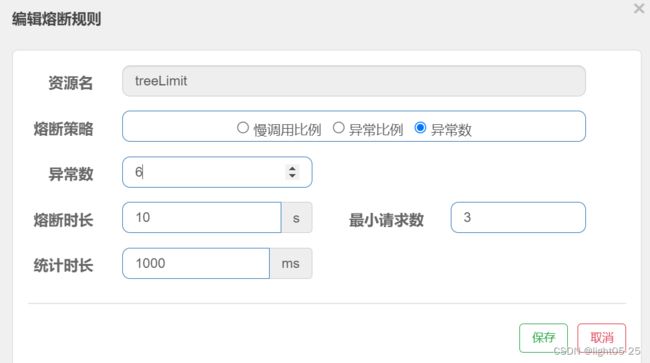
3、异常数
当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
这里请自行测试。。。。。。。
六、异常处理
1、fallback方法
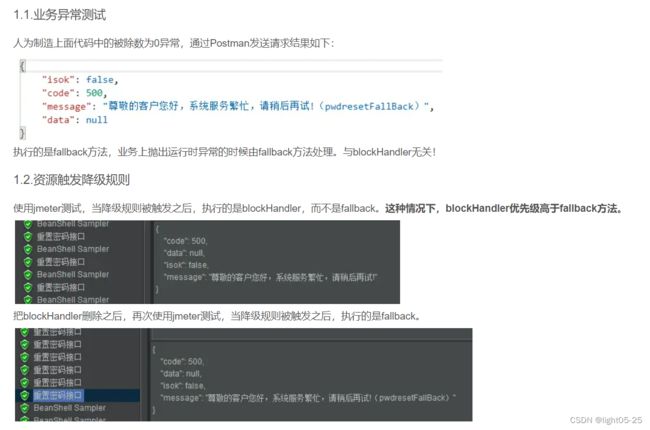
fallback 函数用于两种场景下提供 fallback处理逻辑:
- 业务上抛出运行时异常的时候
- 资源触发降级规则的时候
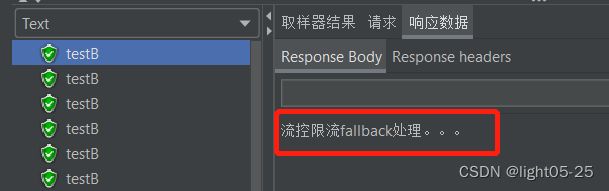
如:下面我们认为制造了被除数为0的异常,会执行fallback方法:flowFail给出响应结果。

- 返回值类型必须与原函数返回值类型一致;
- 方法参数列表需要和原函数一致,或者可以额外多一个Throwable类型的参数用于接收对应的异常。
2、blockHolder方法
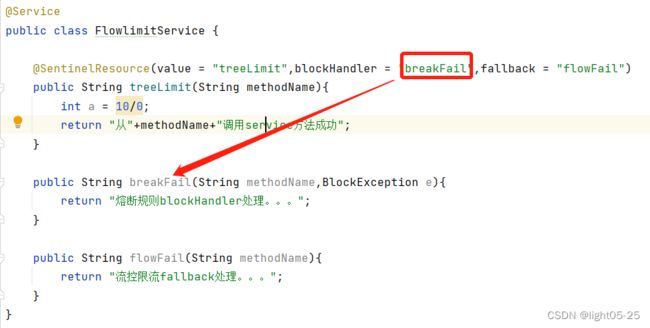
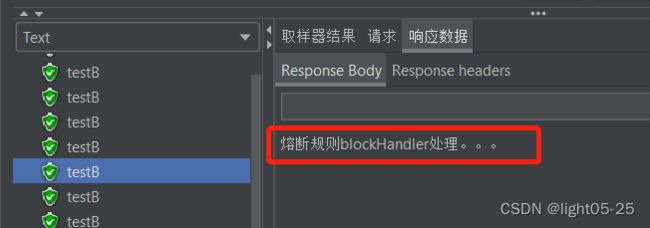
3、fallback和blockHolder方法的区别
注意:
当blockHandler和fallback方法同时定义,且资源触发降级规则的时候,降级处理逻辑由blockHandler来执行。这种情况下,blockHandler优先级高于fallback方法。
4、优化代码实现解耦
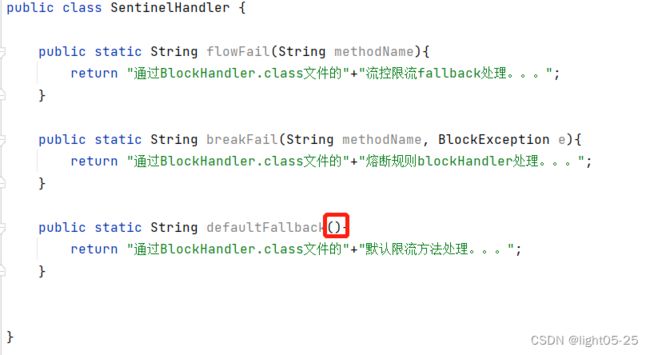
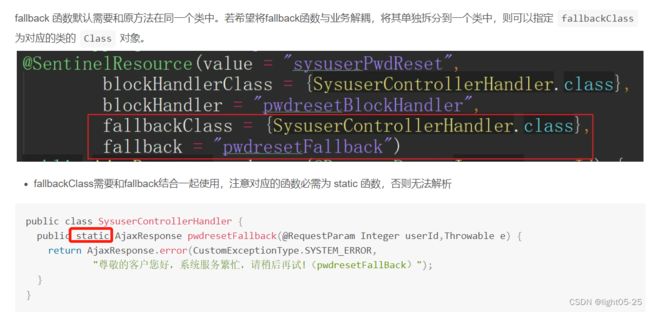
fallback 函数默认需要和原方法在同一个类中。若希望将fallback函数与业务解耦,将其单独拆分到一个类中,则可以指定fallbackClass为对应的类的Class对象。blockHandler同理。
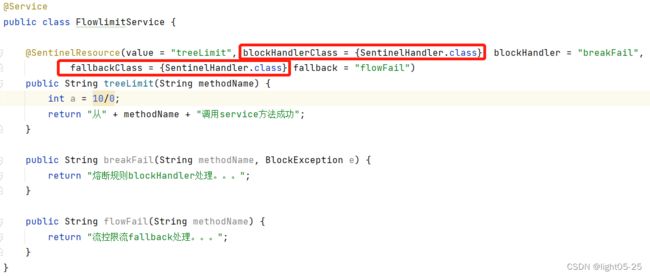
注意这里编写的方法必须是static,否则无法解析


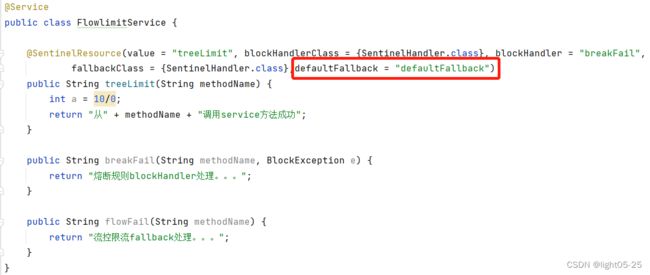
5、通用降级处理方法
- 返回值类型必须与原方法返回值类型一致。
- 方法参数列表需要为空,或者可以额外多一个Throwable类型的参数用于接收对应的异常。
- defaultFallback 方法默认需要和原方法在同一个类中。若希望使用其他类的方法,则可以指定fallbackClass为对应的类的Class对象,注意对应的方法必需为static 方法,否则无法解析。
- 若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效。个性化配置大于通用配置!
- 只要返回值类型一致,在任何的资源上都可以使用defaultFallback,通用!