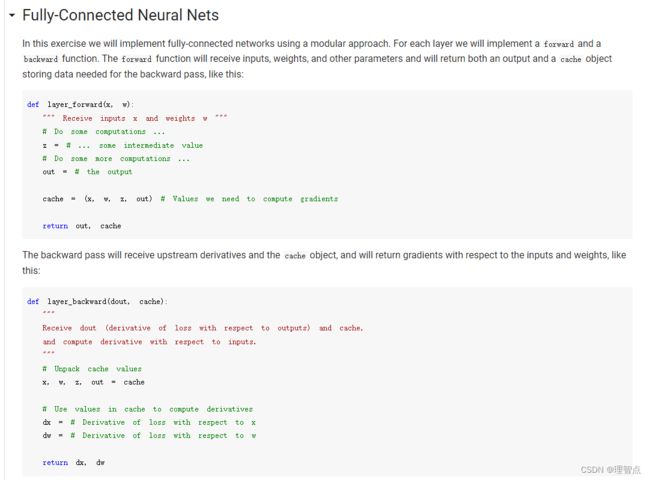
cs231n assignment1 q4
文章目录
- 嫌啰嗦直接看源码
- Q4: two_layer_net
-
- affine_forward
-
- 题面
- 解析
- 代码
- 输出
- affine_backward
-
- 推导
- 题面
- 解析
- 代码
- 输出
- relu_forward
-
- 题面
- 解析
- 代码
- 输出
- relu_backward
-
- 题面
- 解析
- 代码
- 输出
- svm_loss
-
- 题面
- 解析
- 代码
- 输出
- softmax_loss
-
- 题面
- 解析
- 代码
- 输出
- fc_net
-
- \_\_init_\_
-
- 题面
- 解析
- 代码
- loss
-
- 题面
- 解析
- 代码
- Solver
-
- 题面
- 解析
- 代码
- 输出
- Tune your hyperparameters
-
- 题面
- 代码
- 结果
- 最后的输出
嫌啰嗦直接看源码
往期作业
cs231n作业 assignment 1 q1 q2 q3
Q4: two_layer_net
就是让我们训练一个神经网络,跟着教程一步一步走就好了
affine_forward
题面
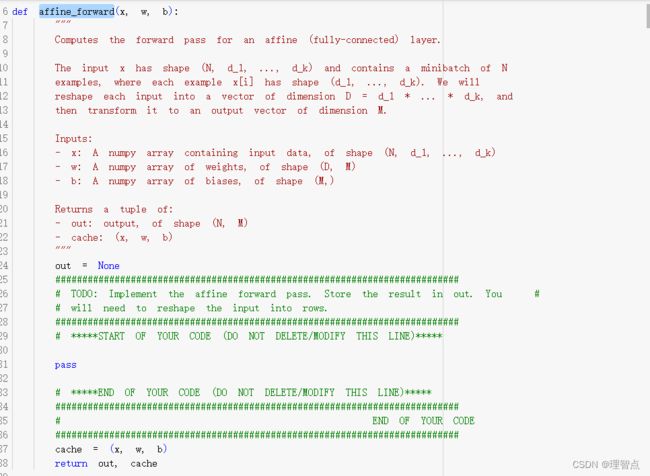
让我们实现一下前向传播的代码,同时让我们对输入的X进行维度转换,就像之前的q1 q2 q3 中教程帮我们做的一样
解析
我觉得没啥好说的,如果说X的维度转换不会的话,可以翻看前面的ipynb,里面又怎么转换的方法,或者直接看我的代码
代码
def affine_forward(x, w, b):
"""
Computes the forward pass for an affine (fully-connected) layer.
The input x has shape (N, d_1, ..., d_k) and contains a minibatch of N
examples, where each example x[i] has shape (d_1, ..., d_k). We will
reshape each input into a vector of dimension D = d_1 * ... * d_k, and
then transform it to an output vector of dimension M.
Inputs:
- x: A numpy array containing input data, of shape (N, d_1, ..., d_k)
- w: A numpy array of weights, of shape (D, M)
- b: A numpy array of biases, of shape (M,)
Returns a tuple of:
- out: output, of shape (N, M)
- cache: (x, w, b)
"""
out = None
###########################################################################
# TODO: Implement the affine forward pass. Store the result in out. You #
# will need to reshape the input into rows. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = x.reshape((x.shape[0],-1)) @ w + b
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = (x, w, b)
return out, cache
输出

affine_backward
推导
题面
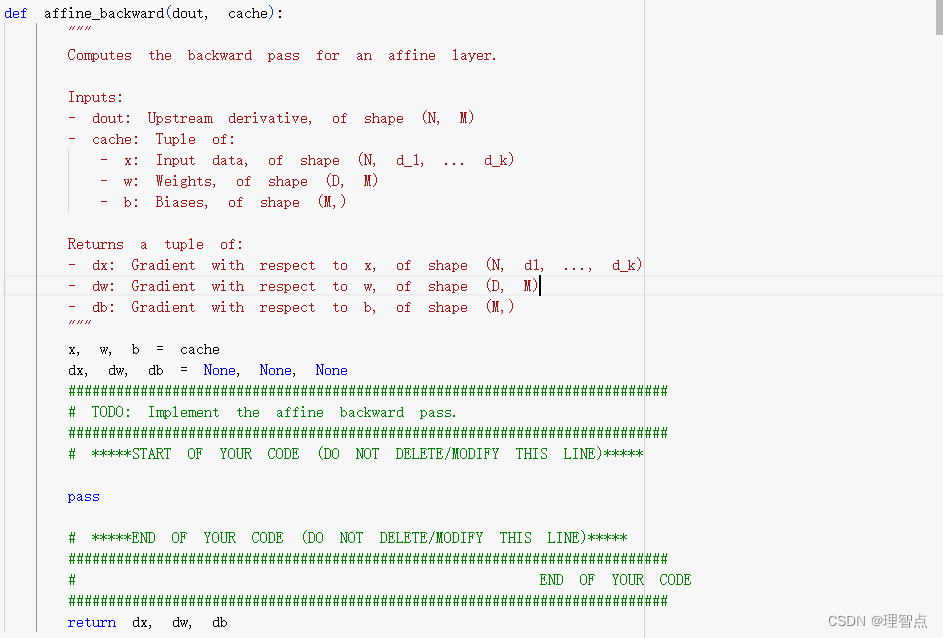
就是让我们求dx,dw,db,注意题目需要的shape
解析
看推导就行了,推导看懂了就不需要解析了
代码
def affine_backward(dout, cache):
"""
Computes the backward pass for an affine layer.
Inputs:
- dout: Upstream derivative, of shape (N, M)
- cache: Tuple of:
- x: Input data, of shape (N, d_1, ... d_k)
- w: Weights, of shape (D, M)
- b: Biases, of shape (M,)
Returns a tuple of:
- dx: Gradient with respect to x, of shape (N, d1, ..., d_k)
- dw: Gradient with respect to w, of shape (D, M)
- db: Gradient with respect to b, of shape (M,)
"""
x, w, b = cache
dx, dw, db = None, None, None
###########################################################################
# TODO: Implement the affine backward pass. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dx = (dout @ w.T).reshape(x.shape)
dw = x.reshape((x.shape[0],-1)).T @ dout
db = np.sum(dout,axis = 0)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx, dw, db
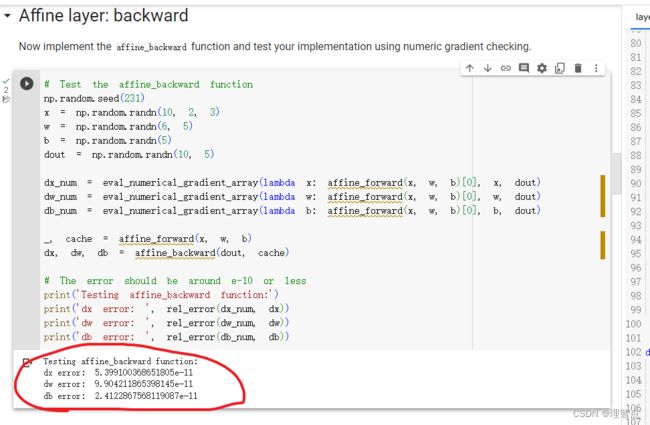
输出
relu_forward
ReLU的公式是:f(x) = max(0,x)
题面

解析
这个太蠢了,就是如果x的元素小于0就赋值为零就好了,用np.maximum就完事了
代码
def relu_forward(x):
"""
Computes the forward pass for a layer of rectified linear units (ReLUs).
Input:
- x: Inputs, of any shape
Returns a tuple of:
- out: Output, of the same shape as x
- cache: x
"""
out = None
###########################################################################
# TODO: Implement the ReLU forward pass. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = np.maximum(0,x)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = x
return out, cache
输出
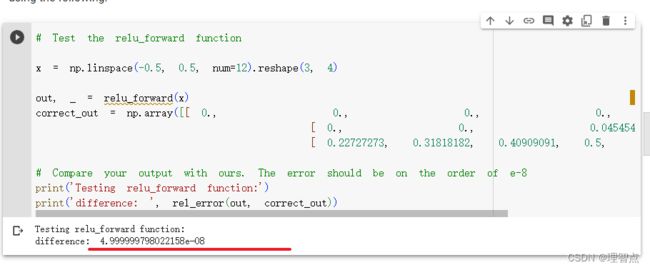
relu_backward
题面

解析
因为relu(x) = max(0,x)
所以如果x < 0,那么该点的梯度为0,因此只需要将dout中对应 x < 0 的位置的元素变成0就行,其他位置不动
代码
def relu_backward(dout, cache):
"""
Computes the backward pass for a layer of rectified linear units (ReLUs).
Input:
- dout: Upstream derivatives, of any shape
- cache: Input x, of same shape as dout
Returns:
- dx: Gradient with respect to x
"""
dx, x = None, cache
###########################################################################
# TODO: Implement the ReLU backward pass. #
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
dx = np.multiply(dout, (x > 0))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx
输出

svm_loss
题面
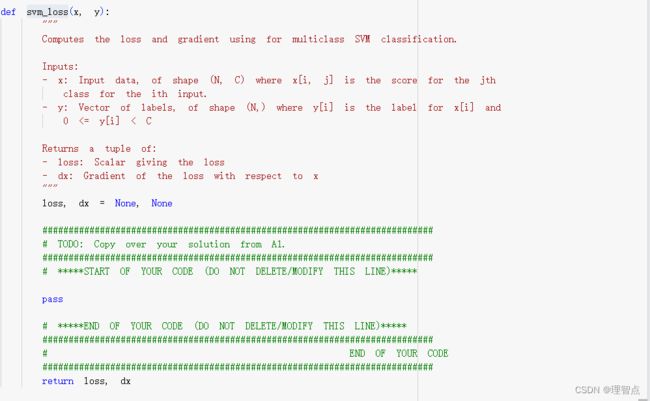
解析
就是跟之前一样的计算svm的loss和梯度,不知道怎么做的话可以看我往期的文章
但是又跟之前的不一样,之前的梯度计算是需要求到仿射层的就是相当于要求到(dL) / (dW)的
但是这里不一样,这个我们只需要求到(dL) / (dy),就是只需要求softmax_loss的梯度,不需要在细致的求到每个w的梯度了(而且想让我们求,我们也没有足够的条件求)
代码
def svm_loss(x, y):
"""
Computes the loss and gradient using for multiclass SVM classification.
Inputs:
- x: Input data, of shape (N, C) where x[i, j] is the score for the jth
class for the ith input.
- y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and
0 <= y[i] < C
Returns a tuple of:
- loss: Scalar giving the loss
- dx: Gradient of the loss with respect to x
"""
loss, dx = 0, 0
###########################################################################
# TODO: Copy over your solution from A1.
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 样本数量
num_train = x.shape[0]
# 获取正确分类的分数
scores_correct = x[range(num_train),y].reshape((x.shape[0],1))
margins = np.maximum(0,x - scores_correct + 1)
# 将正确分类的分数置为0
margins[range(num_train),y] = 0
loss += np.sum(margins)
# 正则项
loss /= num_train
# 计算梯度
margins[margins > 0] = 1
row_sum = np.sum(margins,axis = 1)
margins[range(num_train),y] = -row_sum
dx = margins
dx /= num_train
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
return loss, dx
输出
放到和softmax_loss的一起了,因为是一起输出的结果
softmax_loss
题面
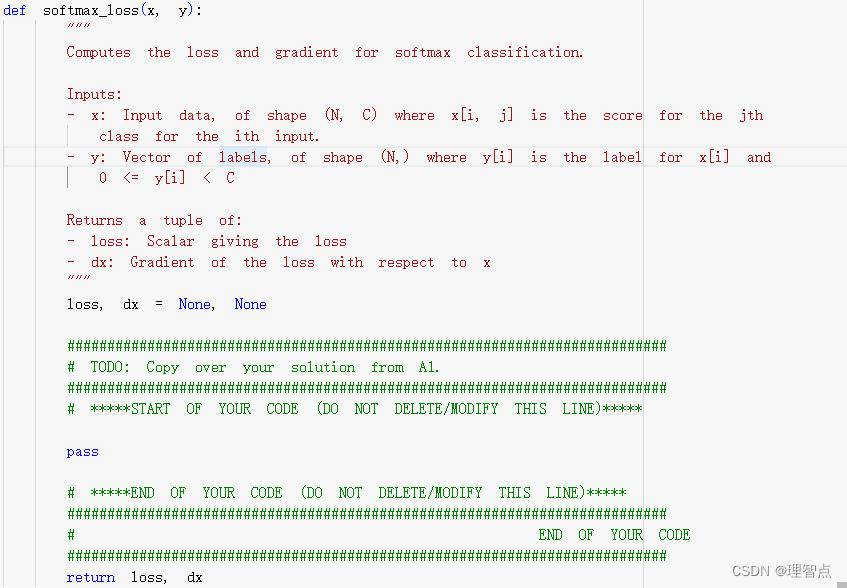
意思同上,就是计算softmax的loss和梯度
解析
同上,不会的话看往期的文章,不过注意这次我加了个数值稳定函数,无伤大雅的,不用也行
代码
def softmax_loss(x, y):
"""
Computes the loss and gradient for softmax classification.
Inputs:
- x: Input data, of shape (N, C) where x[i, j] is the score for the jth
class for the ith input.
- y: Vector of labels, of shape (N,) where y[i] is the label for x[i] and
0 <= y[i] < C
Returns a tuple of:
- loss: Scalar giving the loss
- dx: Gradient of the loss with respect to x
"""
loss, dx = 0, 0
###########################################################################
# TODO: Copy over your solution from A1.
###########################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 训练数据的数量
num_train = x.shape[0]
# 先取e的幂函数
scores = np.exp(x- x.max(axis=1, keepdims=True))
# 上面有种增加数值稳定的函数,防止指数函数太大爆炸影响真正的效果
# scores = np.exp(x- x.max(axis=1, keepdims=True)) 其中的-x.max(axis=1,keepdims=True)就是增加数值稳定的
# 当然对于本题的数据,我们直接用np.exp(x)也可以的 ^_^
# 计算所有的概率
p = scores / np.sum(scores,axis = 1,keepdims = True)
# 计算loss函数
loss += np.sum(-np.log(p[range(num_train),y]))
# 计算梯度 根据公式可以知道只要给正确分类的P - 1就可以得到dW
p[range(num_train),y] -= 1
dx += p
# 计算正则项
loss /= num_train
dx /= num_train
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
###########################################################################
# END OF YOUR CODE #
###########################################################################
return loss, dx
输出

看上面的条件,基本都符合了
fc_net
这个让我们实现一个两层的神经网络,一层是Relu,一层是softmax
网络的结构
affine - relu - affine - softmax.
__init__
题面

按照题目的自已就是让我们自己初始化一下训练用到的参数,其中w是符合高斯分布的随机数,b全是0
解析
np.random.normal()来生成w

np.zeros()来生成b
代码
def __init__(
self,
input_dim=3 * 32 * 32,
hidden_dim=100,
num_classes=10,
weight_scale=1e-3,
reg=0.0,
):
"""
Initialize a new network.
Inputs:
- input_dim: An integer giving the size of the input
- hidden_dim: An integer giving the size of the hidden layer
- num_classes: An integer giving the number of classes to classify
- weight_scale: Scalar giving the standard deviation for random
initialization of the weights.
- reg: Scalar giving L2 regularization strength.
"""
self.params = {}
self.reg = reg
############################################################################
# TODO: Initialize the weights and biases of the two-layer net. Weights #
# should be initialized from a Gaussian centered at 0.0 with #
# standard deviation equal to weight_scale, and biases should be #
# initialized to zero. All weights and biases should be stored in the #
# dictionary self.params, with first layer weights #
# and biases using the keys 'W1' and 'b1' and second layer #
# weights and biases using the keys 'W2' and 'b2'. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.params.W1 = np.random.normal(loc=0.0,scale=weight_scale,size=(input_dim,hidden_dim))
self.params.W2 = np.random.normal(loc=0.0,scale=weight_scale,size=(hidden_dim,num_classes))
self.params.b1 = np.zeros((hidden_dim,))
self.params.b2 = np.zeros((num_classes,))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
loss
题面


解析
一步一步来,主要是别忘了几个正则项,经过这样子网络的结构,对于我们调用的时候其实已经代码书写难度已经大大降低了,稍加思考对应元素的位置就好了
代码
def loss(self, X, y=None):
"""
Compute loss and gradient for a minibatch of data.
Inputs:
- X: Array of input data of shape (N, d_1, ..., d_k)
- y: Array of labels, of shape (N,). y[i] gives the label for X[i].
Returns:
If y is None, then run a test-time forward pass of the model and return:
- scores: Array of shape (N, C) giving classification scores, where
scores[i, c] is the classification score for X[i] and class c.
If y is not None, then run a training-time forward and backward pass and
return a tuple of:
- loss: Scalar value giving the loss
- grads: Dictionary with the same keys as self.params, mapping parameter
names to gradients of the loss with respect to those parameters.
"""
scores = None
############################################################################
# TODO: Implement the forward pass for the two-layer net, computing the #
# class scores for X and storing them in the scores variable. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
W1 = self.params['W1']
W2 = self.params['W2']
b1 = self.params['b1']
b2 = self.params['b2']
affine_1_out,affine_1_cache = affine_forward(X,W1,b1)
relu_out,relu_cache = relu_forward(affine_1_out)
affine_2_out,affine_2_cache = affine_forward(relu_out,W2,b2)
# 这里不走softmax层了,因为softmax层是计算loss值了,而这里我们只需要scores
scores = affine_2_out
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
# If y is None then we are in test mode so just return scores
if y is None:
return scores
loss, grads = 0, {}
############################################################################
# TODO: Implement the backward pass for the two-layer net. Store the loss #
# in the loss variable and gradients in the grads dictionary. Compute data #
# loss using softmax, and make sure that grads[k] holds the gradients for #
# self.params[k]. Don't forget to add L2 regularization! #
# #
# NOTE: To ensure that your implementation matches ours and you pass the #
# automated tests, make sure that your L2 regularization includes a factor #
# of 0.5 to simplify the expression for the gradient. #
############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# 用softmax计算loss和grad
loss,d_affine_2_out = softmax_loss(affine_2_out,y)
# loss 只需要算到这里,接下来加上正则项
loss += 0.5 * self.reg * (np.sum(W1 * W1) + np.sum(W2 * W2)
)
# 接下来算梯度
d_relu_out,dW_2,dB_2 = affine_backward(d_affine_2_out,affine_2_cache)
d_affine_1_out = relu_backward(d_relu_out,relu_cache)
dX,dW_1,dB_1 = affine_backward(d_affine_1_out,affine_1_cache)
dW_1 += self.reg * W1
dW_2 += self.reg * W2
# 保存梯度
grads['W1'] = dW_1
grads['W2'] = dW_2
grads['b1'] = dB_1
grads['b2'] = dB_2
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
Solver
题面

解析
就是让我们去阅读solver的代码,去熟悉我们自己写的几个api,然后构造一下我们solver就好了,代码很简单的,主要是阅读solver代码的过程
代码
input_size = 32 * 32 * 3
hidden_size = 50
num_classes = 10
model = TwoLayerNet(input_size, hidden_size, num_classes)
solver = None
##############################################################################
# TODO: Use a Solver instance to train a TwoLayerNet that achieves about 36% #
# accuracy on the validation set. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
solver = Solver(model, data, optim_config={'learning_rate': 1e-3})
solver.train()
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
输出
(Iteration 1 / 4900) loss: 2.301084
(Epoch 0 / 10) train acc: 0.109000; val_acc: 0.109000
(Iteration 11 / 4900) loss: 2.273729
(Iteration 21 / 4900) loss: 2.174355
(Iteration 31 / 4900) loss: 2.033214
(Iteration 41 / 4900) loss: 2.018372
(Iteration 51 / 4900) loss: 1.936294
(Iteration 61 / 4900) loss: 1.909365
(Iteration 71 / 4900) loss: 1.968080
(Iteration 81 / 4900) loss: 1.831189
(Iteration 91 / 4900) loss: 1.836682
(Iteration 101 / 4900) loss: 1.874288
(Iteration 111 / 4900) loss: 1.796551
(Iteration 121 / 4900) loss: 1.829135
(Iteration 131 / 4900) loss: 1.863156
(Iteration 141 / 4900) loss: 1.785416
(Iteration 151 / 4900) loss: 1.670677
(Iteration 161 / 4900) loss: 1.825214
(Iteration 171 / 4900) loss: 1.946122
(Iteration 181 / 4900) loss: 1.712422
(Iteration 191 / 4900) loss: 1.833139
(Iteration 201 / 4900) loss: 1.712148
(Iteration 211 / 4900) loss: 1.616144
(Iteration 221 / 4900) loss: 1.635851
(Iteration 231 / 4900) loss: 1.634573
(Iteration 241 / 4900) loss: 1.634086
(Iteration 251 / 4900) loss: 1.648923
(Iteration 261 / 4900) loss: 1.691381
(Iteration 271 / 4900) loss: 1.762122
(Iteration 281 / 4900) loss: 1.731388
(Iteration 291 / 4900) loss: 1.819805
(Iteration 301 / 4900) loss: 1.566611
(Iteration 311 / 4900) loss: 1.678215
(Iteration 321 / 4900) loss: 1.564199
(Iteration 331 / 4900) loss: 1.635177
(Iteration 341 / 4900) loss: 1.490303
(Iteration 351 / 4900) loss: 1.560792
(Iteration 361 / 4900) loss: 1.797754
(Iteration 371 / 4900) loss: 1.654941
(Iteration 381 / 4900) loss: 1.551228
(Iteration 391 / 4900) loss: 1.588600
(Iteration 401 / 4900) loss: 1.571287
(Iteration 411 / 4900) loss: 1.727028
(Iteration 421 / 4900) loss: 1.677506
(Iteration 431 / 4900) loss: 1.611189
(Iteration 441 / 4900) loss: 1.680913
(Iteration 451 / 4900) loss: 1.654809
(Iteration 461 / 4900) loss: 1.640508
(Iteration 471 / 4900) loss: 1.575345
(Iteration 481 / 4900) loss: 1.617710
(Epoch 1 / 10) train acc: 0.458000; val_acc: 0.450000
(Iteration 491 / 4900) loss: 1.651279
(Iteration 501 / 4900) loss: 1.684094
(Iteration 511 / 4900) loss: 1.578795
(Iteration 521 / 4900) loss: 1.562049
(Iteration 531 / 4900) loss: 1.603936
(Iteration 541 / 4900) loss: 1.539127
(Iteration 551 / 4900) loss: 1.543073
(Iteration 561 / 4900) loss: 1.499725
(Iteration 571 / 4900) loss: 1.567476
(Iteration 581 / 4900) loss: 1.897302
(Iteration 591 / 4900) loss: 1.573814
(Iteration 601 / 4900) loss: 1.404451
(Iteration 611 / 4900) loss: 1.618614
(Iteration 621 / 4900) loss: 1.680000
(Iteration 631 / 4900) loss: 1.670598
(Iteration 641 / 4900) loss: 1.589472
(Iteration 651 / 4900) loss: 1.600195
(Iteration 661 / 4900) loss: 1.352244
(Iteration 671 / 4900) loss: 1.578689
(Iteration 681 / 4900) loss: 1.650075
(Iteration 691 / 4900) loss: 1.465578
(Iteration 701 / 4900) loss: 1.483167
(Iteration 711 / 4900) loss: 1.427129
(Iteration 721 / 4900) loss: 1.784575
(Iteration 731 / 4900) loss: 1.415954
(Iteration 741 / 4900) loss: 1.511715
(Iteration 751 / 4900) loss: 1.487680
(Iteration 761 / 4900) loss: 1.373061
(Iteration 771 / 4900) loss: 1.665580
(Iteration 781 / 4900) loss: 1.430671
(Iteration 791 / 4900) loss: 1.326836
(Iteration 801 / 4900) loss: 1.426356
(Iteration 811 / 4900) loss: 1.498721
(Iteration 821 / 4900) loss: 1.377391
(Iteration 831 / 4900) loss: 1.374316
(Iteration 841 / 4900) loss: 1.507345
(Iteration 851 / 4900) loss: 1.662028
(Iteration 861 / 4900) loss: 1.468440
(Iteration 871 / 4900) loss: 1.569410
(Iteration 881 / 4900) loss: 1.388390
(Iteration 891 / 4900) loss: 1.467064
(Iteration 901 / 4900) loss: 1.505520
(Iteration 911 / 4900) loss: 1.779084
(Iteration 921 / 4900) loss: 1.490847
(Iteration 931 / 4900) loss: 1.429472
(Iteration 941 / 4900) loss: 1.598223
(Iteration 951 / 4900) loss: 1.690766
(Iteration 961 / 4900) loss: 1.494032
(Iteration 971 / 4900) loss: 1.522085
(Epoch 2 / 10) train acc: 0.483000; val_acc: 0.455000
(Iteration 981 / 4900) loss: 1.520685
(Iteration 991 / 4900) loss: 1.328689
(Iteration 1001 / 4900) loss: 1.394128
(Iteration 1011 / 4900) loss: 1.456969
(Iteration 1021 / 4900) loss: 1.621858
(Iteration 1031 / 4900) loss: 1.477229
(Iteration 1041 / 4900) loss: 1.462630
(Iteration 1051 / 4900) loss: 1.524669
(Iteration 1061 / 4900) loss: 1.515345
(Iteration 1071 / 4900) loss: 1.477645
(Iteration 1081 / 4900) loss: 1.470350
(Iteration 1091 / 4900) loss: 1.513094
(Iteration 1101 / 4900) loss: 1.544782
(Iteration 1111 / 4900) loss: 1.477012
(Iteration 1121 / 4900) loss: 1.364902
(Iteration 1131 / 4900) loss: 1.604127
(Iteration 1141 / 4900) loss: 1.536314
(Iteration 1151 / 4900) loss: 1.586519
(Iteration 1161 / 4900) loss: 1.463541
(Iteration 1171 / 4900) loss: 1.243605
(Iteration 1181 / 4900) loss: 1.481631
(Iteration 1191 / 4900) loss: 1.532539
(Iteration 1201 / 4900) loss: 1.249551
(Iteration 1211 / 4900) loss: 1.506066
(Iteration 1221 / 4900) loss: 1.427642
(Iteration 1231 / 4900) loss: 1.376686
(Iteration 1241 / 4900) loss: 1.566314
(Iteration 1251 / 4900) loss: 1.432466
(Iteration 1261 / 4900) loss: 1.567310
(Iteration 1271 / 4900) loss: 1.560503
(Iteration 1281 / 4900) loss: 1.595545
(Iteration 1291 / 4900) loss: 1.567085
(Iteration 1301 / 4900) loss: 1.454316
(Iteration 1311 / 4900) loss: 1.490910
(Iteration 1321 / 4900) loss: 1.592518
(Iteration 1331 / 4900) loss: 1.541783
(Iteration 1341 / 4900) loss: 1.374896
(Iteration 1351 / 4900) loss: 1.625951
(Iteration 1361 / 4900) loss: 1.471044
(Iteration 1371 / 4900) loss: 1.350735
(Iteration 1381 / 4900) loss: 1.609883
(Iteration 1391 / 4900) loss: 1.534862
(Iteration 1401 / 4900) loss: 1.452917
(Iteration 1411 / 4900) loss: 1.436169
(Iteration 1421 / 4900) loss: 1.405132
(Iteration 1431 / 4900) loss: 1.457032
(Iteration 1441 / 4900) loss: 1.494302
(Iteration 1451 / 4900) loss: 1.441696
(Iteration 1461 / 4900) loss: 1.606940
(Epoch 3 / 10) train acc: 0.483000; val_acc: 0.474000
(Iteration 1471 / 4900) loss: 1.399039
(Iteration 1481 / 4900) loss: 1.381901
(Iteration 1491 / 4900) loss: 1.395354
(Iteration 1501 / 4900) loss: 1.417236
(Iteration 1511 / 4900) loss: 1.484106
(Iteration 1521 / 4900) loss: 1.682362
(Iteration 1531 / 4900) loss: 1.469124
(Iteration 1541 / 4900) loss: 1.509884
(Iteration 1551 / 4900) loss: 1.484987
(Iteration 1561 / 4900) loss: 1.306599
(Iteration 1571 / 4900) loss: 1.355572
(Iteration 1581 / 4900) loss: 1.503104
(Iteration 1591 / 4900) loss: 1.492781
(Iteration 1601 / 4900) loss: 1.413251
(Iteration 1611 / 4900) loss: 1.560257
(Iteration 1621 / 4900) loss: 1.291057
(Iteration 1631 / 4900) loss: 1.286758
(Iteration 1641 / 4900) loss: 1.514361
(Iteration 1651 / 4900) loss: 1.518735
(Iteration 1661 / 4900) loss: 1.370597
(Iteration 1671 / 4900) loss: 1.469074
(Iteration 1681 / 4900) loss: 1.464342
(Iteration 1691 / 4900) loss: 1.384501
(Iteration 1701 / 4900) loss: 1.423517
(Iteration 1711 / 4900) loss: 1.417733
(Iteration 1721 / 4900) loss: 1.446887
(Iteration 1731 / 4900) loss: 1.320535
(Iteration 1741 / 4900) loss: 1.491887
(Iteration 1751 / 4900) loss: 1.498635
(Iteration 1761 / 4900) loss: 1.489212
(Iteration 1771 / 4900) loss: 1.542994
(Iteration 1781 / 4900) loss: 1.514106
(Iteration 1791 / 4900) loss: 1.304327
(Iteration 1801 / 4900) loss: 1.222466
(Iteration 1811 / 4900) loss: 1.378112
(Iteration 1821 / 4900) loss: 1.393398
(Iteration 1831 / 4900) loss: 1.345431
(Iteration 1841 / 4900) loss: 1.474607
(Iteration 1851 / 4900) loss: 1.278975
(Iteration 1861 / 4900) loss: 1.423413
(Iteration 1871 / 4900) loss: 1.470634
(Iteration 1881 / 4900) loss: 1.523484
(Iteration 1891 / 4900) loss: 1.494911
(Iteration 1901 / 4900) loss: 1.549876
(Iteration 1911 / 4900) loss: 1.506629
(Iteration 1921 / 4900) loss: 1.377911
(Iteration 1931 / 4900) loss: 1.431192
(Iteration 1941 / 4900) loss: 1.377486
(Iteration 1951 / 4900) loss: 1.415583
(Epoch 4 / 10) train acc: 0.506000; val_acc: 0.476000
(Iteration 1961 / 4900) loss: 1.618262
(Iteration 1971 / 4900) loss: 1.492193
(Iteration 1981 / 4900) loss: 1.454406
(Iteration 1991 / 4900) loss: 1.359818
(Iteration 2001 / 4900) loss: 1.285706
(Iteration 2011 / 4900) loss: 1.371012
(Iteration 2021 / 4900) loss: 1.359123
(Iteration 2031 / 4900) loss: 1.498010
(Iteration 2041 / 4900) loss: 1.354732
(Iteration 2051 / 4900) loss: 1.438783
(Iteration 2061 / 4900) loss: 1.480778
(Iteration 2071 / 4900) loss: 1.537145
(Iteration 2081 / 4900) loss: 1.188694
(Iteration 2091 / 4900) loss: 1.282485
(Iteration 2101 / 4900) loss: 1.342001
(Iteration 2111 / 4900) loss: 1.548787
(Iteration 2121 / 4900) loss: 1.572799
(Iteration 2131 / 4900) loss: 1.343591
(Iteration 2141 / 4900) loss: 1.586770
(Iteration 2151 / 4900) loss: 1.293524
(Iteration 2161 / 4900) loss: 1.547009
(Iteration 2171 / 4900) loss: 1.408669
(Iteration 2181 / 4900) loss: 1.455682
(Iteration 2191 / 4900) loss: 1.168711
(Iteration 2201 / 4900) loss: 1.277475
(Iteration 2211 / 4900) loss: 1.269945
(Iteration 2221 / 4900) loss: 1.315483
(Iteration 2231 / 4900) loss: 1.362125
(Iteration 2241 / 4900) loss: 1.415312
(Iteration 2251 / 4900) loss: 1.362131
(Iteration 2261 / 4900) loss: 1.511428
(Iteration 2271 / 4900) loss: 1.207401
(Iteration 2281 / 4900) loss: 1.415940
(Iteration 2291 / 4900) loss: 1.425663
(Iteration 2301 / 4900) loss: 1.295703
(Iteration 2311 / 4900) loss: 1.254505
(Iteration 2321 / 4900) loss: 1.497928
(Iteration 2331 / 4900) loss: 1.251498
(Iteration 2341 / 4900) loss: 1.382769
(Iteration 2351 / 4900) loss: 1.288472
(Iteration 2361 / 4900) loss: 1.458135
(Iteration 2371 / 4900) loss: 1.313538
(Iteration 2381 / 4900) loss: 1.387674
(Iteration 2391 / 4900) loss: 1.306602
(Iteration 2401 / 4900) loss: 1.450026
(Iteration 2411 / 4900) loss: 1.420869
(Iteration 2421 / 4900) loss: 1.248337
(Iteration 2431 / 4900) loss: 1.327928
(Iteration 2441 / 4900) loss: 1.505570
(Epoch 5 / 10) train acc: 0.493000; val_acc: 0.458000
(Iteration 2451 / 4900) loss: 1.339375
(Iteration 2461 / 4900) loss: 1.391034
(Iteration 2471 / 4900) loss: 1.574944
(Iteration 2481 / 4900) loss: 1.508791
(Iteration 2491 / 4900) loss: 1.304072
(Iteration 2501 / 4900) loss: 1.440362
(Iteration 2511 / 4900) loss: 1.305748
(Iteration 2521 / 4900) loss: 1.488807
(Iteration 2531 / 4900) loss: 1.615756
(Iteration 2541 / 4900) loss: 1.405928
(Iteration 2551 / 4900) loss: 1.246385
(Iteration 2561 / 4900) loss: 1.315364
(Iteration 2571 / 4900) loss: 1.421446
(Iteration 2581 / 4900) loss: 1.497967
(Iteration 2591 / 4900) loss: 1.331557
(Iteration 2601 / 4900) loss: 1.453666
(Iteration 2611 / 4900) loss: 1.285519
(Iteration 2621 / 4900) loss: 1.425636
(Iteration 2631 / 4900) loss: 1.314801
(Iteration 2641 / 4900) loss: 1.298306
(Iteration 2651 / 4900) loss: 1.461723
(Iteration 2661 / 4900) loss: 1.523801
(Iteration 2671 / 4900) loss: 1.415812
(Iteration 2681 / 4900) loss: 1.318759
(Iteration 2691 / 4900) loss: 1.469690
(Iteration 2701 / 4900) loss: 1.262966
(Iteration 2711 / 4900) loss: 1.489861
(Iteration 2721 / 4900) loss: 1.228969
(Iteration 2731 / 4900) loss: 1.468175
(Iteration 2741 / 4900) loss: 1.349398
(Iteration 2751 / 4900) loss: 1.271159
(Iteration 2761 / 4900) loss: 1.391232
(Iteration 2771 / 4900) loss: 1.357391
(Iteration 2781 / 4900) loss: 1.417309
(Iteration 2791 / 4900) loss: 1.522723
(Iteration 2801 / 4900) loss: 1.526235
(Iteration 2811 / 4900) loss: 1.331352
(Iteration 2821 / 4900) loss: 1.329435
(Iteration 2831 / 4900) loss: 1.088911
(Iteration 2841 / 4900) loss: 1.695192
(Iteration 2851 / 4900) loss: 1.439629
(Iteration 2861 / 4900) loss: 1.304997
(Iteration 2871 / 4900) loss: 1.327335
(Iteration 2881 / 4900) loss: 1.360054
(Iteration 2891 / 4900) loss: 1.608956
(Iteration 2901 / 4900) loss: 1.301895
(Iteration 2911 / 4900) loss: 1.286987
(Iteration 2921 / 4900) loss: 1.465441
(Iteration 2931 / 4900) loss: 1.436922
(Epoch 6 / 10) train acc: 0.494000; val_acc: 0.441000
(Iteration 2941 / 4900) loss: 1.214374
(Iteration 2951 / 4900) loss: 1.442676
(Iteration 2961 / 4900) loss: 1.182191
(Iteration 2971 / 4900) loss: 1.540090
(Iteration 2981 / 4900) loss: 1.329494
(Iteration 2991 / 4900) loss: 1.255908
(Iteration 3001 / 4900) loss: 1.693805
(Iteration 3011 / 4900) loss: 1.482947
(Iteration 3021 / 4900) loss: 1.518969
(Iteration 3031 / 4900) loss: 1.261443
(Iteration 3041 / 4900) loss: 1.125180
(Iteration 3051 / 4900) loss: 1.384420
(Iteration 3061 / 4900) loss: 1.449550
(Iteration 3071 / 4900) loss: 1.422641
(Iteration 3081 / 4900) loss: 1.317469
(Iteration 3091 / 4900) loss: 1.427890
(Iteration 3101 / 4900) loss: 1.226803
(Iteration 3111 / 4900) loss: 1.385459
(Iteration 3121 / 4900) loss: 1.326855
(Iteration 3131 / 4900) loss: 1.148374
(Iteration 3141 / 4900) loss: 1.223508
(Iteration 3151 / 4900) loss: 1.461523
(Iteration 3161 / 4900) loss: 1.515457
(Iteration 3171 / 4900) loss: 1.557221
(Iteration 3181 / 4900) loss: 1.353831
(Iteration 3191 / 4900) loss: 1.203578
(Iteration 3201 / 4900) loss: 1.281293
(Iteration 3211 / 4900) loss: 1.200816
(Iteration 3221 / 4900) loss: 1.512150
(Iteration 3231 / 4900) loss: 1.580219
(Iteration 3241 / 4900) loss: 1.244586
(Iteration 3251 / 4900) loss: 1.326828
(Iteration 3261 / 4900) loss: 1.337245
(Iteration 3271 / 4900) loss: 1.346274
(Iteration 3281 / 4900) loss: 1.373448
(Iteration 3291 / 4900) loss: 1.311027
(Iteration 3301 / 4900) loss: 1.110510
(Iteration 3311 / 4900) loss: 1.247533
(Iteration 3321 / 4900) loss: 1.353995
(Iteration 3331 / 4900) loss: 1.084901
(Iteration 3341 / 4900) loss: 1.208503
(Iteration 3351 / 4900) loss: 1.306901
(Iteration 3361 / 4900) loss: 1.366972
(Iteration 3371 / 4900) loss: 1.345756
(Iteration 3381 / 4900) loss: 1.343105
(Iteration 3391 / 4900) loss: 1.454141
(Iteration 3401 / 4900) loss: 1.177776
(Iteration 3411 / 4900) loss: 1.400214
(Iteration 3421 / 4900) loss: 1.342663
(Epoch 7 / 10) train acc: 0.547000; val_acc: 0.495000
(Iteration 3431 / 4900) loss: 1.305331
(Iteration 3441 / 4900) loss: 1.325195
(Iteration 3451 / 4900) loss: 1.318475
(Iteration 3461 / 4900) loss: 1.396304
(Iteration 3471 / 4900) loss: 1.360285
(Iteration 3481 / 4900) loss: 1.184701
(Iteration 3491 / 4900) loss: 1.238211
(Iteration 3501 / 4900) loss: 1.283518
(Iteration 3511 / 4900) loss: 1.428018
(Iteration 3521 / 4900) loss: 1.496044
(Iteration 3531 / 4900) loss: 1.381695
(Iteration 3541 / 4900) loss: 1.418340
(Iteration 3551 / 4900) loss: 1.328346
(Iteration 3561 / 4900) loss: 1.322044
(Iteration 3571 / 4900) loss: 1.378151
(Iteration 3581 / 4900) loss: 1.420039
(Iteration 3591 / 4900) loss: 1.219752
(Iteration 3601 / 4900) loss: 1.140046
(Iteration 3611 / 4900) loss: 1.282249
(Iteration 3621 / 4900) loss: 1.390048
(Iteration 3631 / 4900) loss: 1.582304
(Iteration 3641 / 4900) loss: 1.250451
(Iteration 3651 / 4900) loss: 1.328232
(Iteration 3661 / 4900) loss: 1.243136
(Iteration 3671 / 4900) loss: 1.423866
(Iteration 3681 / 4900) loss: 1.340820
(Iteration 3691 / 4900) loss: 1.425670
(Iteration 3701 / 4900) loss: 1.203154
(Iteration 3711 / 4900) loss: 1.249543
(Iteration 3721 / 4900) loss: 1.435793
(Iteration 3731 / 4900) loss: 1.250016
(Iteration 3741 / 4900) loss: 1.319717
(Iteration 3751 / 4900) loss: 1.373801
(Iteration 3761 / 4900) loss: 1.620420
(Iteration 3771 / 4900) loss: 1.321370
(Iteration 3781 / 4900) loss: 1.406195
(Iteration 3791 / 4900) loss: 1.133733
(Iteration 3801 / 4900) loss: 1.477101
(Iteration 3811 / 4900) loss: 1.418692
(Iteration 3821 / 4900) loss: 1.325902
(Iteration 3831 / 4900) loss: 1.274603
(Iteration 3841 / 4900) loss: 1.416265
(Iteration 3851 / 4900) loss: 1.503136
(Iteration 3861 / 4900) loss: 1.323808
(Iteration 3871 / 4900) loss: 1.326465
(Iteration 3881 / 4900) loss: 1.291280
(Iteration 3891 / 4900) loss: 1.643525
(Iteration 3901 / 4900) loss: 1.235655
(Iteration 3911 / 4900) loss: 1.179011
(Epoch 8 / 10) train acc: 0.554000; val_acc: 0.503000
(Iteration 3921 / 4900) loss: 1.136915
(Iteration 3931 / 4900) loss: 1.183221
(Iteration 3941 / 4900) loss: 1.399673
(Iteration 3951 / 4900) loss: 1.311476
(Iteration 3961 / 4900) loss: 1.270733
(Iteration 3971 / 4900) loss: 1.348953
(Iteration 3981 / 4900) loss: 1.154720
(Iteration 3991 / 4900) loss: 1.597530
(Iteration 4001 / 4900) loss: 1.154861
(Iteration 4011 / 4900) loss: 1.382757
(Iteration 4021 / 4900) loss: 1.583512
(Iteration 4031 / 4900) loss: 1.367937
(Iteration 4041 / 4900) loss: 1.432329
(Iteration 4051 / 4900) loss: 1.353527
(Iteration 4061 / 4900) loss: 1.432101
(Iteration 4071 / 4900) loss: 1.348392
(Iteration 4081 / 4900) loss: 1.717534
(Iteration 4091 / 4900) loss: 1.165055
(Iteration 4101 / 4900) loss: 1.191290
(Iteration 4111 / 4900) loss: 1.413249
(Iteration 4121 / 4900) loss: 1.313827
(Iteration 4131 / 4900) loss: 1.309803
(Iteration 4141 / 4900) loss: 1.315864
(Iteration 4151 / 4900) loss: 1.365802
(Iteration 4161 / 4900) loss: 1.554362
(Iteration 4171 / 4900) loss: 1.374609
(Iteration 4181 / 4900) loss: 1.238242
(Iteration 4191 / 4900) loss: 1.169315
(Iteration 4201 / 4900) loss: 1.378836
(Iteration 4211 / 4900) loss: 1.295552
(Iteration 4221 / 4900) loss: 1.416132
(Iteration 4231 / 4900) loss: 1.410366
(Iteration 4241 / 4900) loss: 1.552665
(Iteration 4251 / 4900) loss: 1.123680
(Iteration 4261 / 4900) loss: 1.345930
(Iteration 4271 / 4900) loss: 1.288356
(Iteration 4281 / 4900) loss: 1.394372
(Iteration 4291 / 4900) loss: 1.204953
(Iteration 4301 / 4900) loss: 1.219376
(Iteration 4311 / 4900) loss: 1.372091
(Iteration 4321 / 4900) loss: 1.303272
(Iteration 4331 / 4900) loss: 1.177567
(Iteration 4341 / 4900) loss: 1.269099
(Iteration 4351 / 4900) loss: 1.360113
(Iteration 4361 / 4900) loss: 1.371245
(Iteration 4371 / 4900) loss: 1.221913
(Iteration 4381 / 4900) loss: 1.236036
(Iteration 4391 / 4900) loss: 1.135667
(Iteration 4401 / 4900) loss: 1.302358
(Epoch 9 / 10) train acc: 0.547000; val_acc: 0.477000
(Iteration 4411 / 4900) loss: 1.181607
(Iteration 4421 / 4900) loss: 1.401505
(Iteration 4431 / 4900) loss: 1.292314
(Iteration 4441 / 4900) loss: 1.437959
(Iteration 4451 / 4900) loss: 1.414004
(Iteration 4461 / 4900) loss: 1.262010
(Iteration 4471 / 4900) loss: 1.236764
(Iteration 4481 / 4900) loss: 1.200308
(Iteration 4491 / 4900) loss: 1.269349
(Iteration 4501 / 4900) loss: 1.005077
(Iteration 4511 / 4900) loss: 1.293746
(Iteration 4521 / 4900) loss: 1.340251
(Iteration 4531 / 4900) loss: 1.303106
(Iteration 4541 / 4900) loss: 1.248767
(Iteration 4551 / 4900) loss: 1.320377
(Iteration 4561 / 4900) loss: 1.508266
(Iteration 4571 / 4900) loss: 1.350432
(Iteration 4581 / 4900) loss: 1.281510
(Iteration 4591 / 4900) loss: 1.429621
(Iteration 4601 / 4900) loss: 1.180842
(Iteration 4611 / 4900) loss: 1.075045
(Iteration 4621 / 4900) loss: 1.357894
(Iteration 4631 / 4900) loss: 1.212787
(Iteration 4641 / 4900) loss: 1.512692
(Iteration 4651 / 4900) loss: 1.285667
(Iteration 4661 / 4900) loss: 1.165197
(Iteration 4671 / 4900) loss: 1.293227
(Iteration 4681 / 4900) loss: 1.103044
(Iteration 4691 / 4900) loss: 1.140829
(Iteration 4701 / 4900) loss: 1.389774
(Iteration 4711 / 4900) loss: 1.310982
(Iteration 4721 / 4900) loss: 1.249437
(Iteration 4731 / 4900) loss: 1.216739
(Iteration 4741 / 4900) loss: 1.266213
(Iteration 4751 / 4900) loss: 1.442673
(Iteration 4761 / 4900) loss: 1.219733
(Iteration 4771 / 4900) loss: 1.378369
(Iteration 4781 / 4900) loss: 1.505432
(Iteration 4791 / 4900) loss: 1.232619
(Iteration 4801 / 4900) loss: 1.350596
(Iteration 4811 / 4900) loss: 1.293851
(Iteration 4821 / 4900) loss: 1.317689
(Iteration 4831 / 4900) loss: 1.313958
(Iteration 4841 / 4900) loss: 1.303738
(Iteration 4851 / 4900) loss: 1.320713
(Iteration 4861 / 4900) loss: 1.222695
(Iteration 4871 / 4900) loss: 1.096203
(Iteration 4881 / 4900) loss: 1.234871
(Iteration 4891 / 4900) loss: 1.050064
(Epoch 10 / 10) train acc: 0.525000; val_acc: 0.434000
Tune your hyperparameters
题面
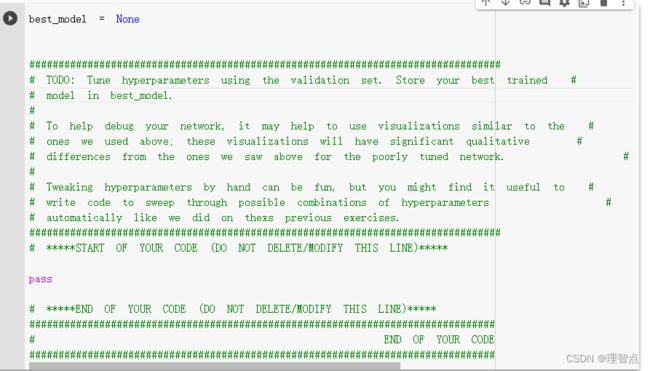
跟之前的差不多,就是找到合适的超参数
代码
best_model = None
#################################################################################
# TODO: Tune hyperparameters using the validation set. Store your best trained #
# model in best_model. #
# #
# To help debug your network, it may help to use visualizations similar to the #
# ones we used above; these visualizations will have significant qualitative #
# differences from the ones we saw above for the poorly tuned network. #
# #
# Tweaking hyperparameters by hand can be fun, but you might find it useful to #
# write code to sweep through possible combinations of hyperparameters #
# automatically like we did on thexs previous exercises. #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
results = {}
best_val = -1
learning_rates = np.geomspace(3e-4, 3e-2, 3)
regularization_strengths = np.geomspace(1e-6, 1e-2, 5)
import itertools
for lr, reg in itertools.product(learning_rates, regularization_strengths):
# Create Two Layer Net and train it with Solver
model = TwoLayerNet(hidden_dim=128, reg=reg)
solver = Solver(model, data, optim_config={'learning_rate': lr}, num_epochs=10, verbose=False)
solver.train()
# Compute validation set accuracy and append to the dictionary
results[(lr, reg)] = solver.best_val_acc
# Save if validation accuracy is the best
if results[(lr, reg)] > best_val:
best_val = results[(lr, reg)]
best_model = model
# Print out results.
for lr, reg in sorted(results):
val_accuracy = results[(lr, reg)]
print('lr %e reg %e val accuracy: %f' % (lr, reg, val_accuracy))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
################################################################################
# END OF YOUR CODE #
################################################################################
结果

我跑了24分钟!!!
最后的输出
