MySQL开发技巧(一)
文章目录
- MySQL开发技巧(一)
-
- 常用的SQL语句类型:
- 正确使用SQL的重要性:
- join类型
- join从句 -- 内连接 (INNER)
- 左外连接(LEFT OUTER)
- 右外连接(RIGHT OUTER)
- join从句—全连接(Full-Join)
- join从句—交叉连接(cross join)
- 使用join更新表
- 使用join优化子查询
- 使用join优化聚合子查询
- 如何实现分组选择数据
MySQL开发技巧(一)
常用的SQL语句类型:
- DDL 数据定义语言
- TPL 事务处理语言
- DCL 数据控制语言
- DML 数据操作语言
正确使用SQL的重要性:
- 增加数据库处理效率,减少应用相应时间
- 减少数据库服务器负载,增加服务器稳定性
- 减少服务器间通讯的网络流量
join类型
- 内连接(INNER)
- 全外连接(FULL OUTER)
- 左外连接(LEFT OUTER)
- 右外连接(RIGHT OUTER)
- 交叉连接(CROSS)
join从句 – 内连接 (INNER)
西天取经四人组
| id | user_name | over |
|---|---|---|
| 1 | 唐僧 | 旃檀功德佛 |
| 2 | 孙悟空 | 斗战神佛 |
| 3 | 猪八戒 | 净坛使者 |
| 4 | 沙僧 | 金身罗汉 |
悟空的朋友们
| id | user_name | over |
|---|---|---|
| 1 | 孙悟空 | 成佛 |
| 2 | 牛魔王 | 被降服 |
| 3 | 蛟魔王 | 被降服 |
| 4 | 鹏魔王 | 被降服 |
| 5 | 狮驼王 | 被降服 |
内连接
内连接Inner join基于连接谓词将两张表(如A和B)的列组合在一起,产生新的结果表。可以用来交集。

SELECT a.user_name,a.over,b.over FROM user1 a INNER JOIN user2 b ON a.username=b.user_name;
结果:

左外连接(LEFT OUTER)
左外连接有两种形式
一种是包含所有A表中的数据

select a.id,a.user_name, a.over, b.id, b.user_name, b.over
from user1 a
left join user2 b
on a.user_name = b.user_name
结果:
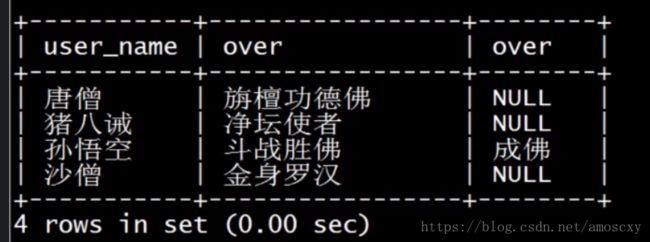
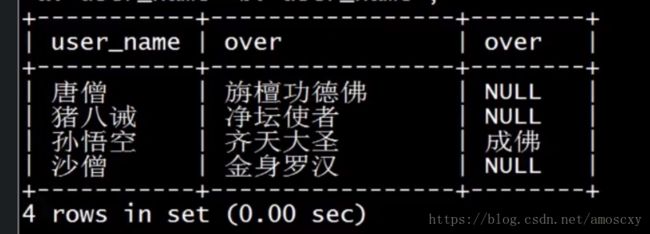
一种是通过左外连接查询出只存在于A表中,不存在与B表中的数据

select a.id,a.user_name, a.over, b.id, b.user_name, b.over
from user1 a
left join user2 b
on a.user_name = b.user_name
where b.user_name is null;
结果:

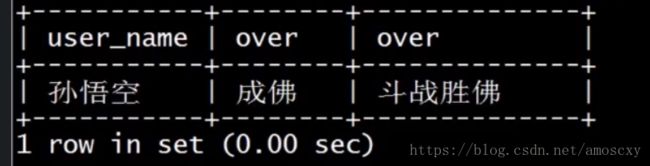
右外连接(RIGHT OUTER)
以右表为基础,查询结果会包好右表中所有的记录。

在悟空朋友中有谁参与的取经:
select b.user_name,b.over,a.over
from user1 a
Right JOIN user2 b
on a.user_name = b.user_name
where a.user_name is not null;
join从句—全连接(Full-Join)
全连接可以查询所有存在于A表和B表中的数据
或者查询只存在A表或B表中的数据
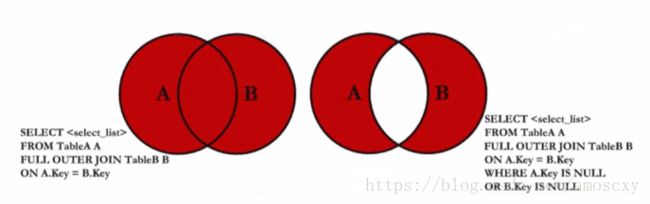
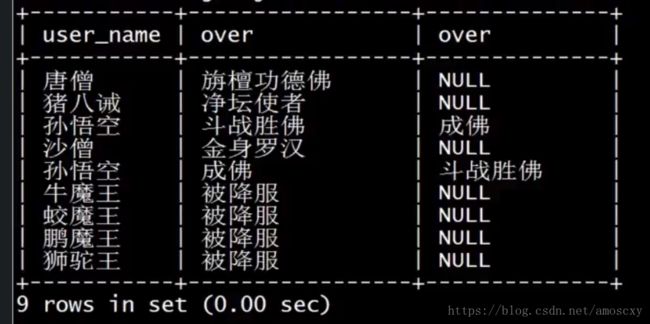
MySQL不支持全连接,可以使用union all来实现
select a.id,a.user_name, a.over, b.id, b.user_name, b.over
from user1 a
left join user2 b
on a.user_name = b.user_name
union all
select a.id,a.user_name, a.over, b.id, b.user_name, b.over
from user1 a
right join user2 b
on a.user_name = b.user_name;
结果:
join从句—交叉连接(cross join)
交叉连接(cross join),又称笛卡尔连接(cartesian join)或叉乘,如果A和B是连个集合,他们的交叉连接即为AXB
不需要提供连接关键词从句
select * from user1 a cross join user2 b;
使用join更新表
如何更新包含在from从句中的表?
如下,把user1中的over字段改为’齐天大圣’,过滤条件使用了user1
UPDATE user1
SET
over = '齐天大圣'
WHERE
user1.user_name IN (SELECT
b.user_name
FROM
user1 a
INNER JOIN
user2 b ON a.user_name = b.user_name);
在MySQL中执行会出错:
Error Code: 1093. Table 'user1' is specified twice, both as a target for 'UPDATE' and as a separate source for data
原因是:
if you're doing an UPDATE/INSERT/DELETE on a table, you can't reference that table in an inner query (you can however reference a field from that outer table...)
所以正确的做法可以是:
update user1 a join (
select b.user_name
from user1 a inner join user2 b on
a.user_name = b.user_name
) b on a.user_name = b.user_name
set a.over = '齐天大圣';
或者
update user1 a inner join user2 b on a.user_name = b.user_name set a.over='齐天大圣';

使用join优化子查询
如下使用了子查询语句,子查询比较耗时,可以使用join来优化子查询
select a.user_name, a.over, (
select over from user2 b where a.user_name = b.user_name
) as over2
from user1 a;
a表中的每一条记录都要进行子查询,非常低效
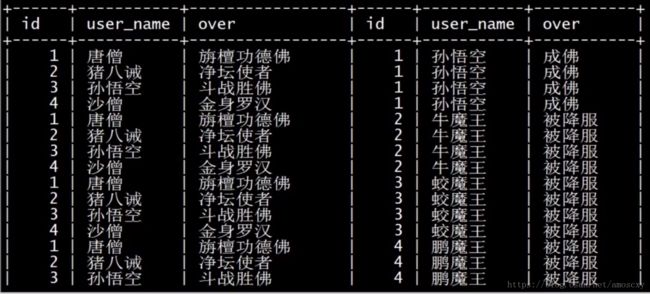
如果使用join连接,查询的结果一样,但是所用的时间更少
select a.user_name, a.over, b.over as over2
from user1 a
left join user2 b on
a.user_name = b.user_name;
结果:
使用join优化聚合子查询
如何查询出四人组中打怪最多的日期?
引入一张新表,按日期记录四人组中每个人打怪的数量
表3 user_kills
| id | user_id | Timestr | kills |
|---|---|---|---|
| 1 | 3 | 2013-01-10 00:00:00 | 10 |
| 2 | 3 | 2013-02-01 00:00:00 | 2 |
| 3 | 3 | 2013-02-05 00:00:00 | 12 |
| 4 | 4 | 2013-01-10 00:00:00 | 3 |
| 5 | 3 | 2013-02-11 00:00:00 | 5 |
| 6 | 3 | 2013-02-06 00:00:00 | 1 |
| 7 | 2 | 2013-01-11 00:00:00 | 20 |
| 8 | 3 | 2013-02-12 00:00:00 | 10 |
| 9 | 3 | 2013-02-07 00:00:00 | 17 |
原始方法如下:
select a.user_name, b.timestr, b.kills
from user1 a join user_kills b
on a.id = b.user_id
where b.kills=(select max(c.kills) from user_kills c where c.user_id=b.user_id);

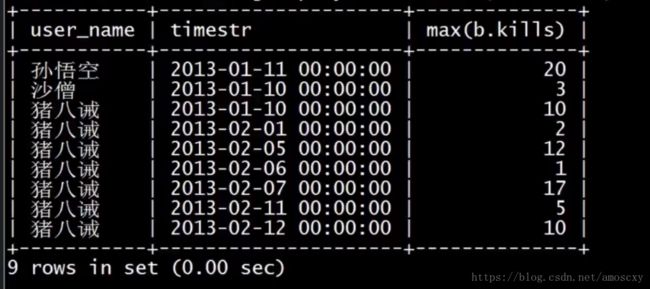
验证不使用子查询只使用MAX()不正确
SELECT a.user_name,b.timestr,max(b.kills) from user1 a join user_kills b on a.id = b.user_id group by a.user_name,b.timestr;
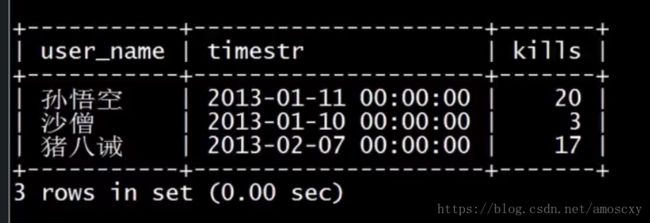
如何查询出四人组中打怪最多的日期?(避免子查询)
select a.user_name, b.timestr, b.kills
from user1 a
join user_kills b on a.id = b.user_id
join user_kills c on c.user_id = b.user_id
group by a.user_name, b.timestr, b.kills
having b.kills = max(c.kills);
使用了两次join,一次为了查询出时间和数量,另一次为了在having从句中使用来得出最大的数量是多少
如何实现分组选择数据
一些记录可以分成多个组,在每个组中选取一定数量的数据,就叫做分组选择
现在2张表
user1表中的数据如下:
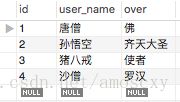
user_kills表中的数据如下:
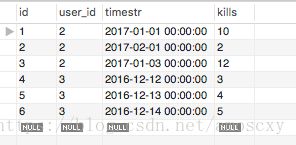
需求是:选择多条记录,比如阅读量最多的前几条
本例是每个人杀怪最多的头两天
对"孙悟空"而言查询语句如下:
select a.id, a.user_name, b.timestr, b.kills
from user1 a join user_kills b
on a.id = b.user_id
where user_name = '孙悟空'
order by b.kills desc
limit 2;
查询结果为:

查询"猪八戒"时,把user_name换成"猪八戒"即可。
但这样做存在着一些问题:
- 如果分类或是用户很多的情况下则需要多次执行同一查询
- 增加应用程序同数据库的交互次数
- 增加了数据库执行查询的次数,不符合批处理的原则
- 增加了网络流量
优化方式一:

MySQL优化:分类聚合问题,一次性查询出所有结果:
select d.user_name, c.timestr, kills from
(
select user_id, timestr, kills, (select count(*) from user_kills b
where b.user_id=a.user_id and a.kills<=b.kills) as cnt
from user_kills a
group by user_id, timestr, kills
) c join user1 d on c.user_id=d.id
where cnt<=2;