Pytorch 自定义数据集的加载训练
目录
1)Datasets 源代码
2)Datasets 整体框架
3)自定义Datasets框架
4)DataLoader的使用
5)生成txt文件
Datasets是我们用的数据集的库,我们知道pytorch自带多种数据集列如Cifar10数据集就是在pytorch的Datasets的库中的。
Pytorch中有工具函数torch.utils.Data.DataLoader,通过这个函数我们在准备加载数据集使用mini-batch的时候可以使用多线程并行处理,这样可以加快我们准备数据集的速度。Datasets就是构建这个工具函数的实例参数之一。
Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数必须被重载,否则将会触发错误提示:
1. def getitem(self, index):
2. def len(self):其中__len__应该返回数据集的大小,而__getitem__应该编写支持数据集索引的函数
这里重点看 getitem函数,getitem接收一个index,然后返回图片数据和标签,这个index通常指的是一个list的index,这个list的每个元素就包含了图片数据的路径和标签信息。
制作list,通常的方法是将图片的路径和标签信息存储在一个txt中,然后从该txt中读取。
那么读取自己数据的基本流程就是:
1. 制作存储了图片的路径和标签信息的txt;
2. 将这些信息转化为list,该list每一个元素对应一个样本;
3. 通过getitem函数,读取数据和标签,并返回数据和标签;
定义自己的数据集类
1)Datasets 源代码
All datasets are subclasses of torch.utils.data.Dataset i.e,
they have __getitem__ and __len__ methods implemented.
Hence, they can all be passed to a torch.
utils.data.DataLoader which can load multiple samples parallelly using torch.multiprocessing workers. [源代码地址(https://pytorch.org/docs/stable/torchvision/datasets.html)
从源代码我们可以看出继承Datasets必须继承__init_()和__getitim__()
首先继承上面的dataset类。然后在__init__()方法中得到图像的路径,然后将图像路径组成一个数组,这样在__getitim__()中就可以直接读取.
2)Datasets 整体框架
class FirstDataset(data.Dataset):#需要继承data.Dataset
def __init__(self):
# TODO
# 1. 初始化文件路径或文件名列表。
#也就是在这个模块里,我们所做的工作就是初始化该类的一些基本参数。
pass
def __getitem__(self, index):
# TODO
#1。从文件中读取一个数据(例如,使用numpy.fromfile,PIL.Image.open)。
#2。预处理数据(例如torchvision.Transform)。
#3。返回数据对(例如图像和标签)。
#这里需要注意的是,第一步:read one data,是一个data
pass
def __len__(self):
# 您应该将0更改为数据集的总大小。3)自定义Datasets框架
# ***************************一些必要的包的调用********************************
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
import torch.optim as optim
import os
# ***************************初始化一些函数********************************
# torch.cuda.set_device(gpu_id)#使用GPU
learning_rate = 0.0001 # 学习率的设置
# *************************************数据集的设置****************************************************************************
root = os.getcwd() + '/data1/' # 数据集的地址
# 定义读取文件的格式
def default_loader(path):
return Image.open(path).convert('RGB')
class MyDataset(Dataset):
# 创建自己的类: MyDataset,这个类是继承的torch.utils.data.Dataset
# ********************************** #使用__init__()初始化一些需要传入的参数及数据集的调用**********************
def __init__(self, txt, transform=None, target_transform=None, loader=default_loader):
super(MyDataset, self).__init__()
# 对继承自父类的属性进行初始化
fh = open(txt, 'r')
# 按照传入的路径和txt文本参数,以只读的方式打开这个文本
for line in fh: # 迭代该列表#按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n')
# 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split()
# 用split将该行分割成列表 split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0], int(words[1])))
# 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lable
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
# *************************** #使用__getitem__()对数据进行预处理并返回想要的信息**********************
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn, label = self.imgs[index]
# fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
img = self.loader(fn)
# 按照路径读取图片
if self.transform is not None:
img = self.transform(img)
# 数据标签转换为Tensor
return img, label
# return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
# ********************************** #使用__len__()初始化一些需要传入的参数及数据集的调用**********************
def __len__(self):
# 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
train_data = MyDataset(txt=root + 'train.txt', transform=transforms.ToTensor())
test_data = MyDataset(txt=root + 'text.txt', transform=transforms.ToTensor())这里就不在详细描述,代码中注释的非常清楚,下面对一些小问题进行详细的说明:
问题1.为什么返回的是RGB?
def default_loader(path):
return Image.open(path).convert('RGB')答:对于彩色图像,不管其图像格式是PNG,还是BMP,或者JPG,在PIL中,使用Image模块的open()函数打开后,返回的图像对象的模式都是“RGB”。
而对于灰度图像,不管其图像格式是PNG,还是BMP,或者JPG,打开后,其模式为“L”。
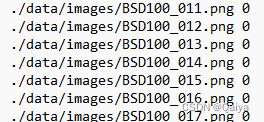
问题2:为什么word[0]是图片信息word[1]是标签信息
imgs.append((words[0],int(words[1])))
# 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lable在生成txt文件的时候我默认设定的是第一部分是图片信息,第二部分是标签信息,当然如果你不喜欢这个顺序可以更改。
4)DataLoader的使用
从上面Datasets源代码中可以知道定义Datasets还会遇到DataLoader类,它可以 调utils.data.DataLoader,可以使用torch.multiprocessing worker并行加载多个样本。
DataLoader类
之前所说的Dataset类是读入数据集数据并且对读入的数据进行了索引。但是光有这个功能是不够用的,在实际的加载数据集的过程中,我们的数据量往往都很大,对此我们还需要一下几个功能:
batch_size: 可以分批次读取
shuffle=True 可以对数据进行随机读取,可以对数据进行洗牌操作(shuffling),打乱数据集内数据分布的顺序
num_workers=2 可以并行加载数据(利用多核处理器加快载入数据的效率
batch : 可以分批次读取:batch-size这时候就需要Dataloader类了,Dataloader这个类并不需要我们自己设计代码,我们只需要利用DataLoader类读取我们设计好的ShipDataset即可:
train_loader= DataLoader(dataset=train_data, batch_size=6, shuffle=True ,num_workers=4)
test_loader = DataLoader(dataset=test_data, batch_size=6, shuffle=False,num_workers=4)简单的读取数据集的操作大体上就是这样的,当然实际应用中可能会与更加复杂的操作,这里就不进行复杂的描述了,具体的大家可以看一下官方网的源代码
5)生成txt文件
除了上面的读取数据集的代码,我们实际的图像数据应该怎么去放置呢?这就要用到txt文件了。
一般来说,我们自己制作的数据集一般包含三个部分:训练集、验证集和测试集。
因为数据集较大,所以一般我们将这三个模块分别放到三个文件夹下面,利用代码直接调用吗,简单又方便而且不容易出错。
调用的时候,我们不仅要调用图片还有图片的路径和标签信息等,所以我们使用txt文件,在txt文件中加入两种信息,一种是图片的路径,我们可以通过图片的路径来找到图,从而读取图片;另一种是图片的标签,将每张图片的信息和标签一 一对应。
下面是生成图片的txt文件的代码:
import os
a = 0
while (a < 1024): # 1024为我们的类别数
dir = './data/images/' # 图片文件的地址
label = a
# os.listdir的结果就是一个list集,可以使用list的sort方法来排序。如果文件名中有数字,就用数字的排序
files = os.listdir(dir) # 列出dirname下的目录和文件
files.sort() # 排序
train = open('./data/train.txt', 'a')
text = open('./data/text.txt', 'a')
i = 1
for file in files:
if i < 200000:
fileType = os.path.split(file) # os.path.split():按照路径将文件名和路径分割开
if fileType[1] == '.txt':
continue
name = str(dir) + file + ' ' + str(int(label)) + '\n'
train.write(name)
i = i + 1
else:
fileType = os.path.split(file)
if fileType[1] == '.txt':
continue
name = str(dir) + file + ' ' + str(int(label)) + '\n'
text.write(name)
i = i + 1
text.close()
train.close()
a = a+1 #######
生成txt文件这里引用了文章https://blog.csdn.net/Jack_and_monkey/article/details/86677253
本文定义数据集的整个代码如下:
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
import torchvision.models as models
from torchvision import transforms, utils
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import numpy as np
import torch.optim as optim
import os
# torch.cuda.set_device(gpu_id)#使用GPU
learning_rate = 0.0001
# 数据集的设置*****************************************************************************************************************
root = os.getcwd() + '/data1/' # 调用图像
# 定义读取文件的格式
def default_loader(path):
return Image.open(path).convert('RGB')
# 首先继承上面的dataset类。然后在__init__()方法中得到图像的路径,然后将图像路径组成一个数组,这样在__getitim__()中就可以直接读取:
class MyDataset(Dataset): # 创建自己的类:MyDataset,这个类是继承的torch.utils.data.Dataset
def __init__(self, txt, transform=None, target_transform=None, loader=default_loader): # 初始化一些需要传入的参数
super(MyDataset, self).__init__() # 对继承自父类的属性进行初始化
fh = open(txt, 'r') # 按照传入的路径和txt文本参数,打开这个文本,并读取内容
imgs = []
for line in fh: # 迭代该列表#按行循环txt文本中的内
line = line.strip('\n')
line = line.rstrip('\n') # 删除 本行string 字符串末尾的指定字符,这个方法的详细介绍自己查询python
words = line.split() # 用split将该行分割成列表 split的默认参数是空格,所以不传递任何参数时分割空格
imgs.append((words[0], int(words[1]))) # 把txt里的内容读入imgs列表保存,具体是words几要看txt内容而定
# 很显然,根据我刚才截图所示txt的内容,words[0]是图片信息,words[1]是lable
self.imgs = imgs
self.transform = transform
self.target_transform = target_transform
self.loader = loader
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn, label = self.imgs[index] # fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
img = self.loader(fn) # 按照路径读取图片
if self.transform is not None:
img = self.transform(img) # 数据标签转换为Tensor
return img, label # return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
def __len__(self): # 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
# 根据自己定义的那个MyDataset来创建数据集!注意是数据集!而不是loader迭代器
# *********************************************数据集读取完毕********************************************************************
# 图像的初始化操作
train_transforms = transforms.Compose([
transforms.RandomResizedCrop((227, 227)),
transforms.ToTensor(),
])
text_transforms = transforms.Compose([
transforms.RandomResizedCrop((227, 227)),
transforms.ToTensor(),
])
# 数据集加载方式设置
train_data = MyDataset(txt=root + 'train.txt', transform=transforms.ToTensor())
test_data = MyDataset(txt=root + 'text.txt', transform=transforms.ToTensor())
# 然后就是调用DataLoader和刚刚创建的数据集,来创建dataloader,这里提一句,loader的长度是有多少个batch,所以和batch_size有关
train_loader = DataLoader(dataset=train_data, batch_size=6, shuffle=True, num_workers=4)
test_loader = DataLoader(dataset=test_data, batch_size=6, shuffle=False, num_workers=4)
print('num_of_trainData:', len(train_data))
print('num_of_testData:', len(test_data))
原文链接:https://blog.csdn.net/sinat_42239797/article/details/90641659